FlashAttention:深度学习中的高效注意力机制
FlashAttention 通过分块计算、块内归一化和 CUDA 并行化技术,显著提高了注意力机制的计算速度和内存效率。它在自然语言处理、计算机视觉和语音识别等多个领域具有广泛的应用前景。通过本文的介绍和公式推导,希望读者能够更好地理解和应用 FlashAttention,为深度学习模型的训练和推理提供更高效的支持。
FlashAttention:深度学习中的高效注意力机制
背景
在深度学习领域,Transformer 模型因其在自然语言处理和计算机视觉等任务中的卓越性能而备受关注。而注意力机制(Attention Mechanism)作为 Transformer 模型的核心组件,其计算效率和内存占用一直是一个重要的研究方向。FlashAttention 作为一种新型的注意力机制优化算法,通过创新的计算方法和内存管理策略,显著提高了注意力机制的计算速度和内存效率,为大规模模型的训练和推理提供了有力支持。
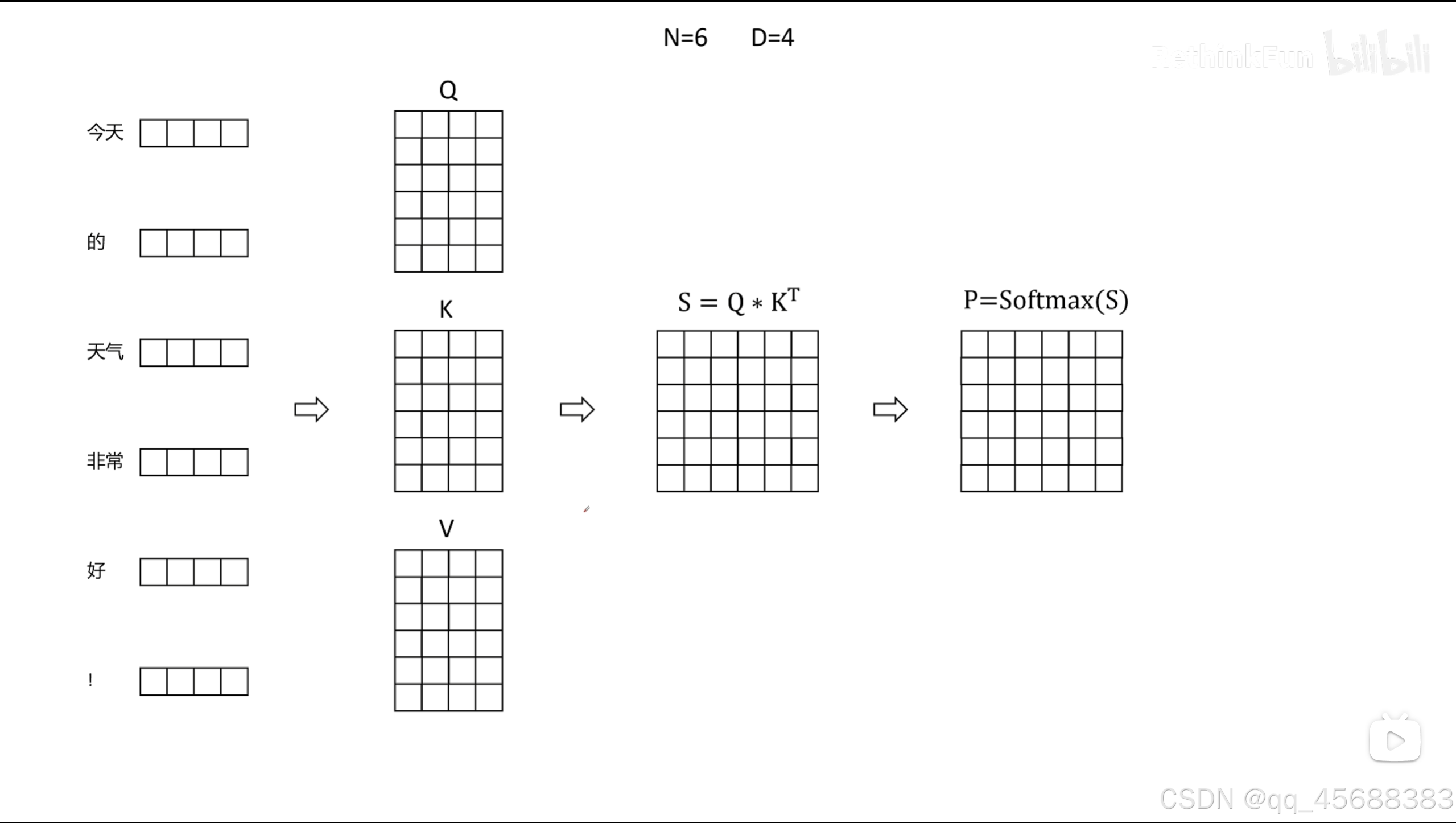
传统的注意力机制计算复杂度为 O ( N 2 ) O(N^2) O(N2),其中 N N N 为序列长度。如上图所示(图片出处:B站视频Flash Attention 为什么那么快?原理讲解
),如果图片中 D D D的大小增加了1,那么图中的矩阵 S S S大小会呈平方增大。
随着模型规模的不断扩大和序列长度的增加,这种计算方式在计算资源和内存占用方面面临着巨大的挑战。尤其是在处理长序列数据时,传统的注意力机制会导致计算速度缓慢和内存消耗巨大,限制了模型的性能和应用范围。为了解决这些问题,研究人员提出了多种优化方法,FlashAttention 就是其中一种具有代表性的解决方案。
FlashAttention 的原理
核心机制
FlashAttention 的核心思想是通过分块计算和块内归一化来避免存储完整的 n × n n \times n n×n 矩阵,从而减少内存占用和计算量。具体来说,FlashAttention 将输入序列分成多个小块,然后在每个小块内进行注意力计算和归一化操作,最后将结果合并得到最终的输出。这种方法不仅减少了内存占用,还提高了计算效率。
分块计算
在 FlashAttention 中,输入序列 Q Q Q、 K K K、 V V V 被分成多个大小为 b l o c k _ s i z e block\_size block_size 的小块。对于每个小块,分别计算其注意力分数和输出。这种方法避免了存储完整的注意力矩阵,从而减少了内存占用。同时,分块计算还可以更好地利用 GPU 的并行计算能力,提高计算速度。
具体来说,假设输入序列的长度为 N N N,块大小为 b b b,则可以将输入序列分成 ⌈ N b ⌉ \lceil \frac{N}{b} \rceil ⌈bN⌉ 个块。对于每个块 i i i,计算其注意力分数 S i S_i Si 和输出 O i O_i Oi,然后将所有块的结果合并得到最终的输出。
块内归一化
在每个小块内,FlashAttention 使用块内归一化来计算注意力分数。具体来说,对于每个小块内的注意力分数,先计算其最大值,然后将每个分数减去最大值,再进行指数运算和归一化。这种方法可以避免数值溢出问题,同时提高计算精度。
块内归一化的公式如下:
Softmax ( x ) = exp ( x − max ( x ) ) ∑ exp ( x − max ( x ) ) \text{Softmax}(x) = \frac{\exp(x - \max(x))}{\sum \exp(x - \max(x))} Softmax(x)=∑exp(x−max(x))exp(x−max(x))
其中, x x x 是注意力分数, max ( x ) \max(x) max(x) 是 x x x 的最大值。
CUDA 并行化
FlashAttention 利用 CUDA 并行化技术,将注意力计算分解为多个小任务,分配给 GPU 的多个核心并行处理。通过结合 kernel fusion 技术,FlashAttention 实现了高效的矩阵运算,进一步提高了计算速度。
具体来说,FlashAttention 将注意力计算分解为多个小块,每个小块的计算任务可以独立地在 GPU 的不同核心上并行执行。这样可以充分利用 GPU 的并行计算能力,显著提高计算速度。
公式推导
传统注意力机制
传统的注意力机制公式如下:
Attention ( Q , K , V ) = Softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=Softmax(dkQKT)V
其中, Q Q Q、 K K K、 V V V 分别是查询、键和值矩阵, d k d_k dk 是键的维度。
FlashAttention 的优化
FlashAttention 通过分块计算和块内归一化来优化注意力机制。具体来说,对于每个小块 i i i,计算其注意力分数 S i S_i Si 和输出 O i O_i Oi,然后将所有块的结果合并得到最终的输出。
对于每个小块 i i i,计算其注意力分数 S i S_i Si 的公式如下:
S i = Q i K i T d k S_i = \frac{Q_i K_i^T}{\sqrt{d_k}} Si=dkQiKiT
其中, Q i Q_i Qi 和 K i K_i Ki 是块 i i i 的查询和键矩阵。
块内归一化的公式如下:
Softmax ( S i ) = exp ( S i − max ( S i ) ) ∑ exp ( S i − max ( S i ) ) \text{Softmax}(S_i) = \frac{\exp(S_i - \max(S_i))}{\sum \exp(S_i - \max(S_i))} Softmax(Si)=∑exp(Si−max(Si))exp(Si−max(Si))
其中, max ( S i ) \max(S_i) max(Si) 是 S i S_i Si 的最大值。
最终的输出 O i O_i Oi 为:
O i = Softmax ( S i ) V i O_i = \text{Softmax}(S_i) V_i Oi=Softmax(Si)Vi
其中, V i V_i Vi 是块 i i i 的值矩阵。
分块计算的优化
通过分块计算,FlashAttention 避免了存储完整的 n × n n \times n n×n 矩阵,从而减少了内存占用。同时,分块计算还可以更好地利用 GPU 的并行计算能力,提高计算速度。
具体来说,假设输入序列的长度为 N N N,块大小为 b b b,则可以将输入序列分成 ⌈ N b ⌉ \lceil \frac{N}{b} \rceil ⌈bN⌉ 个块。对于每个块 i i i,计算其注意力分数 S i S_i Si 和输出 O i O_i Oi,然后将所有块的结果合并得到最终的输出。
CUDA 并行化的优化
FlashAttention 利用 CUDA 并行化技术,将注意力计算分解为多个小任务,分配给 GPU 的多个核心并行处理。通过结合 kernel fusion 技术,FlashAttention 实现了高效的矩阵运算,进一步提高了计算速度。
具体来说,FlashAttention 将注意力计算分解为多个小块,每个小块的计算任务可以独立地在 GPU 的不同核心上并行执行。这样可以充分利用 GPU 的并行计算能力,显著提高计算速度。
代码实现
基于numpy实现
import numpy as np
class FlashAttention:
def __init__(self, block_size=16):
"""
初始化 FlashAttention 类
:param block_size: 分块大小
"""
self.block_size = block_size
self.cache = {} # 用于存储前向传播的中间结果
def forward(self, Q, K, V):
"""
前向传播
:param Q: 查询矩阵,形状为 (batch_size, seq_len, hidden_dim)
:param K: 键矩阵,形状为 (batch_size, seq_len, hidden_dim)
:param V: 值矩阵,形状为 (batch_size, seq_len, hidden_dim)
:return: 输出矩阵,形状为 (batch_size, seq_len, hidden_dim)
"""
batch_size, seq_len, hidden_dim = Q.shape
output = np.zeros_like(Q)
self.cache['Q'] = Q
self.cache['K'] = K
self.cache['V'] = V
self.cache['attention_weights'] = [] # 存储每个块的注意力权重
# 分块计算
for i in range(0, seq_len, self.block_size):
Q_block = Q[:, i:i + self.block_size, :]
K_block = K[:, i:i + self.block_size, :]
V_block = V[:, i:i + self.block_size, :]
# 计算注意力分数
scores = np.matmul(Q_block, K_block.transpose(0, 2, 1)) / np.sqrt(hidden_dim)
# 块内归一化
max_scores = np.max(scores, axis=-1, keepdims=True)
scores -= max_scores
attention_weights = np.exp(scores) / np.sum(np.exp(scores), axis=-1, keepdims=True)
# 输出
output_block = np.matmul(attention_weights, V_block) # (batch_size, block_size, hidden_dim)
output[:, i:i + self.block_size, :] += output_block
# 存储注意力权重
self.cache['attention_weights'].append(attention_weights)
return output
def backward(self, dout):
"""
反向传播
:param dout: 输出的梯度,形状为 (batch_size, seq_len, hidden_dim)
:return: dQ, dK, dV 分别为查询、键和值的梯度
"""
batch_size, seq_len, hidden_dim = self.cache['Q'].shape
Q = self.cache['Q']
K = self.cache['K']
V = self.cache['V']
attention_weights_list = self.cache['attention_weights']
dQ = np.zeros_like(Q)
dK = np.zeros_like(K)
dV = np.zeros_like(V)
for i in range(0, seq_len, self.block_size):
# 获取当前分块的范围
start = i
end = min(i + self.block_size, seq_len)
# 获取当前分块的注意力权重
attention_weights = attention_weights_list[i // self.block_size]
# 获取当前分块的输入和输出梯度
Q_block = Q[:, start:end, :]
K_block = K[:, start:end, :]
V_block = V[:, start:end, :]
dout_block = dout[:, start:end, :]
# 计算 dV_part
dV_part = np.matmul(attention_weights.transpose(0, 2, 1), dout_block)
dV[:, start:end, :] += dV_part
# 计算 dAttention_weights
dAttention_weights = np.matmul(dout_block, V_block.transpose(0, 2, 1))
# 反向传播块内归一化
dScores = dAttention_weights * np.exp(attention_weights) / np.sum(np.exp(attention_weights), axis=-1, keepdims=True)
# 反向传播注意力分数
dQ_block = np.matmul(dScores, K_block) / np.sqrt(hidden_dim)
dK_block = np.matmul(Q_block.transpose(0, 2, 1), dScores) / np.sqrt(hidden_dim)
dQ[:, start:end, :] += dQ_block
dK[:, start:end, :] += dK_block
return dQ, dK, dV
# 示例用法
batch_size, seq_len, hidden_dim = 2, 5, 4
Q = np.random.rand(batch_size, seq_len, hidden_dim)
K = np.random.rand(batch_size, seq_len, hidden_dim)
V = np.random.rand(batch_size, seq_len, hidden_dim)
flash_attn = FlashAttention(block_size=2)
output = flash_attn.forward(Q, K, V)
dQ, dK, dV = flash_attn.backward(np.random.rand(batch_size, seq_len, hidden_dim))
print("Flash Attention Output:\n", output)
print("\nGradient of Q:\n", dQ)
print("\nGradient of K:\n", dK)
print("\nGradient of V:\n", dV)
基于pytorch实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class FlashAttention(nn.Module):
def __init__(self, block_size=16):
super(FlashAttention, self).__init__()
self.block_size = block_size
def forward(self, Q, K, V):
"""
前向传播
:param Q: 查询矩阵,形状为 (batch_size, seq_len, hidden_dim)
:param K: 键矩阵,形状为 (batch_size, seq_len, hidden_dim)
:param V: 值矩阵,形状为 (batch_size, seq_len, hidden_dim)
:return: 输出矩阵,形状为 (batch_size, seq_len, hidden_dim)
"""
batch_size, seq_len, hidden_dim = Q.shape
output = torch.zeros_like(Q)
for i in range(0, seq_len, self.block_size):
# 获取当前分块的索引范围
start = i
end = min(i + self.block_size, seq_len)
# 获取当前分块的 Q、K、V
Q_block = Q[:, start:end, :]
K_block = K[:, start:end, :]
V_block = V[:, start:end, :]
# 计算注意力分数
scores = torch.matmul(Q_block, K_block.transpose(-2, -1)) / torch.sqrt(torch.tensor(hidden_dim, dtype=Q.dtype))
# 块内归一化
max_scores = torch.max(scores, dim=-1, keepdim=True)[0]
scores = scores - max_scores
attention_weights = torch.softmax(scores, dim=-1)
# 计算输出
output_block = torch.matmul(attention_weights, V_block)
output[:, start:end, :] += output_block
return output
# 示例用法
batch_size, seq_len, hidden_dim = 2, 5, 4
Q = torch.randn(batch_size, seq_len, hidden_dim)
K = torch.randn(batch_size, seq_len, hidden_dim)
V = torch.randn(batch_size, seq_len, hidden_dim)
flash_attn = FlashAttention(block_size=2)
output = flash_attn(Q, K, V)
# 反向传播示例
output.sum().backward()
基于flash_attn + pytorch 实现
安装 flash_attn 和相关依赖:
pip install flash-attn torch
总结
FlashAttention 通过分块计算、块内归一化和 CUDA 并行化技术,显著提高了注意力机制的计算速度和内存效率。它在自然语言处理、计算机视觉和语音识别等多个领域具有广泛的应用前景。通过本文的介绍和公式推导,希望读者能够更好地理解和应用 FlashAttention,为深度学习模型的训练和推理提供更高效的支持。
致谢

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)