transformers库使用实例
使用 transformers 库实现文本分类任务可以直接使用 transformers 中对应任务的 pipeline ,但是为了理解 transformers 中对应各个环节的细节,还是使用自己封装 pipeline 的方法实现。
·
使用 transformers 库实现文本分类任务
可以直接使用 transformers 中对应任务的 pipeline ,但是为了理解 transformers 中对应各个环节的细节,还是使用自己封装 pipeline 的方法实现。
Step1 导包
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
Step2 加载数据集
dataset = load_dataset("csv", data_files="./ChnSentiCorp_htl_all.csv", split="train")
# 从本地数据集加载
dataset = dataset.filter(lambda x: x["review"] is not None)
# filter函数用于过滤数据集,这里将空数据滤出掉
dataset
![![[Pasted image 20230829095408.png]]](https://i-blog.csdnimg.cn/blog_migrate/38ac2279f0154d6c476b54d53a1a8e7b.png)
Step3 划分数据集
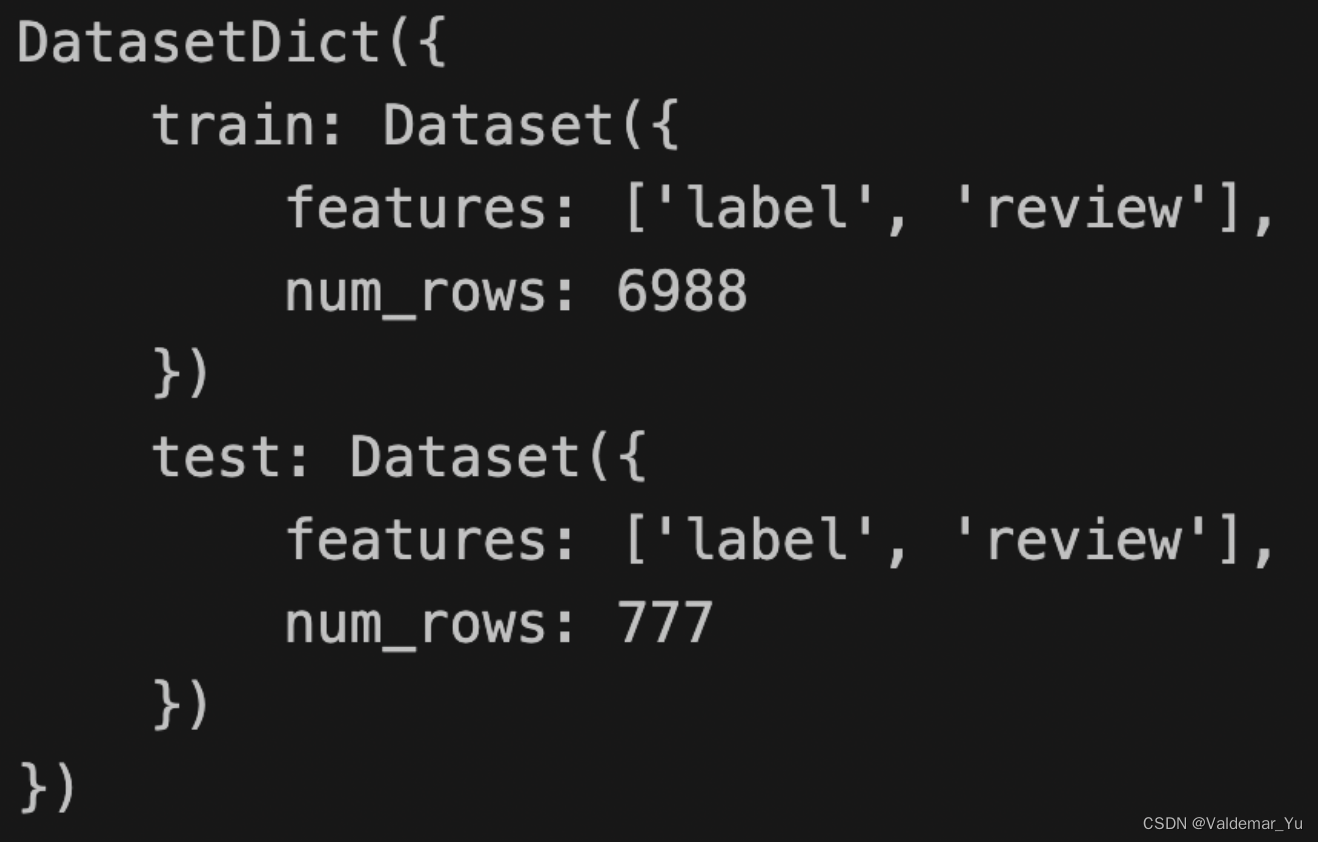
datasets = dataset.train_test_split(test_size=0.1)
# train_test_split(test_size=x)函数将数据集按比例划分,这里test占总数据的10%,test_size只能用小数形式
datasets
```python
![[Pasted image 20230829095732.png]]
## Step4 数据集处理
```python
import torch
tokenizer = AutoTokenizer.from_pretrained("hfl/rbt3")
# 从hugging face加载预训练模型 rbt3 的分词方法,参数使用hugging face的模型地址即可
def process_function(examples):
# 定义处理函数,后续直接使用map进行处理
tokenized_examples = tokenizer(examples["review"], max_length=128, truncation=True)
# 处理 ‘review’列,maxlength为128,过长进行截断
tokenized_examples["labels"] = examples["label"]
# labels 列不进行处理
return tokenized_examples
tokenized_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)
# 使用map对数据集所有数据进行处理,使用批处理方式,移除训练集的列名称
tokenized_datasets
有些时候会出现hugging face连接不上的情况,科学上网多尝试几次,实在不行可以将预训练模型下载到本地,采用本地的方式载入模型。
接下来几步但凡涉及从网站加载的内容都容易受网络影响,多科学上网尝试几次即可。
Step4 数据集处理
import torch
tokenizer = AutoTokenizer.from_pretrained("hfl/rbt3")
# 从hugging face加载预训练模型 rbt3 的分词方法,参数使用hugging face的模型地址即可
def process_function(examples):
# 定义处理函数,后续直接使用map进行处理
tokenized_examples = tokenizer(examples["review"], max_length=128, truncation=True)
# 处理 ‘review’列,maxlength为128,过长进行截断
tokenized_examples["labels"] = examples["label"]
# labels 列不进行处理
return tokenized_examples
tokenized_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)
# 使用map对数据集所有数据进行处理,使用批处理方式,移除训练集的列名称
tokenized_datasets
有些时候会出现hugging face连接不上的情况,科学上网多尝试几次,实在不行可以将预训练模型下载到本地,采用本地的方式载入模型。
接下来几步但凡涉及从网站加载的内容都容易受网络影响,多科学上网尝试几次即可。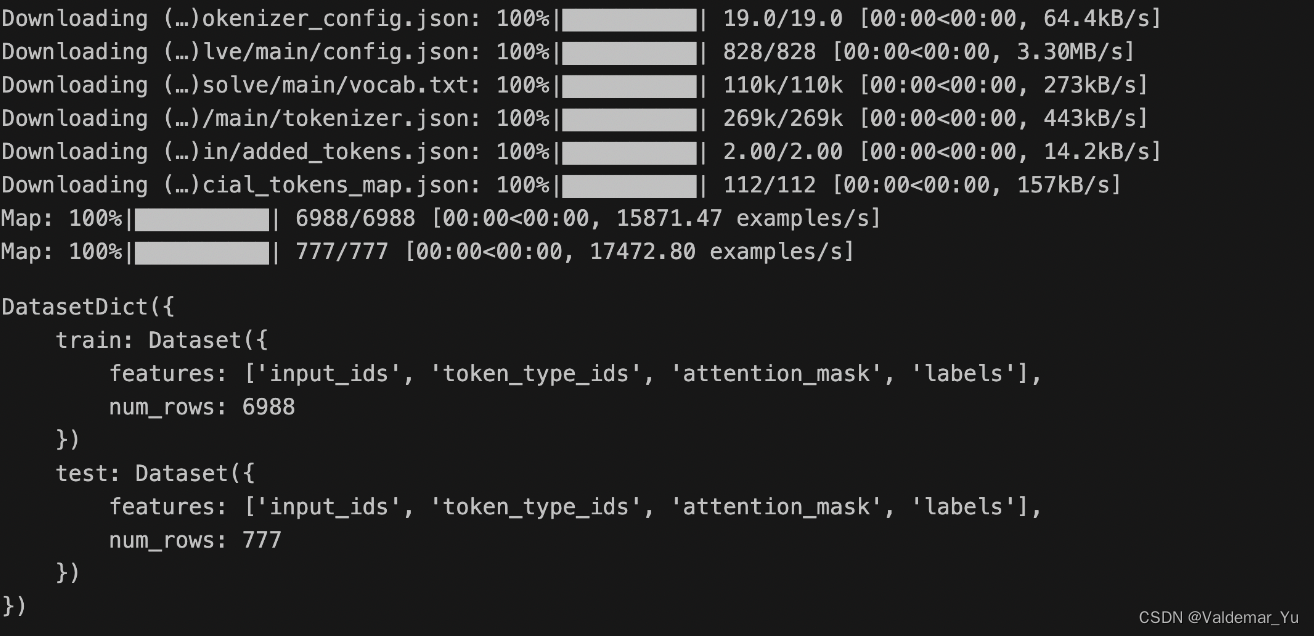
Step5 创建模型
model = AutoModelForSequenceClassification.from_pretrained('hfl/rbt3')
![![[Pasted image 20230829103756.png]]](https://i-blog.csdnimg.cn/blog_migrate/ff6e48b66dafe589c32cbc59a864adfa.png)
Step6 创建评估函数
import evaluate
acc_metric = evaluate.load("accuracy")
f1_metirc = evaluate.load("f1")
# 加载 accuracy 和 f1 作为评估函数
如果没有安装 sklearn 的话需要提前安装!pip install -U scikit-learn

def eval_metric(eval_predict):
# 定义评估函数
predictions, labels = eval_predict
# 将真实值和预测值传入
predictions = predictions.argmax(axis=-1)
# 在最后一个维度,将最大值对应的index返回给predictions
acc = acc_metric.compute(predictions=predictions, references=labels)
f1 = f1_metirc.compute(predictions=predictions, references=labels)
# 计算acc和f1值
acc.update(f1)
# 用f1来更新acc,这样的metrics可以同时兼顾准确率和召回率
return acc
Step7 创建 TrainingArguments
train_args = TrainingArguments(output_dir="./checkpoints", # 输出文件夹
per_device_train_batch_size=64, # 训练时的batch_size
per_device_eval_batch_size=128, # 验证时的batch_size
logging_steps=10, # log 打印的频率
evaluation_strategy="epoch", # 评估策略
save_strategy="epoch", # 保存策略
save_total_limit=3, # 最大保存数
learning_rate=2e-5, # 学习率
weight_decay=0.01, # weight_decay
metric_for_best_model="f1", # 设定评估指标
load_best_model_at_end=True) # 训练完成后加载最优模型
train_args
![![[Pasted image 20230829111407.png]]](https://i-blog.csdnimg.cn/blog_migrate/72ba69dea07005c2eb7e97d2a5e14530.png)
Step8 创建 Trainer
from transformers import DataCollatorWithPadding
trainer = Trainer(model=model,
args=train_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
data_collator=DataCollatorWithPadding(tokenizer=tokenizer),
compute_metrics=eval_metric)
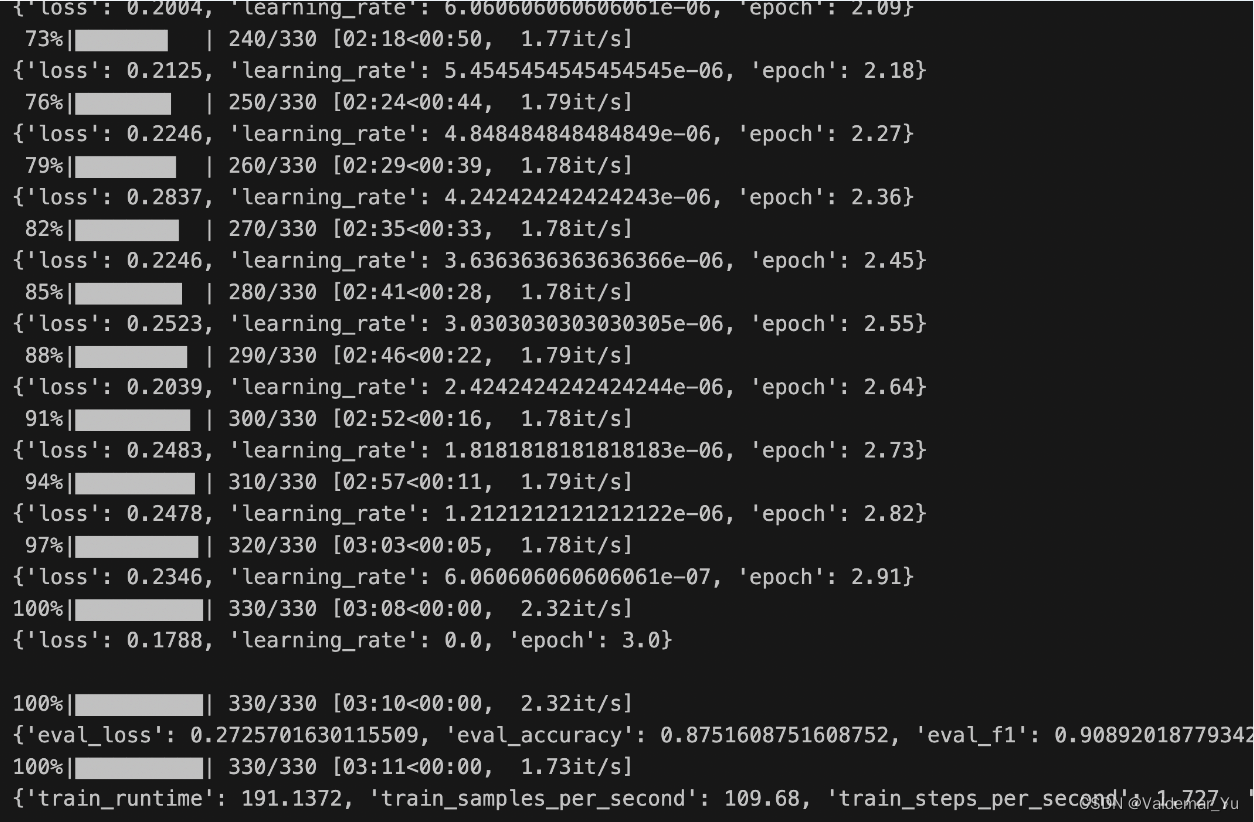
Step9 模型训练
trainer.train()
Step10 模型评估
trainer.evaluate(tokenized_datasets["test"])
使用测试集进行测试,评估模型准确性![![[Pasted image 20230829121841.png]]](https://i-blog.csdnimg.cn/blog_migrate/5896a2dca0ce4192345f71b1fc7d8fd5.png)
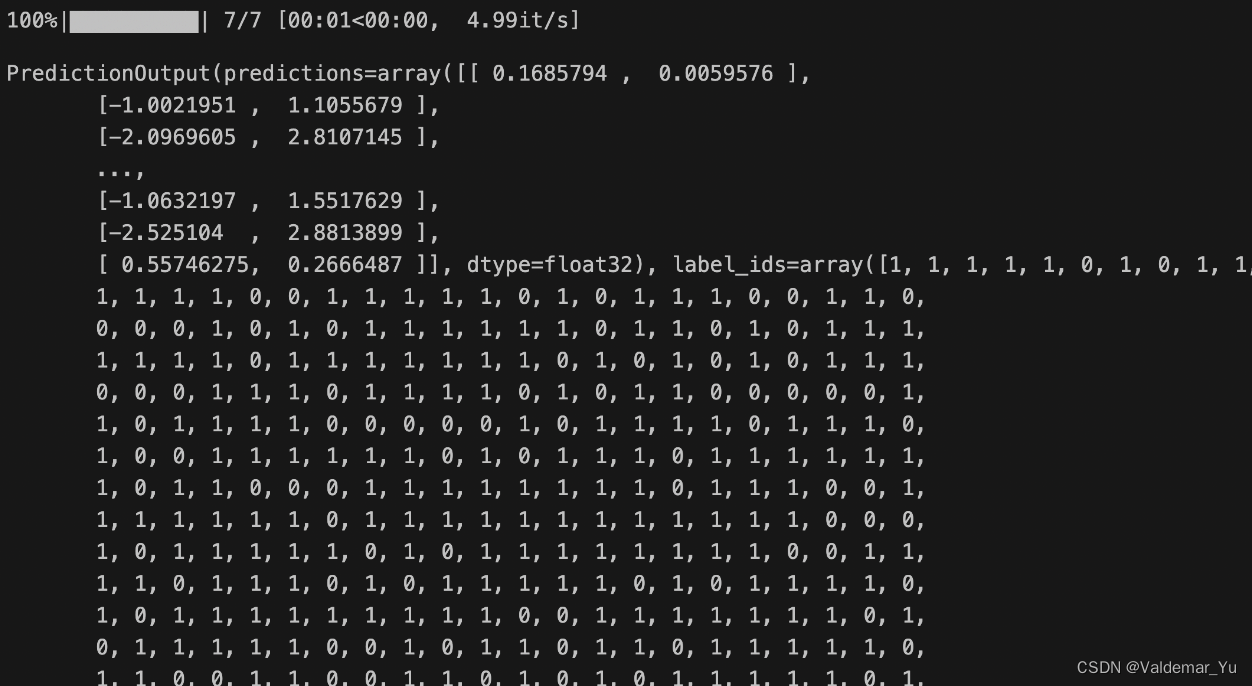
Step11 模型预测
trainer.predict(tokenized_datasets["test"])

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)