深度学习——batch normalization
参考链接:https://mp.weixin.qq.com/s/XPsRC6rC4_I9a-WPzOTSywTable of Contents什么是Batch Normalization它如何工作优点Batch Normalization的诅咒在使用小batch size的时候不稳定导致训练时间的增加什么是Batch Normalization在训练过程中,当我们更新之前的权值时,每个中间激活层的
Table of Contents
https://blog.csdn.net/qq_25737169/article/details/79048516
ICS 内部协方差偏移
训练深度网络的时候经常发生训练困难的问题,因为,每一次参数迭代更新后,上一层网络的输出数据经过这一层网络计算后,数据的分布会发生变化,为下一层网络的学习带来困难(神经网络本来就是要学习数据的分布,要是分布一直在变,学习就很难了),此现象称之为 I n t e r n a l Internal Internal C o v a r i a t e Covariate Covariate S h i f t Shift Shift。
BN
batchnorm直译过来就是批规范化,就是为了解决这个分布变化问题。
在训练中完成的任务,每次训练给一个批量,然后计算批量的均值方差(跟踪统计全局的均值方差),然后归一化,然后缩放和平移。
深入理解NLP中LayerNorm的原理以及LN的代码详解_白马金羁侠少年的博客-CSDN博客_layernorm层
深入理解NLP中LayerNorm的原理以及LN的代码详解_白马金羁侠少年的博客-CSDN博客_layernorm层
LN
对每一个embedding参数维度做norm。
为什么Layer Norm是对每个单词的embedding进行归一化,而不是对这个序列的所有单词embedding向量的相同维度进行归一化呢?
——即BN是对所有单词embedding向量的相同维度做归一化
——LN是对每一个单词的embedding做归一化
什么是Batch Normalization
在训练过程中,当我们更新之前的权值时,每个中间激活层的输出分布会在每次迭代时发生变化。这种现象称为内部协变量移位(ICS, internal covariate shift)。所以很自然的一件事,如果我想防止这种情况发生,就是修正所有的分布。简单地说,如果我的分布变动了,我会限制住这个分布,不让它移动,以帮助梯度优化和防止梯度消失,这将帮助我的神经网络训练更快。因此减少这种内部协变量位移是推动batch normalization发展的关键原则。
它如何工作
Batch Normalization通过在batch上减去经验平均值除以经验标准差来对前一个输出层的输出进行归一化。这将使数据看起来像高斯分布。
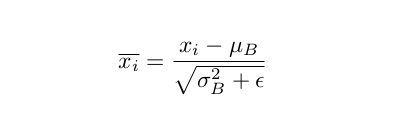
其中μ和*σ^2^*分别为批均值和批方差。
优点
我将列举使用batch normalization的一些好处,但是我不会详细介绍,因为已经有很多文章讨论了这个问题。
-
更快的收敛。
-
降低初始权重的重要性。
-
鲁棒的超参数。
-
需要较少的数据进行泛化。
Batch Normalization的诅咒/问题
在使用小batch size的时候不稳定
如上所述,batch normalization必须计算平均值和方差,以便在batch中对之前的输出进行归一化。如果batch大小比较大的话,这种统计估计是比较准确的,而随着batch大小的减少,估计的准确性持续减小,因为不稳定。
如果batch大小是一个问题,为什么我们不使用更大的batch?我们不能在每种情况下都使用更大的batch。在finetune的时候,我们不能使用大的batch,以免过高的梯度对模型造成伤害。在分布式训练的时候,大的batch最终将作为一组小batch分布在各个实例中。
导致训练时间的增加
NVIDIA和卡耐基梅隆大学进行的实验结果表明,“尽管Batch Normalization不是计算密集型,而且收敛所需的总迭代次数也减少了。”但是每个迭代的时间显著增加了,而且还随着batch大小的增加而进一步增加。
batch normalization消耗了总训练时间的1/4。原因是batch normalization需要通过输入数据进行两次迭代,一次用于计算batch统计信息,另一次用于归一化输出。
训练和推理时不一样的结果??
例如,在真实世界中做“物体检测”。在训练一个物体检测器时,我们通常使用大batch(YOLOv4和Faster-RCNN都是在默认batch大小= 64的情况下训练的)。但在投入生产后,这些模型的工作并不像训练时那么好。这是因为它们接受的是大batch的训练,而在实时情况下,它们的batch大小等于1,因为它必须一帧帧处理。考虑到这个限制,一些实现倾向于基于训练集上使用预先计算的平均值和方差。另一种可能是基于你的测试集分布计算平均值和方差值。
对于在线学习的不友好
与batch学习相比,在线学习是一种学习技术,在这种技术中,系统通过依次向其提供数据实例来逐步接受训练,可以是单独的,也可以是通过称为mini-batch的小组进行。每个学习步骤都是快速和便宜的,所以系统可以在新的数据到达时实时学习。
由于它依赖于外部数据源,数据可能单独或批量到达。由于每次迭代中batch大小的变化,对输入数据的尺度和偏移的泛化能力不好,最终影响了性能。
对于循环神经网络不好
虽然batch normalization可以显著提高卷积神经网络的训练和泛化速度,但它们很难应用于递归结构。batch normalization可以应用于RNN堆栈之间,其中归一化是“垂直”应用的,即每个RNN的输出。但是它不能“水平地”应用,例如在时间步之间,因为它会因为重复的重新缩放而产生爆炸性的梯度而伤害到训练。
可替换的方法
这就是使用batch normalization的一些缺点。在batch normalization无法很好工作的情况下,有几种替代方法。
-
Layer Normalization
-
Instance Normalization
-
Group Normalization (+ weight standardization)
-
Synchronous Batch Normalization


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)