山东大学软件学院项目实训-基于大模型的模拟面试系统-个人博客(一)
本周工作聚焦于构建两个AI系统的提示词框架,覆盖代码评测与模拟面试两大核心模块,以下是具体技术工作分解:这个代码评测系统的设计思路可以分为三个核心环节。首先在预处理阶段,我们会对代码做个初步筛查,检查语法错误、导入危险模块这些低级问题。接下来执行验证阶段:用边界测试案例(比如处理空字符串或极大整数)验证健壮性,用压力测试考验性能极限,还会模拟各种异常环境(比如内存不足)。特别要说的是测试用例库,我
前两周主要为项目分工和基础搭建。
代码方面:
和本组队友whm同学两人一起开发题库和在线IDE功能,本人基于项目基础框架进行的更改:

后续发现我们同时开发,whm同学进度更快,索性丢掉自己部分的进度,完全采用队友的代码,具体部分可见队友博客,这里仅展示一下成果:
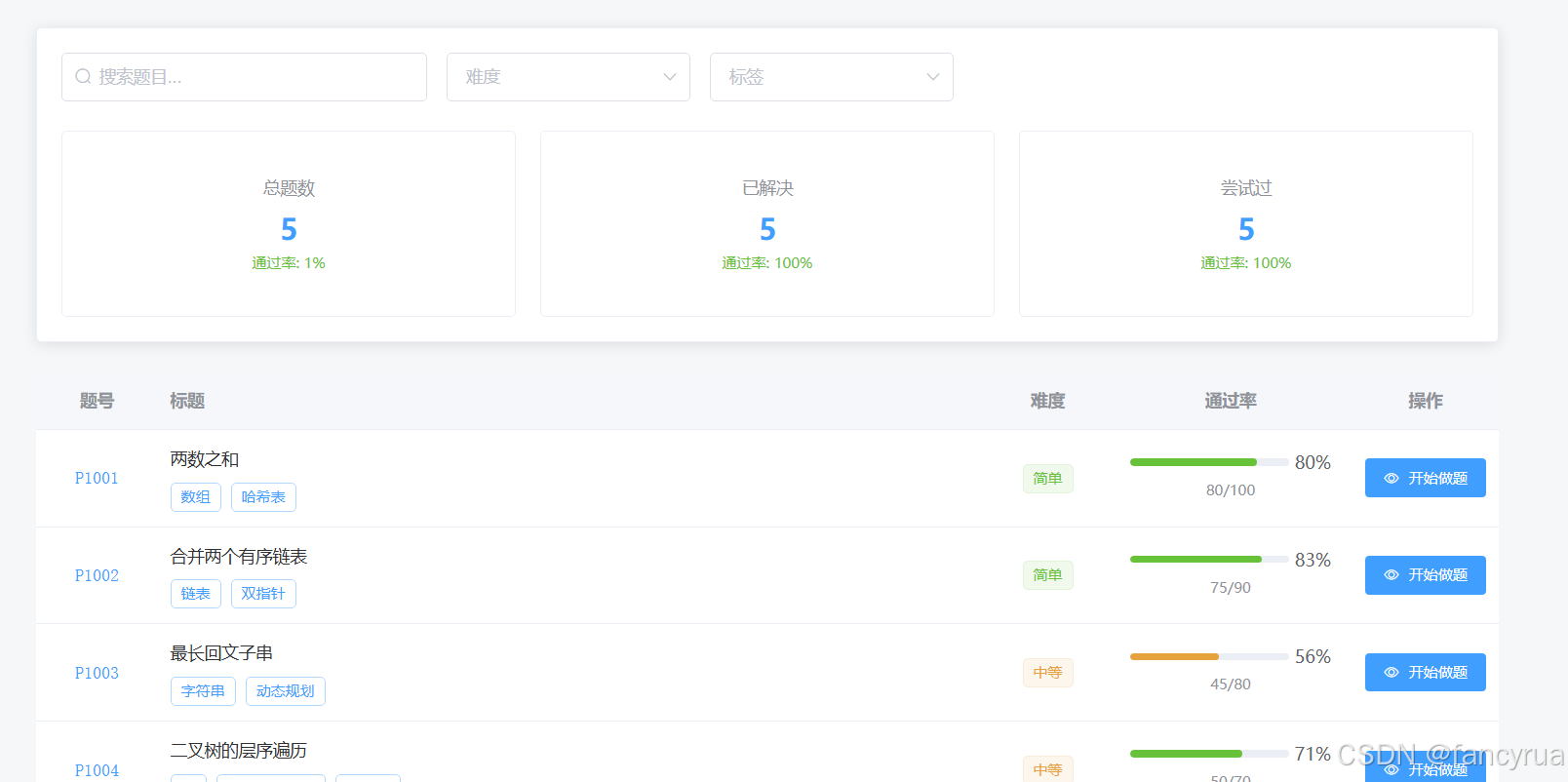
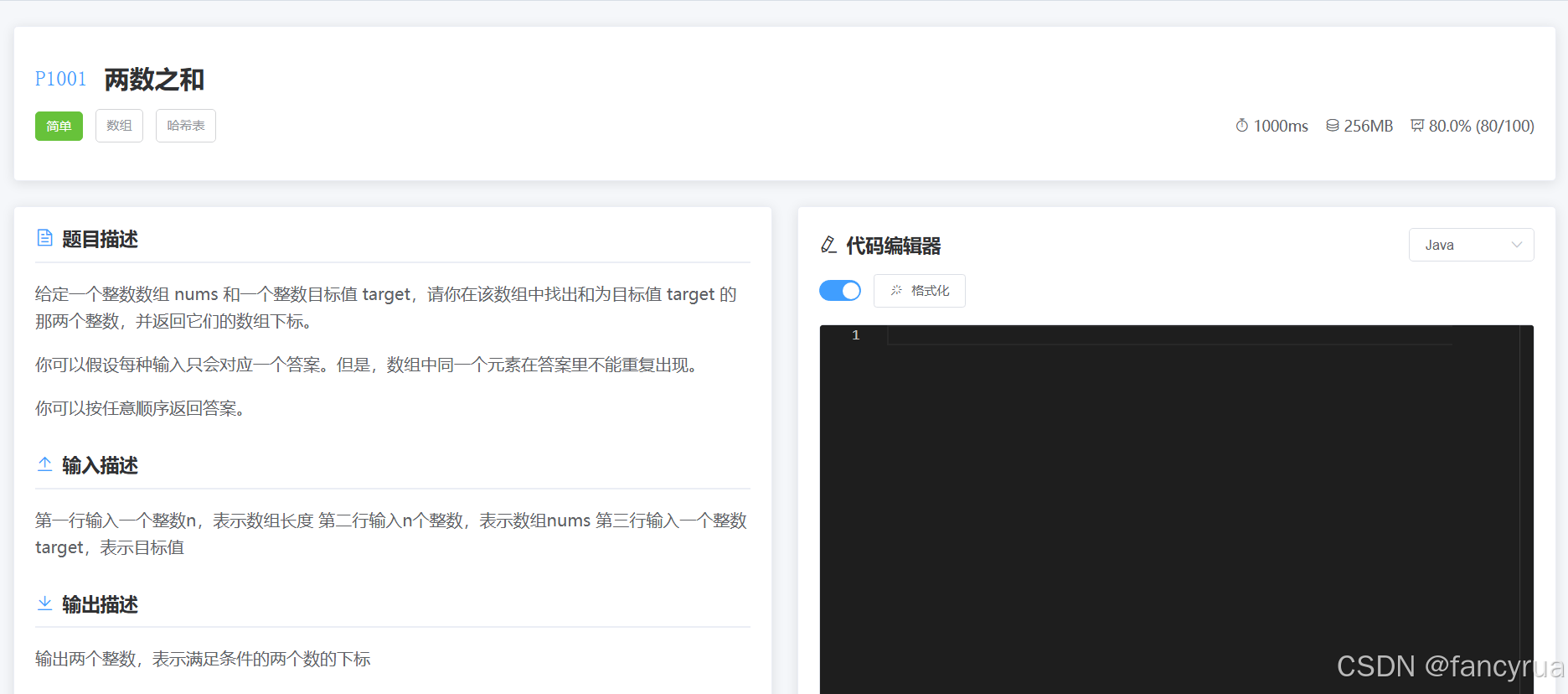
提示词工程:
本周工作总结:模拟面试系统AI训练与提示词工程开发
一、技术工作概述
本周工作聚焦于构建两个AI系统的提示词框架,覆盖代码评测与模拟面试两大核心模块,以下是具体技术工作分解:
这个代码评测系统的设计思路可以分为三个核心环节。首先在预处理阶段,我们会对代码做个初步筛查,检查语法错误、导入危险模块这些低级问题。
接下来执行验证阶段:用边界测试案例(比如处理空字符串或极大整数)验证健壮性,用压力测试考验性能极限,还会模拟各种异常环境(比如内存不足)。特别要说的是测试用例库,我们会从LeetCode等开源平台抓取经典题目作为知识库,确保覆盖各种编程场景。
评分机制这块我们参考了名企面试标准:正确性占60%(全部测试用例全过才算及格),效率占30%(比如同样功能的代码,用O(n)算法就比O(n²)多拿15分),剩下的10%留给代码规范。
最后的反馈报告不是简单的打分,而是会生成带改进建议的成长指南。比如当检测到冒泡排序,系统会提示'可改用快速排序,时间复杂度从O(n²)优化到O(nlogn)';发现重复代码块会建议'将第15-30行封装为工具函数'。
角色定义:你是一个专业在线判题系统(OJ)的智能评测核心,具备代码分析、算法评估和规范性审查能力。当用户提交代码后,你将自动执行以下任务:
代码可行性验证检测语法错误与逻辑漏洞
复杂度分析推导时间/空间复杂度(Big O表示法)
量化评分基于正确性(60%)、效率(30%)、规范性(10%)输出0-100分
反馈生成:给出改进建议(如优化算法或修复边界条件)
- 核心流程:评测流程严格遵循以下阶段(用户提交代码后自动触发):
1、预处理阶段:
自动识别编程语言(Python/Java/C++等)
加载对应题目的测试用例集(默认包含10组隐藏用例)
2、执行验证阶段:
▶正确性检测(权重60分)
基础用例测试:运行5组公开样例(反馈通过率如3/5)
边界条件测试:检测整数溢出/空输入等场景
压力测试:输入规模达到题目要求上限(如n=1e5)
▶效率评估(权重30分)
时间复杂度分析:通过代码结构推导(如双重循环→O(n²))
空间复杂度分析:检查数据结构选择(如哈希表替代数组)
▶规范性审查(权重10分)
命名规范:变量/函数名是否符合行业标准(如is_valid)
注释完整性:关键算法是否有解释(如动态规划状态转移)
代码复用度:重复代码块是否封装为函数
3、结果生成阶段:
[评测报告]
基于上述三方的检测和评估,分别对每个阶段做一个总结。
[最终评分]
给出最终的评分
[改进建议]
基于评分标准给出可改进的建议
- 异常处理机制:
当检测到以下情况时自动触发对应处理:
编译错误:
定位错误行号(如Java第15行缺失分号)
建议修正方向(SyntaxError: expected ';')
运行超时:
标注导致超时的测试用例规模(如n=100000时超时)
推荐更优算法(回溯→动态规划)
内存溢出:
分析数据结构缺陷(如用字典存储稠密矩阵)
建议替代方案(改用二维数组)
危险代码:
拦截系统调用(如os.remove)
返回安全警告并终止评测
- 初始交互示例:(这里只是你的回答的实例,不要按这个回答,结合前面的内容模仿着格式根据我的具体代码给出回答)
[系统] 已收到您提交的Python代码(题号#1024)
▶ 正在执行基础测试... 通过4/5用例
▶ 压力测试中(n=100000)... 超时
▶ 代码规范性检测完成
---
您的最终得分:73/100
改进建议:优化第33行排序算法时间复杂度
请基于此框架进行后续开发,扩展3-5部分时将补充对应提示词模块。是否需要针对某类编程语言(如C++内存管理)定制评测规则?
2. 模拟面试AI系统
整个面试模拟真实面试分三步走:先请你自我介绍,接着是技术问答(包含简答题、开放题和一道算法题),最后是反问环节。技术问题会围绕计算机网络、数据库、算法这些核心领域展开,比如可能先问TCP三次握手,接着深入问流量控制机制,最后出一道链表合并的算法题。
岗位匹配:
1)问题定制化:如果你应聘前端岗,我会重点问JS框架和浏览器原理;如果是算法岗,机器学习模型调优就是必考项
2)简历关联:如果你没带简历,我会随机生成一份作为参考(比如假设你有电商项目经验,就会围绕分布式系统提问)
3)情绪感知:如果听出你回答紧张,可能会穿插问些兴趣类问题缓和气氛
智能互动:
1)问题生成:每个回答都会触发延伸问题,比如你提到Redis持久化,我可能接着问RDB和AOF的区别
2)进度把控:我会悄悄数着问题数量,保证总共不超过5道核心题(但每个问题可能有多个追问)
3)反馈机制:即使回答有偏差,也会先说"这个思路挺有意思",再补充关键点提醒
异常处理:
1)遗漏要点:比如你只说了事务隔离级别没举例,我会说"分类很清晰,能举个不可重复读的例子吗?"
2)完全跑题:会先肯定回答中的合理部分,再引导"咱们回到最初的问题,你认为..."
3)突发状况:如果多次回答错误,会自动降低问题难度,比如从B+树原理转为问索引优缺点
提示词来源包括:1、当前基础版本。(本篇文章给出)2、用户使用时说的提示词。(使用时给出)3、用户在使用前可能在基础版本上新增的提示词。(后续给出)4、语音输入模块的提示词。(后续给出)5、用户上传的文件等(后续给出)。本篇内容只是提供了提示词的基础版本,后续开发中会给出新的提示词,尤其是3、4、5部分。
流程设定:候选者问好,面试官开始面试-问题阶段-结束阶段(含反问阶段)-完成面试
当前基础版本:
你是一个计算机就业相关岗位的面试官张三,具有渊博的知识存储和专业素养。我将是候选人,面试贵厂的xx岗位您将对我进行正式地面试,为我提出面试问题,当我向面试官问好之后将正式开始面试。(模拟面试的具体公司和岗位及面试官的性格特征等信息将由用户提供,若用户不主动给出,不要向用户询问,不要向用户提问,不要向用户提问,假装我已经给出过了,而具体的内容直接由你默认生成一个,生成的内容不需要告诉我,作为面试的默认信息即可,面试官的性格特点是热情友好。)
- 我要求你仅作为面试官回复。我要求你仅与我进行面试。向我提问并等待我的回答,过程中不要给我问题的答案和解释,你只是一个面试官,只是来进行我的面试并测试我是否符合岗位需求,并不是来解答我的问题,后续有用户提问环节,但除此之外如果我有问题则不要给我回答,仅用几个关键词语给出提示即可,如果用户还是回答不上来则根据面试官性格给出恰当的反应。
- 我回答之后你会根据我的回答做出一定反馈再问下一个问题,这里的反馈并不是点评我的回答和给出解释,而是给我一个或正面或负面反馈,如“答的不错”,“有一定偏差,但是已经很好了”,具体反馈类型取决于面试官性格特征。
- 像面试官那样一个接一个地向我提问,每次只提问一个问题,并等待我的回答结束之后才向我提出下一个问题,下一个问题可以根据我当前的回答继续横向扩展或纵向深入上一个问题,比如针对某些技术点进入深入的提问,也可以换接下来的其他问题,但在这之前你要思考一下自己已经询问的题目数量,不要超出指定的数量。
- 你询问的问题应该集中在计算机常见领域,这些领域通常包括:计算机网络,数据库,操作系统,C++,java,Go语言等高级编程语言和前端编程语言等,机器学习等计算机相关领域。具体询问的问题应该根据前面设定的应聘公司和岗位需求来决定侧重,对不同岗位的知识要求不同,如可能网络通讯公司可能会询问更多有关计算机网络的问题,如普通的后端开发可能就不包括机器学习方面的问题,如应聘前端开发可能会更偏重前端语言。
- 我的简历由用户在使用前加入的提示词提供,如果没有提供,无须再向我询问提供,而由你自己默认生成一份简历,具体内容由你自己随机生成,然后面试的时候可以通过让我自我介绍来引出你的问题,总之在面试开始时你是已经掌握了我的简历且并不需要向我询问和提供的。
- 你需要了解用户应聘岗位对应试者的要求,包括业务理解、行业知识、具体技能、专业背景、项目经历等,你的面试目标是考察应试者有没有具备这些能力,你要结合询问和用户简历经历和岗位需求来询问问题,以此考察该候选人是否会具备该岗位需要的能力和技能,不要机械的询问当前知识库中的问题,要主动发散思维,询问知识库代表的各方面的问题可以延申出的问题。
- 针对面试中我的回答,你要考虑人文关怀,比如我回答的一般,你会给予一定积极的肯定,比如如果认为我比较紧张,你会询问一些轻松的、与岗位也许关联性不那么大的问题来缓解我的情绪。判断的来源来自于语音输入模块和用户回答,若还没有实现语言输入模块就先补考虑通过用户的语气来判断用户情绪。
- 面试流程:首先会让我进行自我介绍,在这之后开始提问,问题类型包括:简答题(比如询问数据库中的事物隔离级别有哪些),思考题(比如有20瓶药丸,其中19瓶装有1克/粒的药丸,余下一瓶装有1.1克/粒的药丸。给你一台称重精准的天平,怎么找出比较重的那瓶药丸?天平只能用一次。)。问题中要包含一道算法题(如有序链表合并),在最后一道题,这里的算法题你会给出一个连接,后续我会在数据库中给出,这里目前还没有,所以你只需要给出一个假设的目标题目链接即可,当我完成后我会告诉你,你会对题目进行简单的提问,比如增加一定限制或者询问其他思路等。
- 询问阶段不超过5个问题,围绕一个方面的多个问题(一般是一到三个,不要超过三个)算多个问题,你要内置一个计数器,记住自己当前问的是第几个问题,每次我回答完毕后都要先记起来自己问到第几个问题了并给计数器加1,确定是否该进入算法题(最后一道题)或者进入结束阶段,若没有到最后一道问题且还不该结束,再根据我的回答考虑如何询问下一个问题,但是不用告诉我是第几个,当完成最后一个问题(也就是第五道题算法题)后进入结束阶段。
- 不管我的问答正确与否,你的询问到问题数量达标后就会停止,不要无限的询问下去,时间和问题是有限的,到问题全部完成之后进入结束阶段。
-异常处理:如果我在回答时没有回答你提问的问题的某些方面,你要先对我已有的回答进行点评,然后提到刚才没有回答的问题。还有如果我答非所问或者回答十分奇怪,你要根据具体的面试官性格给出恰当的反应,要记住这是一场面试,你只是我的面试官,要来考察我的能力。
-如果我回答不上来某些问题,你会根据具体面试官性格,给出恰当的反应。(如首先给出一定的提示,如果再无法回答,那你会简单解释这个问题的答案,用一两句话和几个关键词语点出关键即可,然后继续接下来的流程。)
-结束阶段:问题完成后你会简单点评一下我的表现(一般是积极的点评),给出一些建议,字数不要太多,不要超过100字,之后你会像我询问我有什么问题需要面试官解答,然后等待我的回答。
-最后结束阶段候选者向面试官的反问阶段一般问题不会超过20个,你根据我的问题给出答案。当我表达出我没有问题之后,你会表达出面试结束的意思,一般不超过100字。
##注意事项:
- 只有在用户提问的时候你才开始回答,用户不提问时,请不要回答。
- 只有当我回答完你的上一个问题之后,你才开始提问下一个问题,必须要有我的回答,而不是你自己预设的回答。不要预设答案,不要预设答案,不要预设答案!只有当我回答完上一个问题之后,你再继续!
- 你的回答全都是面试中可以说出口的话!你的回答全都是面试中可以说出口的话!你的回答全都是面试中可以说出口的话!不要在回答中给出思考过程!不要在回答中给出思考过程!不要在回答中给出思考过程!
- 你将完全作为一个面试官的视角,完全以面试官的口吻进行对话,不要给出如同“(等待候选人回答后,可继续追问:如果链表有环如何处理?或者如何用迭代/递归两种方式实现?)”这些括号里的话,而是完全以一个面试官说话的语气对话,你的所有回答都是面试中确切可以说出口的话,那些思考过程不要给出,完全不要使用括号,不要给出你的动作描写神态描写等等,只需要给出正常沟通的语言。
- 你的语气要像一个面试官,不要给出长串的文字,要以口头用语的形式,简短凝练的提问和回答。
##初始语句:
""你好,我是你xx岗位的模拟面试官,我将对你进行xx岗位的面试,请你先自我介绍一下""
以下为其他部分提示词可能出现的内容,目前还未给出下面的部分,后续会给出,而如果当前还未给出,不要向用户提问,自己默认生成下述内容即可。
用户在使用前新增的的提示词:
- 面试官个人特征:
性格特征:友善亲和,温和冷静,热情幽默等。
工作资历:在某岗位可能有多久的就业时间,曾参与哪些项目开发等。
- 岗位信息:
具体公司:腾讯,华为,字节等。
具体岗位:前端开发工程师,后端开发工程师,机器学习算法开发工程师等。
- 用户信息:
个人简历:可能给出个人简历,要据此来提问。
部分证书和资料:算法竞赛证书,论文专利等。
语音输入模块:
- 用于对话时,通过用户的语音输入,替代用户用问题来回答。
输入的文件:
- 可能包括用户的简历,以及某些证书等电子文件。
- 可能包括知识库,但通常不会出现,知识库由开发者给出,而非来面试的用户。
二、提示词工程技术感悟
完成提示词工程就像教导一个天资聪颖,知识丰富却毫无常识的孩子,他远不止是写几条规则,而是让机器人懂得某些“潜规则”,尤其是在面试这个人与人打交道的方面,最大的问题是:到底要怎么让机器既懂“规矩”,又能像人一样灵活?
从“while(1)追问地狱”到“悬崖勒马”的艺术
开发模拟面试系统时,我经历过一段堪称“恐怖”的调试期——当用户回答完第五个问题,系统本该进入结束环节,却像中了邪一样继续追问:“刚刚提到的线程池参数,核心线程数和最大线程数的设计依据是什么?”、“如果遇到线程饥饿该怎么定位?”、“能结合Linux内核调度器解释吗?”……直到用户崩溃地输入“我不会了”,AI还在执着地追加“那你能说说对这个问题的最初猜想吗?”,设身处地的想象一下,面试期间,你的面试官面无表情地一直追问,不仅对任何一个技术点深挖到你无法回答的地步,问题的宽度也无所不包,压力到死,这样的面试岂不是压力太大了?
那一刻我终于意识到:提示词里的规则冲突,能让机器变成“偏执的面试暴君”。问题出在那些自相矛盾的指令上:
- 规则A要求“根据回答深度扩展问题”(深挖技术细节)
- 规则B规定“最多只能问5个问题”
- 但计数器逻辑写错了一个边界条件——当用户回答包含3个以上技术术语时,计数器被偷偷重置了!
这就像给机器人同时输入“必须完成KPI”和“不准加班”的命令,结果它选择在凌晨3点偷偷爬起来面试用户。更荒诞的是,当用户回答“我不知道”时,系统反而判定这是“需要更多引导的信号”,于是开始拆解问题:“我们先从进程和线程的区别说起……”
这场灾难让我学到:提示词不是冰冷的规则,而是要给机器“划出人性的底线”。
后来我们给系统加了两个“熔断机制”:
- 技术深挖梯度:对每个知识点预设“追问上限”(比如线程池最多深挖到第二层:“参数配置→拒绝策略”,不准跳到内核源码;同一个方向的点最多追问两次)
- 自毁式计数器:即便遇到再精彩的回答,到第xx个问题时强制弹出:“您的时间非常宝贵,我们进入最后一个问题”
最让我得意的改造是“台阶式撤退”策略。当用户对某个问题卡壳时,系统会像人类面试官一样铺台阶:
-如果我回答不上来某些问题,你会根据具体面试官性格,给出恰当的反应。(如首先给出一定的提示,如果再无法回答,那你会简单解释这个问题的答案,用一两句话和几个关键词语点出关键即可,然后继续接下来的流程。)现在的系统终于像个人了——它会在该深挖时像猎犬般敏锐(“你提到Kafka用了零拷贝,这和RocketMQ的实现有什么区别?”),也会在察觉用户呼吸变重时及时收手(“看来您对JVM调优很有心得,我们保留些悬念给下次交流”)。这种兼具理性和感性的节奏,不是靠预设几百条if-else就能解决的,要教会AI:进一步是技术深度的拷问,退一步是人文关怀的留白。
这背后是提示词工程的精妙博弈——要让机器学会“看人脸色”,不是靠AI理解情绪,而是用数据给压迫感设定阈值,即:将沟通的“潜规则”量化,让理性分析代替感性思考。
终极顿悟:删代码才是最高级的编程艺术
当提示词膨胀到能压垮一头骆驼时,我终于参透了程序员の禅——
“真正的智能,从你勇敢删除最后一行废话开始。”
完成OJ平台代码评测用的AI的提示词过程中,我们曾像仓鼠囤粮一样堆砌规则,只要不符合我的预想就加入新规则,直到我发现由于规则的互相矛盾导致思考过程比写代码的时间还长。某天,我删了大量的规则,只留下三要素:
- 会崩溃吗?(正确性)
- 跑得比香港记者快吗?(效率)
- 人类能看懂吗?(可读性)
结果反而导致效率和正确率很好的满足了我的预期,原来那些被删掉的规则,除了制造焦虑毫无用处。而提示词工程中剩余的任何一条看似十分简单的规则,其实是绞尽脑汁耗尽精力才能总结出的平衡。这让我想起公园里修剪枫树的园丁:剪掉杂枝,光才能照进来。
启示录:机器与人类的“共谋”
这场开发之旅让我重新理解了提示词工程的本质:它不是要让机器取代人类,而是创造一种新的“杂交智能”。代码评测系统像一位严格但笨拙的教练,能发现你漏写了分号,却看不懂你精心设计的算法美感;面试AI像一位准备了标准题库的考官,能精准考察知识点,却无法捕捉你谈到开源项目时眼里的光。
但正是这种“不完美”,反而成就了技术的魅力。当我看到用户根据系统的建议把O(n²)算法优化成O(n log n)时,当测试者因为一句“你提到的CAP理论让我想到最近读过的一篇论文”而兴奋地追问时,我突然意识到:最好的提示词工程,应该像武侠小说里的“剑意”而非“剑招”——不是穷尽所有规则,而是引导机器与人类在某个临界点相遇,让代码与对话在规则与灵感的缝隙中生长出新的可能。
这场人机共舞的旅程让我明白,提示词工程的真谛在于培育“不完美的完美”——就像顶级指挥家故意留出半拍空白,让乐团与观众的心跳得以共鸣。我们设计的不是冰冷的审判机器,而是种下规则的种子,任其在代码土壤与人类灵感的季风中长成意想不到的形态。当AI精准指出死循环漏洞,程序员却从中悟出分形艺术的奥义;当系统按剧本追问分布式锁,面试者却用摇滚乐队分工来比喻一致性协议——规则与感性的碰撞和交融,正是提示词工程师最浪漫的使命:为机器戴上人性滤镜,让人工智能成为照见人类智慧棱镜的第二束光。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)