【高中生讲机器学习】29. 马尔可夫随机场 2w 字详解!超!系!统!
创建时间:2024-12-12
首发时间:2024-12-18
最后编辑时间:2024-12-18
作者:Geeker_LStar
你好呀~这里是 Geeker_LStar 的人工智能学习专栏,很高兴遇见你~
我是 Geeker_LStar,一名高一学生,热爱计算机和数学,我们一起加油~!
⭐(●’◡’●) ⭐
oohhhh!! 我来啦!
上上篇中我们讲完了贝叶斯网络,这篇我们就来延续概率图模型这个话题,讲讲它的另一个分支——马尔可夫随机场(MRF)!
(注:马尔可夫随机场和马尔可夫网络是一个东西,后面有可能两种叫法都会出现。
马尔可夫网络和贝叶斯网络有很多相似的地方,所以这一篇会省略掉一些之前已经讲过的东西,可以先去看看贝叶斯网络!!:
okay! 那我们开始这一篇!
文章目录
无向图
在贝叶斯网络(BN)那一篇我们讲过,BN 使用有向无环图来描述变量之间的依赖关系。
和 BN 不同,MRF 使用无向图来建模变量之间的依赖关系。so 我们先来简单回顾一下无向图。
注意,我们说的是无向图,而不是无向无环图,所以图中是可以有环的。
先放一个无向图在这里,我觉得这部分应该不需要讲太多。
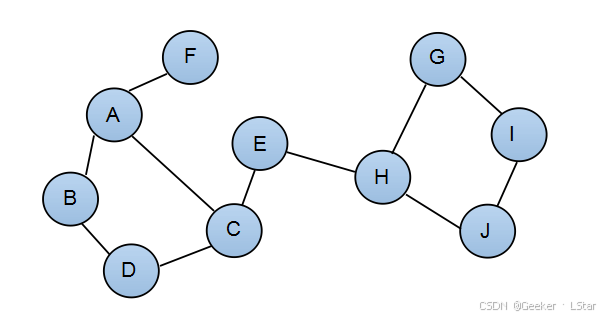
其实看图就很简单了,无向图无非就是少了箭头嘛,节点之间没有父子的概念了,边连接的任意两个节点的关系都是相互的。
在贝叶斯网络中,有向无环图建模的是变量之间的因果关系。父节点代表因,子节点代表果,又从此延伸出了条件独立性的概念和联合概率分解等等等。
我们可以说,有向无环图适用于变量之间有明确因果关系的情境。
那,如果变量之间没有明确的因果关系呢?或者说,如果变量之间的依赖是相互的呢?
这时候就该无向图出场了呀!
无向图中没有父节点和子节点的概念。如果两个节点是相连的,说明它们是互相影响的。也就是说,无向图适用于变量之间具有双向依赖的情境。
for eg,在一张照片中,像素之间的关系就可以抽象成一个无向图。因为相邻像素之间没有因果关系,它们是双向依赖的。(比如说,你不能说因为像素 A 是 (114,51,4),所以像素 B 是 (19, 198, 10)。像素之间的关系是平行的。(????????????呃虽然但是呃我真的有在好好举例子吗。。。。)
well,其实这一部分主要说明了在 MRF 中使用无向图暗示了什么,这是很重要的,因为图结构,或者说图结构暗示的变量之间的关系,会直接影响到我们后面对条件独立性的分析和分解联合概率的方式。
好吧,或许也不能说是图结构暗示的变量之间的关系,因为我们是根据变量之间的关系选择的合适的图结构…嗯…不过其实两种方式都可以理解,选择好理解的一种方式就 ok 啦!
豪德,做完一些铺垫,我们可以正式进入 MRF 的讲解咯!
马尔可夫网络概述
马尔可夫网络,或者说马尔可夫随机场,英文全称 Markov Random Field,是概率图模型的另一大分支。
和贝叶斯网络建模变量间的因果关系不同,马尔可夫网络主要用于建模变量间的双向依赖关系,它使用的图结构是无向图。
还记得在贝叶斯网络那一篇中我们提到的,概率图模型的两大关键点吗?
- 图结构是如何建模变量间的依赖关系的?
- 图结构是如何简化概率计算的?
对于第一个问题,回答比较简单——MRF 使用无向图建模变量之间的双向(对称)依赖关系。在 MRF 中,如果两个节点间有边相连,就表明这两个节点是互相影响的。
比如下面就是一个马尔可夫网络:
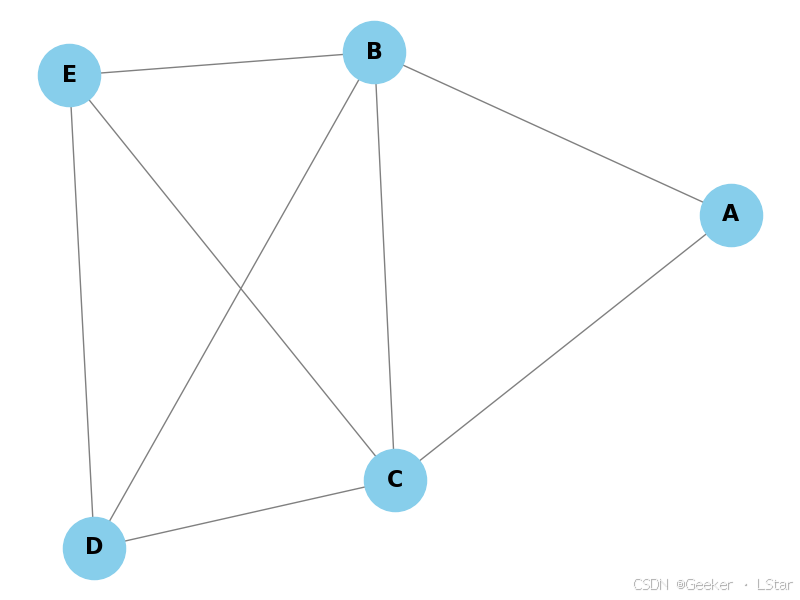
其中 A 和 B、C 两个节点就是相互影响的。B、C、D、E 分别和其它四个节点都是相互影响的。
豪德,接下来我们转向第二个问题——无向图结构如何简化概率计算?
显然,我们并不想计算
P ( A , B , C , D , E ) = P ( A ) P ( B ∣ A ) . . . P ( E ∣ A , B , C , D ) P(A,B,C,D,E)=P(A)P(B|A)...P(E|A,B,C,D) P(A,B,C,D,E)=P(A)P(B∣A)...P(E∣A,B,C,D)
嗯,这就要说到 MRF 的条件独立性假设了。它可以表述为:
在 MRF 中,每个节点的状态只和与它直接相连的节点相关。或者说,在给定与这个节点直接相连的所有节点之后,这个节点和所有与它不直接连接的节点条件独立。
然后,根据这个结论,我们写出 MRF 的联合概率分解。
o,你以为会是类似于下面这样吗?其中每个节点的条件都是与它直接相连的节点。
P ( A , B , C , D , E ) = P ( A ∣ B , C ) P ( B ∣ A , C , D , E ) . . . P(A,B,C,D,E)=P(A|B,C)P(B|A,C,D,E)... P(A,B,C,D,E)=P(A∣B,C)P(B∣A,C,D,E)...
其实并不是o(moo ),真正的写法是:
P ( X ) = 1 Z ∏ C ∈ C exp ( − E ( X C ) ) P(X)=\frac 1 Z \prod_{C{\in \mathcal{C}}}\exp(-E(X_C)) P(X)=Z1C∈C∏exp(−E(XC))
其中 X X X 代表图中所有的随机变量, X C X_C XC 就是我们之前讲过的最大团, E ( Y C ) E(Y_C) E(YC) 是定义在最大团上的能量函数, exp ( − E ( Y C ) ) \exp(-E(Y_C)) exp(−E(YC)) 其实只是对能量函数的变形,我们称之为势函数。 Z Z Z 是规范化(归一化)因子,即:
Z = ∑ ∏ C ∈ C exp ( − E ( X C ) ) Z=\sum\prod_{C{\in \mathcal{C}}}\exp(-E(X_C)) Z=∑C∈C∏exp(−E(XC))
其中 ∑ \sum ∑ 代表了 X X X 所有可能的情况。
aaa 怎么突然冒出这么多新概念??没事,后面我们都会讲到的,而且会很详细。这些都是最核心的概念。
用到我们的例子中,即:
P ( A , B , C , D , E ) = 1 Z exp ( − E ( A , B , C ) ) × exp ( − E ( B , C , D , E ) ) P(A,B,C,D,E)=\frac 1 Z \exp(-E(A,B,C)) \times \exp(-E(B,C,D,E)) P(A,B,C,D,E)=Z1exp(−E(A,B,C))×exp(−E(B,C,D,E))
可以看到,图中的最大团有两个:A、B、C 和 B、C、D、E。这里用到了它们。
这是 MRF 的第二个重要结论:MRF 的联合概率可以表示为最大团上的势函数的乘积。
well,但这只是两个结论。我们关心的是,这个两个结论是哪来的?
okay,接下来我们深入这个话题,来看一看 MRF 条件独立性和联合概率分解的基础——马尔可夫性。
马尔可夫性
马尔可夫性,如果你看过 HMM 那篇,你应该听过这个这个名词。在 HMM 中,它描述了一种概率依赖关系。更进一步,它假设当前的状态只依赖于前一个时间的状态,而和更早的状态无关;类似的,将来一个时间的状态只依赖于当前的状态,而和过去的状态无关。
简而言之,在 HMM,或者说在有向无环图中,马尔可夫性描述了一种 “一步” 的依赖关系。
那在 MRF,或者说在无向图中,马尔可夫性又是什么意思捏~?
其实叙述起来也很简单——在 MRF 中,对于一个节点,在给定与它直接相连的所有节点后,它和其他与它不直接相连的节点条件独立。(提前剧透一下,这只是无向图中马尔可夫性的一种叙述o,还有另外两种,后面都会说到~
比如说,现在给定一个节点 a a a,和它相连的节点集合记为 B B B,剩余的和它不直接相连的节点集合记为 C C C。
那么,根据条件独立性的定义,我们有:
P ( a , C ∣ B ) = P ( a ∣ B ) P ( C ∣ B ) P(a, C|B)=P(a|B)P(C|B) P(a,C∣B)=P(a∣B)P(C∣B)
这就是 MRF(无向图)中马尔可夫性的数学叙述(之一)。
(ooo 注意,关于条件独立性的定义和解释,在 BN 那篇中都有说明,如果这里感觉很突兀可以去看看那篇~
注意注意,这里是一个重要的区别——时间序列中的马尔可夫性是有方向的(因为时间是单向的,从过去到未来),但无向图,或者说 MRF 中的马尔可夫性是没有方向的。MRF 中,一个节点和它左边的节点有连接,那么这种依赖关系是双向的,即这个节点会对它左边的节点产生影响,它左边的节点也会对它产生影响。
en…为什么呢?为什么都是马尔可夫性,却有两套表述,或者说两套依赖体系?
这又要说回图结构了。
前面时间序列的例子,也就是 HMM,属于有向无环图,所以它的马尔可夫性描述的是有方向的一步依赖。而 MRF 属于无向图,所以它的马尔可夫性描述的是没有方向,或者说双向的一步依赖。
也就是说,马尔可夫性的具体表述是和图结构有关的。记住这一点o,不要搞混了 HMM 和 MRF 的马尔可夫性。
en,不过我们不妨再看深入一点。
为什么 HMM 中的依赖关系是有方向的一步依赖呢?
其实正确的思维路径应该是,因为我们的任务是时间序列数据,时间是单向的,所以选择 HMM,或者说 BN,会比选择 MRF 更合适。
我认为,说 “因为时间是单向的,所以 HMM 中的依赖关系是有方向的” 是不合适的。HMM 只是个模型,它不会因为任何特定的任务而改变它自身的性质,我们是在根据任务的性质选择合适的模型,而不是用模型的性质去说明任务为什么是这样的。
还是那句话,虽然很多情况下我们都说,图结构反映了任务/场景的什么什么性质,但其实更多的时候,我们都是先确定了任务中的依赖属于哪种关系(因果 or 对称),再据此选择对应的图结构。
啊…好像又说绕了。我自己明白我在说什么,但是我不知道我是否表述清楚了。。。
如果你对上述内容感到疑惑,可以忽略它,只需要记住 MRF 中的马尔可夫性是双向的就可以了。
接下来我们来看看马尔可夫的具体表述吧!!
okyyyy,这里细化一下之前留下的悬念,无向图中的马尔可夫性有三种,分别是成对马尔可夫性、局部马尔可夫性和全局马尔可夫性。下面我们会分别说明这三个性质!
成对马尔可夫性
okaaay,我们先从成对马尔可夫性开始吧!(后面你会知道为什么是这个顺序。
成对马尔可夫性描述两个特定的节点之间的关系。它的意思是,对于图中任意不相连的两个节点,在给定图中所有其它节点的情况下,这两个节点条件独立。
还是来看图吧,图中两个中心节点(红色)我们要分析的。蓝色节点是所有给定的节点。
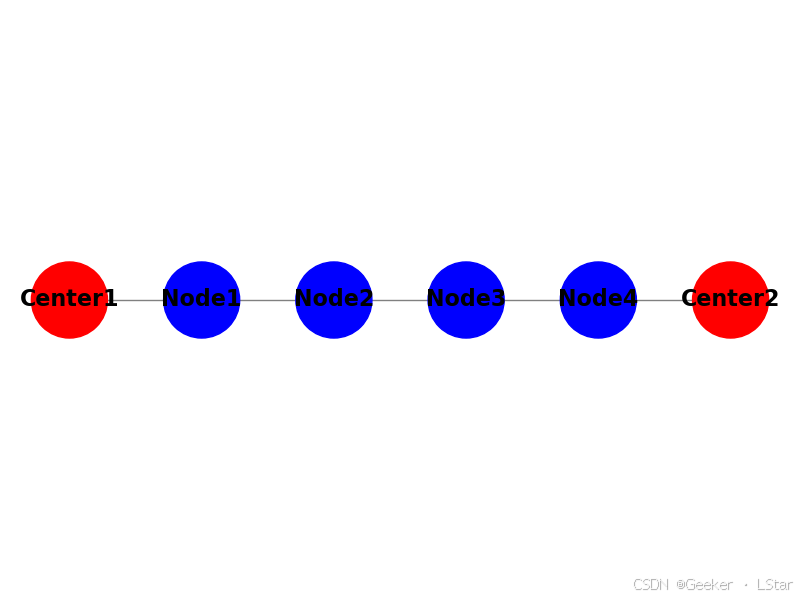
成对马尔可夫性是说,在给定图中所有蓝色节点的情况下,两个红色节点条件独立。
如果我们用 Y r 1 Y_{r1} Yr1 代表左边的红色节点, Y r 2 Y_{r2} Yr2 代表右边的红色节点, Y B Y_B YB 代表所有蓝色节点。那么成对马尔可夫性写成数学公式就是:
P ( Y r 1 , Y r 2 ∣ Y B ) = P ( Y r 1 ∣ Y B ) P ( Y r 2 ∣ Y B ) P\left(Y_{r1}, Y_{r2} \mid Y_{B}\right)=P\left(Y_{r1} \mid Y_{B}\right) P\left(Y_{r2} \mid Y_{B}\right) P(Yr1,Yr2∣YB)=P(Yr1∣YB)P(Yr2∣YB)
这等价于:
P ( Y r 1 ∣ Y O ) = P ( Y r 1 ∣ Y O , Y r 2 ) P\left(Y_{r1} \mid Y_{O}\right)=P\left(Y_{r1} \mid Y_{O}, Y_{r2}\right) P(Yr1∣YO)=P(Yr1∣YO,Yr2)
oki 呀,可以说,成对马尔可夫性反映的是特定的两个节点之间的关系,接下来我们来看看局部马尔可夫性,它反映了特定的一个节点和其它一些节点之间的关系。
局部马尔可夫性
局部马尔可夫性可能是我们最常见的一种马尔可夫性,它可以简单概括为:一个节点的状态只和与它直接相连的所有节点有关。
或者说,在给定与这个节点直接相连的所有节点后,这个节点与其它所有节点条件独立。
e 其实就是在上一个小部分中我说的那个。
下面是一张描述局部马尔可夫性的图,其中红色的是中心节点(我们要分析的节点),绿色的是与它直接相连的所有节点,蓝色的是其它节点。
(呃虽然但是这是我用 matplotlib 画的图(显然用 PPT 画图会把我整死 ),虽然稍显奇怪,但是基本的意思还是可以看出来的。
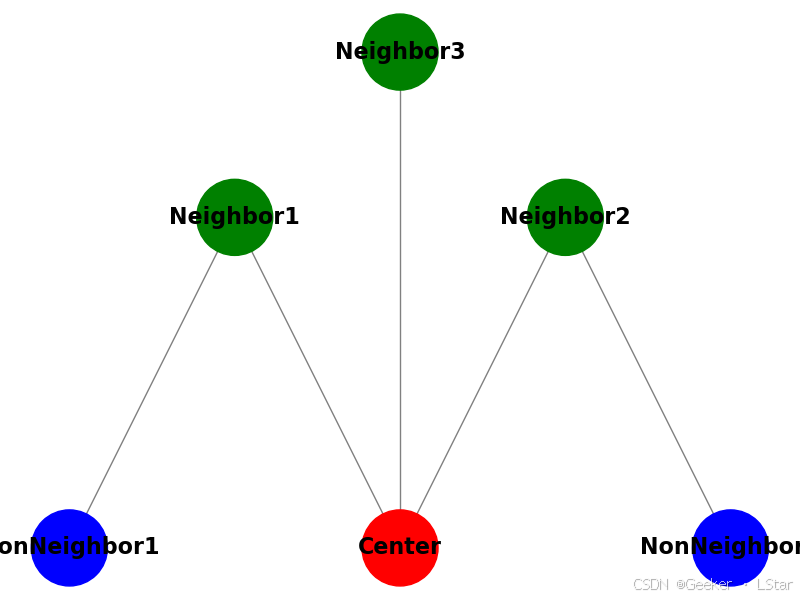
如果我们用 Y r Y_r Yr 表示中心节点(红色), Y G Y_G YG 表示所有和中心节点直接相连的节点(绿色), Y B Y_B YB 表示所有和中心节点不直接相连的节点(蓝色)。
那么,根据局部马尔可夫性,我们可以知道,在给定所有绿色节点的情况下,红色节点和所有蓝色节点条件独立,即:
P ( Y r , Y B ∣ Y G ) = P ( Y r ∣ Y G ) P ( Y B ∣ Y G ) P\left(Y_{r}, Y_{B} \mid Y_{G}\right)=P\left(Y_{r} \mid Y_{G}\right) P\left(Y_{B} \mid Y_{G}\right) P(Yr,YB∣YG)=P(Yr∣YG)P(YB∣YG)
oki,接下来我们来看看全局马尔可夫性,它在局部马尔可夫性的基础上更进一步,反映了一些节点和另一些节点之间的关系。
全局马尔可夫性
全局马尔可夫性,听这个名字就不简单啊不是。
前面我们已经研究了一个变量和一个变量之间的条件独立性以及一个变量和一些变量之间的条件独立性。按照这个 “规律”,接下来我们该研究什么了?
——一些变量和一些变量之间的条件独立性!这可太合理了((
没错,全局马尔可夫性就是干这个的。全局马尔可夫性如果正着说会很复杂,so 我在这里采用一种简单的说法:对于图中给定的任意两组节点集合,如果对于一个集合中的任意节点,另一个集合中都没有一个与之直接相连的节点,那么在给定图中所有其它节点的情况下,这两个节点集合彼此条件独立。
再简化一点,如果两个节点集合中的节点两两都不相连,那么在给定图中所有其它节点的情况下,这两个节点集合彼此条件独立。
依然是看图,不过这次的中心节点是两个集合而不是两个点了。图中红色的部分是两组中心节点,蓝色的部分是给定的其它节点
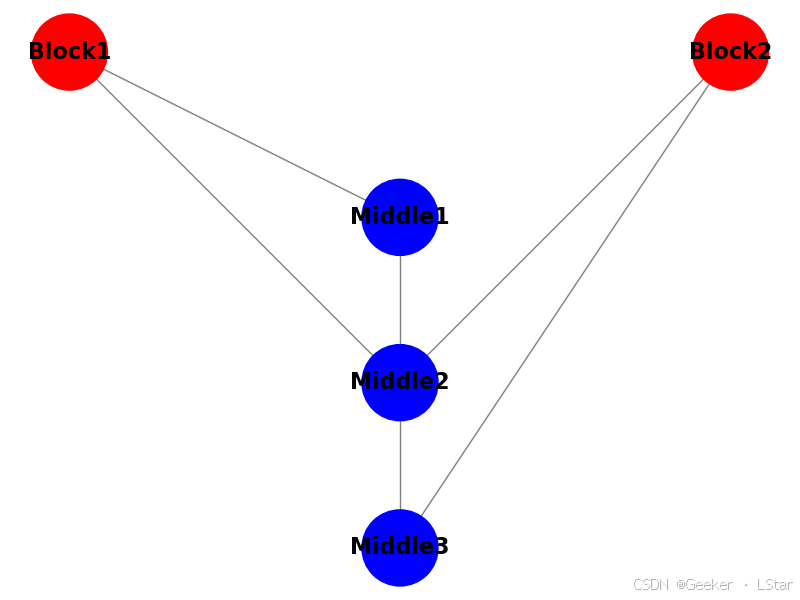
如果我们把左边的红色节点们记作 Y R 1 Y_{R1} YR1,右边的红色节点们记作 Y R 2 Y_{R2} YR2,所有的蓝色节点记作 Y B Y_B YB,全局马尔可夫性告诉我们:
P ( Y R 1 , Y R 2 ∣ Y B ) = P ( Y R 1 ∣ Y B ) P ( Y R 2 ∣ Y B ) P(Y_{R1}, Y_{R2}|Y_B) = P(Y_{R1}|Y_B)P(Y_{R2}|Y_B) P(YR1,YR2∣YB)=P(YR1∣YB)P(YR2∣YB)
豪德,这就是 “最高级” 的版本了()现在三个独立的我们都看完了,我们不妨来做一波总结…(((
三者的关系
weeeeell,现在我们终于讲完了马尔可夫性的三种表述!!!
我认为这三种表述是层层递进的(这也是为什么我按照这个顺序讲它们)。成对马尔可夫性聚焦于特定的两个节点,局部马尔可夫性关注特定的一个节点和其它一些节点,全局马尔可夫性则从一些节点和另一些节点出发。
你可能会好奇,诶,不是有三个吗,那我怎么知道在什么情境下应该用哪一个?
诶嘿,其实,它们三个是等价的!换言之,你用哪个都行。
至于为什么这三者等价,其实也比较简单。
从成对马尔可夫性出发可以得到局部马尔可夫性,只需要固定成对马尔可夫性中的两个中心节点之一不变,不断改变另一个节点(让它扫过不变的那个节点的所有不相连节点),就可以得到固定的那个节点和所有非相连节点都条件都条件独立,即局部马尔可夫性。
从局部马尔可夫性又可以推导出全局马尔可夫性。因为全局马尔可夫性其实就是两个节点集合中所有节点的局部马尔可夫性同时成立得来的(比如,上面的例子中,两个红色集合中的每个点都满足局部马尔可夫性,所以这两个集合中没有任意两对点是非条件独立的,导致最终这两个集合是彼此条件独立的。
嗯,然后,从全局马尔可夫性显然可以推出局部马尔可夫性,只需要把全局马尔可夫性两个节点集合之一换成一个单独的节点。
从局部马尔可夫性又可以推出成对马尔可夫性,只需要把局部马尔可夫性中的节点集合换成一个单独的节点。
emmm(), 上面这些推理思路反映出什么??
这三个马尔可夫性,彼此互为充分必要条件!它们之间的推导过程是这样的:
A → B → C → B → A A \to B \to C \to B \to A A→B→C→B→A
这不就是等价吗?
耶,现在我们理解为什么它们三个等价了!!!
well,我们 “活学活用” 一下,其实这三者的关系也可以用一个无向图来表示,只不过这个无向图是有环的,如下:
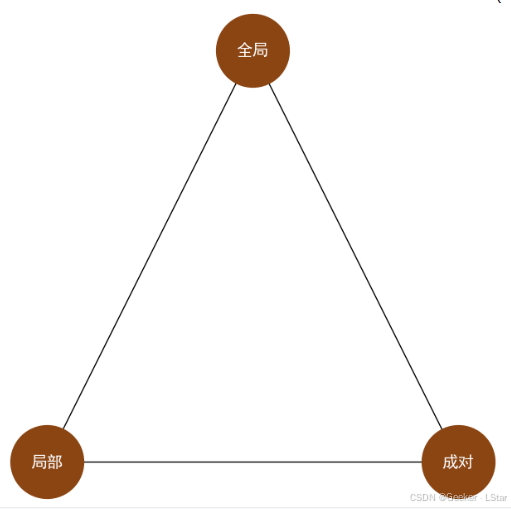
呃我觉得我代码写的挺正常的为什么画出来这么丑。
如果你没有理解这部分(为什么等价)在讲什么,no matter,直接记住这个结论就可以啦。
不过,在做联合概率分解的时候,通常我们用局部马尔可夫性,因为在联合概率分解的背景下,我们关注的是局部(每一个变量)和其它变量之间的依赖关系。和成对、全局的关系不大。
嘿嘿,还是说一下吧。其实在这里我玩了一个文字游戏,我本来打的是 “三种马尔可夫性”,但是后来转念一想,诶不行,它们三个是同一个概念的三种不同但等价的表述,so 又改成了 “马尔可夫性的三种表述”,咳咳咳(((不知道有没有人发现(溜~
好欸!我想现在你已经对马尔可夫性的三种表述有所了解啦!接下来我们就从马尔可夫性出发,来解决一下 "图结构如何简化概率分布” 这个问题。(重点重点重点来啦!!!
MRF 的因子分解
和 BN 类似,我们接下来要依据条件独立性,对复杂的联合概率(此时每个节点都和图中的所有其它节点有关)进行化简。
MRF 联合概率的化简,又叫 MRF 的因子分解,是一个很不好理解的过程(反正我看了好久哈哈哈哈)。我会把它分成很多个步骤来讲!!
团与最大团
first,要理解 MRF 的因子分解,我们需要知道我们分解完的东西是什么。换言之,我们分解的最小单位是什么。
这涉及到两个概念——团和最大团。
团是指图中的一个完全子图,这个子图中的每个点之间都有边相连。
最大团是一个团,并且加入任何一个新的节点都会破坏这个团。或者说加入任何一个新的节点后,原来的团就不是团了。
也就是说,如果有一个团,向这个团中加入任意一个新的节点,都会破坏这个团 “每两个节点之间都有边相连” 的性质,那么这个团就是一个最大团。
注意,最大团不是说包含节点最多的团。比如我现在有一个包含五个节点 1、2、3、4、5 的图,它当中两个节点 1、2 和三个节点 3、4、5 可以同时是最大团,只要它们符合最大团的定义。
下图左右两边都是一个团,但右边的团是最大团(而左边的团不是)。因为在左边的团中加入新的节点(4)后,得到的依然是一个团。
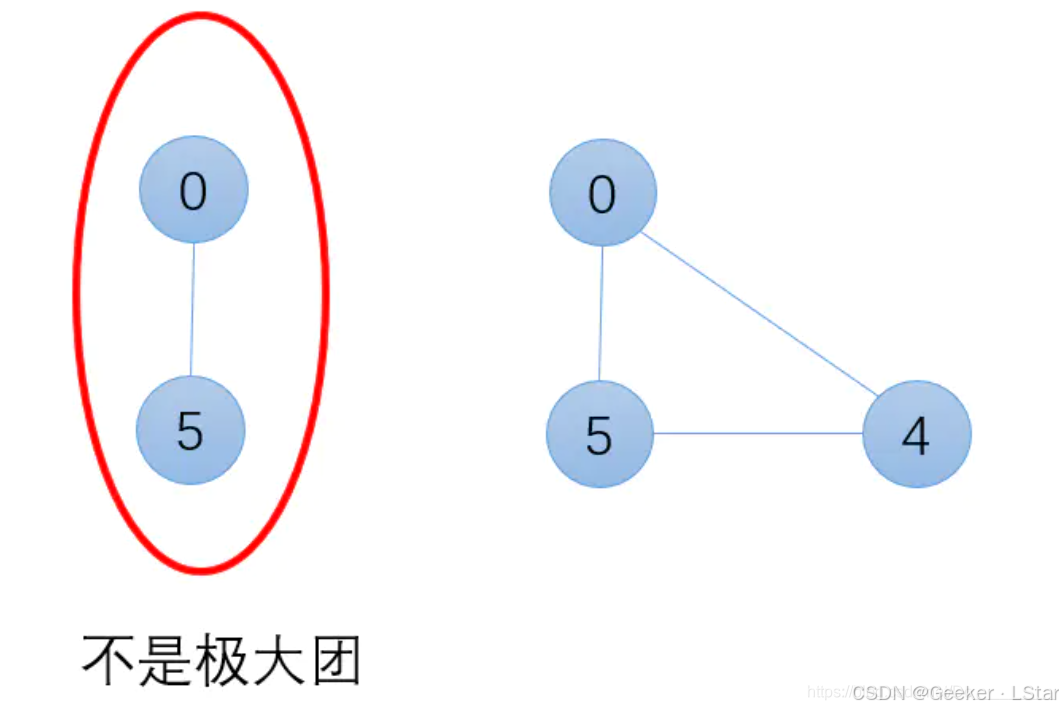
okay,团和最大团是无向图分解中最基本的知识,MRF 分解的最小单位就是最大团。这个我们后面会讲到!
不过,在开启后续内容之前,我们需要先插入一些背景知识…((
吉布斯分布
okay,我们从吉布斯分布开始吧。(呃呃呃谁懂,写这个的时候化学课刚好开始讲吉布斯自由能???这俩甚至还是一个人搞出来的。。然后我就边听那个边写这个()
吉布斯分布是一种包含能量函数的概率分布。确切地说,它衡量通过能量函数来衡量一个系统处于某种状态的概率。
可能在我们日常的情景当中,能量和概率之间没有什么联系。但在物理学中这俩的联系可就大了——在物理学中,我们认为,一个系统的能量越低,它的(这种状态)就越稳定;一个系统(的某种状态)越稳定,它处于这种状态的概率就越大。
也就是说,一个物理系统更倾向于处于能量更低的状态。
en,其实吉布斯分布最早是用于统计物理中的,后来才被引入到了机器学习领域。
理解了吉布斯分布要干什么,进一步的任务来了——如何用数学公式表示吉布斯分布?
这里先给出吉布斯分布的公式,然后我会详细说明它为什么长成这个样子。
P ( x ) = 1 Z exp ( − E ( x ) ) , Z = ∑ x exp ( − E ( x ) ) P(x)=\frac{1}{Z} \exp (-E(x)), \ Z=\sum_x \exp(-E(x)) P(x)=Z1exp(−E(x)), Z=x∑exp(−E(x))
其中 E ( x ) E(x) E(x) 就是处于系统处于这种状态时的能量。 Z Z Z 是配分函数,在前面的文章当中我们已经见过它很多次了,它保证了这个式子构成一个合法的概率分布,即概率密度函数曲线下的面积总为 1。
豪德,这个式子还是太抽象了,我们画个图吧。
下图就是吉布斯分布的函数图像,横轴是能量函数 E ( x ) E(x) E(x),即系统处于特定状态下的能量;纵轴是系统处于这种状态的概率。
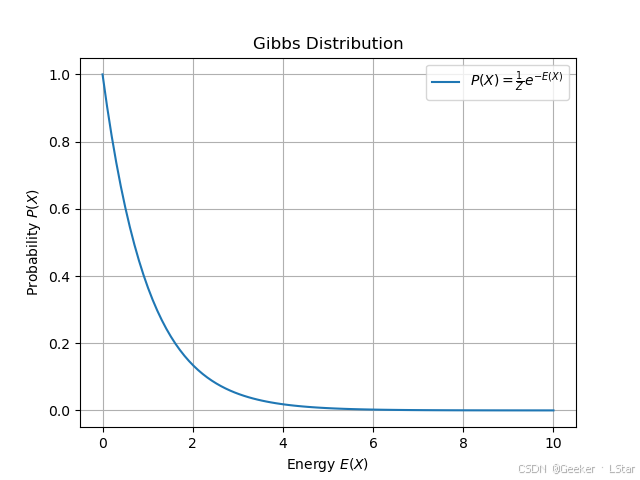
从图中我们可以直观地看出,状态的能量越小,系统处于这种状态的概率就越大。这个公式和吉布斯分布反映的意思是一样的!
(o 这里插一句话,你可能会好奇能量函数到底是什么东西。先不用着急,后面我们会说到的~
然后解释一下为什么要用 exp \exp exp。
我们的出发点是,一个状态的能量越低就越稳定,越稳定的状态出现的概率越高,所以一个状态的能量越低,系统处于这种状态概率就越高。
well,单调性转换一下,一个系统的能量的相反数越高,其出现的概率就越高。
这很合理,那我们能不能直接把概率建模为能量的相反数?就是说,直接让 P ( x ) = 1 Z ( − E ( x ) ) P(x)=\frac 1 Z (-E(x)) P(x)=Z1(−E(x))
呃。。注意到(bushi),如果直接这么建模,那只要能量是正数, P ( x ) P(x) P(x) 就会是负数。但是,概率显然需要是正数,so 我们需要一个函数,它不改变原来的单调性,同时还能保证得到的概率总是正的。
这 exp \exp exp 不就来了嘛!
给 − E ( x ) -E(x) −E(x) 外面套一层 exp \exp exp,不改变原来 − E ( x ) -E(x) −E(x) 和 P ( x ) P(x) P(x) 之间的关系(同向变化、单调递增),同时还能保证得到的概率总是正的。
嗯,现在你就理解吉布斯分布的式子的来源啦!本质上就一句话:能量越低,概率越高。形式只是为了保证概率的非负性。
吉布斯随机场
豪德,我觉得吉布斯分布已经说的很清楚啦,接下来我们从它出发,来看更复杂的情景。
我们可以把吉布斯分布推广到复杂的图结构上,这时候我们就得到了吉布斯随机场,或者说 GRF。但是这个时候我们就需要考虑能量函数计算的问题了——如何计算一个复杂图结构(状态)的能量?
well,有个算法叫分治。那我们是不是也可以采用类似的思想,把复杂图结构中的能量函数的计算拆解为在各个小部分上能量函数的计算。
或者,说的更好理解一些,对于一个复杂的图结构,它全局的能量可以分解为多个局部能量之和。最小化全局能量的任务可以拆解到最小化每一个局部能量。
那么,这个 “局部” 是怎么定义的呢?yes 没错,就是我们前面说过的最大团。
换言之,吉布斯随机场的能量函数可以表示为定义在各个最大团上的吉布斯分布的能量函数之和。
e 这其实恒河里(很合理),把全局能量分解为各个局部的能量。
至于为什么是分解到各个最大团上,no why,这是 GRF 的规定。
那么,按照我们说的,吉布斯随机场的联合概率分布可以写为下式:
P ( X ) = 1 Z exp ( ∑ C ∈ C − E ( X C ) ) P(X)=\frac{1}{Z} \exp (\sum_{C \in \mathcal{C}}-E(X_C)) P(X)=Z1exp(C∈C∑−E(XC))
其中 X C X_C XC 就是每个极大团, E ( X C ) E(X_C) E(XC) 就是这个极大团上的能量函数。
en,其实我们也可以利用 exp \exp exp 的性质,把 ∑ \sum ∑ 提到外面来变成 ∏ \prod ∏。即:
P ( X ) = 1 Z ∏ C ∈ C exp ( − E ( X C ) ) P(X)=\frac{1}{Z} \prod_{C \in \mathcal{C}}\exp (-E(X_C)) P(X)=Z1C∈C∏exp(−E(XC))
不难发现 exp ( − E ( X C ) ) \exp(-E(X_C)) exp(−E(XC)) 就是最大团上的未规范化(没有 Z Z Z)概率。
这样的话,GRF 的联合概率分布就可以描述成,各个最大团上的未规范化概率的乘积。
好了用一句话总结一下 GRF:
吉布斯随机场是建立在吉布斯分布之上的(废话 ),它的总能量是各个最大团上的能量的和,它的联合概率可以被分解为各个最大团上的未规范化概率的乘积。
okiiiii,现在我们的 “背景知识” 差不多铺垫完成了,,,接下来我们来看一个非常重点的地方!!!
H-C 定理
好的,好的,好的。事情到这里开始变得有意思了!
你可能刚才一直在想,这篇文章不是讲马尔可夫随机场的吗,怎么突然开始说吉布斯去了还说了好久,,,
well,恭喜你发现了问题的关键!(((
为什么我说了好多吉布斯分布/随机场相关的东西?
因为它们和马尔可夫随机场之间有非常非常紧密的联系!
重点来啦!(敲黑板!
先放结论:马尔可夫随机场和吉布斯随机场是等价的。
这个等价性有两条含义:
- 如果一个随机场是马尔可夫随机场,则它的联合概率分布可以用吉布斯分布表示
- 如果一个随机场是吉布斯随机场,则它满足马尔可夫性。
我们主要关注第一条含义,因为它的主语是 MRF,我们研究的对象。
我们想想,我们最初,是想要得到什么来着?
我们想要说明,为什么 MRF 的联合概率分解可以写成所有最大团上的势函数(能量函数的变形)的乘积的形式。
现在,从 MRF 和 GRF 的等价性出发,我们知道了,如果一个随机场是 MRF,则它的联合概率分布可以用 GRF 表示。
而在上一小节,我们又说明了 GRF 的表示——各个最大团上未规范化吉布斯分布的乘积——也就是各个最大团上势函数的乘积。
这不就说明了为什么 MRF 的联合概率分解可以写成那样了吗?
!!!
所以,现在没有被串起来的链条只剩下一个了——如何说明 MRF 和 GRF 的等价性?
这就要说到这个小节的标题了,H-C 定理,全称 Hammersley-Clifford 定理。
这个定理说明了这个等价性。
不过,这个定理的证明过程实在是太长,这里不展开写,你可以在下面这个网站中找到对应的证明过程:
H-C 定理证明!!(虽然但是这可是 yale 数理统计课的 pdf 啊我天。。。
(e 其实我觉得这个证明真的很难懂,,,等我搞懂了所有细节之后我或许会把这个坑填上…
好诶,到现在,我们算是把整条链条都梳理通了!
说真的我觉得我写的这一串思路真的很好,我觉得如果不从最初始的地方开始一点点推出结论的话,这块真的非常令人 confuse。。。
okay!! 那我们下一个小节就来总结一下 MRF 的因子分解吧。
MRF 的因子分解
终于到这个部分了。
我感觉其实前面好几个小节的铺垫都是为了流畅而自然地引出这个部分。
我们现在已经非常明白 MRF 因子分解的来源了,它的公式可以写成:
P ( X ) = 1 Z ∏ c ∈ C exp ( − E ( X C ) ) P(X)=\frac{1}{Z} \prod_{c\in\mathcal{C}}\exp (-E(X_C)) P(X)=Z1c∈C∏exp(−E(XC))
用一句话总结就是:MRF 的联合概率可以表示为所有最大团上势函数(本质是能量函数),或者说未规范化概率,的乘积的形式。
Ising Model 与能量函数
well,上面我们一直在说能量函数,但是貌似一直都是用 E ( x ) E(x) E(x) 表示的,好像还没有给出过一个具体的格式…?
嗯! 这一部分会给出一个具体的格式,嘿嘿。
前面说过,能量函数衡量的是一个系统状态的稳定性。这其实可以从两个方面来看。
- 系统中每个组成部分自身的稳定性。
- 系统中每个组成部分互相作用的时候的稳定性。
这两条都很好理解。如果一个系统的各个组分本身很不稳定,或这些组分相互作用(共存)的时候很不稳定,那这个系统都是不稳定的,或者说都会具有较高的能量。
相反,如果一个系统中的组分本身很稳定,且相互作用的时候也很稳定,那这个系统一定是稳定的,或者说具有较低的能量。
从这两条出发,我们可以对能量函数的设计有一个初步的想法。——这个函数要同时衡量各个组分本身的稳定程度和它们相互作用(共存)时的稳定程度。
一个直观而自然的想法形成了:能量函数有两个部分,一部分反映组分自身的稳定程度,一部分反映组分相互作用的稳定程度。
okay! 从这个想法出发,我们把(一个最大团上的)能量函数的结构写出来,如下:
E ( X C ) = ∑ i ∈ C U ( x i ) + ∑ ( i , j ) ∈ C V ( x i , x j ) E(X_C)=\sum_{i \in C} U\left(x_i\right)+\sum_{(i, j) \in C} V\left(x_{i}, x_{j}\right) E(XC)=i∈C∑U(xi)+(i,j)∈C∑V(xi,xj)
其中 X C X_C XC 就是这个最大团中的所有节点,式子的前一项 U U U 衡量的是组分自身的稳定程度,后一项衡量的是组分相互作用的稳定程度。
这就是 MRF 中能量函数的基本形式!
okay,现在我们总算是可以把前面写的联合概率分解中的能量函数展开了,算是有了一个清晰且较为统一的格式。
− ∑ C ∈ C E ( X C ) = ∑ C ∈ C ( ∑ i ∈ C U ( x i ) + ∑ ( i , j ) ∈ C V ( x i , x j ) ) -\sum_{C \in \mathcal{C}} E(X_C)=\sum_{C \in \mathcal{C}}\left(\sum_{i \in C} U\left(x_{i}\right)+\sum_{(i, j) \in C} V\left(x_{i}, x_{j}\right)\right) −C∈C∑E(XC)=C∈C∑ i∈C∑U(xi)+(i,j)∈C∑V(xi,xj)
那么,整个联合概率分解就可以写成:
P ( X ) = 1 Z ∏ c ∈ C exp ( − E ( X C ) ) = 1 Z ∏ c ∈ C exp ( − ∑ i ∈ C U ( x i ) − ∑ ( i , j ) ∈ C V ( x i , x j ) ) P(X)=\frac{1}{Z} \prod_{c\in\mathcal{C}}\exp (-E(X_C)) \\ =\frac{1}{Z} \prod_{c\in\mathcal{C}}\exp \left(-\sum_{i \in C} U\left(x_{i}\right)-\sum_{(i, j) \in C} V\left(x_{i}, x_{j}\right)\right) P(X)=Z1c∈C∏exp(−E(XC))=Z1c∈C∏exp
−i∈C∑U(xi)−(i,j)∈C∑V(xi,xj)
en,追根溯源一下,其实这个能量函数的形式来源于 ising model,一个物理模型。
en 还是大概讲讲 ising model 吧,可以加深对于这个函数的理解。
ising model 是一个描述量子自旋的模型,量子的自旋有 +1 和 -1 两种状态,
ising model 的能量函数如下所示:
H = − h ∑ i S i − J ∑ ⟨ i , j ⟩ S i S j H=-h \sum_{i} S_{i}-J \sum_{\langle i, j\rangle} S_{i} S_{j} H=−hi∑Si−J⟨i,j⟩∑SiSj
不难看出,第一项( h h h 项)对应的是每个组分(粒子)自身的稳定程度,第二项( J J J 项)对应的是两个组分(粒子)相互作用时的稳定程度。
嗯,那么,对于 ising model,能量函数什么时候最小呢?
h h h 反映了外部磁场的某些性质,有时候为正有时候为负,当 x i x_i xi 和 h h h 对齐(正负号一致)的时候,能量函数最小。
J J J 是耦合常数,和 h h h 一样有时候为正有时候为负。如果 J J J 为正,在相邻两个粒子具有相同的自旋状态的时候,能量函数第二项的值较小。
so,当 h h h 和 J J J 都为正的时候,每一个粒子的自旋都为 +1 会使得能量函数取到最小值。
呃不过注意,我们在这里讨论 ising model 的思路和我们在 MRF 中学习参数的思路是相反的。在这里我们已经预先规定了 h h h 和 J J J,讨论的是这些参数会迫使数据呈现出什么样的趋势;但是在 MRF 中,我们是通过已有的数据学习参数,注意区分。
weeeeell,srds 这不是物理小课堂()so ising model 本身我们就说到这里。如果你没看懂,跳过就好((
说回机器学习。ising model 直观地告诉了我们一件事——在 MRF 中,我们要学习的参数就是能量函数中的参数,比如 ising model 中的 h , J h, J h,J.
你可能发现了一个令人疑惑的事——在 ising model 的能量函数中,有着明确的可学习(或者说被规定)的参数 h h h 和 J J J。但我们给出的能量函数的框架(U 和 V)中好像没有可学习的参数诶??但是我们又说要学习的参数就是能量函数的参数?这不对吧。
well,其实还有后续的啦。
上面给出的能量函数只是一个基本的框架或者说结构,它告诉我们应该如何设计 MRF 中的能量函数。即能量函数应该由两个部分组成,一个部分衡量每个组分自身的稳定程度,一个部分衡量组分之间相互作用的稳定程度。 但是,具体每个部分的式子是什么样的,没有一个统一的答案,都是依照任务的内容确定的。
举个例子吧。现在我们有一个图像分割任务,我们希望把图片的背景和非背景部分区分开。
那么,对于一个最大团,损失函数就可以这么设计:
E ( x ) = ∑ i λ 1 ∥ I i − μ x i ∥ 2 + ∑ ( i , j ) ∈ E λ 2 I ( x i ≠ x j ) E(x)=\sum_{i} \lambda_{1}\left\|I_{i}-\mu_{x_{i}}\right\|^{2}+\sum_{(i, j) \in \mathcal{E}} \lambda_{2} \mathbb{I}\left(x_{i} \neq x_{j}\right) E(x)=i∑λ1∥Ii−μxi∥2+(i,j)∈E∑λ2I(xi=xj)
看到了咩()在这个例子中,我们遵循了 ising model 指出的设计能量函数的 “框架”(两个部分),但是我们根据任务的具体需要,细化了每个部分的公式。
这样,我们就看到了可以学习的参数 λ 1 \lambda_1 λ1 和 λ 2 \lambda_2 λ2 啦!!我们的任务就是最小化这个能量函数。至于这具体是怎么做的,后面 MRF 参数学习那部分会讲。
嗯,稍微延伸一下。和许多机器学习模型一样,MRF 可以分为学习(训练)和预测(测试)两个阶段。
在学习阶段,我们使用已标记的数据(比如带有每个像素的类别标签的图片),学习出像上面的 λ 1 , λ 2 \lambda_1, \lambda_2 λ1,λ2 之类的参数,这个过程中 x i , x j x_i, x_j xi,xj 等都是已知的。
在预测阶段,所有的参数(如 λ 1 , λ 2 \lambda_1, \lambda_2 λ1,λ2)是固定的,我们通过最小化能量函数来得到变量 x i , x j x_i, x_j xi,xj 的取值。
简单概括一下,在学习阶段,MRF 通过最小化能量函数来确定参数;而在预测阶段(此时参数已经固定),MRF 通过最小化能量函数来得到变量的最优值。
MRF 中的能量函数就像损失函数一样(呃其实从某种程度上来说你甚至可以把它看作损失函数的一种变式),遵循某种范式,但是没有一个确定的公式。具体的公式一定是根据具体的任务确定的。
嗷,通过这个小节,我想你已经大概明白了能量函数是怎么工作的啦!它是 MRF 中最核心的概念之一,一定要好好看看呀。
接下来,我们来看一个和能量函数紧密相关且经常在 MRF 相关讲解中出现的概念…
势函数
enen,你可能已经在许多其他文章中看到了势函数这个词。
我第一次看到势函数的时候我很迷惑,始终搞不清它到底是怎么来的。不过实际上我现在认为事情很简单——我们之前不是把原始能量函数 E ( x ) E(x) E(x) 加上了负号又取了个 exp 吗,其实这一坨得到的就是势函数 ψ ( X ) \psi(X) ψ(X),即:
ψ ( x ) = exp ( − E ( x ) ) \psi(x)=\exp(-E(x)) ψ(x)=exp(−E(x))
换言之,势函数的本质来源还是能量函数,它的出现有两个原因。
第一,在比较远的地方说过的,我们需要保证概率是非负的,所以在原来的 − E ( x ) -E(x) −E(x) 外面套了层 exp \exp exp,得到了最终的函数形式。
第二,原始的能量函数 E ( x ) E(x) E(x) 带着 exp 和负号,在原始式子中写起来太复杂了。所以我们就把它用一个更简单的符号 ψ \psi ψ 替换了, ψ ( x ) \psi(x) ψ(x) 就是势函数。
其实并不是很复杂啦,势函数和能量函数描述的底层关系是一样的,完全可以用能量函数去理解。能量函数才是出发点。
okiii,其实上面我们已经说完了 MRF 联合概率分解的内容了!!接着我们来看一下 MRF 和我们之间讲过的最大熵模型之间的一些巧妙的关联…
MRF 与最大熵模型
okay,e 或许你会感觉,诶怎么这么跳跃()但实际上,MRF 与最大熵模型之间有着非常多的联系,但其中有一些容易弄混或误会的地方,so 这个部分我会讲一讲它们之间的联系,同时 clarify 一些误区。
emm 不过首先,你需要对最大熵模型有一定的了解,可以参考我之前写过的文章:
【高中生讲机器学习】23. 最大熵模型详解+推导来啦!解决 why sigmoid!
如果你对最大熵模型完全没有了解,可以暂时跳过这个部分,不会对后续的内容造成任何影响。(只是我无意中发现 MRF 和最大熵很像,所以开了这么一个部分。
我们还是从能量函数出发。根据 MRF 的条件概率分解,我们有:
P ( X ) = 1 Z ∏ C ∈ C exp ( − E ( X C ) ) P(X)=\frac 1 Z \prod_{C{\in \mathcal{C}}}\exp(-E(X_C)) P(X)=Z1C∈C∏exp(−E(XC))
嗯, ∏ \prod ∏ 和 exp \exp exp 同时出现,这很容易让我们想到 exp \exp exp 的性质:
exp ( a ) × exp ( b ) = exp ( a + b ) \exp(a) \times \exp(b)= \exp(a + b) exp(a)×exp(b)=exp(a+b)
根据上面这个简单的公式,我们也可以把 MRF 联合概率分解的式子中,现在在 exp \exp exp 外面的 ∏ \prod ∏,放到 exp \exp exp 里面去变成 ∑ \sum ∑,即:
P ( X ) = 1 Z exp ( ∑ C ∈ C − E ( X C ) ) P(X)=\frac 1 Z \exp(\sum_{C{\in \mathcal{C}}}-E(X_C)) P(X)=Z1exp(C∈C∑−E(XC))
然后我们把 Z Z Z,也就是配分函数,写出来,即:
Z = ∑ X exp ( ∑ C ∈ C − E ( X C ) ) Z=\sum_X\exp(\sum_{C{\in \mathcal{C}}}-E(X_C)) Z=X∑exp(C∈C∑−E(XC))
接下来我们把 Z Z Z 带回去,得到:
P ( X ) = exp ( ∑ C ∈ C − E ( X C ) ) ∑ X exp ( ∑ C ∈ C − E ( X C ) ) P(X)=\frac {\exp(\sum_{C{\in \mathcal{C}}}-E(X_C))} {\sum_X\exp(\sum_{C{\in \mathcal{C}}}-E(X_C))} P(X)=∑Xexp(∑C∈C−E(XC))exp(∑C∈C−E(XC))
哦吼!这个形式我们可太熟悉了呀!这不就是最大熵模型的形式吗?那我们是不是可以说,MRF 是最大熵模型的一种特殊形式?
nonono,等等,我们再仔细观察一下。
我把最大熵模型那篇总结的一般形式粘贴过来了,如下:
P w ( y ∣ x ) = exp ( ∑ i = 1 m w i f i ( x , y ) ) ∑ y exp ( ∑ i = 1 m w i f i ( x , y ) ) \begin{align} P_w(y|x) = \frac{\exp\bigg(\sum_{i=1}^m w_i f_i(x, y)\bigg)}{\sum_y\exp\bigg(\sum_{i=1}^m w_i f_i(x, y)\bigg)} \end{align} Pw(y∣x)=∑yexp(∑i=1mwifi(x,y))exp(∑i=1mwifi(x,y))
可以看到,MRF 建模的是什么,是 X X X 的联合概率;但最大熵模型建模的是什么,是条件概率呀!
更进一步,MRF 是生成模型,而最大熵模型是判别模型。
所以,这两个模型虽然形式非常相似,但是不能说 MRF 是最大熵模型的特例。
不过,这倒是给我们提供了一些新的思路…
一点 hint:如果我们搞出一个 “条件概率版” 的 MRF,是不是就可以看作最大熵模型的一种特殊情况了?
诶嘿嘿,这块就留做一个悬念吧,会在后面一点的地方和下一篇中揭晓,嘻嘻嘻…(
好啦好啦就说到这里!!((后面你会明白的)
okaaaaay!! 这个大 part 已经说了很多东西了,接下来我们来总结一下吧!!
总结!
好诶!!!到目前为止!!我们已经系统地讲完了 MRF 中最为关键的部分——MRF 的条件独立性和联合概率分解!
这部分的思路链条非常关键,我觉得是一条能够完全理解 MRF “是什么样 & 为什么是这样” 的思路!我们来总结一下它。
首先,为了更好地理解后续的内容,我们铺垫了吉布斯分布和吉布斯随机场的概念。吉布斯分布用于描述状态的能量与系统处于这个状态的概率之间的关系,状态的能量越低,系统处于这种状态的概率就越高。吉布斯随机场是吉布斯分布在复杂图结构上的推广,它的联合概率可以分解为各个最大团上的未规范化概率(势函数)的乘积。
then,我们遇到了 Hammersley-Clifford 定理,它证明了马尔可夫随机场和吉布斯随机场之间的等价性,换言之,它保证了任意一个 MRF 的联合概率分解都一定可以写成一个 GRF 的形式。这样我们就得到了 MRF 的联合概率分解,即它的联合概率可以被分解为各个最大团上的未规范化概率(势函数)的乘积:
P ( X ) = 1 Z ∏ C ∈ C exp ( − E ( X C ) ) P(X)=\frac 1 Z \prod_{C{\in \mathcal{C}}}\exp(-E(X_C)) P(X)=Z1C∈C∏exp(−E(XC))
明白了 MRF 的联合概率分解,下一步我们确定了(每个最大团上)能量函数的形式,它由两个部分组成,分别衡量组分自身的稳定程度和组分之间相互作用的稳定程度。
E ( X C ) = ∑ i ∈ C U ( x i ) + ∑ ( i , j ) ∈ C V ( x i , x j ) E(X_C)=\sum_{i \in C} U\left(x_i\right)+\sum_{(i, j) \in C} V\left(x_{i}, x_{j}\right) E(XC)=i∈C∑U(xi)+(i,j)∈C∑V(xi,xj)
接下来我们 clarify 了能量函数和势函数的关系,势函数只是为了保证概率始终非负而对能量函数做的变形,本质依然可以通过能量函数去理解。
最后我们讨论了 MRF 和最大熵模型之间的关系,两者有着相似的形式,但是不能认为 MRF 是最大熵模型的特殊形式。因为 MRF 是建模联合概率的生成模型,而最大熵模型是建模条件概率的判别模型。
接下来我们可以进入到一些 “常规环节” 了,和贝叶斯网络一样,马尔可夫随机场也有参数学习和条件学习两大部分。
下面我们就来看看这两部分!
MRF 的参数学习
MRF 的学习,无论是参数学习还是结构学习,其实都和 BN 非常的类似。在这里我根据 MRF 条件独立性和联合概率分解的特点给出一个 MRF 参数学习的例子,但是不做过多的展开。
关于参数学习的更多内容,可以去看贝叶斯网络那篇!
完全数据:MLE
对于完全数据的学习,和 BN 一样直接用 MLE 就可以了。
比如我们上面给出的图像分割的例子,它的能量函数如下:
∑ i λ 1 ∥ I i − μ x i ∥ 2 + ∑ ( i , j ) ∈ E λ 2 I ( x i ≠ x j ) \sum_{i} \lambda_{1}\left\|I_{i}-\mu_{x_{i}}\right\|^{2}+\sum_{(i, j) \in \mathcal{E}} \lambda_{2} \mathbb{I}\left(x_{i} \neq x_{j}\right) i∑λ1∥Ii−μxi∥2+(i,j)∈E∑λ2I(xi=xj)
我们要最小化这个能量函数,这等价于最大化联合概率 P ( X ) P(X) P(X)(数学上的等价,没有因果关系)。
最大化联合概率,在专门讲 MLE 的那篇我们说过,等价于极大似然估计。(如果你想知道这是为什么,可以去看 MLE 那篇文章~
oki,那么我们要做的就是最大化下面这个式子:
P ( X ) = 1 Z ∏ c ∈ C exp ( − E ( X C ) ) P(X)=\frac{1}{Z} \prod_{c\in\mathcal{C}}\exp (-E(X_C)) P(X)=Z1c∈C∏exp(−E(XC))
即:
P ( X ) = 1 Z ∏ c ∈ C exp ( − ( ∑ i λ 1 ∥ x i − μ x i ∥ 2 + ∑ ( i , j ) ∈ E λ 2 I ( x i ≠ x j ) ) ) P(X)=\frac{1}{Z} \prod_{c\in\mathcal{C}}\exp \left(-\left(\sum_{i} \lambda_{1}\left\|x_{i}-\mu_{x_{i}}\right\|^{2}+\sum_{(i, j) \in \mathcal{E}} \lambda_{2} \mathbb{I}\left(x_{i} \neq x_{j}\right)\right)\right) P(X)=Z1c∈C∏exp
−
i∑λ1∥xi−μxi∥2+(i,j)∈E∑λ2I(xi=xj)
我们通过最小化这个函数来确定所有的 x i x_i xi 和 x j x_j xj,即每个像素的类别。同时我们最小化这个函数来确定两个参数 λ 1 , λ 2 \lambda_1, \lambda_2 λ1,λ2.
豪德!这就可以用各种数值优化方法或者直接求解偏导来做啦,MLE 那篇有讲,这里就不展开了。
不完全数据:EM
对于不完全数据的学习,比如原始带有标签的图像中某些区域的标签是不可观测的,我们使用 EM 算法。
这个算法也已经说过很多遍啦,首先根据现有的参数预测出隐藏变量的取值,比如不可观测的像素的取值,再利用预测得到的隐藏数据和已知数据,利用 MLE 更新参数的取值。
EM 算法和 MLE 的区别其实只是 EM 多了一个预测隐藏变量的过程,这里也不展开啦~
okiii,说完参数学习,我们来看一下 MRF 的结构学习。
MRF 的结构学习
MRF 的结构学习和 BN 就更是相似了,甚至都不用展开说。
在 BN 那篇我讲了概率图模型常用的两个结构学习方法——评分方法和约束方法。这两个方法在 MRF 中依然适用,并且使用方法几乎没有变化。这里大致说一下,不再展开。
如果想知道两种方法的细节,可以去看 BN 那篇~
评分方法
在 MRF 中我们依然可以使用基于贪心策略的评分方法来选择图结构。
具体来说,我们每次都尝试添加边、删除边、改变边的方向这三种操作中的一种,并在每一步都选出并执行在这一步当中能够最大化评分(BIC 信息准则)的操作。在使用评分方法的时候,结构学习和参数学习是交替进行的。
同时,因为 MRF 是无向图,所以可以粗略的认为尝试的次数会比有向图(贝叶斯)少了一半,因为我们不用每次都尝试两个方向的边了。
约束方法
和 BN 一样,我们也可以使用基于严格条件独立性检验(比如卡方检验)的约束方法来学习 MRF 的结构。
具体来讲,约束方法通过严谨的统计学方法判断哪些变量之间是非条件独立的,并在这些变量之间添加一条边。
约束方法相比评分方法,数学解释性更强,但同时对数据质量的要求也更高。
诶嘿,在 MRF 中使用约束方法其实还有一个潜在的好处。
如果你看过贝叶斯那篇的话,你可能还记得,在 BN 中使用约束方法会导致有一些边的方向无法确定(因为约束方法只能够告诉你哪些变量间非条件独立,但是没有办法告诉你谁是因谁是果)。但是因为 MRF 是无向图,所以这个顾虑就不存在了,我们可以非常顺畅地使用约束方法。
en,这两个方法大致就介绍到这里,详情可见 BN 那篇~
好诶,不知道你有没有发现,这篇的架构和 BN 那篇几乎完全一样。其实这是我专门设计的嘿嘿嘿。
BN 那篇的最后我给出了一个特例 HMM,同样地,这篇最后我也会给出 MRF 的一个特例——条件随机场(CRF)!
特例:条件随机场
条件随机场,英文全称 conditional random field,简称 CRF。在这里我只是做一个简单的引入,在下一篇中我会深入地讲它。
简单来说,条件随机场可以看作是在给定输入的情况下,输出的马尔可夫随机场。或者说,条件随机场中的 “条件” 指的就是给定的输入。
比如,我们给出一个词性标注问题,希望在给定输入序列的情况下,预测这个序列的每个词对应的词性。
那么,这个问题就可以用如下的图进行建模。其中下面那行是输入序列,上面那行是预测的输出序列,图中的所有边都满足马尔可夫性。
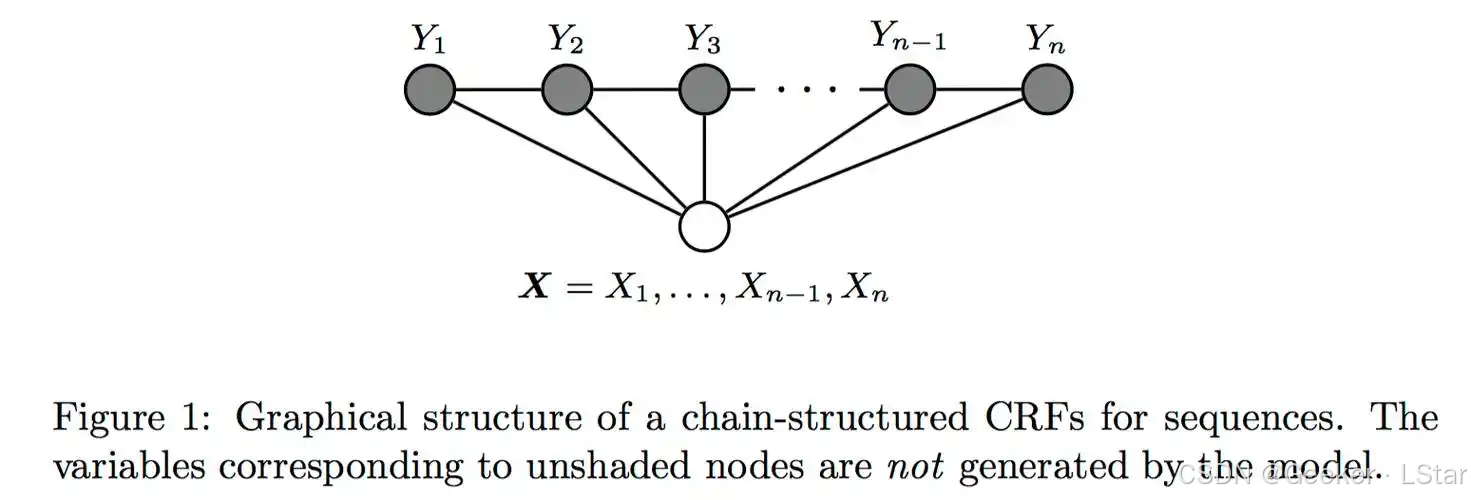
那么,在 CRF 中,我们要预测的就是 P ( Y ∣ X ) P(Y|X) P(Y∣X)。它也可以通过利用马尔可夫性分解成最大团,然后计算各个最大团上的能量函数得到。
不过因为 CRF 建模的是条件概率,所以它的分解和 MRF 稍有不同(但底层逻辑是一样的),这里不展开。
如果你还记得前面说的 MRF 和最大熵模型的关系那块(我提到了一个 hint),你其实可以思考一下 CRF 和最大熵模型的关系…
这个悬念的答案就留到下一篇啦嘿嘿。
关于条件随机场的更多内容,我会专门写一篇文章来讲的!写完之后会把 link 放在这里!
keeeep follow!
好耶!!那这一篇的所有内容就都讲完了耶!!!下一篇 CRF 再见啦~~
(e,一个彩蛋,忽然发现昨天吉布斯自由能这部分的作业(化学作业)还没写,eerrrr))
(赶紧溜去写作业((这文章三天爆肝 2w 字我真是累瘫了哈哈哈哈哈哈(((
这篇文章系统地马尔可夫随机场,包括 MRF 的条件独立性和因子分解、参数学习和结构学习等,希望对你有所帮助!⭐
欢迎三连!!一起加油!🎇
——Geeker_LStar

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 23
23 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)