大学生机器学习入门
·
1. 基本原理图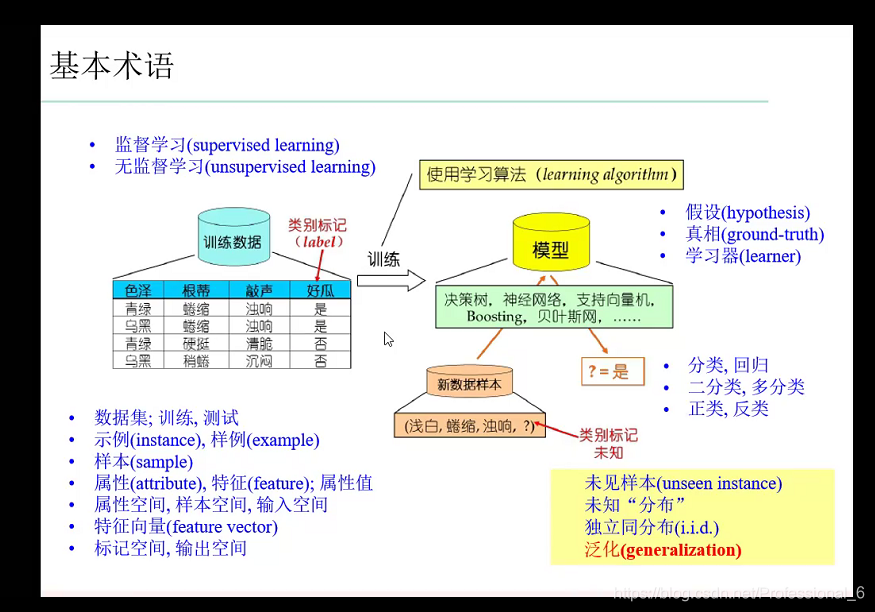
!!!是否有类型标记来区分监督学习和无监督学习
监督学习一般是分类和回归问题 (是否有label)
- 西瓜分类问题 就是判段是否为好瓜
- 西瓜回归问题 就是判断一个西瓜成熟程度
无监督学习一般是聚类和降维问题
- 聚类: 把两个班的人 一班的在一起 二班的在一起
一般的训练过程:
从训练集反应出假设空间->在选出版本空间->通过测试集来筛选最合适的假设
- 假设空间 就是所以可能存在的选项n1n2n3…+1 n1是样本属性的可能存在值 n2 n3 **同理
- 版本空间就是 符合所有训练集的假设保留下来
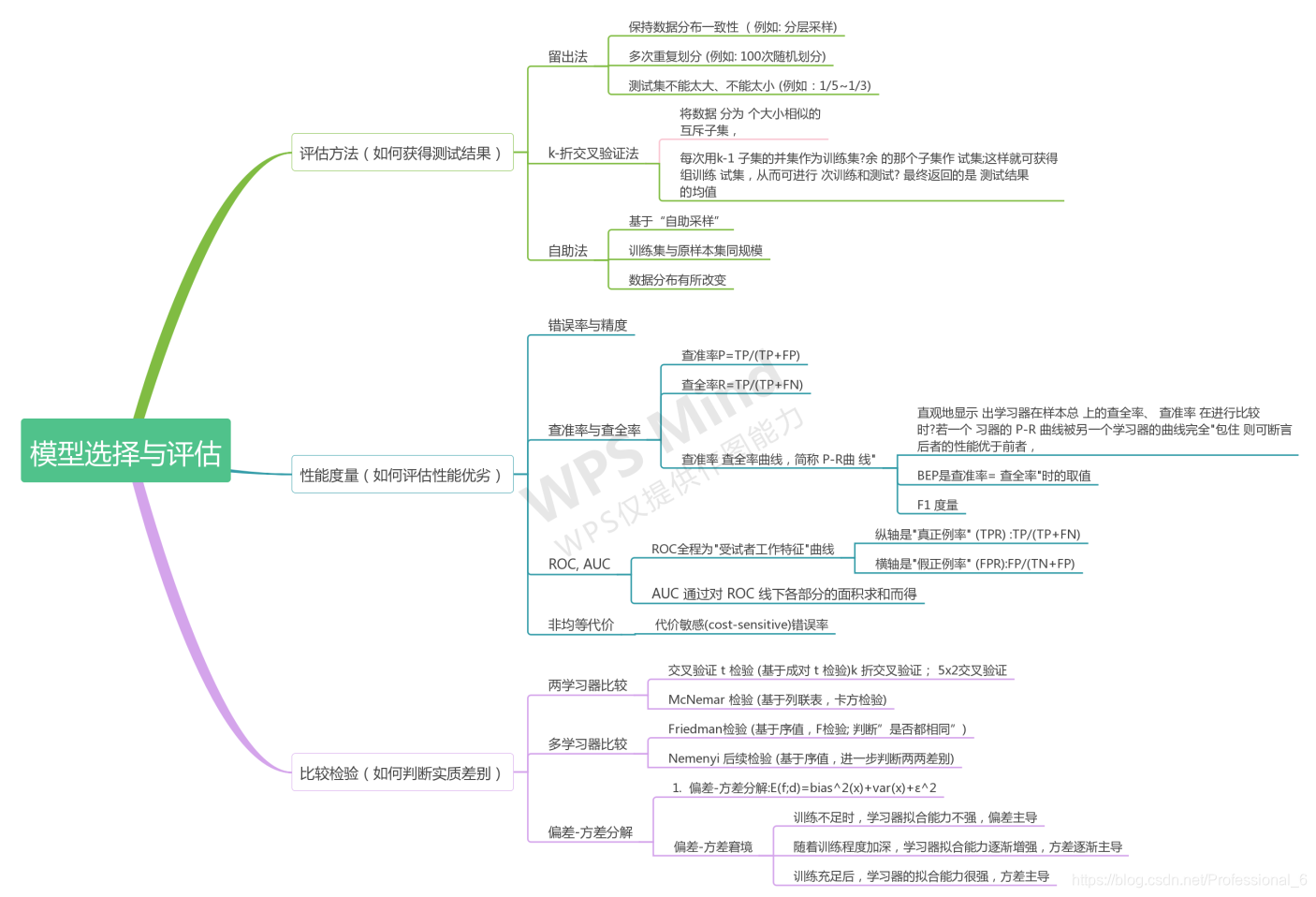
2.0 模型的选择和评估
模型的选择
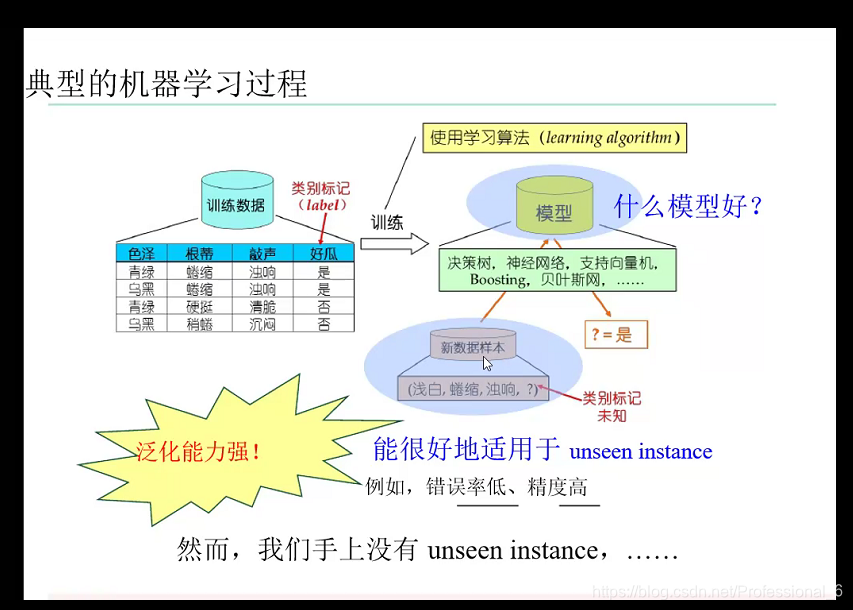
原理: 在测试机上测试的性能为泛化性能
- 泛化误差:在未来样本上的误差
- 经验误差:在训练集上的误差
泛化误差是越小越好,但是经验误差不是越小越好 因为会发送过拟合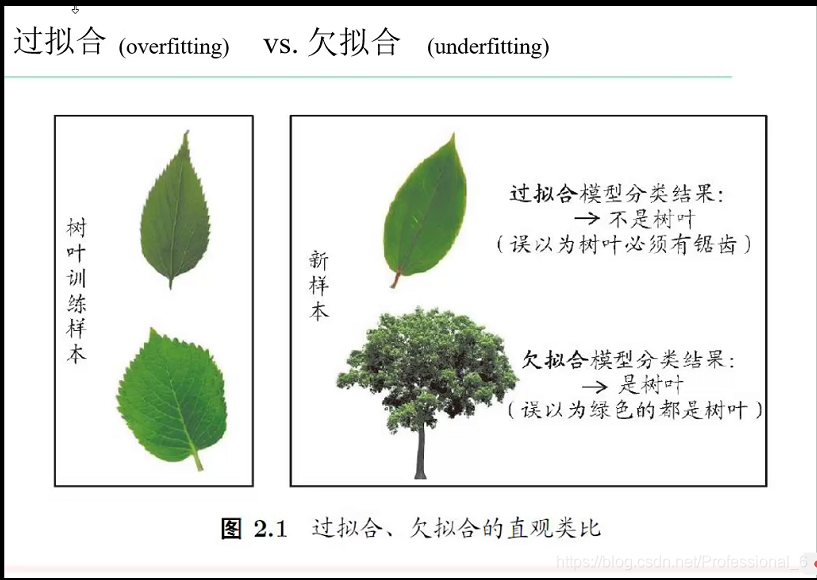
一旦在训练集上表现的太优秀,在泛化性能就差了,因为NFL原则。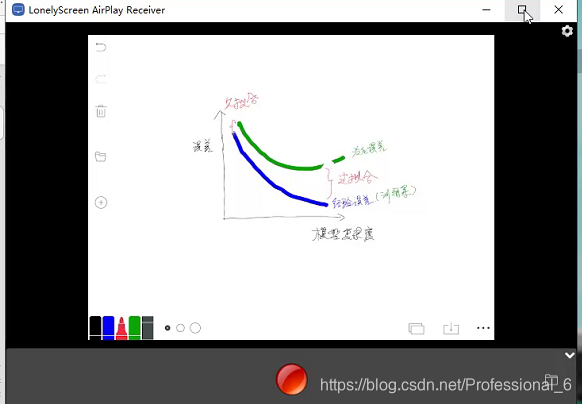
随着模型复杂度的上升 经验误差 会越来越小 ,因为复杂度是上升会带来训练集维度提高,精确度上升,但是当经验误差太小了,就过拟合了,反而泛化误差会上升。
评估方法 和怎么分离数据集 —把一部分训练集变成验证集
因为测试机没用标签,无法评估,所以就打算从数据集中拿出一些来验证。
!!!简单讲一下 验证集和训练集和测试机的关系
首先训练集是来拟合模型的,然后我们要把测试集导入模型去得出我们要的分类结果,但是这样错误率很高,因为我们没有评估我们的模型好坏就直接用了,不能直接用测试集来测评,因为测试集没有结果(要我们自己去得出),所以我们想到用训练集去评估我们的模型(有结果),我们可以从训练集中分离一部分数据来测试我们的模型,所以验证集就诞生了-----从训练集中分离了一部分数据。
1.0 留出法(Hold-Out Cross Validation):从训练集选出一部分当成验证集

留出的数据集不难太大 不然就会欠拟合,太小就会过拟合。
2.0 交叉法(Cross Validation):从训练集选出一部分当成验证集

- 不重复抽样将原始数据随机分成k份。
- 每次挑选其中1份作为测试集,剩余k-1份作为训练集用于训练模型。
- 重复第2步k次,在每个训练集上训练后得到一个模型。用这个模型在相应的测试集上测试,计算并保存模型的评估指标。
- 计算k组测试结果的平均值作为模型准确度的估计,并作为当前k折交叉验证下模型的性能指标。
3.0 自助法
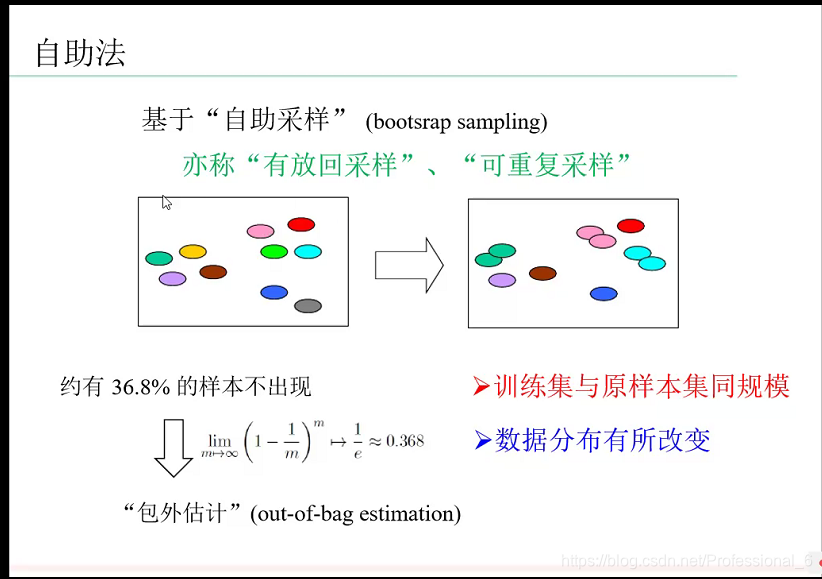
每次从数据集中拿出一个放入验证集,然后拿回来,做重复抽样,所以一个数据没抽到的可能为(1-1/m)重复m次当m无限大时,概率大致为0.38,那么100个个数据大致就是38个数据没抽到,->总体大概38%没重复,但是这个确实改变了样本的分布,所以不太好,可能一些垃圾数据变多,而好的数据没用,基本使用于小数据样本。
调参
查全率:所有的正例中我预测了多少
查准率:我预测的正例中真正的正例有多少
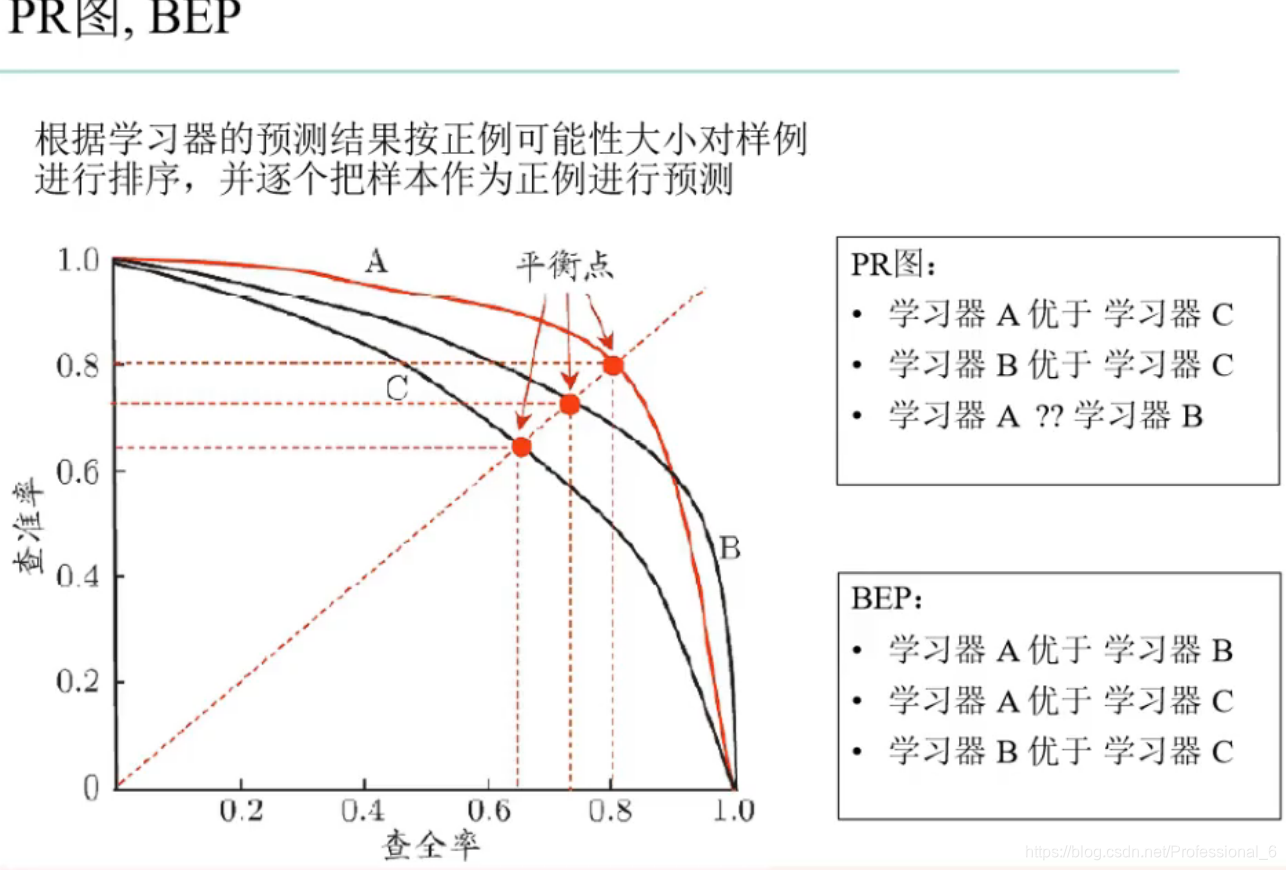
PR曲线 a和b都包含于c 所以c垃圾,然后比a和b他们有交集 但是平衡点a更高 所以a好
F1 分类
1/F1=1/2(1/p+1/R)
1/Fβ=1/(1+β^2)(1/P+ β*β /R)
当β大于一时查全率影响8更大 反之查准率影响更大
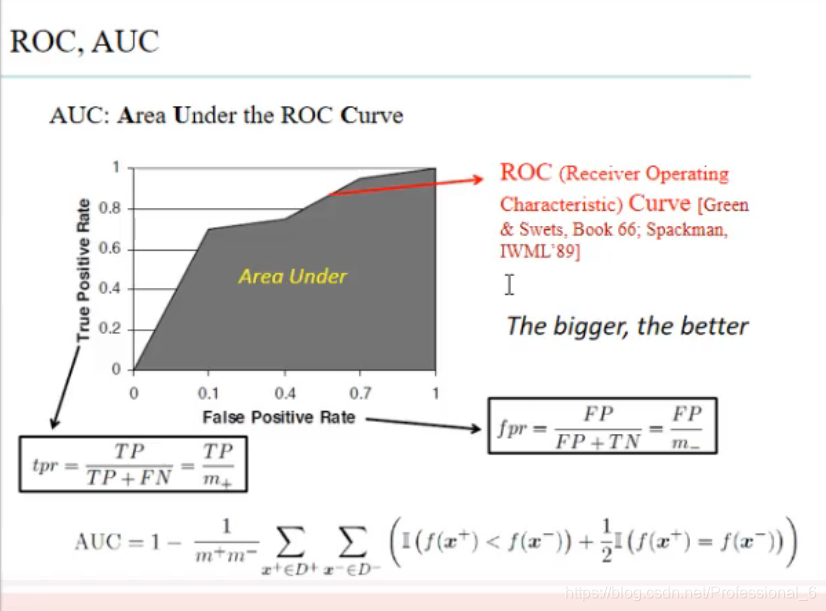
ROC和AOC

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)