深度学习框架有什么作用?
作为一个看过tensorflow官网基础教程,玩过一段时间的keras,还测试过fastAI,跟着李沐老师团队MXnet/Gluon课程的半吊子AI工程师,今天开始学pytorch了,然后突然想到这个问题,就整理了一下。1. 什么是深度学习框架这个概念很泛化,先举几个例子,最后总结的时候再说:Pytorch的定义是:无缝替换NumPy,并且通过利用GPU的算力来实现神经网络的加速。通过自动微分机制
文章目录
作为一个看过tensorflow官网基础教程,玩过一段时间的keras,还测试过fastAI,跟着李沐老师团队MXnet/Gluon课程的半吊子AI工程师,今天开始学pytorch了,然后突然想到这个问题,就整理了一下。
1. 什么是深度学习框架
这个概念很泛化,先举几个例子,最后总结的时候再说:
Pytorch的定义是:
- 无缝替换NumPy,并且通过利用GPU的算力来实现神经网络的加速。
- 通过自动微分机制,来让神经网络的实现变得更加容易。
MXnet或者Gluon的一些特性:
记得以前上李沐老师团队的课,课中提到有自动求导的机制
PaddlePaddle:
PaddlePaddle会自动执行链式求导法则计算模型里面每个参数和变量对应的梯度值
TensorFlow很早就有了自动求导机制,网上搜索Tensorflow自动求导会有很多博文结果。
所以不难得知目前的深度学习框架都实现了自动求梯度的功能。
2. 深度学习框架的出现
背景:自从IBM 的深蓝Deep Blue 国际象棋系统在 1997 年击败了世界冠军 Garry Kasparov(Hsu, 2002),2016年alphago战胜人类围棋顶尖高手柯洁之后。
诱因:神经网络再次成为学术界和工业界的一个热点(学术带动工业,工业场景促进学术),所以出现了大量的深度学习计算框架,根本原因是深度学习对硬件环境的依赖很高,对于开发者有较高的门槛,深度学习计算框架的出现,屏蔽了大量硬件环境层面的开发代价,使研究者和开发人员可以专注于算法的实现,快速迭代。
举例:其实大多数深度学习框架都是在2016年附近开始出现的。
- tensorflow
2015年11月9日(github上最早的一个release时间 0.5.0)——tensorflow-github-tags2017年2月15日,tensorflow v1.0正式发布——【重磅】TensorFlow 1.0 官方正式发布,重大更新及5大亮点- 此后,
2019年10月1日,tensorflow发布2.0版本——TensorFlow 2.0凌晨发布!“改变一切,力压PyTorch”- pytorch ——
2016年8月24日,v0.1.1第一个release版本——pytorch-github-tags2018年12月,pytroch1.0正式版发布——PyTorch 1.0 正式版发布了!,- 百度的paddlepaddle,github上第一个release版本:
2016年8月31日V0.8.0b0 ——paddlepaddle-github-tags- 微软的CNTK,github上第一个release版本:
2016年2月22日2015-12-08——CNTK-github-tags- 亚马逊的mxbet,github上第一个release版本:
2016年5月27日v0.7.0 ——mxnet-github-tags
所以巨头入场,深度学习计算框架爆发元年,就是2015年底——2016年。
另外,在网上搜索了一下深度学习计算框架元年,搜到以下内容(源自:国产开源这一年,好生热闹):
2020年,“开源”成为AI领域的标签之一,而今年也成为国内深度学习框架的开源元年。
从年初开始,华为Mindspore、旷视天元MegEngine、腾讯TNN、清华Jittor等数个国产AI框架渐次宣布开源。此外,百度飞桨也通过与不同企业的合作,不断拓展飞桨的兼容性和开放特征。随着国内科技公司对框架的开源,逐渐打破了国外PyTorch、TensorFlow、Keras、MXNet四家独大的局面,为国内人工智能技术的发展奠定了最关键的底层基础。
据全球咨询机构IDC在《中国深度学习平台市场份额调研》显示,在AI技术使用方面,接受调研的企业和开发者中,86.2%选择使用开源的深度学习框架。
就目前而言,除了华为、腾讯等大体量的科技企业外,一批新兴人工智能企业的开源项目,也逐渐成为主流,旷视的深度学习框架天元(MegEngine)就是其中之一。
虽然好像都没怎么听过,但是有总比没得好,😀
3. 总结
深度学习计算框架的作用(个人观点,欢迎补充)
- 代替numpy(numpy能实现数值计算)使用GPU对Tensor进行操作,实现神经网络的操作
- 提供自动求导/求微分/求梯度的机制,让神经网络实现变得容易
- 内置许多基本网络组件,比如全连接网络,卷积网络,RNN/LSTM等,简化代码工作,让大家可以专注于模型设计等其他步骤,而不是编程上。
或者其他人的说法是:
大部分深度学习框架都包含以下五个核心组件:
- 张量(Tensor)
- 基于张量的各种操作
- 计算图(Computation Graph)
- 自动微分(Automatic Differentiation)工具
- BLAS、cuBLAS、cuDNN等拓展包
3.1 深度学习框架如何加速计算
1. 张量+基于张量的各种操作+计算图=为了加速计算
最早的Theano使用了计算图,其程序性能是numpy的1.8倍,而在GPU上是NumPy的11倍。
参考:
——在GPU上运行,性能是NumPy的11倍,这个Python库你值得拥有
——如何理解TensorFlow计算图?
> 计算图从本质上来说,是TensorFlow在内存中构建的程序逻辑图,计算图可以被分割成多个块,并且可以并行地运行在多个不同的cpu或gpu上,这被称为并行计算。因此,计算图可以支持大规模的神经网络。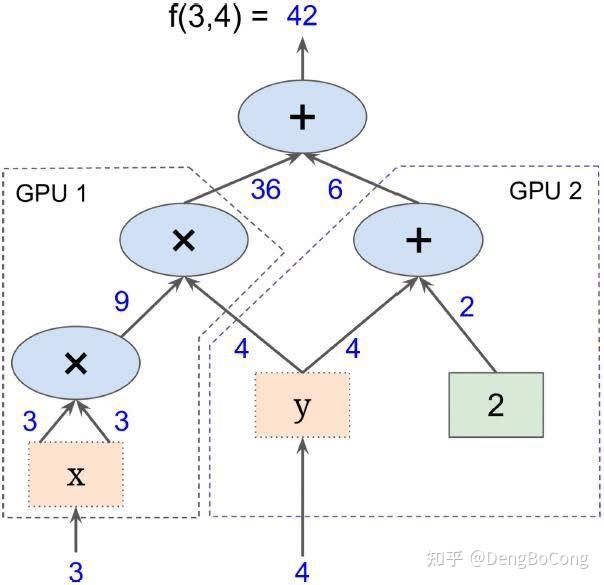
——为什么Tensorflow需要使用"图计算"来表示计算过程
3.1.1 计算图
计算图诞生的原因:
由于张量和张量的操作很多,难以理清关系的话可能会引发许多问题,比如:多个操作之间应该并行还是顺次执行,如何协同各种不同的底层设备,以及如何避免各种类型的冗余操作等等。这些问题有可能拉低整个深度学习网络的运行效率或者引入不必要的Bug,而计算图正是为解决这一问题产生的。
计算图首次被引入AI领域:
计算图首次被引入人工智能领域是Yoshua Bengio(约书亚·本吉奥,深度学习三巨头之一)在2009年的论文《Learning Deep Architectures for AI》。
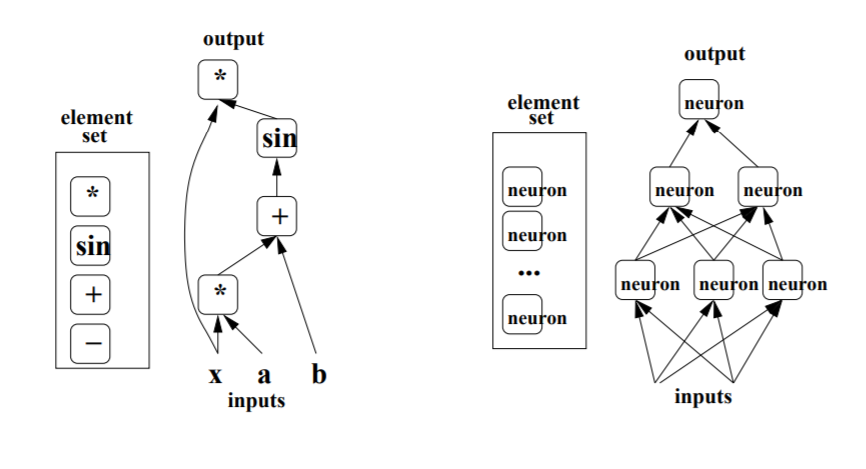
如图:作者用不同的占位符(*,+,sin)构成操作结点,以字母x、a、b构成变量结点,再以有向线段将这些结点连接起来,组成一个表征运算逻辑关系的清晰明了的“图”型数据结构,这就是最初的计算图。
计算图的发展:随着技术的演进,结合脚本语言和底层语言各自不同的特点(脚本语言建模方便但执行缓慢,底层语言则相反),因此业界逐渐形成了这样的一种流程:前端用Python等脚本语言建模,后端用C++等底层语言执行,以此综合二者的优点。这种开发框架大大降低了传统框架做跨设备计算时的代码耦合度,也避免了每次后端变动都需要修改前端的维护开销。其中在前端和后端之间起到关键耦合作用的就是计算图。
计算图的优点:将计算图作为前后端之间的中间表示(Intermediate Representations)可以带来良好的交互性,开发者可以将Tensor对象作为数据结构,函数/方法作为操作类型,将特定的操作类型应用于特定的数据结构,从而定义出类似MATLAB的强大建模语言。
需要注意的是,
通常情况下开发者不会将用于中间表示得到的计算图直接用于模型构造,因为这样的计算图通常包含了大量的冗余求解目标,也没有提取共享变量,因而通常都会经过依赖性剪枝、符号融合、内存共享等方法对计算图进行优化。
目前,各个框架对于计算图的实现机制和侧重点各不相同。例如Theano和MXNet都是以隐式处理的方式在编译中由表达式向计算图过渡。而Caffe则比较直接,可以创建一个Graph对象,然后以类似Graph.Operator(xxx)的方式显示调用。
结论:计算图的引入,使得开发者可以从宏观上俯瞰整个神经网络的内部结构,就好像编译器可以从整个代码的角度决定如何分配寄存器那样,计算图也可以从宏观上决定代码运行时的GPU内存分配,以及分布式环境中不同底层设备间的相互协作方式。除此之外,现在也有许多深度学习框架将计算图应用于模型调试,可以实时输出当前某一操作类型的文本描述。
3.2 如何实现自动微分
自动微分工具(主要是比传统的符号微分更加方便)
传统求解微分的方式:与自动微分对应,业内更传统的做法是
符号微分。符号微分即常见的求导分析。
传统求解微分方式的缺点:针对一些非线性过程(如修正线性单元ReLU)或者大规模的问题,使用符号微分法的成本往往非常高昂,有时甚至不可行(即不可微)。
自动微分的好处:众所周知,神经网络就是由许多非线性过程组成的一个复杂的函数体,而计算图则以模块化的方式完整表征了这一函数体的内部逻辑关系,
- 因此
微分这一复杂函数体,即求取模型梯度的方法就变成了在计算图中简单地从输入到输出进行一次完整遍历的过程。- 上述迭代式的自动微分法求解模型梯度已经被广泛采用。
- 并且由于自动微分可以成功应对一些符号微分不适用的场景,目前许多计算图程序包(例如Computation Graph Toolkit)都已经预先实现了自动微分。
- 另外,由于每个节点处的导数只能相对于其相邻节点计算,因此实现了自动微分的模块一般都可以直接加入任意的操作类中,当然也可以被上层的微分大模块直接调用。
3.3 扩展包用来做什么
常见的有:BLAS、cuBLAS、cuDNN等拓展包
- 现有优势:结构/流程/模块完整
可以将待处理数据转换为
张量,针对张量施加各种需要的操作,还有计算图整理这些操作和张量流动方式,通过自动微分对模型展开训练,然后得到输出结果开始测试,其实已经足以支撑一个深度学习计算框架了。 - 等待改进:运算效率。
由于此前的大部分实现都是基于高级语言的(如Java、Python、Lua等),而即使是执行最简单的操作,高级语言也会比底层语言(C++)消耗更多的CPU周期,更何况是结构复杂的深度神经网络,因此运算缓慢就成了高级语言的一个天然的缺陷。
关于高级语言运算速率低的问题,目前有两种解决方案。
- 第一种方法是
模拟传统的编译器。就好像传统编译器会把高级语言编译成特定平台的汇编语言实现高效运行一样,这种方法将高级语言转换为C语言,然后在C语言基础上编译、执行。为了实现这种转换,每一种张量操作的实现代码都会预先加入C语言的转换部分,然后由编译器在编译阶段将这些由C语言实现的张量操作综合在一起。目前pyCUDA和Cython等编译器都已经实现了这一功能。 - 第二种方法就是前文提到的,利用脚本语言实现前端建模,用底层语言如C++实现后端运行,这意味着高级语言和低级语言之间的交互都发生在框架内部,因此每次的后端变动都不需要修改前端,也不需要完整编译(只需要通过修改编译参数进行部分编译),因此整体速度也就更快。
- 除此之外,由于底层语言的最优化编程难度很高,而且大部分的基础操作其实也都有公开的最优解决方案,因此
另一个显著的加速手段就是利用现成的扩展包。例如最初用Fortran实现的BLAS( basic linear algebra subroutine,基础线性代数子程序),是一个非常优秀的基本矩阵(张量)运算库,此外还有英特尔的MKL(Math Kernel Library)等,开发者可以根据个人喜好灵活选择。
一般的BLAS库只是针对普通的CPU场景进行了优化,但目前大部分的深度学习模型都已经开始采用并行GPU的运算模式,因此利用诸如NVIDIA推出的针对GPU优化的cuBLAS和cuDNN等更据针对性的库可能是更好的选择。
运算速度对于深度学习框架来说至关重要,例如同样训练一个神经网络,不加速需要4天的时间,加速的话可能只要4小时。在快速发展的人工智能领域,特别是对那些成立不久的人工智能初创公司而言,这种差别可能就会决定谁是先驱者,而谁是追随者。
3.4 部署模型加速的工具
3.4.1 GPU级别的加速-英伟达的TensorRT
在平台上部署模型投入应用,很多时候就需要用到专门的模型加速工具 —— TensorRT,TensorRT只负责模型的推理(inference)过程,一般不用TensorRT来训练模型。
TensorRT为什么能提升模型的运行速度?
TensorRT是英伟达针对自家平台做的加速包,TensorRT主要做了这么两件事情,来提升模型的运行速度。
- TensorRT支持INT8和FP16的计算。深度学习网络在训练时,通常使用 32 位或 16 位数据。TensorRT则在网络的推理时选用不这么高的精度,达到加速推断的目的。
- TensorRT对于网络结构进行了重构,把一些能够合并的运算合并在了一起,针对GPU的特性做了优化。现在大多数深度学习框架是没有针对GPU做过性能优化的,而英伟达,GPU的生产者和搬运工,自然就推出了针对自己GPU的加速工具TensorRT。一个深度学习模型,在没有优化的情况下,比如一个卷积层、一个偏置层和一个reload层,这三层是需要调用三次cuDNN对应的API,但实际上这三层的实现完全是可以合并到一起的,TensorRT会对一些可以合并网络进行合并。
3.4.2 CPU级别的加速——英特尔公司的OpenVINO工具箱
OpenVINO是英特尔公司开发的基于卷积神经网络(CNN)的深度学习推理加速工具箱。它能使英特尔公司硬件,最大化提高深度学习计算性能。因此,当将深度学习模型部署到CPU端时,可以利用OpenVINO工具箱进行部署,提高深度学习模型推理速度。
此外,参考机器之心文章:基于CPU的深度学习推理部署优化实践,网上也有视频讲座,可以搜搜。
CPU上系统级优化实践中我们主要采用数学库优化(基于MKL-DNN)和深度学习推理SDK优化(Intel OpenVINO)两种方式。这两种方式均包含了SIMD指令集的加速。

参考神经网络推理加速之模型量化可知:
许多云服务商和硬件供应商提供了一系列针对推理优化的基础设施,例如亚马逊的SageMaker、Deep Learning AMIs,英特尔 ® 的 Deep Learning Boost、矢量神经网络指令集 (VNNI) 等。
4. 参考内容:
- 新浪博客: 常见的深度学习计算框架
- 博客园博客: 深度学习框架究竟是什么?
- 参考知乎回答:什么叫做深度学习框架,其作用是什么
- 参考知乎专栏文章:[深度学习]TensorRT为什么能让模型跑快快
- 参见csdn博客:如何将Pytorch生成的模型进行CPU部署
- 参考知乎专栏文章:[网络加速] openvino与Tensor RT 原理比较
- 参考知乎专栏文章:MKLDNN推理加速技术简介
- 参考机器之心文章:基于CPU的深度学习推理部署优化实践
- 神经网络推理加速之模型量化
- 很多互联网大厂都在各个网站上是入驻作者,比如
爱奇艺技术产品团队就在机器之心上:https://www.jiqizhixin.com/columns/aiqiyijishutuandui

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 14
14 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)