[PyQt5+深度学习]人脸+音频防伪检测系统
基于PyQt5+神经网络模型的视频&音频防伪检测
本系统参考了Qt+Yolo实时目标检测(带美化Gui界面和高帧率检测)(附带代码)
博客。
在上面的基础上结合自己项目的需求进行了改进:
1.增加了伪造音频检测
2.将目标检测改造为防伪检测
3.丰富了输出框的内容
4.增加了批量检测的功能
5.界面进行了优化
首先来看看系统长啥样吧!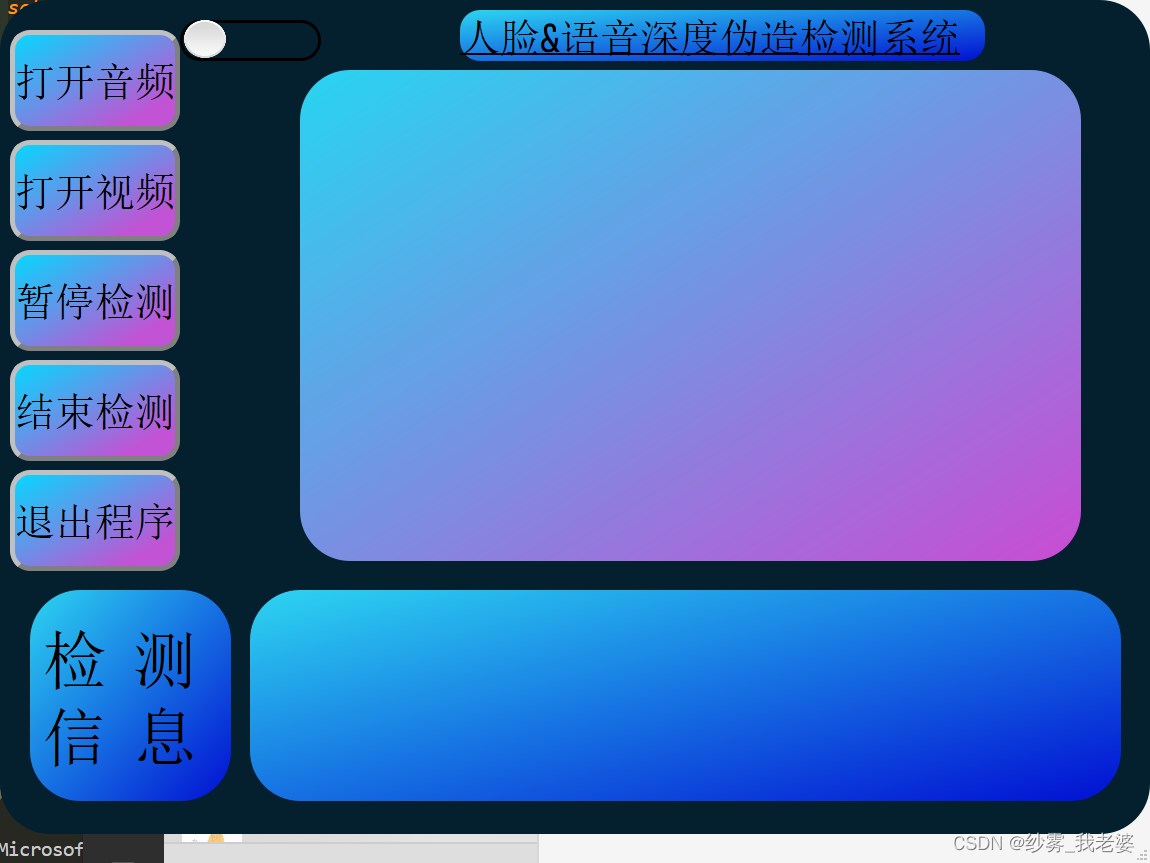
功能实现:
1.音频防伪检测: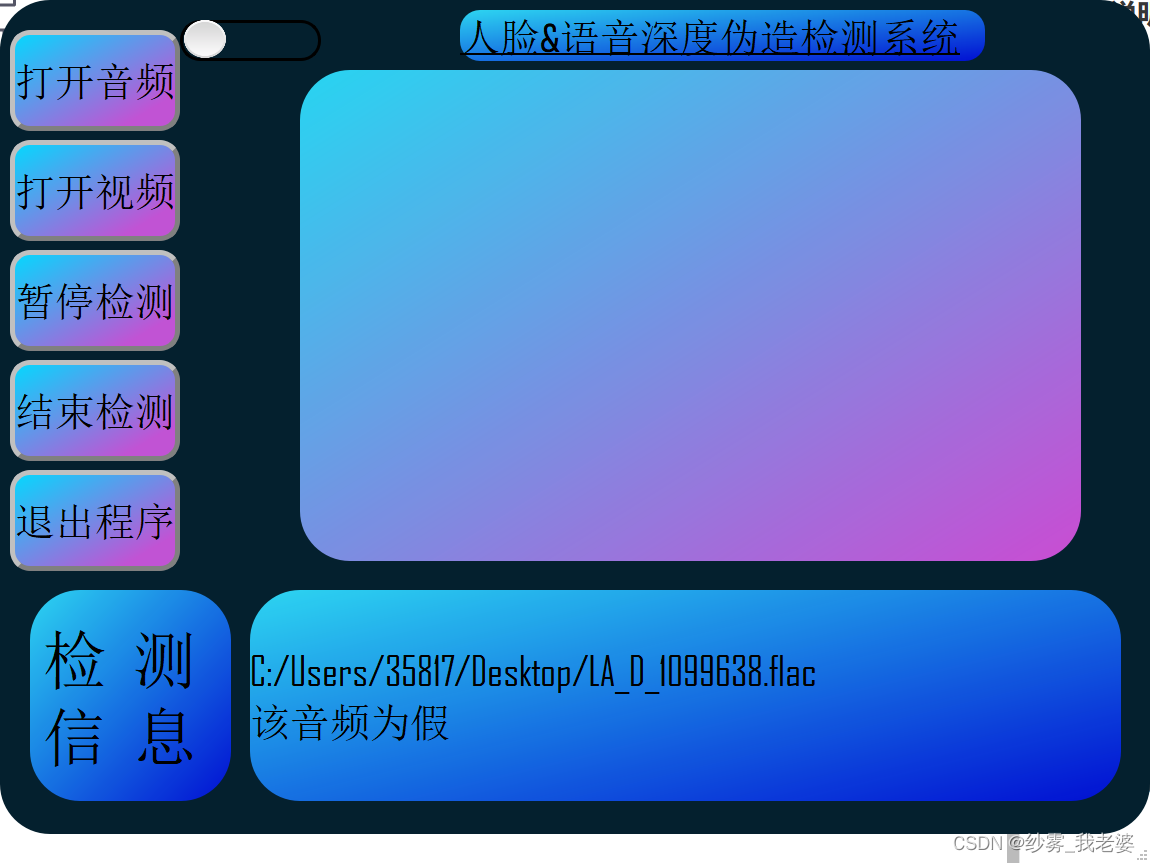
2.视频防伪检测
3.模型准确率测试
在打开音频中选中所有测试文件
同理可以检测视频准确率
代码讲解
代码结构:
|——ReadMe.md //帮助文档
|——dataset
| |——mydataset.py //构建自己数据集
| |——transform.py //对图片进行操作
|——Lib
| |——QRC_rc.py //编译文件,不要动
| |——UI_From.py //设计GUI界面
|——network
| |——mesonet.py //网络模型
| |——models.py //网络模型
| |——xception.py //网络模型
|——test
| |——LA_D_1099638.flac //测试文件
| |——test.mp4 //测试文件
|——weights
| |——model2.pth //人脸检测模型权重
| |——Res_TSSDNet…4%.pth //音频检测模型权重
|——Audio_detect.py //检测音频
|——data //音频数据操作
|——Face_detect.py //人脸检测
|——models.py //音频检测模型文件
|——Main.py //主函数
环境配置:
pytorch
opencv
PyQt5
matplotlib
soundfile
dlib
PIL
pandas
改造思想:
1.本项目继承了源代码多线程的思想,不然在检测时会出现界面卡死的情况
2.源代码是检测视频的,因此采用了QTimer计时器,来对每一帧进行检测。但本项目由于涉及到检测音频,只用检测一次就行,因此需要对定时器进行暂停操作,不然程序会一直检测同一个音频。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)