[论文阅读]KD——神经网络中的知识提取(知识蒸馏)
Distilling the Knowledge in a Neural Network
神经网络中的知识提取
论文网址:KD
摘要
提高几乎任何机器学习算法性能的一个非常简单的方法是在相同的数据上训练许多不同的模型,然后对它们的预测进行平均[Ensemble methods in machine learning]。 不幸的是,使用整个模型集合进行预测是很麻烦的,而且计算开销太大,不允许部署到大量用户,尤其是如果单个模型是大型神经网络。 [Model compression]已经表明,将集合中的知识压缩到一个更容易部署的单一模型是可能的,本文使用不同的压缩技术进一步发展了这种方法。 本文在MNIST上取得了一些令人惊讶的结果,并表明可以通过将模型集合中的知识提取到单个模型中来显著地改进大量使用的商业系统的声学模型。 本文还引入了一种新的集合,由一个或多个完整模型和许多专业模型组成,它学习区分完整模型所混淆的细粒度类。 与混合专家不同,这些专家模型可以快速并行地训练。
论文中提到完整模型(full model)会混淆一些细粒度的类别(fine-grained classes),比如:
完整模型可以区分汽车和胡萝卜,但可能会混淆宝马和奔驰这些细粒度的汽车品牌。
完整模型可以区分数字,但可能会混淆数字2和3这些细微不同的手写体。
也就是说,完整模型可以进行一些高层的区分,但在一些细粒度的类别上可能会错误,这些细粒度类别对完整模型来说是易混淆的。
为了改进在这些细粒度类别上的表现,论文提出训练一些专家模型(specialist models),让每个专家模型只专注于一组易混淆的细粒度类别,而不关心其他类别。这可以提高在这些细粒度类别上的识别准确率。
所以“完整模型所混淆的细粒度类”指的是对完整模型来说易混淆的一些细分类别,需要训练专家模型来专门区分。
引言
许多昆虫的幼虫形态是为了从环境中获取能量和养分,而成虫形态则完全不同,是为了满总旅行和繁殖等截然不同的要求。在大规模机器学习中,通常在训练阶段和部署阶段使用非常相似的模型,尽然它们的要求截然不同:对于语音识别和物体识别等任务,训练必须从非常庞大、高度冗余的数据集中提取结构,但不需要实时运行,而且可能使用大量计算资源。然而,向大量用户部署系统对延迟和计算资源的要求严格得多。与昆虫的类比表明,如果能更容易地从数据中提取结构,应该愿意训练非常繁琐的模型。繁琐的模型可以是一个由单独训练的模型组成的集合,也可以是一个由非常强的正则化器(如dropout)训练的单一大型模型[Dropout:A simple way to prevent neural networks from overfitting.]。一旦繁琐模型训练完成,就可以使用另一种训练方式,称之为"蒸馏",将繁琐模型中的知识转移到更适合部署的小型模型中。[Model compression]已经开创了这种策略的一个版本。在他们的论文中,已经证明了从一个大型模型集合中获得的知识可以转移到一个单一的小型模型中。
对这一非常有前途的方法进行更多研究的一个概念性障碍是,倾向于将训练过的模型中的知识于学习到的参数值联系起来,这使得研究者很难理解如何改变模型的形式而保持相同的知识。对知识的一种更抽象的看法是,它是一种学习到的知识,可以从任何特定的实例化中解脱出来,从输入向量到输出向量的映射。对于学习区分大量类别的复杂模型来说,正常的训练目标是最大化正确答案的平均对数概率,但学习的一个副作用是,训练好的模型会给所有错误答案分配概率,即使这些概率很小,其中的一些也比其他答案大得多。错误答案的相对概率可以让我们了解这个复杂模型是如何趋向于泛化的。例如:轿车的图像被误认为垃圾车的概率非常小,但这一错误概率仍然比被误认为胡萝卜的概率高很多。
一般认为,用于训练的目标函数应尽可能地反映用户的真实目标。尽管如此,模型的训练通常是为了优化训练数据的性能,而真正的目标是对新数据进行良好的泛化。显然,训练模型使其具有良好的泛化能力会更好,但这需要关于正确泛化方式的信息,而这种信息通常是不可用的。不过,将大模型中的知识提炼成小模型是,可以训练小模型,使其泛化方式与大模型相同。举例说明:如果复杂模型的泛化效果很好,因为它是一个大型不同模型集合的平均值,那么在测试数据上,以同样方式训练泛化的小模型,通常会比在用于训练集合的相同训练集上以正常方式训练的小模型好很多。
将复杂模型的泛化能力转移到小模型的一个显而易见的方法是将复杂模型产生的类概率作为训练小模型的“软目标”。在这个转移阶段,可以使用同一个训练集,也可以使用一个单独的“转移”集。当复杂模型是一个由较简单模型组成的大型集合时,可以使用它们各自预测分布的算术平均值或几何平均值作为软目标。当软目标的熵值较高时,它们为每个训练案例提供的信息要比硬目标多得多,而且训练案例之间的梯度方差也要小得多,因此小型模型通常可以用比原始复杂模型少得多的数据进行训练,而且学习率也要高得多。
硬目标(hard targets)和软目标(soft targets)指的是神经网络训练时使用的目标表示形式。
软目标:每个训练样本对应多个类别,使用类别的概率分布表示。比如[0.1, 0.1, 0.7, 0.05, 0.03, 0.01, …]。软目标包含了更丰富的信息,可以指导模型更好地泛化。
硬目标:每个训练样本只对应一个正确的类,使用one-hot编码表示。比如如果有10个类别,正确类别使用[0,0,1,0,0,0,0,0,0,0]表示。
硬目标简单和高效,但信息量有限。软目标信息量大,能更好表示样本之间的关系,指导模型泛化,但计算更复杂。
对于像MNIST这样的任务,复杂的模型几乎总是能以极高的置信度得出正确答案,因此有关所学函数的大部分信息都存在于软目标中的极小概率比率中。例如,一个版本的2可能有10负6次方的概率是3,有10负9次方的概率是7,而另一个版本的概率可能正好相反。这些宝贵的信息为数据定义了丰富的相似性结构(即哪些2看起来像3,哪些看起来像7),但在转移阶段,这些信息对交叉熵成本函数的影响非常小,因为概率非常接近于零。有一种方法是,通过使用对数(最终softmax的输入)而不是softmax产生的概率作为学习小模型的目标来规避这个问题,这样最大限度地减少了复杂模型产生的对数与小模型产生的对数之间的平方差。本文更普遍的解决方案称为“蒸馏”,即提高最终softmax的温度,直到复杂模型产生一组适当的软目标。然后,在训练小模型时使用相同的高温来匹配这些软目标。匹配复杂模型的对数实际上是蒸馏的一个特例。
用于训练小模型的转移集可以完全由无标记数据组成,也可以使用原始训练集。本文发现,使用原始数据集的效果更好,尤其是如果在目标函数中添加一个小项,鼓励小模型预测真实目标,并与复杂模型提供的软目标相匹配。通常情况下,小模型无法完全匹配软目标,而向正确答案的方向偏移会有所帮助。
蒸馏
神经网络通常通过使用“softmax”输出层来生成类别概率,该层通过将Zi与其他对数进行比较,将为每个类别计算的对数Zi转换类概率Qi: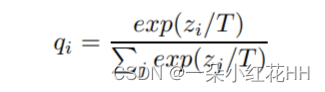
其中T是一个温度值,通常设为1。使用较高的T值会产生较柔和的类别概率分布。
在最简单的蒸馏法中,通过在转移集上对蒸馏模型进行训练,并为转移集中的每个案例使用软目标分布,将知识转移到蒸馏模型中。在训练蒸馏模型时,也会使用同样的高温,但在训练完成后,会使用T=1的温度。
当已知全部或部分转移集的正确标签时,还可以通过训练蒸馏模型来生成正确标签,从而大大改进这种方法。一种方法是,使用正确的标签来修改软目标,但更好的方法是简单的使用两个不同目标函数的加权平均和。第一个目标函数是与软目标的交叉熵,交叉熵的计算方法与从复杂模型生成软目标时使用的方法相同,都是在蒸馏模型的softmax中使用高温(大的T)。第二个目标函数是正确标签的交叉熵。在第二个目标函数上使用较低的权重通常能获得最佳结果。由于软目标产生的梯度大小随1/T的2次方而变化,因此在同时使用硬目标和软目标时,必须将它们乘以T的二次方。这样可以确保在实验元参数时,如果改变蒸馏温度,硬目标和软目标的相对贡献基本保持不变。
第一个损失函数是小模型输出的softmax概率分布与大模型软目标概率分布之间的交叉熵。第一个部分让小模型拟合大模型的软目标分布,进行知识迁移。
第二个损失函数是小模型输出与真实one-hot标签之间的交叉熵。第二个部分让小模型拟合真实标签,进行正常的分类训练。
小模型不可能完美拟合软目标,保留一定比例的真实标签损失可以更好地防止误差累积。
匹配对数是蒸馏的一个特例
相对于蒸馏模型的每个对数Zi,转移集中的每个案例都会产生一个交叉熵梯度。如果复杂模型的对数Vi,产生软目标概率Pi,且转移训练是在温度为T的条件下进行的,则该梯度由一下公式给出: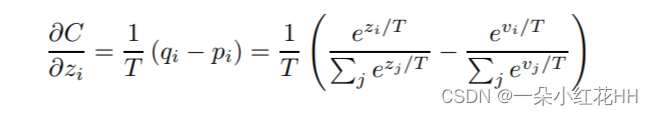
如果温度与对数的大小相比较高,则可以近似计算:
如果现在假设每种转移情况的对数都分别进行了零点校正,那么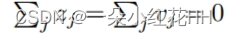
上述公式可以简化为: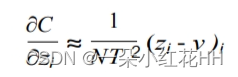
因此在高温极限下,蒸馏相当于最小化 1/2(zi − vi)的二次方,前提是每个转移情况下的对数分别进行零均值化。在较低温度下,蒸馏法对匹配负值远大于平均值的对数的关注要少得多。这样做有潜在优势,因为这些对数几乎完全不受用于训练复杂模型的成本函数的限制,因此可能会非常嘈杂。另一方面,非常负的对数可能会传递有关复杂模型所获知识的有用信息。究竟哪种效应占主导地位是一个经验问题。实验表明,当蒸馏模型太小而无法捕捉到复杂模型中的所有知识时,中间的温度效果最好,这有力的说明忽略大的负对数是有帮助的。
结论
这篇论文主要研究了知识蒸馏(knowledge distillation)的方法,以实现从大型模型向小型模型的知识迁移。主要内容和结论如下:
- 知识蒸馏的思想是先训练一个大型的教师模型(ensemble或加正则的单模型),然后使用这个模型在软目标上训练一个小型的学生模型,从而让小模型获取教师模型的预测能力。
- 软目标包含类别分布信息,而不仅是one-hot标签,可以更好表示样本间的关系,指导小模型泛化。软目标通过在教师模型使用高温度softmax获得。
- 在训练小模型时,联合使用软目标的交叉熵损失和真实标签的交叉熵损失,可以更好地迁移知识并防止误差累积。软目标的权重通常更大。
- 实验结果显示,该方法可以有效将教师模型集成的改进迁移到小模型中,即使小模型架构不同或训练集不完整。
- 对于超大型数据集,可以训练多个专家模型,专注于易混淆的细粒度类别,以提高性能并行训练。
- 软目标也可以作为正则项,帮助使用极少数据防止专家模型过拟合。
总体而言,知识蒸馏让小模型可以获取教师模型的知识,是模型压缩与迁移的有效技术。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)