机器学习分类_机器学习-KNN图像分类
步骤:(1):计算测试数据与训练数据之间的距离;(2):按结果距离排序(3):选取距离最小的K个点(4):确定此K个样本中各个类别的频率(5):将频率最高的作为预测分类的结果样本数据集:0、1、2、3。分别是黑夜、激光、CXK、山水以上有三种方法,参考其他博主。import datetimestarttime=datetime.datetime.now()import numpy as npimp
·
步骤:
(1):计算测试数据与训练数据之间的距离;
(2):按结果距离排序
(3):选取距离最小的K个点
(4):确定此K个样本中各个类别的频率
(5):将频率最高的作为预测分类的结果
样本数据集:0、1、2、3。分别是黑夜、激光、CXK、山水
以上有三种方法,参考其他博主。
import datetimestarttime=datetime.datetime.now()import numpy as npimport osimport cv2 as cvfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import confusion_matrix,classification_reportfrom sklearn.neighbors import KNeighborsClassifier#from numpy import *# 1 导入数据X=[]Y=[]for i in range(0, 4): # 遍历文件夹,读取图片 for f in os.listdir("D:/testimage/test/%s" % i): # 获取图像名称 img = cv.imread("D:/testimage/test/" + str(i) + "/" + str(f)) image = cv.resize(img, (256, 256), interpolation=cv.INTER_CUBIC) image=cv.cvtColor(image,cv.COLOR_BGR2GRAY) hist = cv.calcHist([image], [0], None, [256], [0.0, 256.0]) X.append(((hist / 255).flatten())) Y.append(i)X = np.array(X)Y = np.array(Y)#切分训练集和测试集x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.3,random_state=1)class KNN: def __init__(self, train_data, train_label, test_data): self.train_data = train_data self.train_label = train_label self.test_data = test_data def knn_classify(self): num_train = (self.train_data).shape[0] num_test = (self.test_data).shape[0] labels = [] for i in range(num_test): y = [] for j in range(num_train): dis = np.sum(np.square((self.train_data)[j] - (self.test_data)[i])) y.append(dis) labels.append(self.train_label[y.index(min(y))]) labels = np.array(labels) return labelsknn = KNN(x_train, y_train, x_test)predictions_labels = knn.knn_classify()print(confusion_matrix(y_test, predictions_labels))print(classification_report(y_test, predictions_labels))endtime = datetime.datetime.now()print(endtime - starttime)#方法2 用KNN集成函数包clf0 = KNeighborsClassifier(n_neighbors=10).fit(x_train, y_train)predictions0 = clf0.predict(x_test)print(confusion_matrix(y_test, predictions0))print (classification_report(y_test, predictions0))#方法3 数学原理方法'''def KNN_Classify(newInput, dataSet, labels, k): numSamples = dataSet.shape[0] # shape[0]表示行数 # tile(A, reps): 构造一个矩阵,通过A重复reps次得到 # the following copy numSamples rows for dataSet diff = np.tile(newInput, (numSamples, 1)) - dataSet # 按元素求差值 squaredDiff = diff ** 2 # 将差值平方 squaredDist = np.sum(squaredDiff, axis=1) # 按行累加 distance = squaredDist ** 0.5 # 将差值平方和求开方,即得距离 # # step 2: 对距离排序 # argsort() 返回排序后的索引值 sortedDistIndices = np.argsort(distance) classCount = {} # define a dictionary (can be append element) for i in range(k): # # step 3: 选择k个最近邻 voteLabel = labels[sortedDistIndices[i]] # # step 4: 计算k个最近邻中各类别出现的次数 # when the key voteLabel is not in dictionary classCount, get() # will return 0 classCount[voteLabel] = classCount.get(voteLabel, 0) + 1 # # step 5: 返回出现次数最多的类别标签 maxCount = 0 for key, value in classCount.items(): if value > maxCount: maxCount = value maxIndex = key return maxIndexpredictions = []for i in range(x_test.shape[0]): predictions_labes = KNN_Classify(x_test[i], x_train, y_train, 10) predictions.append(predictions_labes)print(confusion_matrix(y_test, predictions))# 打印预测结果混淆矩阵print(classification_report(y_test, predictions))# 打印精度、召回率、FI结果endtime = datetime.datetime.now()print(endtime - starttime)'''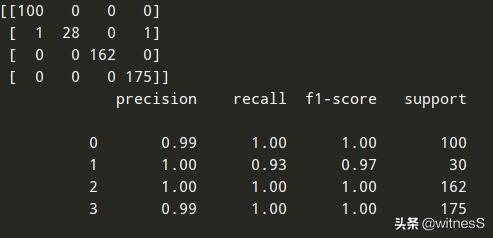
由于样本很相似,所以准确率很高,样本的采集来源于视频帧率截取。
参考文献:[1] 机器学习之KNN算法实现图像分类
[2] [Python图像处理] 二十六.图像分类原理及基于KNN、朴素贝叶斯算法的图像分类案例
CSDN:@WitnesS

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)