机器学习——朴素贝叶斯分类器
在朴素贝叶斯中,若某个属性值在训练集中没有与某个类同时出现过,则训练后的模型会出现 over-fitting 现象。比如 “敲声=清脆” 测试例,训练集中没有该样例,因此连乘式计算的概率值为0,无论其他属性上明显像好瓜,分类结果都是 “好瓜=否” ,这显然不合理。
朴素贝叶斯分类器
一、朴素贝叶斯定理
1.朴素贝叶斯是什么
① 是一种基于概率的分类算法。
② 核心思想:根据各个特征对分类结果的贡献来进行预测。
③ 名字解释:“贝叶斯”使用了贝叶斯定理来进行推断;“朴素”假设各个特征是条件独立的,这简化了计算。
2.贝叶斯定理
公式如下: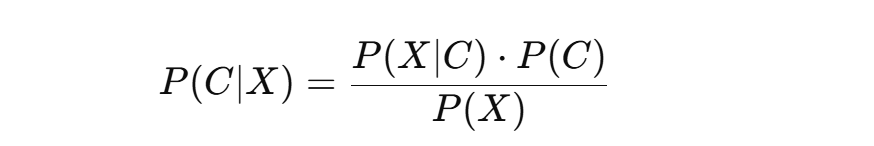
· P( C∣X ):后验概率,即在已知特征 X 的情况下,属于类别 C 的概率。
· P( C ):先验概率,样本属于类别 C 的概率。
· P( X∣C ):似然,给定类别 C,样本具有特征 X 的概率。
· P( X ):特征 X 出现的总概率(不影响比较时谁概率大)。
3.朴素贝叶斯公式(分类用法)
给定特征向量 X = (x1, x2, …, xn),我们计算: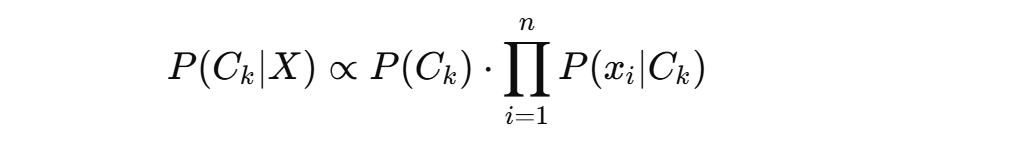
也就是说:
① 计算每个类别的先验概率 P(Ck);
② 对每个特征 xi,计算其在类别Ck下的条件概率;
③ 将所有条件概率相乘,再乘上先验概率;
④ 哪个类别的结果大,就预测为该类别。
4.适用情况
特征可以是:
· 离散型(如颜色、形状):统计概率;
· 连续型(如身高、糖分含量):用高斯分布估计概率;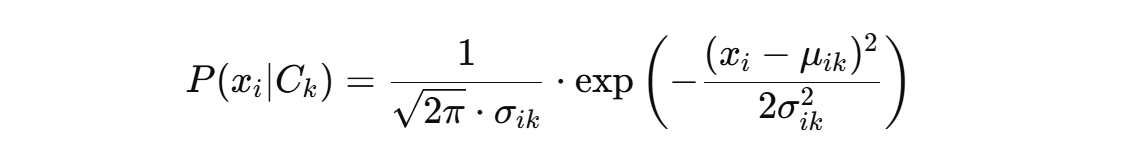
常用于:
· 文本分类(如垃圾邮件识别);
· 情感分析;
· 疾病诊断;
· 简单预测任务。
5.优缺点
优点:
- 简单易实现:公式直观,容易上手;
- 训练和预测效率高:计算快、内存占用小;
- 对小数据集表现良好;
- 高维数据友好:特别适合文本数据(如词袋模型);
- 可处理多分类问题(不限于二分类);
缺点:
- 特征之间假设独立,在现实中很难满足;
- 如果某个特征在某类别中从未出现过,会导致概率为 0(需要用拉普拉斯平滑解决);
- 对连续变量假设为高斯分布,可能不贴合真实情况;
- 对于数据不平衡的分类任务效果可能不佳。
二、先验概率、条件概率、后验概率
1.先验概率
· 含义:在没有观察任何特征值之前,某个类别出现的概率。
· 公式:
· 举例:数据集中有 20 个样本,其中 8 个是“好瓜”,则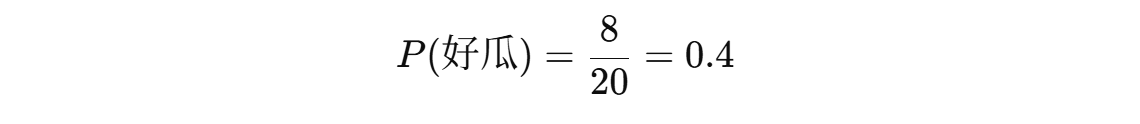
2.条件概率
· 含义:在已知类别的前提下,某个特征取某个值的概率。
· 对于离散特征(如色泽、触感):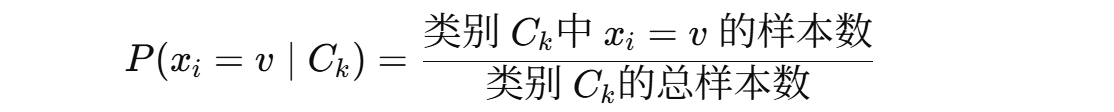
· 对于连续特征(如密度、含糖率):假设其符号高斯分布,用公式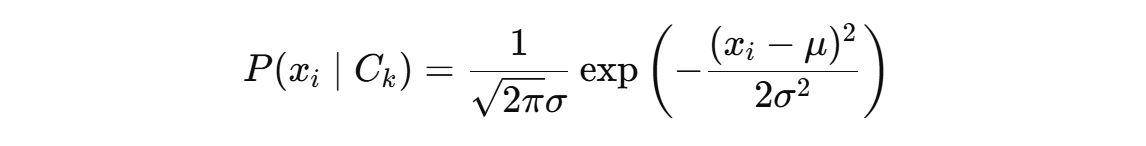
(其中 μ、σ 是在类别 Ck下第 i 个特征的均值和标准差)
3.后验概率
· 含义:在观察了样本特征之后,属于某一类别的概率。
· 公式: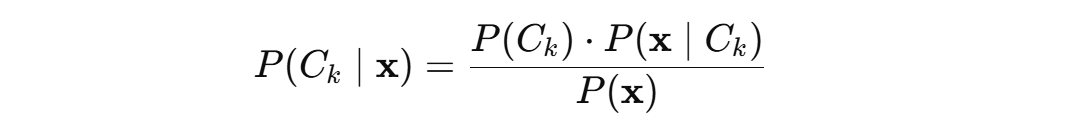
(其中P(x)是特征向量的总概率,一般在分类中不需要明确计算,因为所有类别都有同一个分母)
4.朴素贝叶斯分类器中的计算
· 朴素假设:各个特征是条件独立的。
· 分类决策规则: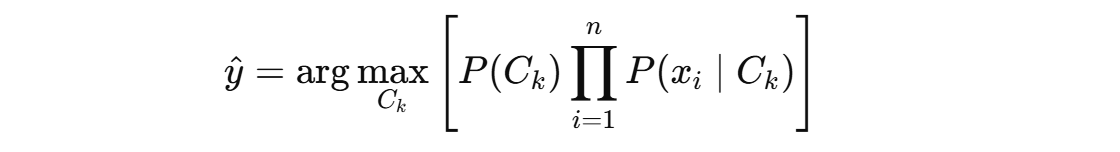
· 步骤总结:
① 计算每个类别的先验概率 P(Ck)
② 对每个特征,计算在该类别下的条件概率 P(xi | Ck)
③ 将先验概率与所有条件概率相乘
④ 比较所有类别的乘积值,选择最大者作为分类结果
三、朴素贝叶斯分类器代码实现
1.加载数据集
loadDataSet函数:
· 功能:加载训练数据集、待测数据集和特征标签。
def loadDataSet():
dataSet = [['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.697, 0.460, '好瓜'],
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.774, 0.376, '好瓜'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.634, 0.264, '好瓜'],
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.608, 0.318, '好瓜'],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.556, 0.215, '好瓜'],
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.403, 0.237, '好瓜'],
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', 0.481, 0.149, '好瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', 0.437, 0.211, '好瓜'],
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', 0.666, 0.091, '坏瓜'],
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', 0.243, 0.267, '坏瓜'],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', 0.245, 0.057, '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', 0.343, 0.099, '坏瓜'],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', 0.639, 0.161, '坏瓜'],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', 0.657, 0.198, '坏瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.360, 0.370, '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', 0.593, 0.042, '坏瓜'],
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', 0.719, 0.103, '坏瓜']]
testSet = ['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.697, 0.460] # 待测集
labels = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '密度', '含糖率'] # 特征
return dataSet, testSet, labels
2.计算连续变量的均值和方差
mean_std函数:
· 功能:计算在指定类别(好瓜或坏瓜)中,某个特征的均值和标准差。
def mean_std(feature, cla): # feature:传入指定将要计算其均值的标准差的特征名称,cla:计算指定分类cla下该特征的条件概率 feature/cla
dataSet, testSet, labels = loadDataSet()
lst = [item[labels.index(feature)] for item in dataSet if item[-1] == cla] # 类别为cla中指定特征feature组成的列表
mean = round(np.mean(lst), 3) # 均值
std = round(np.std(lst), 3) # 标准差
return mean, std
3.计算先验概率
prior函数:
· 功能:计算每个类别(好瓜、坏瓜)的先验概率 P©。
· 返回: 返回好瓜和坏瓜的先验概率。
def prior():
dataSet = loadDataSet()[0] # 载入数据集
countG = 0 # 初始化好瓜=0
countB = 0 # 初始化坏瓜=0
countAll = len(dataSet)
for item in dataSet: # 好瓜个数
if item[-1] == "好瓜":
countG += 1
for item in dataSet: # 坏瓜个数
if item[-1] == "坏瓜":
countB += 1
# 计算先验概率P(c)
P_G = round(countG / countAll, 3)
P_B = round(countB / countAll, 3)
return P_G, P_B
4.计算离散属性条件概率
P函数:
· 功能: 计算离散属性的条件概率 P(xi | c),即在类别 c 下,特征 xi 取某个值的概率。
def P(index, cla):
dataSet, testSet, labels = loadDataSet() # 载入数据集
countG = 0 # 初始化好瓜数量
countB = 0 # 初始化坏瓜数量
for item in dataSet: # 统计好瓜个数
if item[-1] == "好瓜":
countG += 1
for item in dataSet: # 统计坏瓜个数
if item[-1] == "坏瓜":
countB += 1
lst = [item for item in dataSet if
(item[-1] == cla) & (item[index] == testSet[index])] # lst为cla类中第index个属性上取值为xi的样本组成的集合
# P = round(len(lst) / (countG if cla == "好瓜" else countB), 3) # 计算条件概率
P = round(len(lst) / (countG if cla == "好瓜" else countB), 3)
return P
5.计算连续属性条件概率
p函数:
· 功能:计算连续属性的条件概率 P(xi | c)。
def p():
dataSet, testSet, labels = loadDataSet() # 载入数据集
denG_mean, denG_std = mean_std("密度", "好瓜") # 好瓜密度的均值、标准差
denB_mean, denB_std = mean_std("密度", "坏瓜") # 坏瓜密度的均值、标准差
sugG_mean, sugG_std = mean_std("含糖率", "好瓜") # 好瓜含糖率的均值、标准差
sugB_mean, sugB_std = mean_std("含糖率", "坏瓜") # 坏瓜含糖率的均值、标准差
# p(密度|好瓜)
p_density_G = (1 / (math.sqrt(2 * math.pi) * denG_std)) * np.exp(
-(((testSet[labels.index("密度")] - denG_mean) ** 2) / (2 * (denG_std ** 2))))
p_density_G = round(p_density_G, 3)
# p(密度|坏瓜)
p_density_B = (1 / (math.sqrt(2 * math.pi) * denB_std)) * np.exp(
-(((testSet[labels.index("密度")] - denB_mean) ** 2) / (2 * (denB_std ** 2))))
p_density_B = round(p_density_B, 3)
# p(含糖率|好瓜)
p_sugar_G = (1 / (math.sqrt(2 * math.pi) * sugG_std)) * np.exp(
-(((testSet[labels.index("含糖率")] - sugG_mean) ** 2) / (2 * (sugG_std ** 2))))
p_sugar_G = round(p_sugar_G, 3)
# p(含糖率|坏瓜)
p_sugar_B = (1 / (math.sqrt(2 * math.pi) * sugB_std)) * np.exp(
-(((testSet[labels.index("含糖率")] - sugB_mean) ** 2) / (2 * (sugB_std ** 2))))
p_sugar_B = round(p_sugar_B, 3)
return p_density_G, p_density_B, p_sugar_G, p_sugar_B
6.计算后验概率
bayes函数:
· 功能:计算待测数据属于每个类别(好瓜、坏瓜)的后验概率 P(c | xi)。
def bayes():
# 计算类先验概率
P_G, P_B = prior()
# 计算离散属性的条件概率
P0_G = P(0, "好瓜") # P(青绿|好瓜)
P0_B = P(0, "坏瓜") # P(青绿|坏瓜)
P1_G = P(1, "好瓜") # P(蜷缩|好瓜)
P1_B = P(1, "坏瓜") # P(蜷缩|坏瓜)
P2_G = P(2, "好瓜") # P(浊响|好瓜)
P2_B = P(2, "坏瓜") # P(浊响|坏瓜)
P3_G = P(3, "好瓜") # P(清晰|好瓜)
P3_B = P(3, "坏瓜") # P(清晰|坏瓜)
P4_G = P(4, "好瓜") # P(凹陷|好瓜)
P4_B = P(4, "坏瓜") # P(凹陷|坏瓜)
P5_G = P(5, "好瓜") # P(硬滑|好瓜)
P5_B = P(5, "坏瓜") # P(硬滑|坏瓜)
# 计算连续属性的条件概率
p_density_G, p_density_B, p_sugar_G, p_sugar_B = p()
# 计算后验概率
isGood = P_G * P0_G * P1_G * P2_G * P3_G * P4_G * P5_G * p_density_G * p_sugar_G # 计算是好瓜的后验概率
isBad = P_B * P0_B * P1_B * P2_B * P3_B * P4_B * P5_B * p_density_B * p_sugar_B # 计算是坏瓜的后验概率
return isGood, isBad
7.完整代码
import numpy as np
import math
import pandas as pd
# 加载数据集函数
# dataSet:训练集 testSet:待测集 labels:样本所具有的特征的名称
def loadDataSet():
dataSet = [['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.697, 0.460, '好瓜'],
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.774, 0.376, '好瓜'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.634, 0.264, '好瓜'],
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.608, 0.318, '好瓜'],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.556, 0.215, '好瓜'],
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.403, 0.237, '好瓜'],
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', 0.481, 0.149, '好瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', 0.437, 0.211, '好瓜'],
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', 0.666, 0.091, '坏瓜'],
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', 0.243, 0.267, '坏瓜'],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', 0.245, 0.057, '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', 0.343, 0.099, '坏瓜'],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', 0.639, 0.161, '坏瓜'],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', 0.657, 0.198, '坏瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.360, 0.370, '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', 0.593, 0.042, '坏瓜'],
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', 0.719, 0.103, '坏瓜']]
testSet = ['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.697, 0.460] # 待测集
labels = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '密度', '含糖率'] # 特征
return dataSet, testSet, labels
# 计算(不同类别中指定连续特征的)均值、标准差
def mean_std(feature, cla): # feature:传入指定将要计算其均值的标准差的特征名称,cla:计算指定分类cla下该特征的条件概率 feature/cla
dataSet, testSet, labels = loadDataSet()
lst = [item[labels.index(feature)] for item in dataSet if item[-1] == cla] # 类别为cla中指定特征feature组成的列表
mean = round(np.mean(lst), 3) # 均值
std = round(np.std(lst), 3) # 标准差
return mean, std
# 计算先验概率P(c)
def prior():
dataSet = loadDataSet()[0] # 载入数据集
countG = 0 # 初始化好瓜=0
countB = 0 # 初始化坏瓜=0
countAll = len(dataSet)
for item in dataSet: # 好瓜个数
if item[-1] == "好瓜":
countG += 1
for item in dataSet: # 坏瓜个数
if item[-1] == "坏瓜":
countB += 1
# 计算先验概率P(c)
P_G = round(countG / countAll, 3)
P_B = round(countB / countAll, 3)
return P_G, P_B
# 计算离散属性的条件概率P(xi|c)
def P(index, cla):
dataSet, testSet, labels = loadDataSet() # 载入数据集
countG = 0 # 初始化好瓜数量
countB = 0 # 初始化坏瓜数量
for item in dataSet: # 统计好瓜个数
if item[-1] == "好瓜":
countG += 1
for item in dataSet: # 统计坏瓜个数
if item[-1] == "坏瓜":
countB += 1
lst = [item for item in dataSet if
(item[-1] == cla) & (item[index] == testSet[index])] # lst为cla类中第index个属性上取值为xi的样本组成的集合
# P = round(len(lst) / (countG if cla == "好瓜" else countB), 3) # 计算条件概率
P = round(len(lst) / (countG if cla == "好瓜" else countB), 3)
return P
# 计算连续属性的条件概率p(xi|c)
def p():
dataSet, testSet, labels = loadDataSet() # 载入数据集
denG_mean, denG_std = mean_std("密度", "好瓜") # 好瓜密度的均值、标准差
denB_mean, denB_std = mean_std("密度", "坏瓜") # 坏瓜密度的均值、标准差
sugG_mean, sugG_std = mean_std("含糖率", "好瓜") # 好瓜含糖率的均值、标准差
sugB_mean, sugB_std = mean_std("含糖率", "坏瓜") # 坏瓜含糖率的均值、标准差
# p(密度|好瓜)
p_density_G = (1 / (math.sqrt(2 * math.pi) * denG_std)) * np.exp(
-(((testSet[labels.index("密度")] - denG_mean) ** 2) / (2 * (denG_std ** 2))))
p_density_G = round(p_density_G, 3)
# p(密度|坏瓜)
p_density_B = (1 / (math.sqrt(2 * math.pi) * denB_std)) * np.exp(
-(((testSet[labels.index("密度")] - denB_mean) ** 2) / (2 * (denB_std ** 2))))
p_density_B = round(p_density_B, 3)
# p(含糖率|好瓜)
p_sugar_G = (1 / (math.sqrt(2 * math.pi) * sugG_std)) * np.exp(
-(((testSet[labels.index("含糖率")] - sugG_mean) ** 2) / (2 * (sugG_std ** 2))))
p_sugar_G = round(p_sugar_G, 3)
# p(含糖率|坏瓜)
p_sugar_B = (1 / (math.sqrt(2 * math.pi) * sugB_std)) * np.exp(
-(((testSet[labels.index("含糖率")] - sugB_mean) ** 2) / (2 * (sugB_std ** 2))))
p_sugar_B = round(p_sugar_B, 3)
return p_density_G, p_density_B, p_sugar_G, p_sugar_B
# 预测后验概率P(c|xi)
def bayes():
# 计算类先验概率
P_G, P_B = prior()
# 计算离散属性的条件概率
P0_G = P(0, "好瓜") # P(青绿|好瓜)
P0_B = P(0, "坏瓜") # P(青绿|坏瓜)
P1_G = P(1, "好瓜") # P(蜷缩|好瓜)
P1_B = P(1, "坏瓜") # P(蜷缩|坏瓜)
P2_G = P(2, "好瓜") # P(浊响|好瓜)
P2_B = P(2, "坏瓜") # P(浊响|坏瓜)
P3_G = P(3, "好瓜") # P(清晰|好瓜)
P3_B = P(3, "坏瓜") # P(清晰|坏瓜)
P4_G = P(4, "好瓜") # P(凹陷|好瓜)
P4_B = P(4, "坏瓜") # P(凹陷|坏瓜)
P5_G = P(5, "好瓜") # P(硬滑|好瓜)
P5_B = P(5, "坏瓜") # P(硬滑|坏瓜)
# 计算连续属性的条件概率
p_density_G, p_density_B, p_sugar_G, p_sugar_B = p()
# 计算后验概率
isGood = P_G * P0_G * P1_G * P2_G * P3_G * P4_G * P5_G * p_density_G * p_sugar_G # 计算是好瓜的后验概率
isBad = P_B * P0_B * P1_B * P2_B * P3_B * P4_B * P5_B * p_density_B * p_sugar_B # 计算是坏瓜的后验概率
return isGood, isBad
if __name__ == '__main__':
dataSet, testSet, labels = loadDataSet()
testSet = [testSet]
df = pd.DataFrame(testSet, columns=labels, index=[1])
print(f"待测集:\n{df}")
isGood, isBad = bayes()
print("后验概率:")
print(f"P(好瓜|xi) = {isGood}")
print(f"P(坏瓜|xi) = {isBad}")
print("预测结果 : 好瓜" if (isGood > isBad) else "预测结果 : 坏瓜")
8.运行结果

四、拉普拉斯平滑修正
1.什么是拉普拉斯平滑修正
在朴素贝叶斯中,若某个属性值在训练集中没有与某个类同时出现过,则训练后的模型会出现 over-fitting 现象。比如 “敲声=清脆” 测试例,训练集中没有该样例,因此连乘式计算的概率值为0,无论其他属性上明显像好瓜,分类结果都是 “好瓜=否” ,这显然不合理。
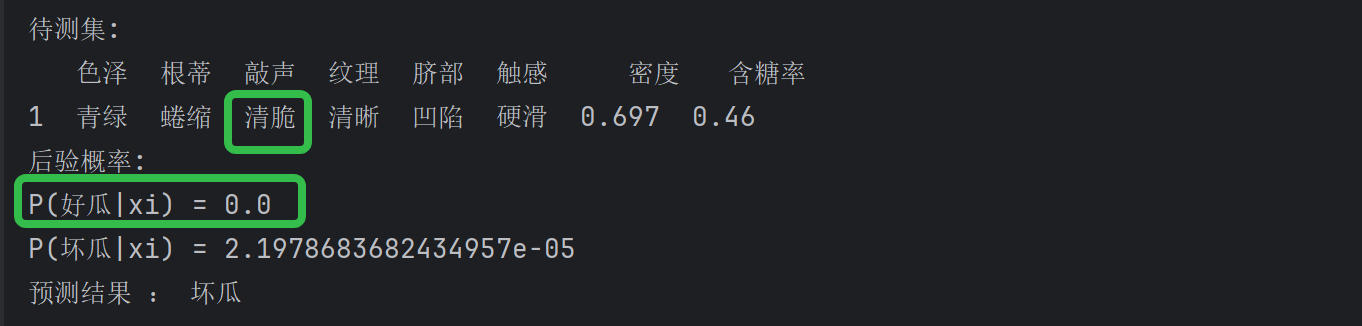
为了避免其他属性携带的信息,被训练集中未出现的属性值 “抹去” ,在估计概率值时通常要进行 “拉普拉斯修正” :令N表示训练集D中可能的类别数,Ni表示第i个属性可能的取值数,则贝叶斯公式修正后为:
P( c ) 进行拉普拉斯修正: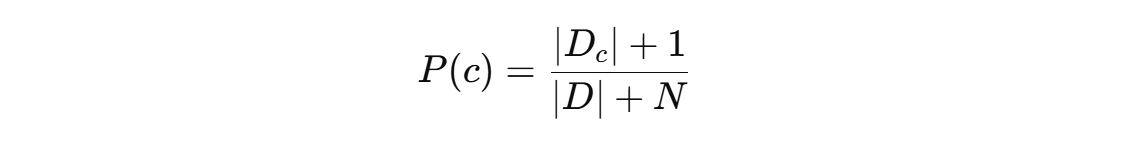
P( xi | c ) 进行拉普拉斯修正: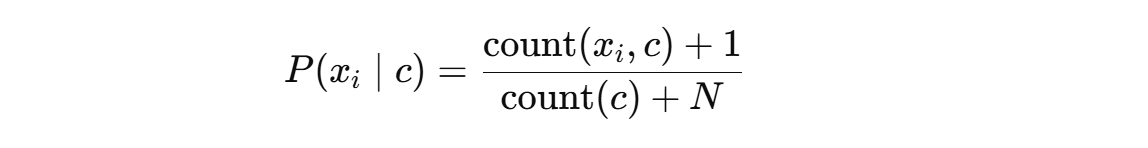
2.代码演示
(1)P( c ) 进行拉普拉斯修正
def prior():
dataSet = loadDataSet()[0]
countG = sum(1 for item in dataSet if item[-1] == "好瓜")
countB = sum(1 for item in dataSet if item[-1] == "坏瓜")
total = len(dataSet)
N_classes = 2 # 类别总数(好瓜和坏瓜)
# 拉普拉斯修正后的先验概率
P_G = (countG + 1) / (total + N_classes)
P_B = (countB + 1) / (total + N_classes)
return round(P_G, 3), round(P_B, 3)
(2)P( xi | c ) 进行拉普拉斯修正:
def P(index, cla):
dataSet, testSet, labels = loadDataSet()
countG = 0 # 好瓜总数
countB = 0 # 坏瓜总数
for item in dataSet:
if item[-1] == "好瓜":
countG += 1
else:
countB += 1
# 拉普拉斯修正:分子+1,分母+属性取值数
feature_values = set(item[index] for item in dataSet) # 当前属性的所有可能取值
N = len(feature_values) # 属性取值数
# 统计当前类别中,指定属性值出现的次数
lst = [item for item in dataSet if (item[-1] == cla) & (item[index] == testSet[index])]
count = len(lst)
# 修正后的条件概率
P = round((count + 1) / ((countG if cla == "好瓜" else countB) + N), 3)
return P
3.运行结果

五、感受
这次朴素贝叶斯分类器的实现实验让我深刻体会到理论与实践之间的差距与联系。最初看到算法简洁的数学公式时,我以为实现会很简单,但真正编码时才发现需要处理许多细节问题。最让我印象深刻的是拉普拉斯修正的实现过程:当直接使用频率估计概率导致零概率问题时,通过引入"+1"和"+N"的平滑处理,不仅解决了算法缺陷,更让我理解了概率论中避免极端值的重要性。在连续特征处理时,高斯分布公式的应用让我意识到理论假设与实际数据的差异,特别是标准差过小导致的数值计算问题,这促使我思考实际应用中数据预处理的关键性。通过反复调试和优化代码结构,我不仅提升了编程效率,更深入理解了算法每个步骤的意义。虽然"特征条件独立"的假设看起来很"朴素",但实验结果证明这种简化在很多情况下依然有效,这让我对奥卡姆剃刀原则有了更直观的认识。整个实验过程中,从最初的困惑到最后的豁然开朗,我最大的收获不是完成了一个分类器,而是学会了如何将抽象的数学公式转化为可执行的代码逻辑,以及如何通过实践来验证和深化理论知识。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)