深度学习推荐系统的算法简单实现
本篇文章,我们使用Keras框架实现一个简单的深度学习推荐算法。下面给出的一些截图和语句是在jupyter notebook环境下的。
一、数据集获取
谷歌的数据集,这里我放到百度云链接,提取码:hway
我们本篇只处理其中的评分表BX-Book-Ratings.csv,另外两个文件是在推荐了Book的id即ISBN后,丰富所推荐的书的信息用的。
二、数据处理
1、先导入所需要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
import warnings
warnings.filterwarnings('ignore')
from keras.layers import Input, Embedding, Flatten, Dot, Dense, Concatenate,Dropout
from keras.models import Model
2、读取csv文件
#部分文件有字节编码错误,errors 忽略
with open('BX-Book-Ratings.csv', encoding='utf-8',errors='ignore') as f:
# 忽略因为数据不规范导致的报错行
dataset = pd.read_csv(f, error_bad_lines=False, sep=';')
此时你若输入语句dataset.head(),可以看到前5条表的显示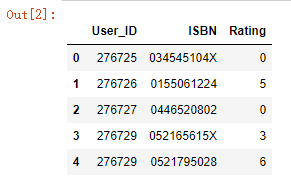
也可以查看一下其他信息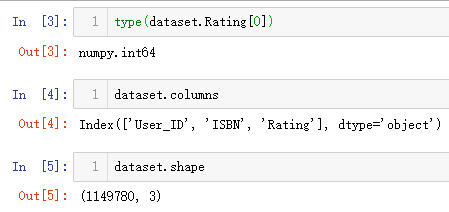
注意到这里dataset实际上有一百多万条样本,我们后面训练模型时,全部训练可能会需要很久的时间,也可选择只训练一部分。
2、图书索引ISBN的处理
2.1 我们先把用户索引User_ID和书的索引ISBN位置互换一下
(这一步只是我为了和参考博客保持一致所做的,你如果弄清对应关系也不需要换)
dataset = dataset[['ISBN', 'User_ID', 'Rating']]
现在的索引位置在输入语句dataset.head()后如图: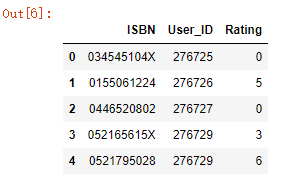
2.2 将ISBN映射到一串字典
下面的value_counts方法可以快速统计:各个图书索引号ISBN及其对应的频率。
(python中如果你自己列字典,一个个累加统计的话,这100多万条数据需要非常久才能处理)
这其实也达到了我们需要的一一对应的效果,我们下面的代码要做的就是将每个ISBN对应的频率改写成0,1,2,3…这样的新id就好。
ISBN_val_counts= dataset.ISBN.value_counts()
map_dict = {}
for i in range(len(ISBN_val_counts)):
map_dict[ISBN_val_counts.index[i]] = i
这样,map_dict就是一个映射的字典。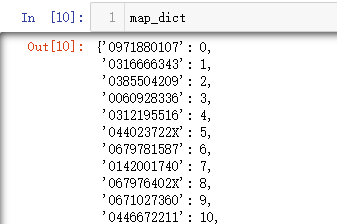
dataset["ISBN"] = dataset["ISBN"].map(map_dict)
通过上面的语句映射之后,ISBN可以看到发生了变化,是0开始的索引,输入语句dataset.head()后如图: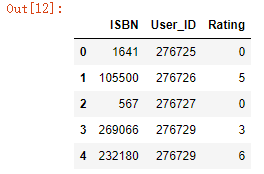
3、用户索引User_ID的处理
和图书索引ISBN是完全一样的处理,这里只给代码了:
User_ID_val_counts= dataset.User_ID.value_counts()
# 映射字典
user_id_map_dict = {}
for i in range(len(User_ID_val_counts)):
user_id_map_dict[User_ID_val_counts.index[i]] = i
# 将User_ID映射到一串字典
dataset["User_ID"] = dataset["User_ID"].map(user_id_map_dict)
4、拆分训练集、测试集
首先看到,有105283个用户,有340553本书。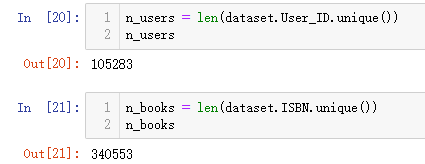
下面以4:1拆分成训练集和测试集:
from sklearn.model_selection import train_test_split
train, test = train_test_split(dataset, test_size=0.2, random_state=42)
train.head()
三、深度学习模型
Emmbeding是从离散对象(例如我们案例中的单词或书籍 ID)到连续值向量的映射。这可用于查找离散对象之间的相似性,如果模型不使用Emmbeding层,则该相似性对模型来说是不明显的。Emmbeding向量是低维的,并在训练网络时得到更新。
我们设计一个这样的模型,将用户id作为用户向量,物品id作为物品向量。
分别Emmbeding两个向量,再Concat连接起来,最后加上3个全连接层构成模型,进行训练。
我们使用adam优化器,用均方差mse来衡量预测评分与真实评分之间的误差。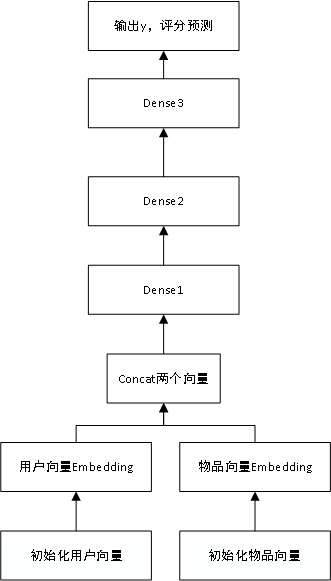
# creating book embedding path
book_input = Input(shape=[1], name="Book-Input")
book_embedding = Embedding(n_books+1, 5, name="Book-Embedding")(book_input)
Dropout(0.2)
book_vec = Flatten(name="Flatten-Books")(book_embedding)
# creating user embedding path
user_input = Input(shape=[1], name="User-Input")
user_embedding = Embedding(n_users+1, 5, name="User-Embedding")(user_input)
Dropout(0.2)
user_vec = Flatten(name="Flatten-Users")(user_embedding)
# concatenate features
conc = Concatenate()([book_vec, user_vec])
# add fully-connected-layers
fc1 = Dense(128, activation='relu')(conc)
Dropout(0.2)
fc2 = Dense(32, activation='relu')(fc1)
out = Dense(1)(fc2)
# Create model and compile it
model2 = Model([user_input, book_input], out)
model2.compile('adam', 'mean_squared_error')
模型概况summary如下: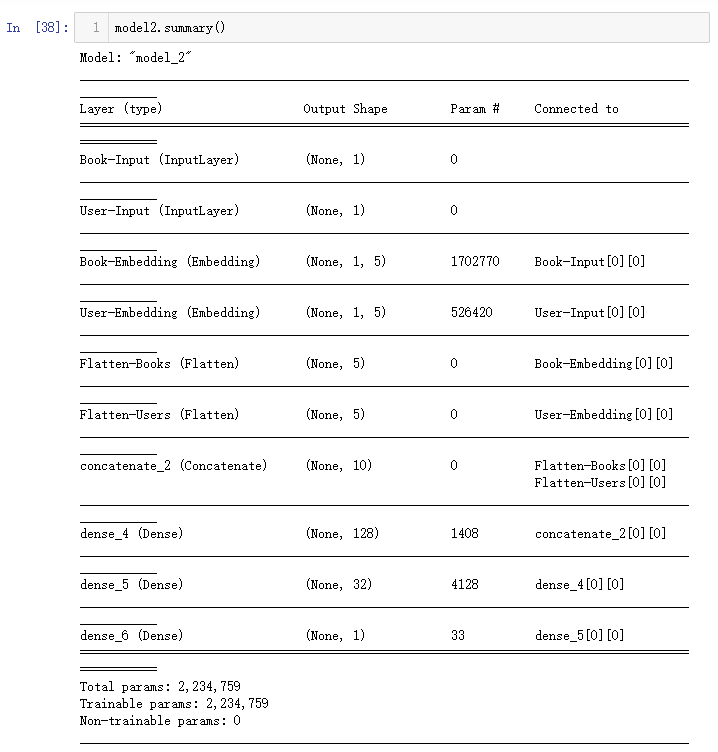
四、训练与评估模型
1、loss
我们在还未训练时,先测试一下测试集在该模型上的loss:
下面我们进行训练:
from keras.models import load_model
if os.path.exists('regression_model2.h5'):
model2 = load_model('regression_model2.h5')
else:
history = model2.fit([train.User_ID, train.ISBN], train.Rating, epochs=10, verbose=1)
model2.save('regression_model2.h5')
loss = history.history['loss'] # 训练集损失
plt.plot(loss,'r')
plt.title('Training loss')
plt.xlabel("Epochs")
plt.ylabel("Loss")
训练10个epoch后,我们再看一次测试集的loss如下:
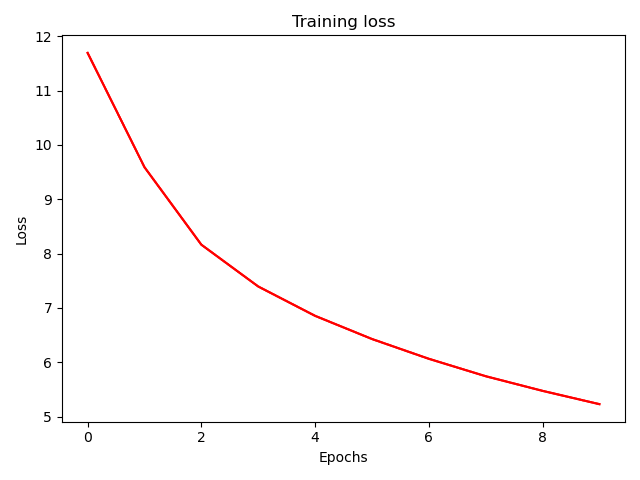
发现还是有下降的效果的,你可以多训练一些epoch来下降更多loss。
2、测试模型输出
我们这里取测试集的前10本书,根据模型预测前10个用户的打分为predictions。
predictions = model2.predict([test.User_ID.head(10), test.ISBN.head(10)])
下面打印出前10本书的预测用户评分、真实评分。
for i in range(0,10):
print(predictions[i], test.Rating.iloc[i])
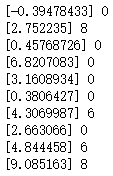
3、真正进行推荐
我们先拿到所有的图书索引ISBN,并去重成为book_data。再添加一个和book_data长度相等的用户列表user,不过这里的user列表中的元素全是1,因为我们要做的是:预测第1个用户对所有图书的评分,再将预测评分高的图书推荐给该用户。
book_data = np.array(list(set(dataset.ISBN)))
user = np.array([1 for i in range(len(book_data))])
predictions = model2.predict([user, book_data])
此时的predcitions是一个长度为len(book_data)的list,里面的元素是用户对所有图书的预测评分。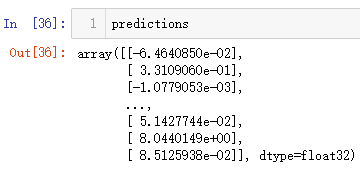
# 更换列->行
predictions = np.array([a[0] for a in predictions])

# 根据原array,取其中数值从大到小的索引,再只取前top5
recommended_book_ids = (-predictions).argsort()[:5]
print(recommended_book_ids)
print(predictions[recommended_book_ids])
recommended_book_ids就是一个长度为5的列表,里面的元素是预测评分predictions最高的5个图书的索引。
recommended_book_ids如下: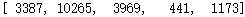
predictions[recommended_book_ids]如下: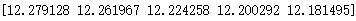
4、TSNE和PCA降维可视化Emmbeding
Emmbeding是权重,可以用来表示特定的变量,例如书本和用户,因此,我们不仅可以使用它们来获取有关问题的良好结果,还可以提取数据的内部信息。
# 提取 embeddings
book_em = model2.get_layer('Book-Embedding')
book_em_weights = book_em.get_weights()[0]
先查看下前5行权重
book_em_weights[:5]

使用PCA降到2维再可视化的操作如下
from sklearn.decomposition import PCA
import seaborn as sns
pca = PCA(n_components=2)
pca_result = pca.fit_transform(book_em_weights)
sns.scatterplot(x=pca_result[:,0], y=pca_result[:,1])
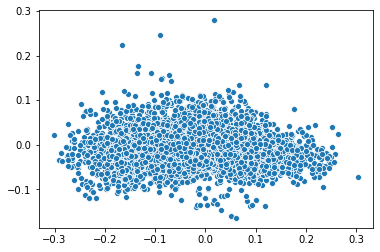
使用TSNE降到2维再可视化的操作如下
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, verbose=1, perplexity=40, n_iter=300)
tnse_results = tsne.fit_transform(book_em_weights)
sns.scatterplot(x=tnse_results[:,0], y=tnse_results[:,1])

参考:
1.《Building a book Recommendation System using Keras》
2.《上面英文blog在github的.ipynb文件Tutorials/blob/master/Recommendation》
3.《用 Keras 实现图书推荐系统》
4.《新闻分类:多分类问题(Keras实现)》
5.《Series.value_counts,pd.value_counts计算Series,DataFrame数据频率》

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)