机器学习的数据预处理模块(一):缺失值处理&数据规范化
数据挖掘分析中有一句至理名言:“垃圾进,垃圾出”,也就是说如果输入数据的质量得不到保障,模型挖掘出来的结果也没有实际的使用价值。因此在实际数据的分析过程中,数据预处理是必不可少的环节。
数据挖掘分析中有一句至理名言:“垃圾进,垃圾出”,也就是说如果输入数据的质量得不到保障,模型挖掘出来的结果也没有实际的使用价值。
因此在实际数据的分析过程中,数据预处理是必不可少的环节,甚至会占用到整个任务的60%以上的时间。同时经过数据预处理,能保障数据的质量,从而减少模型的误差。此处,将介绍三种数据预处理方法,缺失值处理、数据的规范化以及主成分分析。
目录
1.缺失值处理
在数据处理过程中缺失值是十分常见的,需要对其进行处理。这里介绍Scikit-learn包中能充分利用数据信息的三种常用填充策略,即均值填充、中位数填充和最频繁值填充。这里填充方式有两种:按行和按列。所谓按行或者按列均值填充策略,就是对某行或者某列中的所有缺失值用该行或者该列中非缺失部分的值的平均值来表示;中位数填充策略和最频繁值填充策略类似,即取某行或某列中非缺失部分的值的中位数和出现频次最多的值来代替其缺失值。
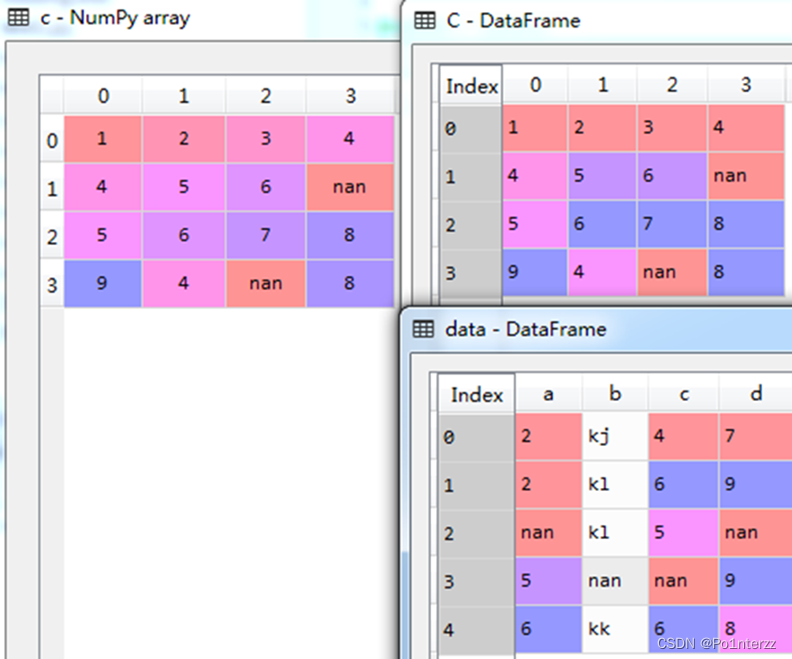
以下举一个例子,存在一个'missing.xlsx'数据集,里面存在有缺失值,首先我们先将数据集读入变量中。
import pandas as pd
import numpy as np
data=pd.read_excel('missing.xlsx') #数据框data
c=np.array([[1,2,3,4],[4,5,6,np.nan],[5,6,7,8],[9,4,np.nan,8]]) #数组c
C=pd.DataFrame(c) #数据框C
需要注意的是,填充的数据结构要求为数组或者数据框,元素则要求为数值类型。使用Scikit-learn中的数据预处理模块进缺失值填充的基本步骤如下:
1.导入数据预处理中的填充模块Imputer,其命令如下:
from sklearn.preprocessing import Imputer
from sklearn.impute import SimpleImputer2.利用Imputer创建填充对象imp,其命令如下:
imp = Imputer(missing_values=‘NaN’, strategy=‘mean’, axis=0) #创建按列均值填充策略对象。
imp = SimpleImputer(missing_values=np.nan, strategy=‘mean’) #创建按列均值填充策略对象。其中对象参数说明如下:strategy:均值(mean)、中位数(median)、最频繁值(most_frequent)三种填充策略
axis=0:按列填充方式;axis=1:按行填充方式 #SimpleImputer只能按列填充
调用填充对象imp中的fit()拟合方法,对待填充数据进行拟合训练,其命令如下:
imp.fit(Data) #Data为待填充数据集变量调用填充对象imp中的transform()方法,返回填充后的数据集了,其命令如下:
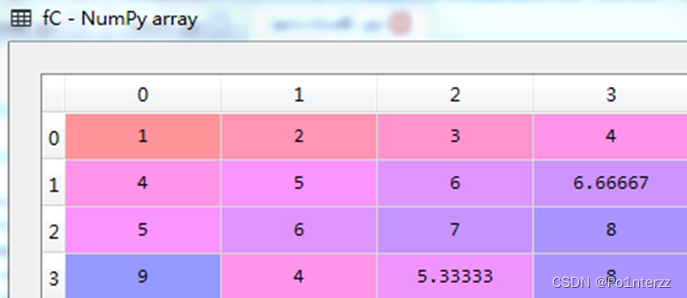
FData=imp.transform(Data) #返回填充后的数据集FData以对象参数为mean为例,代码如下:
from sklearn.impute import SimpleImputer
fC=C
imp = Imputer(missing_values=np.nan, strategy='mean')
imp.fit(fC)
fC=imp.transform(fC)
2.数据规范化
由于变量或指标的单位不同,造成有些指标数据值非常大,而有些非常小,在模型运算过程中会造成模型失真,进而预估准确率下降。因此,需要对这些数据做规范化处理。这里介绍两种常用的规范化处理方法:均值-方差规范化、极差规范化。
2.1均值-方差规范化
所谓均值-方差规范化,是指变量或指标数据减去其均值再除以标准差得到的新的数据。新的数据均值为0,方差为1,其公式如下:
代码实现如下:
from sklearn.impute import SimpleImputer
imp = Imputer(missing_values=np.nan, strategy='mean')
imp.fit(data)
data=imp.transform(data) #对缺失值进行填充处理
#数据规范化,导入StandardScaler模块
from sklearn.preprocessing import StandardScaler
X=data
scaler = StandardScaler() #创建对象scaler
scaler.fit(X) #对数据进行拟合
X=scaler.transform(X) #transform方法返回规范后的数据集
2.2极差规范化
而极差规范化是指变量或者指标数据减去其最小值再除以最大最小值之差得到的新的数据。新的数据取值范围在[0,1]之间,其计算公式为:
代码实现如下:
#导入极差规范化模块
from sklearn.preprocessing import MinMaxScaler
X1=data
min_max_scaler = MinMaxScaler() #创建对象min_max_scaler
min_max_scaler.fit(X1) #拟合
X1=min_max_scaler.transform(X1) #利用transform方法实现规范化
主成分分析会在下一节中详细说明。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 16
16 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)