android 人脸识别开源_本周优秀开源项目分享:用于多动物姿势跟踪的深度学习框架、面部数据集的完整版本 等8大项目...
01sweetviz 只需一行代码即可可视化和比较数据集Sweetviz是一个开放源代码Python库,可生成漂亮的高密度可视化文件,以单行代码启动探索性数据分析。输出是一个完全独立的HTML应用程序。该系统围绕快速可视化目标值和比较数据集而构建。其目标是帮助快速分析目标特征,训练与测试数据以及其他此类数据表征任务。主要特性:目标分析目标值(布尔值或数字值)与其他功能的关系可视化和比较不同的数据集
01sweetviz 只需一行代码即可可视化和比较数据集
Sweetviz是一个开放源代码Python库,可生成漂亮的高密度可视化文件,以单行代码启动探索性数据分析。输出是一个完全独立的HTML应用程序。
该系统围绕快速可视化目标值和比较数据集而构建。其目标是帮助快速分析目标特征,训练与测试数据以及其他此类数据表征任务。

主要特性:
目标分析
目标值(布尔值或数字值)与其他功能的关系
可视化和比较
不同的数据集(例如培训与测试数据)
组内特征(例如男性与女性)
混合型关联
Sweetviz无缝集成了数字(皮尔森相关性),分类(不确定性系数)和分类数字(相关性)数据类型的关联,以提供所有数据类型的最大信息。
类型推断:
自动检测数字,类别和文本特征,并带有可选的手动替代
摘要信息:
类型,唯一值,缺失值,重复行,最频繁的值
数值分析:
最小/最大/范围,四分位数,均值,众数,标准偏差,和,中位数绝对偏差,变异系数,峰度,偏度
Sweetviz当前支持Python 3.6+和Pandas 0.25.3+。
项目地址:
https://github.com/fbdesignpro/sweetviz
02 sleap 用于多动物姿势跟踪的深度学习框架

社会性LEAP估计动物姿势(SLEAP)是通过深度学习进行多动物身体部位位置估计的框架。
它是LEAP的后继者。SLEAP完全用Python编写,支持多动物姿势估计,动物实例跟踪,并带有支持主动学习的标签/训练GUI。
项目地址:
https://github.com/murthylab/sleap
03 champ 基于MIT Cheetah I的四足机器人
CHAMP四足控制器的ROS软件包。

CHAMP是一个开放源代码开发框架,用于构建新的四足机器人和开发新的控制算法。该控制框架基于“利用模式调制和阻抗控制实现高度动态运动的分层控制器:在MIT猎豹机器人上实现”。
核心特性:
完全自主(使用ROS导航堆栈)。
设置助手,以配置新建的机器人。
预先配置的URDF,例如Anymal,MIT Mini Cheetah,Boston Dynamic的LittleDog和SpotMicroAi。
Gazebo模拟环境。
演示机器人使用可访问的组件构建,因此您可以在家中构建它。
演示应用程序,如TOWR和鸡头稳定器。
可以在SBC和微控制器上运行的轻量级C++仅标头库。
项目地址:
https://github.com/chvmp/champ
04 OpenPCDet 用于基于LiDAR的3D对象检测
OpenPCDet是一个清晰,简单,独立的开源项目,用于基于LiDAR的3D对象检测。
OpenPCDet是基于PyTorch的常规代码库,用于从点云进行3D对象检测。它目前支持多种先进的3D对象检测方法,这些方法具有针对一阶段和两阶段3D检测框架的高度重构的代码。
基于OpenPCDet工具箱,在所有仅LiDAR方法中的3D检测,3D跟踪,域适应三个方面赢得了Waymo开放数据集挑战,并且Waymo相关模型将很快发布到OpenPCDet。
目前正在积极更新此存储库,不久将支持更多数据集和模型。
设计模式:
具有统一点云坐标的数据模型分离,可轻松扩展到自定义数据集。
统一的3D框定义:(x,y,z,dx,dy,dz,heading)。
灵活清晰的模型结构可轻松支持各种3D检测模型。
在一个框架内支持以下各种模型。
支持特性:
支持一阶段和两阶段3D对象检测框架
支持使用多个GPU和多台机器进行分布式培训和测试
支持不同比例的多个头部以检测不同的类别
支持堆叠版本集抽象,以编码不同场景中的多个点
支持自适应训练样本选择(ATSS)进行目标分配
支持RoI感知点云池和RoI网格点云池
支持GPU版本3D IoU计算和旋转NMS
模型组件:
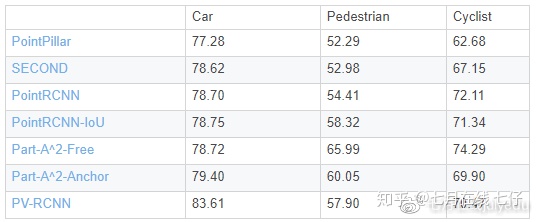
KITTI 3D对象检测基准
下表显示了受支持的选定方法。结果是在KITTI数据集的值集上具有中等难度的3D检测性能。
NuScenes 3D对象检测基准

项目地址:
https://github.com/open-mmlab/OpenPCDet
05 C-MS-Celeb MS-Celeb-1M面部数据集的完整版本
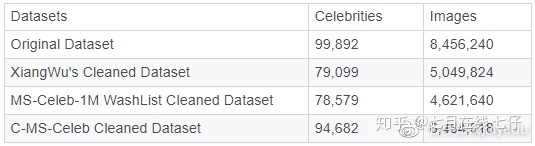
这是MS-Celeb-1M人脸数据集的干净版本,其中包含94,682名名人的6,464,018张图像。由于原始MS-Celeb-1M的标签图像过多,因此我们希望清理此数据集以进行更好的模型训练。
我们的C-MS-Celeb清洁数据集包含6,464,018张图像,属于94,682位名人。下表将我们的数据与其他公开清除的MS-Celeb数据集进行了比较:
我们的C-MS-Celeb大型,清洁且多样化。
大型:
首先,从该表中,与其他清洁列表相比,我们可以看到C-MS-Celeb在清洁过程中为更多人保留了更多图像。
清洁:
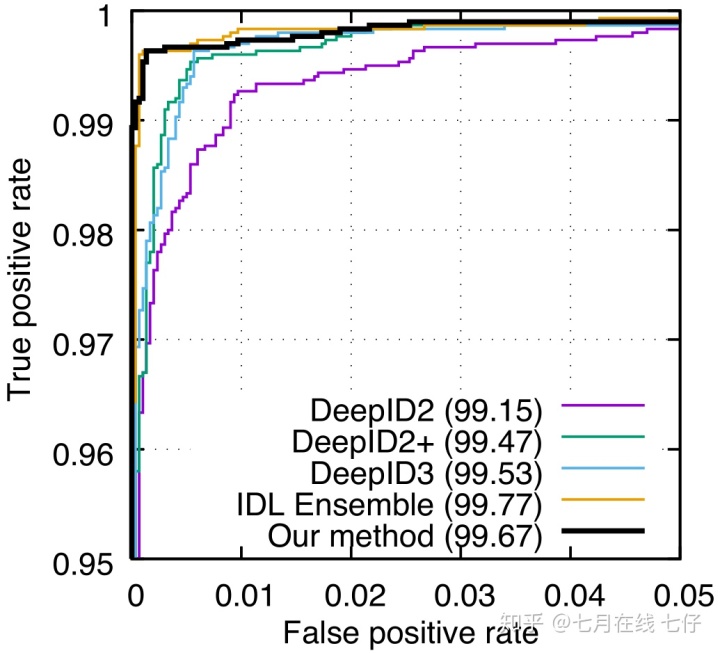
其次,根据我们的经验评估,正确标记了C-MS-Celeb中97.3%的图像。
多样的:
我们基于社区检测的清洁方法还可以为每个人保留面部图像的多样性。以下是我们清洁结果中“ Lady Gaga”和“ Quinn Cummings”的一些示例图像:

从这些样本结果中,我们可以看到在清洁过程中可以保留各种妆容的图像(左半边是Gaga夫人)。从清洁结果还可以观察到不同年龄的多样性(右半部分的奎因·卡明斯)。
下图说明了我们基于社区检测的清洁方法。我们首先使用预先训练的人脸识别模型构造人脸相似度图。相似度图中的每个节点代表一个图像,两个节点之间的链接权重量化了这两个图像之间的相似度。
然后,我们删除弱连接并在该图上运行社区检测算法。最后,我们将图像保留在大型社区(此图中右侧的彩色社区)中,并删除分散的节点和次要社区(图中的灰色节点)。
因此,我们能够在数据清理期间实现高清理度和丰富的数据多样性。

项目地址:
https://github.com/EB-Dodo/C-MS-Celeb
06 TensorFlowTTS Tensorflow 2的实时最新语音合成
TensorFlowTTS基于TensorFlow 2提供了实时的最新语音合成架构,例如Tacotron-2,Melgan,Multiband-Melgan,FastSpeech,FastSpeech2。
借助Tensorflow 2,我们可以加快训练/推理进度,通过使用伪量化感知和修剪进一步优化程序,使TTS模型可以比实时运行更快,并且能够部署在移动设备或嵌入式系统上。
特性:
语音合成方面的高性能。
能够微调其他语言。
快速,可扩展和可靠。
适合部署。
易于实现基于抽象类的新模型。
如果可能的话,混合精度可以加快训练速度。
在基础训练器类别中同时支持单/多GPU。
所有支持模型的TFlite转换。
Android示例。
支持多种语言(当前,我们支持中文,韩文,英文。)
支持C ++推理。
支持将某些模型的重量从pytorch转换为tensorflow以加快速度。
系统需求:
该存储库已在Ubuntu 18.04上经过以下测试:
Python 3.7以上
CUDA 10.1
CuDNN 7.6.5
Tensorflow 2.2 / 2.3
Tensorflow插件> = 0.10.0
支持架构:
MelGAN
Tacotron-2
FastSpeech
Multi-band MelGAN
FastSpeech2
Parallel WaveGAN
项目地址:
https://github.com/TensorSpeech/TensorflowTTS
07 aquvitae 轻量级深度学习的最简单的知识蒸馏库

AquVitae是一个Python库,通过一个非常简单的API即可最轻松地执行知识蒸馏。该库支持TensorFlow和PyTorch。
知识蒸馏是最有代表性的模型压缩技术,以及权重运行和量化。该库具有流行且多样化的知识提取算法。
如果您的项目中使用的深度学习模型过于繁重,则可以使用AquVitae使速度非常快,而不会损失性能。
在AquVitae中实现的知识蒸馏算法列表:

项目地址:
https://github.com/aquvitae/aquvitae
08 spark-rapids 使用GPU加速Apache Spark
用于Apache Spark的RAPIDS加速器为Apache Spark提供了一组插件,这些插件利用GPU通过RAPIDS库和UCX加速处理。
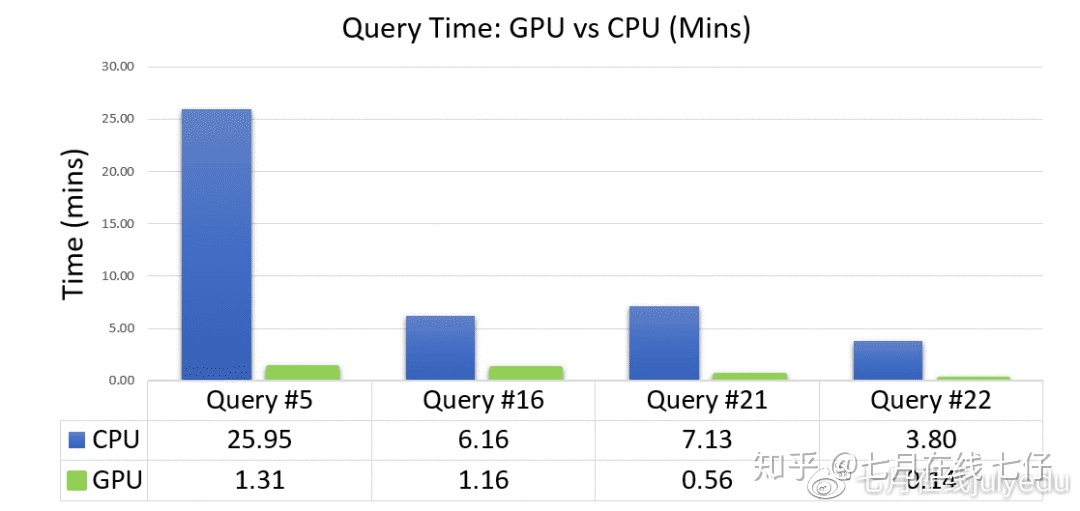
上表显示了根据TPCxBB基准测试运行ETL查询的结果。这些绝对不是官方结果。它使用存储在parquet中的10TB数据集(比例因子10,000)。
处理发生在两个节点的DGX-2群集上。每个节点具有96个CPU内核,1.5TB主机内存,16个V100 GPU和512 GB GPU内存。
项目地址:
https://github.com/NVIDIA/spark-rapids
今日推荐
今天给大家推荐【机器学习集训营 第十二期】课程,下周一开课!
1、专业的教学模式
【机器学习集训营 第十二期】,采取十二位一体的教学模式,包括12个环节:“入学测评、直播答疑、布置作业、阶段考试、毕业考核、一对一批改、线上线下结合、CPU&GPU双云平台、组织比赛、联合认证、面试辅导、就业推荐”。
2、完善的实战项目
只学理论肯定是不行的,学机器学习的核心是要做项目,本期集训营共13大实战项目.



3、专家级讲师团队
本期集训营拥有超豪华讲师团队,学员将在这些顶级讲师的手把手指导下完成本期课程的学习,挑战40万年薪。


授课老师、助教老师,多对一服务。从课上到课下,从专业辅导到日常督学、360度无死角为学员安心学习铺平道路。陪伴式解答学员疑惑,为学员保驾护航。
4、六大课程特色


5、完善的就业服务
学员在完成所有的阶段学习后,将会有一对一的就业服务,包括简历优化、面试求职辅导及企业内推三大部分。
为了确保学员能拿到满意的offer,七月在线还专门成立就业部,会专门为集训营学员提供就业服务,保证每一位学员都能拿到满意的offer。
点击查看课程详情,同时大家也可以去看看之前学员的面试经验分享。
机器学习集训营 第十二期「前11期帮助上千人成功转型AI,本期再次细化项目流程」- 七月在线www.julyedu.com

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)