修复从Ollama导出的配置文件存在乱码的问题,解决离线导入GGUF模型文件进入Ollama的问题
因为需要离线部署测试模型,但又不知道怎么写Ollama创建模型时用的Modelfile,可以先在外网利用Ollama的pull功能加载模型,然后就会自动在存放模型文件的“blobs”文件夹下,你可以用记事本打开一些小体积的文件,就会发现里面有配置信息,但是这个格式不是我需要的Modelfile的格式。3:接下来有个坑,你用记事本打开这个导出的模型文件,会发现部分乱码。4:为了解决乱码问题,不得已借
因为需要离线部署测试模型,但又不知道怎么写Ollama创建模型时用的Modelfile,可以先在外网利用Ollama的pull功能加载模型,然后就会自动在存放模型文件的“blobs”文件夹下,你可以用记事本打开一些小体积的文件,就会发现里面有配置信息,但是这个格式不是我需要的Modelfile的格式。于是可以从Ollama导出标准配置文件。
导出配置文件方法:
1:使用命令查看有哪些模型已经创建,获取标准名称。
ollama list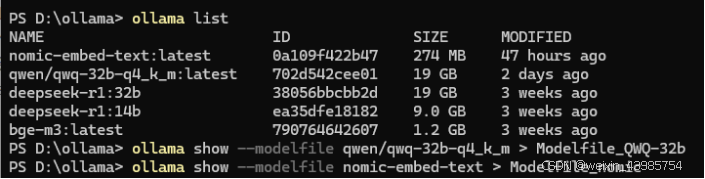
2:使用命令导出指定模型配置文件(参考上图)。
ollama show --modelfile 模型名称 > 保存的配置文件名
3:接下来有个坑,你用记事本打开这个导出的模型文件,会发现部分乱码。如下图:
4:为了解决乱码问题,不得已借助AI写了个解析/替换乱码的程序。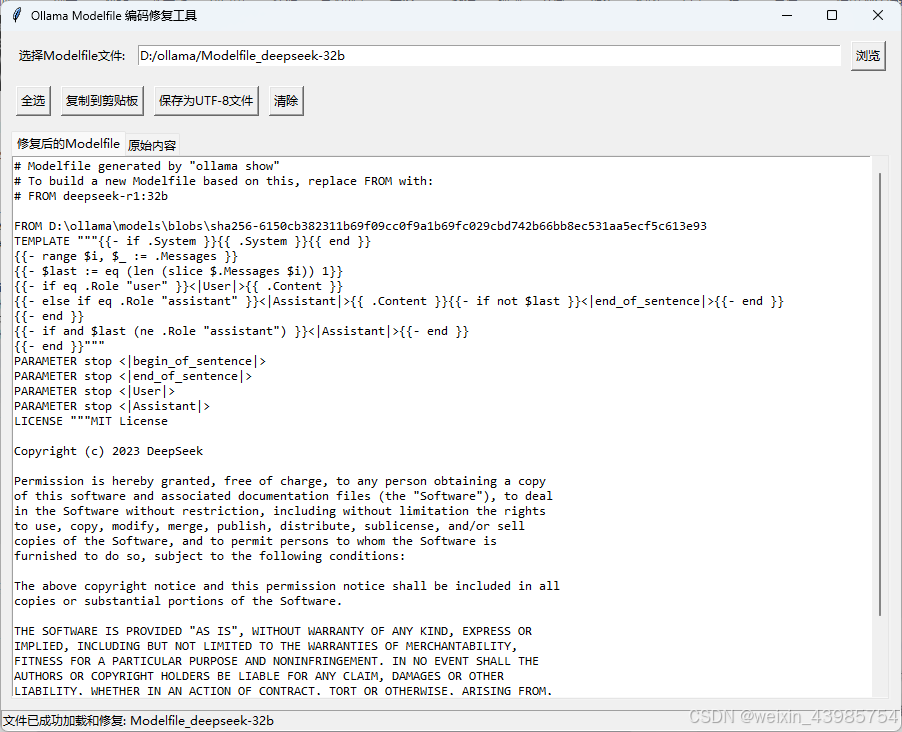
目前该程序只能解决常见的几个乱码问题,不能解决中文字符乱码的问题(主要是我也不知道标准Modelfile怎么写,没有标准还原后的格式,也就推不出应该怎么还原),但这个问题不大,因为你可以从“blobs”文件夹下找到对应中文系统设定词(那些小体积的文件用记事本打开,挨个找,总找得到)。
转换程序源码如下:
import tkinter as tk
from tkinter import filedialog, scrolledtext, messagebox, ttk
import os
import re
class OllamaModelfileConverter:
def __init__(self, root):
self.root = root
self.root.title("Ollama Modelfile 编码修复工具")
self.root.geometry("900x700")
self.root.minsize(700, 500)
self.raw_content = None
self.setup_ui()
def setup_ui(self):
# 顶部框架 - 文件选择
top_frame = tk.Frame(self.root, pady=10)
top_frame.pack(fill=tk.X, padx=10)
tk.Label(top_frame, text="选择Modelfile文件:").pack(side=tk.LEFT, padx=5)
self.file_path_var = tk.StringVar()
tk.Entry(top_frame, textvariable=self.file_path_var, width=50).pack(side=tk.LEFT, padx=5, fill=tk.X, expand=True)
tk.Button(top_frame, text="浏览", command=self.browse_file).pack(side=tk.LEFT, padx=5)
# 按钮框架
button_frame = tk.Frame(self.root, pady=5)
button_frame.pack(fill=tk.X, padx=10)
tk.Button(button_frame, text="全选", command=self.select_all).pack(side=tk.LEFT, padx=5)
tk.Button(button_frame, text="复制到剪贴板", command=self.copy_text).pack(side=tk.LEFT, padx=5)
tk.Button(button_frame, text="保存为UTF-8文件", command=self.save_as_utf8).pack(side=tk.LEFT, padx=5)
tk.Button(button_frame, text="清除", command=self.clear_text).pack(side=tk.LEFT, padx=5)
# 文本区域 - 使用Notebook创建多标签页
self.notebook = ttk.Notebook(self.root)
self.notebook.pack(fill=tk.BOTH, expand=True, padx=10, pady=10)
# 转换后内容标签页
converted_frame = tk.Frame(self.notebook)
self.notebook.add(converted_frame, text="修复后的Modelfile")
self.text_area = scrolledtext.ScrolledText(converted_frame, wrap=tk.WORD, font=("Consolas", 10))
self.text_area.pack(fill=tk.BOTH, expand=True)
# 原始内容标签页
original_frame = tk.Frame(self.notebook)
self.notebook.add(original_frame, text="原始内容")
self.original_text_area = scrolledtext.ScrolledText(original_frame, wrap=tk.WORD, font=("Consolas", 10))
self.original_text_area.pack(fill=tk.BOTH, expand=True)
# 状态栏
self.status_var = tk.StringVar(value="准备就绪")
status_bar = tk.Label(self.root, textvariable=self.status_var, bd=1, relief=tk.SUNKEN, anchor=tk.W)
status_bar.pack(side=tk.BOTTOM, fill=tk.X)
# 绑定快捷键
self.text_area.bind("<Control-a>", self.select_all)
self.text_area.bind("<Control-A>", self.select_all)
self.original_text_area.bind("<Control-a>", self.select_all)
self.original_text_area.bind("<Control-A>", self.select_all)
def browse_file(self):
file_path = filedialog.askopenfilename(
title="选择Modelfile文件",
filetypes=[("所有文件", "*.*"), ("Modelfile", "Modelfile*")]
)
if file_path:
self.file_path_var.set(file_path)
self.load_and_fix_modelfile(file_path)
def load_and_fix_modelfile(self, file_path):
try:
# 读取文件数据
with open(file_path, 'rb') as f:
data = f.read()
# 首先尝试UTF-16LE编码(带BOM标记)
if data.startswith(b'\xff\xfe'):
original_content = data.decode('utf-16-le')
self.status_var.set("检测到UTF-16LE编码")
elif data.startswith(b'\xfe\xff'):
original_content = data.decode('utf-16-be')
self.status_var.set("检测到UTF-16BE编码")
else:
# 如果没有BOM,尝试不同的编码
encodings = ['utf-8', 'utf-16-le', 'utf-16-be', 'gbk', 'gb18030']
for encoding in encodings:
try:
original_content = data.decode(encoding)
self.status_var.set(f"使用{encoding}编码成功")
break
except UnicodeDecodeError:
continue
else:
# 如果所有编码都失败,使用utf-16-le并替换错误字符
original_content = data.decode('utf-16-le', errors='replace')
self.status_var.set("使用UTF-16LE编码处理(包含替换字符)")
# 显示原始内容
self.original_text_area.delete(1.0, tk.END)
self.original_text_area.insert(tk.END, original_content)
# 修复Ollama特殊标记
fixed_content = self.fix_ollama_special_tags(original_content)
# 显示修复后的内容
self.text_area.delete(1.0, tk.END)
self.text_area.insert(tk.END, fixed_content)
# 保存用于保存的内容
self.raw_content = fixed_content
self.status_var.set(f"文件已成功加载和修复: {os.path.basename(file_path)}")
except Exception as e:
messagebox.showerror("错误", f"处理文件时发生错误: {str(e)}")
self.status_var.set("处理失败")
def fix_ollama_special_tags(self, content):
"""修复Ollama特殊标记"""
# 常见的特殊标记映射
special_tags = {
# 使用正则表达式匹配常见的乱码模式并将其替换为可能的原始标记
r'<\x1d\x95\xef\x6d\x73\x00\x65\x00\x72\x00\x1d\x95\x3f\x00': '<|User|>',
r'<\x1d\x95\xce\x6d\x73\x00\x73\x00\x69\x00\x73\x00\x74\x00\x61\x00\x6e\x00\x74\x00\x1d\x95\x3f\x00': '<|Assistant|>',
r'<\x1d\x95\x06\x6e\x6e\x00\x64\x00\x3b\x92\x77\x4e\x66\x00\x3b\x92\x7b\x4e\x65\x00\x6e\x00\x74\x00\x65\x00\x6e\x00\x63\x00\x65\x00\x1d\x95\x3f\x00': '<|end_of_sentence|>',
r'<\x1d\x95\x02\x6e\x65\x00\x67\x00\x69\x00\x6e\x00\x3b\x92\x77\x4e\x66\x00\x3b\x92\x7b\x4e\x65\x00\x6e\x00\x74\x00\x65\x00\x6e\x00\x63\x00\x65\x00\x1d\x95\x3f\x00': '<|begin_of_sentence|>',
# 简化版本的模式,可能在不同导出版本中出现
r'<锝淯ser锝\?': '<|User|>',
r'<锝淎ssistant锝\?': '<|Assistant|>',
r'<锝渆nd鈻乷f鈻乻entence锝\?': '<|end_of_sentence|>',
r'<锝渂egin鈻乷f鈻乻entence锝\?': '<|begin_of_sentence|>'
}
# 特殊处理用于GBK编码错误的中文
# 这是很多中文被GBK错误解码后的特征模式
chinese_pattern = r'浣犳槸閫氫箟鍗冮棶(.*?)鍥炵瓟'
if re.search(chinese_pattern, content):
try:
# 尝试修复中文 - 这种方法可能不完美,但可以尝试
# 先将内容转为bytes,假设它是GBK编码错误导致的
gbk_encoded = content.encode('latin1') # 使用latin1保持字节不变
# 然后尝试用GBK解码
fixed_content = gbk_encoded.decode('gbk', errors='replace')
# 如果解码后看起来更合理,则使用它
return fixed_content
except:
pass # 如果失败,继续使用原始内容
# 应用所有特殊标记替换
fixed_content = content
for pattern, replacement in special_tags.items():
fixed_content = re.sub(pattern, replacement, fixed_content)
# 修复PARAMETER行中可能的乱码
fixed_content = re.sub(r'PARAMETER\s+stop\s+<锝.*?\?', lambda m: m.group(0).replace(m.group(0), 'PARAMETER stop "<|special_tag|>"'), fixed_content)
return fixed_content
def select_all(self, event=None):
# 根据当前活动的标签页选择文本区域
current_tab = self.notebook.index(self.notebook.select())
if current_tab == 0: # 修复后内容
self.text_area.tag_add(tk.SEL, "1.0", tk.END)
self.text_area.mark_set(tk.INSERT, "1.0")
self.text_area.see(tk.INSERT)
else: # 原始内容
self.original_text_area.tag_add(tk.SEL, "1.0", tk.END)
self.original_text_area.mark_set(tk.INSERT, "1.0")
self.original_text_area.see(tk.INSERT)
return 'break' # 防止默认行为
def copy_text(self):
# 根据当前活动的标签页复制文本
current_tab = self.notebook.index(self.notebook.select())
if current_tab == 0: # 修复后内容
if self.text_area.tag_ranges(tk.SEL):
self.root.clipboard_clear()
self.root.clipboard_append(self.text_area.get(tk.SEL_FIRST, tk.SEL_LAST))
self.status_var.set("修复后文本已复制到剪贴板")
else:
self.status_var.set("未选择文本")
else: # 原始内容
if self.original_text_area.tag_ranges(tk.SEL):
self.root.clipboard_clear()
self.root.clipboard_append(self.original_text_area.get(tk.SEL_FIRST, tk.SEL_LAST))
self.status_var.set("原始文本已复制到剪贴板")
else:
self.status_var.set("未选择文本")
def save_as_utf8(self):
if not self.raw_content:
messagebox.showinfo("提示", "没有内容可保存")
return
# 获取当前标签页内容
current_tab = self.notebook.index(self.notebook.select())
if current_tab == 0:
content = self.text_area.get(1.0, tk.END)
else:
content = self.original_text_area.get(1.0, tk.END)
# 默认使用原文件名,但添加.utf8后缀
default_name = os.path.basename(self.file_path_var.get())
if not default_name:
default_name = "Modelfile.utf8"
else:
default_name = f"{default_name}.utf8"
file_path = filedialog.asksaveasfilename(
defaultextension=".utf8",
initialfile=default_name,
filetypes=[("UTF-8文件", "*.utf8"), ("所有文件", "*.*")]
)
if file_path:
try:
with open(file_path, 'w', encoding='utf-8') as f:
f.write(content)
self.status_var.set(f"文件已保存至: {file_path}")
messagebox.showinfo("成功", "文件已成功保存为UTF-8编码")
except Exception as e:
messagebox.showerror("保存错误", f"保存文件时发生错误: {str(e)}")
def clear_text(self):
self.text_area.delete(1.0, tk.END)
self.original_text_area.delete(1.0, tk.END)
self.file_path_var.set("")
self.raw_content = None
self.status_var.set("内容已清除")
if __name__ == "__main__":
root = tk.Tk()
app = OllamaModelfileConverter(root)
root.mainloop()
至此,问题总算基本解决,虽然不完美,但已经不影响使用。
有了这个方法,就可以从魔搭社区等地方下载GGUF格式的大模型文件,直接配置到离线服务器了。直接从网页下载是很慢的,但是有个非常好的办法,先把大模型链接导入迅雷,下载到迅雷云盘,然后通过迅雷云盘高速下载到本地。迅雷就是干下载的,能跑满宽带,此方法下载AI大模型文件非常快。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)