diabetes数据集_数据分析模型11——机器学习兵器中的大杀器:集成学习算法(ENSEMBLE METHODS)...
今天我们来学习机器学习中的一个重量级的武器,集成学习算法。基本上集成学习法是一个多分类器整合方法,传统的机器学习模型只会建立一个分类器,集成学习法通过构建多个分类器,对多个分类器的预测结果进行聚合,提高分类精度。集成方法根据训练数据构造一组基分类器,并通过对每个基分类器的预测进行投票来进行分类。未经许可请勿转载更多数据分析内容参看这里一、基本概念下面我们看一下集成学习算法的过程。原始的训练数据,通

今天我们来学习机器学习中的一个重量级的武器,集成学习算法。基本上集成学习法是一个多分类器整合方法,传统的机器学习模型只会建立一个分类器,集成学习法通过构建多个分类器,对多个分类器的预测结果进行聚合,提高分类精度。集成方法根据训练数据构造一组基分类器,并通过对每个基分类器的预测进行投票来进行分类。
未经许可请勿转载
更多数据分析内容参看这里
一、基本概念
下面我们看一下集成学习算法的过程。
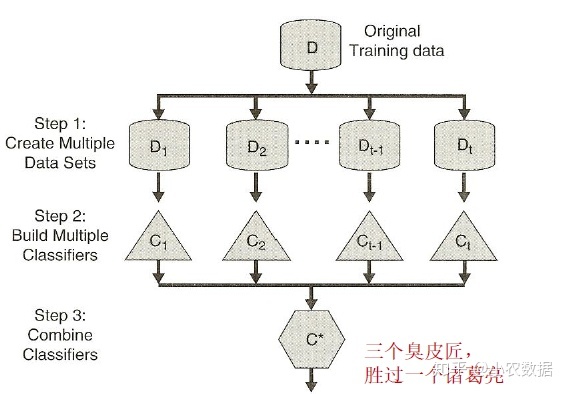
原始的训练数据,通过一些取样方法,会被分成多个不同的数据集,每个数据集生成各自的分类器,最后会把t个分类器的结果进行整合,基本上采用的是投票机制。集成学习法后面隐含的逻辑就是三个臭皮匠胜过诸葛亮。
集成学习法在分类上有两种方式。第一类是在训练数据上进行处理,建立多个模型。还有一大类是从输入字段上进行处理,产生多个模型。
基于训练数据的处理,主要通过不同的取样方式来决定哪些样本会被选作训练集,每一个训练集都会产生一个特定学习算法的分类器。这种方式主要由两种集成学习算法:袋装法Bagging 和提升法Boosting。
基于输入字段的处理,输入字段的一个子集会被挑选出来,构建单独的训练集。这种方式中一个主要方法是随机森林(Random forest)。 随机森林是决策树分类算法的改良,会建立一系列的决策树,通过投票决定结果。传统的决策树通过挑选最好的属性来进行分类,而随机森林会从最好的K个属性里面随机选择1个来进行分类,这时就会产生很多不同的决策树。这种方式在有冗余变量时效果尤佳。
二、集成学习模型构建
1. 袋装法(Bagging)原理
我们先看一下下面的数据集(x是输入字段,y是目标字段)

假定我们构建一个分类器,并且限制为单层的二元树,怎么样才能得到最佳的分类的一层二元树?这边有两个选择(1)将X<=0.35的预测为1,X>0.35的预测为-1.(2)X<=0.75,预测为-1,X>0.75,预测为1。这两种方式,预测的准确率最多均为70%。
下面我们来看一下,使用袋装法怎么提升预测的准确率。我们采用有放回式的抽样,抽取十笔样本。在每一次抽样中,我们都构建一个二元分类树,如下所示。
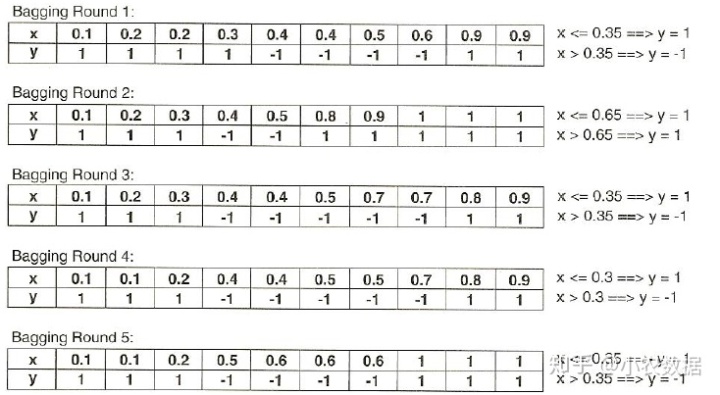
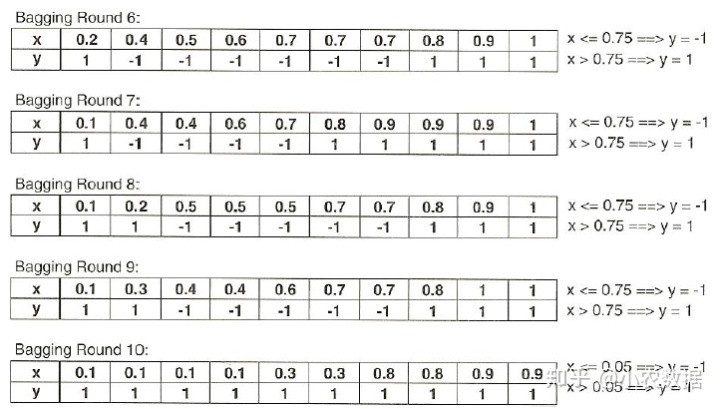
这时候神器的事情发生了,我们再次把原始的0.1到1这是个数据放入上面构建的10个二元树分类器,结果如下:
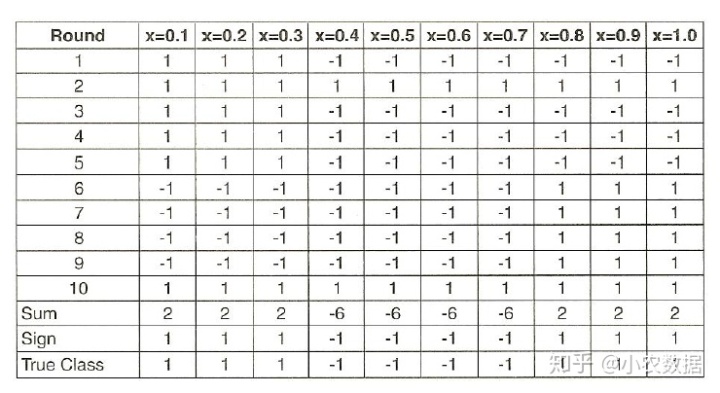
结果是,预测的准确率达到了100%,超越了单层分类树70%的限制。从这个例子可以看出,即便每个分类器是一个基本的二元树,把所有的分类器结果整合后,就形成了一个二层的决策树的效果。基本上Bagging的方法可以套用任何分类模型,这边使用了决策树,比较常见的方式。
由于每个样本都有相同的概率被抽取,bagging方式不需要对特定的训练集进行权重处理。也就是说,这种方式不会存在过拟合问题。
2. 提升法(Boosting)原理
提升法也是对训练数据进行处理,和Bagging不同,它会根据实际情况去调整每个训练数据被抽中的概率,开始大家被抽取的概率是一样的,但是一直被分类错误的数据会被加重权重,在后续的基础分类器中这些一直分错的数据会被更多的抽中,目标是希望比较难分类的数据再下一次的分类中能够分类正确。也就是说Boosting会给每一个训练范例赋予一个权重,每一轮的分类器都可能改变权重值。
初始,每个训练数据的权重都是1/N, 他们都会以相同的概率被抽取。根据1/N的权重,我们第一次会抽取样本建立一个训练集,并在此基础上构建一个分类器。建完分类器后,会对原始的训练数据去进行分类,并判断分类的正确率。分类正确的降低该训练数据的权重,错误的进行提升。然后开始下一轮的循环,这种方式将注意力放在难以分类的数据上。

最后的结果是整合每一轮中所有的分类器,进行投票处理。这边对每一轮的分类器将会进行二次赋予权重处理,越后面的分类器权重越高。
现在的问题就是:(1)怎么在每一轮预测结束后去调整权重?(2)怎么整合每一各分类器预测的结果? 我们来看下面的例子。

第一轮,x<=0.75预测为-1,x>0.75预测为1。0.1到0.3三个数据预测错误,因此提升其权重值(权重值的计算公式比较复杂,此处不再展开)。剩下7个数值预测正确,降低其权重。
第二轮,X<=0.05预测为-1,x>0.05预测为1。0.4到0.7四个数据预测错误,因此提升其权重值 ,降低其余数值的权重。
第三轮,x<=0.3预测为1,x>0.3预测 为-1。
可以看到,一直分类正确的数值,权重在不断下降。假设我们的分类只进行三轮。

下面我们看一三轮预测的结果,每一轮分类器都赋予了权重(权重值的计算同样在此省略)
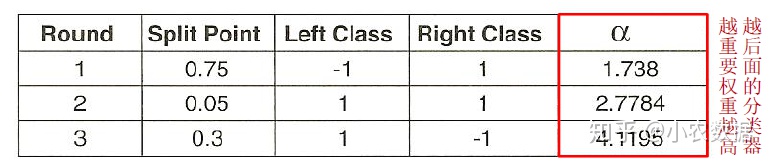
接下来我们再次把原始数据,代入到这三个分类器中分类处理
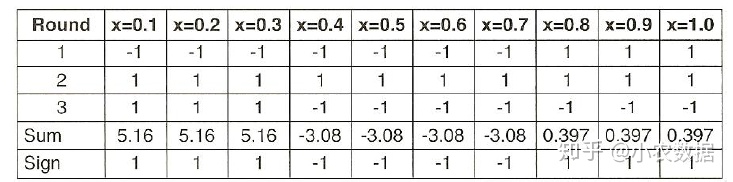
最后我们来计算最终的分类结果,比如第一个数值0.1,Sum1 = -1.738 + 2.7784 + 4.1195 = 5.16, 因此预测其为1。其余数值相同处理。
使用Boosting算法,AdaBoost(R语言中提供相关的包)后,训练集中的每一个数据都被预测准确了。由于Boosting算法侧重于容易分错的数据,因此它很容易陷入过拟合的问题。一般来来说,Boosting算法的分类准确率高于Bagging。
目前比较新的提优集成学习算法是XGBoost, 全称为Extreme Gradient Boosting,其最大的特点在于能够自动利用CPU的多线程进行并行,大幅度提高模型运算效率。
3. 随机森林(Random forest)原理
随机森林主要是为决策树而设计的, 因为决策树只能建一棵,随机森林可以建多棵,如下所示。决策树并不从训练数据出发,而是从字段选择上进行变更,随机从K个最佳字段中选择一个。
目前基于实际的分类效果来看,boosting算法和随机森林的效果是最好的,因此在一些比赛中基本也就应用到了这两种。通常来说,我们会构建50个基础分类器以上。
三、R语言集成学习模型构建
1. 袋装法(Bagging)
要处理的是一个糖尿病的数据集,class是目标字段
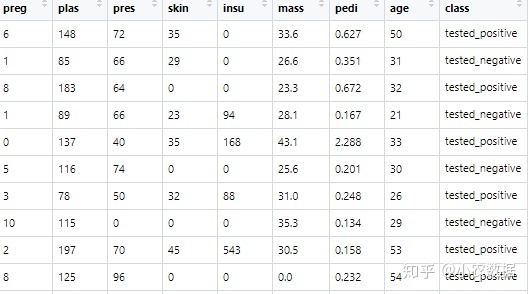
# Read Diabetes Dataset
data <- read.csv("E:/cdadata/jicdata/diabetes.csv")[,-1]
set.seed(102)
select <- sample(1:nrow(data),nrow(data)*0.8) #抽取80%的数据作为训练集
#先用c5.0决策树来分类
# Build C5.0 Model
library(C50)
C50.tree <- C5.0(class ~ ., data=data[select,])
# Make Predictions for Training Data
C50.Prediction <- predict(C50.tree, newdata=data[select,], type='class')
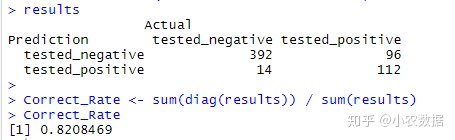
results <- table(Prediction=C50.Prediction, Actual=data[select,]$class)
results
Correct_Rate <- sum(diag(results)) / sum(results)
Correct_Rate
# Make Predictions for Test Data
C50.Prediction <- predict(C50.tree, newdata=data[-select,], type='class')
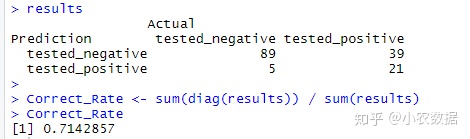
results <- table(Prediction=C50.Prediction, Actual=data[-select,]$class)
results
Correct_Rate <- sum(diag(results)) / sum(results)
Correct_Rate
# Build Bagging Model
library(adabag)
set.seed(101)
Bagging_Model <- bagging(class ~ ., data=data[select,], mfinal = 100)
# Make Predictions for Training Data
Bagging.Prediction <- predict(Bagging_Model, newdata=data[select,])
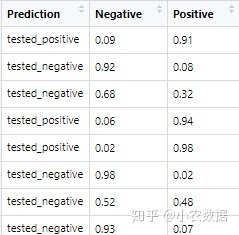
results <- data.frame(Bagging.Prediction$class, Bagging.Prediction$prob)
names(results) <- c("Prediction", "Negative", "Positive")
results
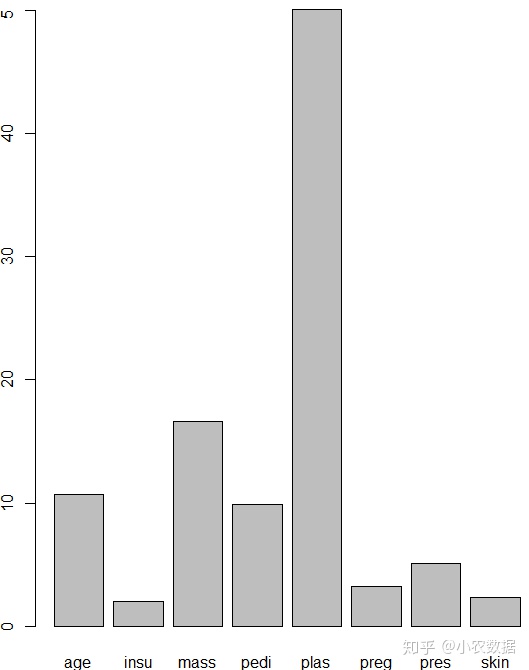
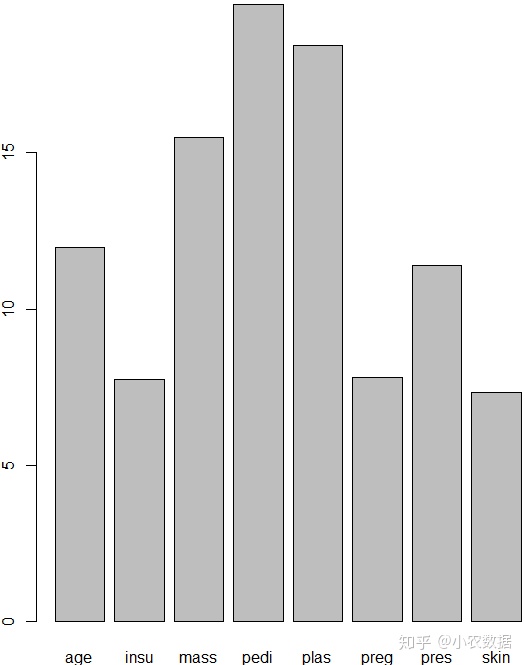
#bagging也可以看一下哪个字段相对更重要
barplot(Bagging_Model$importance)
#看一下预测结果
Bagging.Prediction$confusion

#也可以自己生成混淆矩阵
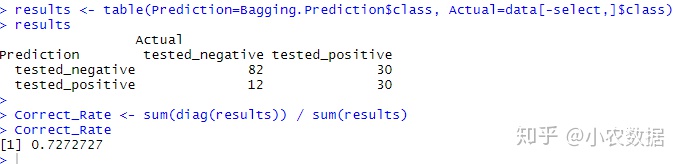
results <- table(Prediction=Bagging.Prediction$class, Actual=data[select,]$class)
results
Correct_Rate <- sum(diag(results)) / sum(results)
Correct_Rate
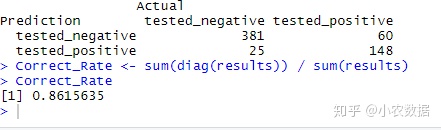
# Make Predictions for Test Data
Bagging.Prediction <- predict(Bagging_Model, newdata=data[-select,])
Bagging.Prediction$confusion
results <- table(Prediction=Bagging.Prediction$class, Actual=data[-select,]$class)
results
Correct_Rate <- sum(diag(results)) / sum(results)
Correct_Rate #正确率略有提升
2. 提升法(Boosting)—adaboost
处理的数据同上,这边说明的是,无论是bagging还是boosting,adabag包背后使用的都是决策树算法cart。
# Build Boosting Model
library(adabag)
set.seed(101)
Boosting_Model <- boosting(class ~ ., data=data[select,])
# Make Predictions for Training Data
Boosting.Prediction <- predict(Boosting_Model, newdata=data[select,])
results <- data.frame(Boosting.Prediction$class, Boosting.Prediction$prob)
names(results) <- c("Prediction", "Negative", "Positive")
results
barplot(Boosting_Model$importance)
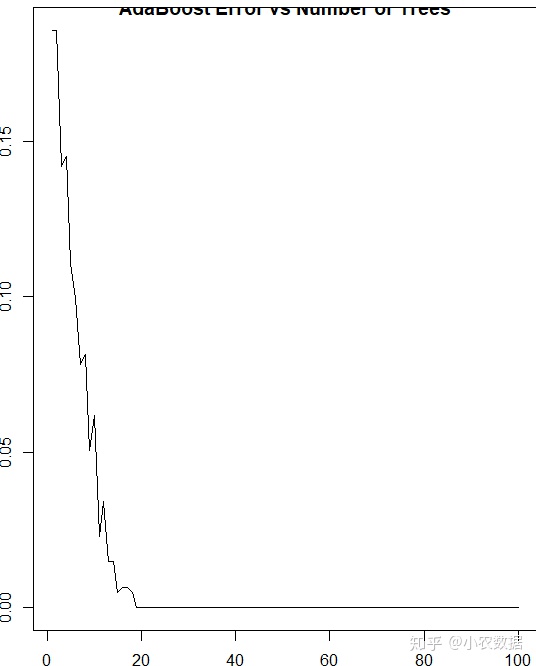
Boosting_Model.Error <- errorevol(Boosting_Model, data[select,]) #计算全体的误差演变
plot(Boosting_Model.Error$error,type="l",
main="AdaBoost Error vs Number of Trees") #对误差演变进行画图,从中可以看出虽#然建立了100个分类器,但到第20个开始误差已经降不下来了。
Boosting.Prediction$confusion
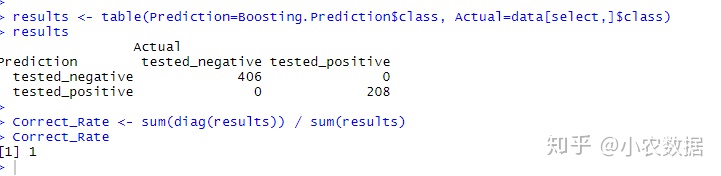
results <- table(Prediction=Boosting.Prediction$class, Actual=data[select,]$class)
results
Correct_Rate <- sum(diag(results)) / sum(results)
Correct_Rate
# Make Predictions for Test Data
Boosting.Prediction <- predict(Boosting_Model, newdata=data[-select,])
Boosting.Prediction$confusion
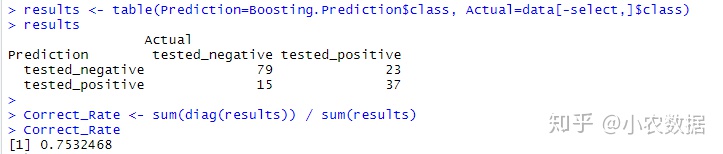
results <- table(Prediction=Boosting.Prediction$class, Actual=data[-select,]$class)
results
Correct_Rate <- sum(diag(results)) / sum(results)
Correct_Rate
3. 提升法(Boosting)—XGBoost
# Read Broadband Dataset
data <- read.csv("E:/jicdata/broadband.csv")[,-1]
# Data Preprocessing
data.y <- data$BROADBAND
data.n <- data[,-c(5,ncol(data))]
data.c <- data[,c("CHANNEL")]
data.c <- as.factor(data.c)
library("nnet")
dummy.c = as.data.frame(class.ind(data.c))
names(dummy.c) <- c("Channel-1", "Channel-2", "Channel-3", "Channel-4")
# Generate Training & Test Datasets
set.seed(102)
select <- sample(1:nrow(data),nrow(data)*0.8)
train_set.x <- cbind(data.n[select,], dummy.c[select,])
train_set.y <- data.y[select]
test_set.x <- cbind(data.n[-select,], dummy.c[-select,])
test_set.y <- data.y[-select]
# Build xgboosting Model
library(xgboost)
dtrain <- xgb.DMatrix(data = as.matrix(train_set.x), label = as.matrix(train_set.y))
dtest <- xgb.DMatrix(data = as.matrix(test_set.x))
xgb.params = list(
#col的抽样比例,越高表示每棵树使用的col越多,会增加每棵小树的复杂度
colsample_bytree = 0.5,
# row的抽样比例,越高表示每棵树使用的col越多,会增加每棵小树的复杂度
subsample = 0.5,
booster = "gbtree",
# 树的最大深度,越高表示模型可以长得越深,模型复杂度越高
max_depth = 2,
# boosting会增加被分错的数据权重,而此参数是让权重不会增加的那么快,因此越大会让模型愈保守
eta = 0.03,
# 或用'mae'也可以
eval_metric = "rmse",
objective = "reg:linear",
# 越大,模型会越保守,相对的模型复杂度比较低
gamma = 0)
cv.model = xgb.cv(
params = xgb.params,
data = dtrain,
nfold = 5, # 5-fold cv
nrounds=200, # 测试1-100,各个树总数下的模型
# 如果当nrounds < 30 时,就已经有overfitting情况发生,那表示不用继续tune下去了,可以提早停止
early_stopping_rounds = 30,
print_every_n = 20 # 每20个单位才显示一次结果,
)
tmp <- cv.model$evaluation_log
plot(x=1:nrow(tmp), y= tmp$train_rmse_mean, col='red', xlab="nround", ylab="rmse", main="Avg.Performance in CV")
points(x=1:nrow(tmp), y= tmp$test_rmse_mean, col='blue')
legend("topright", pch=1, col = c("red", "blue"),
legend = c("Train", "Validation") )
best.nrounds = cv.model$best_iteration
best.nrounds
xgb.Model <- xgb.train(paras = xgb.params, data = dtrain, nrounds = best.nrounds)
# Make Predictions for Training Data
xgb.Prediction <- predict(xgb.Model, dtrain)
xgb.Prediction <- ifelse(xgb.Prediction > 0.01, 1, 0)
accuracy.xgb <- sum(xgb.Prediction==train_set.y)/length(xgb.Prediction)
accuracy.xgb
table(xgb.Prediction, train_set.y)
# Make Predictions for Test Data
xgb.Prediction <- predict(xgb.Model, dtest)
xgb.Prediction <- ifelse(xgb.Prediction > 0.01, 1, 0)
accuracy.xgb <- sum(xgb.Prediction==test_set.y)/length(xgb.Prediction)
accuracy.xgb
table(xgb.Prediction, test_set.y)
4. 随机森林(Random forest)
# Read Diabetes Dataset
data <- read.csv("E:/jicdata/diabetes.csv")[,-1]
set.seed(102)
select <- sample(1:nrow(data),nrow(data)*0.8)
# Build Random Forest Model
library(randomForest)
set.seed(101)
RF_Model <- randomForest(class ~ ., data=data[select,], ntree=300)
# Make Predictions for Training Data
RF.Prediction <- predict(RF_Model, data[select,])
accuracy.rf <- sum(RF.Prediction==data[select,]$class)/length(RF.Prediction)
accuracy.rf
table(RF.Prediction, data[select,]$class)
# Make Predictions for Test Data
RF.Prediction <- predict(RF_Model, data[-select,])
accuracy.rf <- sum(RF.Prediction==data[-select,]$class)/length(RF.Prediction)
accuracy.rf
table(RF.Prediction, data[-select,]$class)



魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)