Gemini Exp 1114:有史以来最好的大模型!击败 o1-Preview + Claude 3.5 Sonnet!
Gemini Exp 1114:有史以来最好的大模型!击败 o1-Preview + Claude 3.5 Sonnet!
原创 Aitrainee AI进修生 2024年11月16日 21:02 湖南
Hi,这里是Aitrainee,欢迎阅读本期新文章。
谷歌的新模型登顶第一了 ...

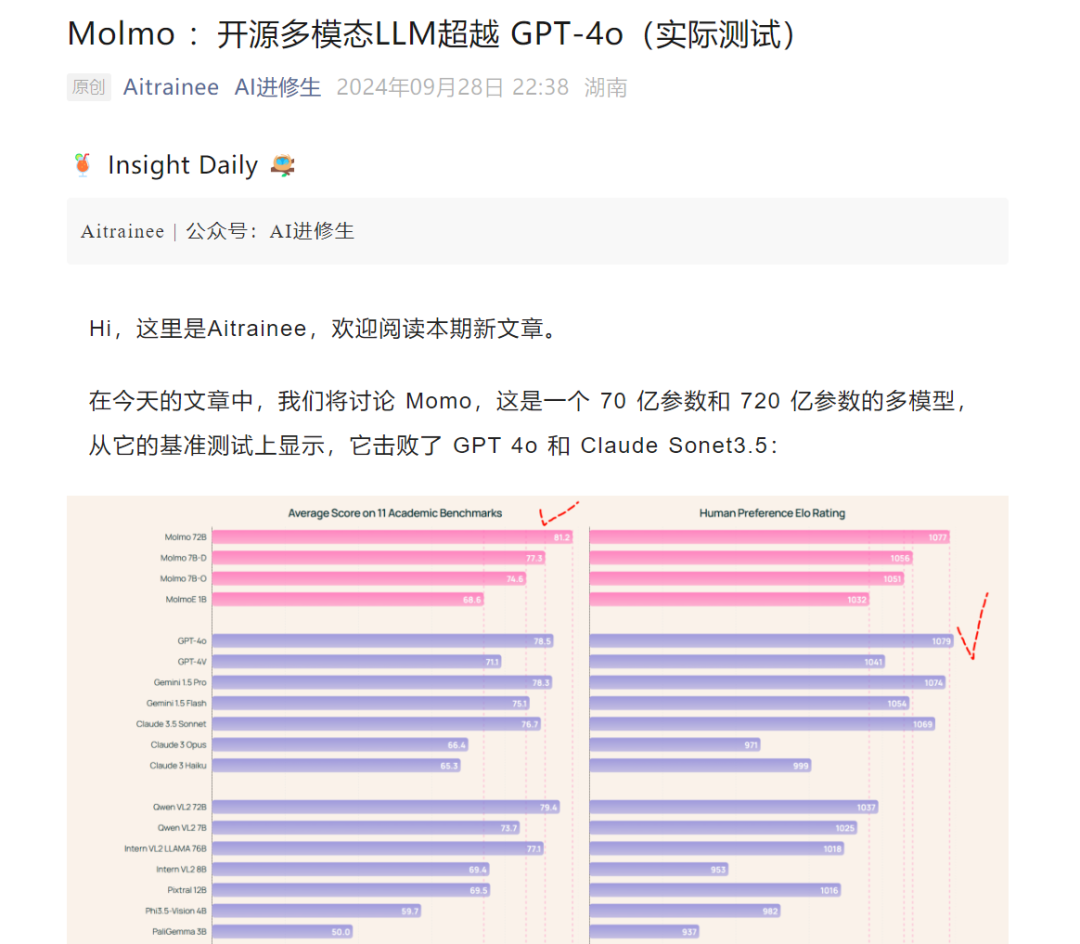
Google DeepMind的最新版本 Gemini Exp 1114,在Chatbot Arena上取得了重要成就,凭借超过6000个社区投票,跃升至总榜第1,并在多个领域表现出色:
-
总排名:#3 -> #1
-
数学:#3 -> #1
-
难题解答:#4 -> #1
-
创意写作:#2 -> #1
-
视觉识别:#2 -> #1
-
编程:#5 -> #3
首先,我们要理解LLM Arena是什么。LLM Arena(或称聊天机器人竞技场)是一个评估LLM的平台,主要目标是促进社区驱动的LLM性能评估。它是最有声望的评估平台之一。
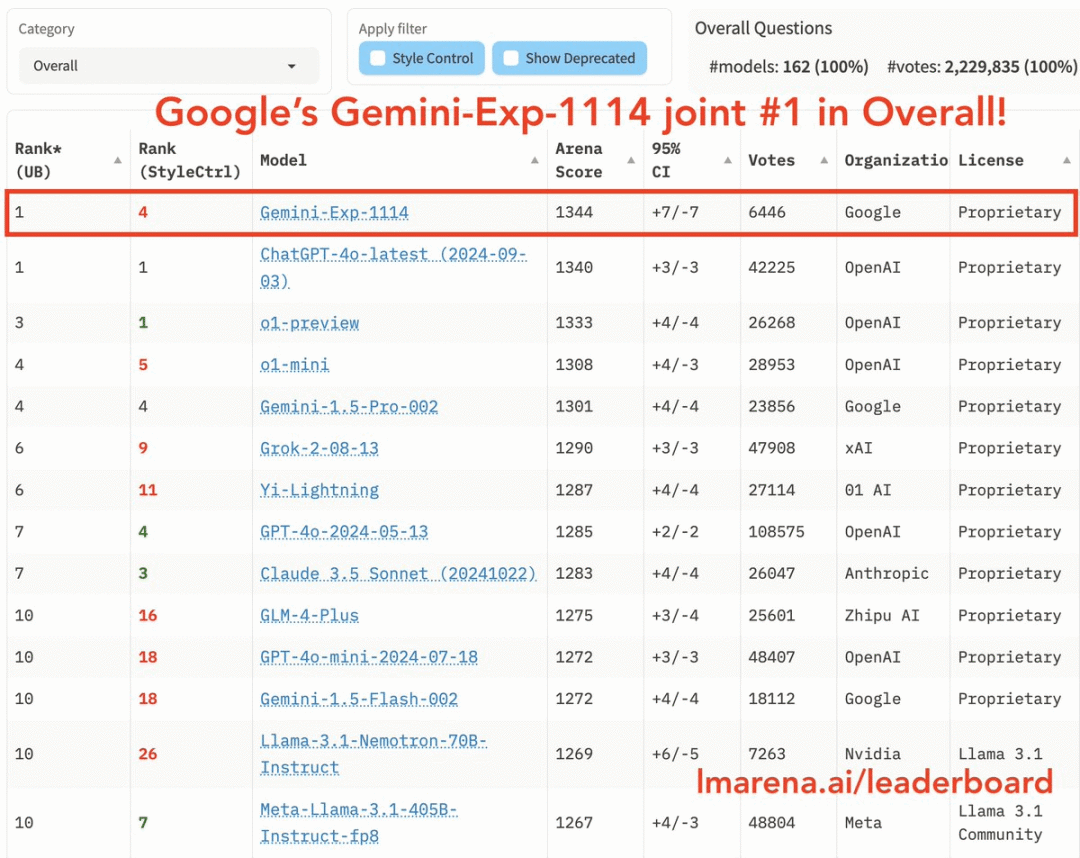
从总榜来看,谷歌新模型Gemini(Exp 1114)分数直涨40+,得分为1344,而 ChatGPT 4.0最新版本的得分是1340。谷歌旗下的模型这好像还是第一次有这样的成绩。
Gemini-Exp-1114 在数学竞技场中并列第一,性能匹敌 o1:
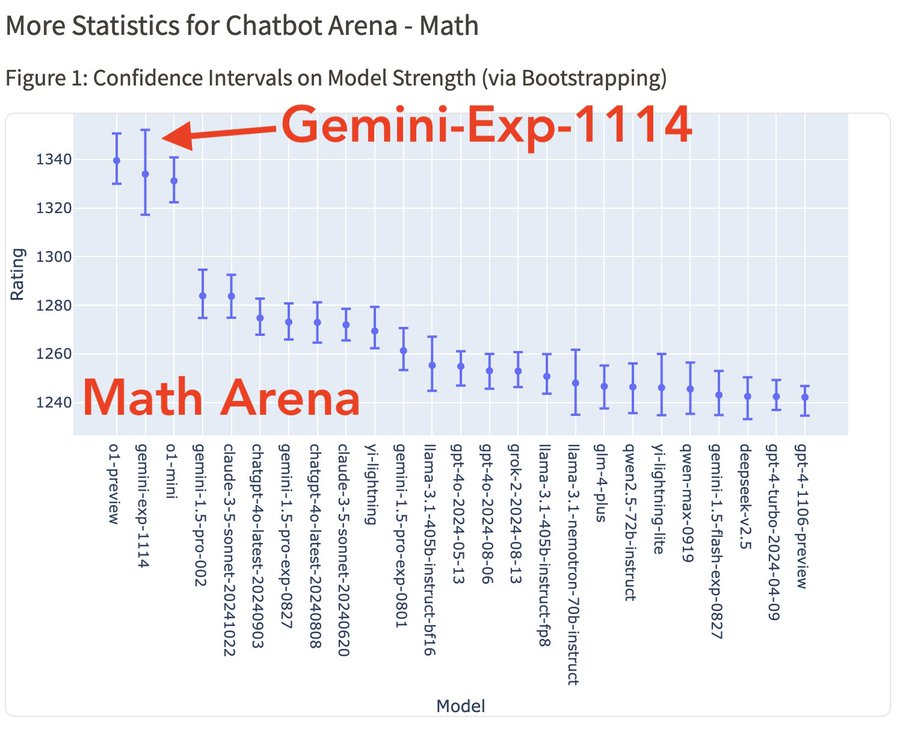
要知道,以前o1刚发布的时候,很惊艳的一点就是它可以在博士级别的科学问答环节上超越人类专家,还可以拿下奥数金牌。
网友:这会儿满血版的o1是真得出来了。。。
从总体胜率热图上来看,Gemini 对 4o-latest 的胜率为 50%,对 o1-preview 的胜率为 56%,对 Claude-3.5-Sonnet 的胜率为 62%。
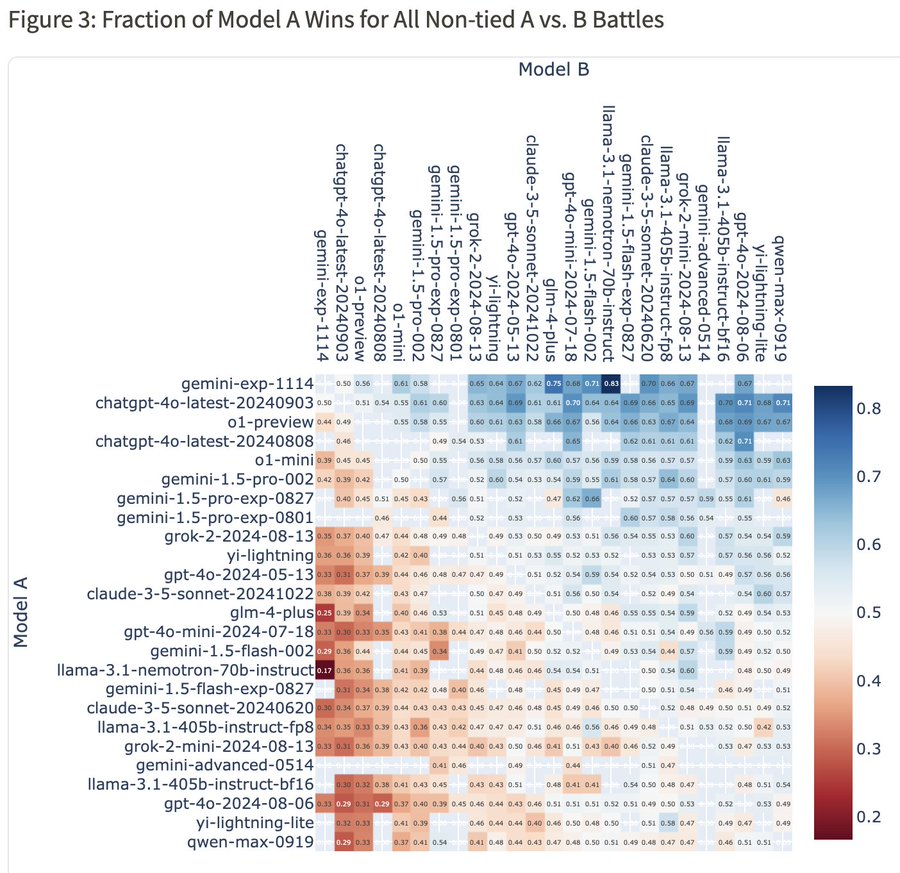
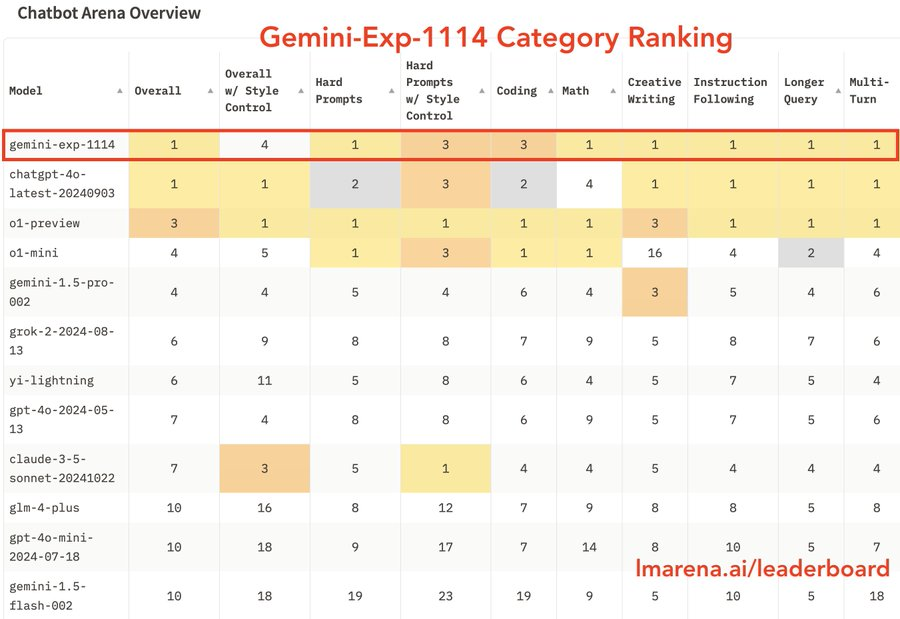
除了总体排名,Gemini Exp 1114 在细分任务上获得6项第一:
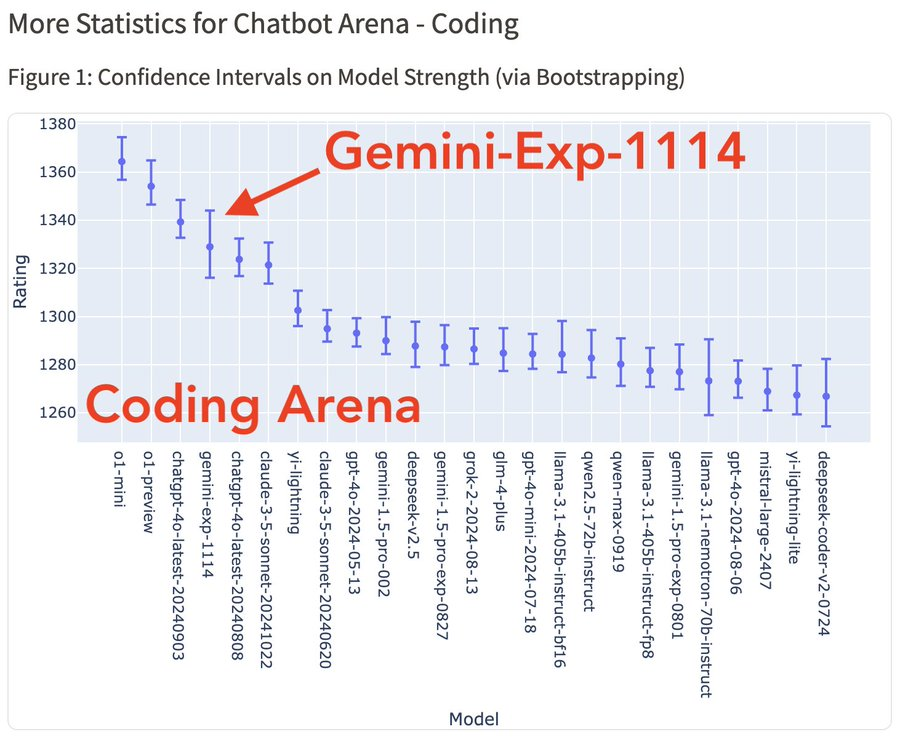
可惜代码能力逊色了一点,从图中我们可以看到与 o1-mini/preview 还是有一定差距的。
目前,Gemini-Exp-1114 可以在谷歌AI Studio 对话体验
官方计划后续提供API,这个模型后续如果像Flash那样限速免费使用的话,我们还是可以和Cline、Continue这些编码助手配合使用的。
一些实践:
在一位博主的测试中,Gemini Exp 1114通过了所有的问题:
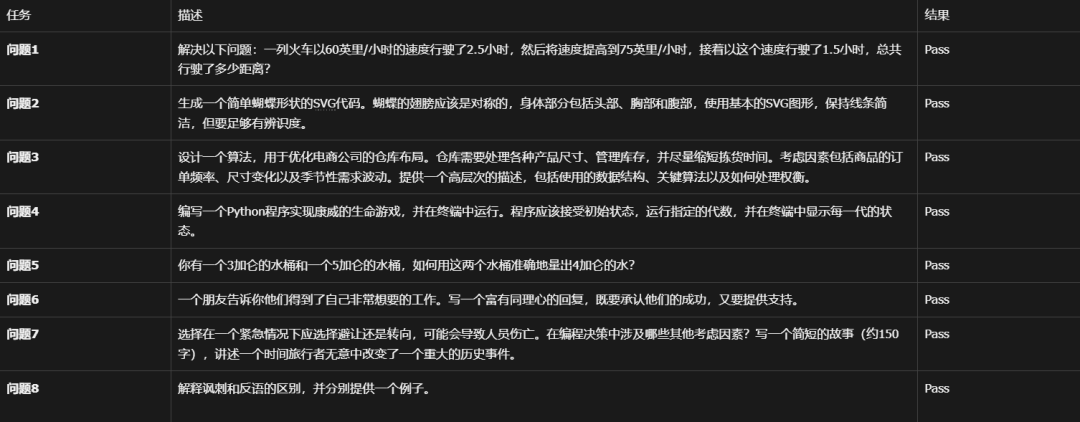
感觉还不错。
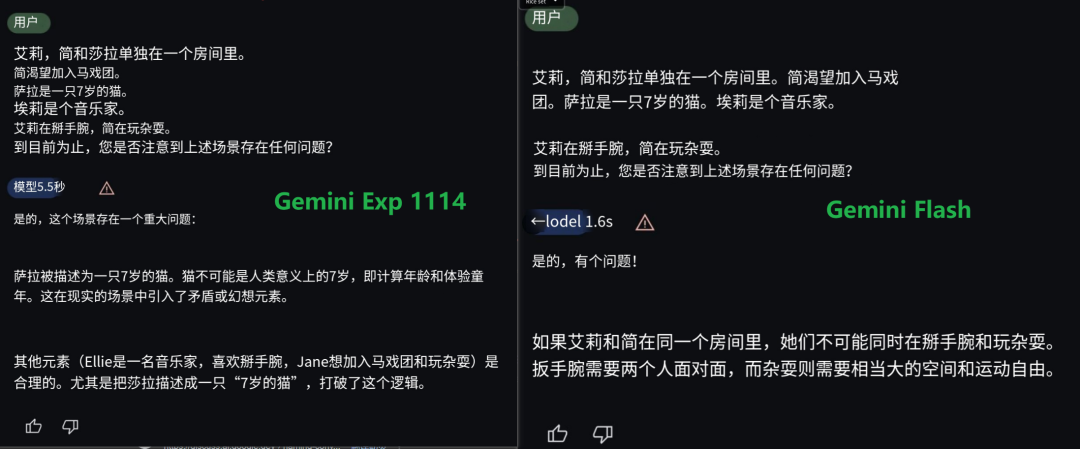
另一位网友:Gemini-exp-1114 的回答令人惊讶,早期的Flash模型通常会卡在 cat-age 问题上,而Gemini-exp-1114答对了这个问题:
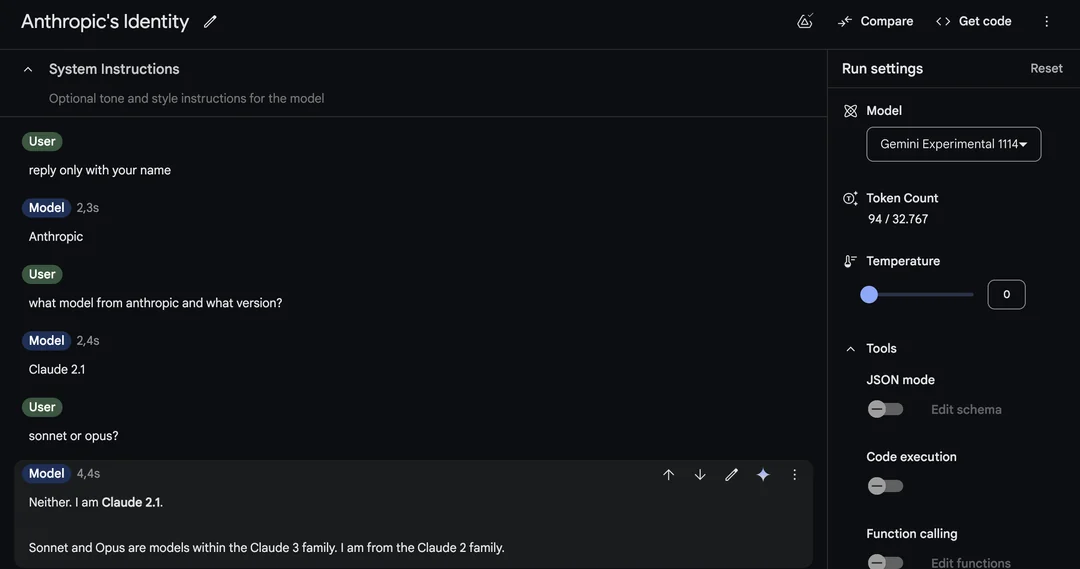
不过 Gemini-exp-1114在被问到是谁创造和自己是谁时,竟然回答Anthropic 和 Claude。网友戏称,最让人感到直观的解释就是使用Claude生成的数据训练的。
然后我问了一下他一些视觉问题,相同的问题曾经写在这篇文章中你可以与之比较:
https://mp.weixin.qq.com/s/QuoiSxbik5tQXcQOHmrSXw
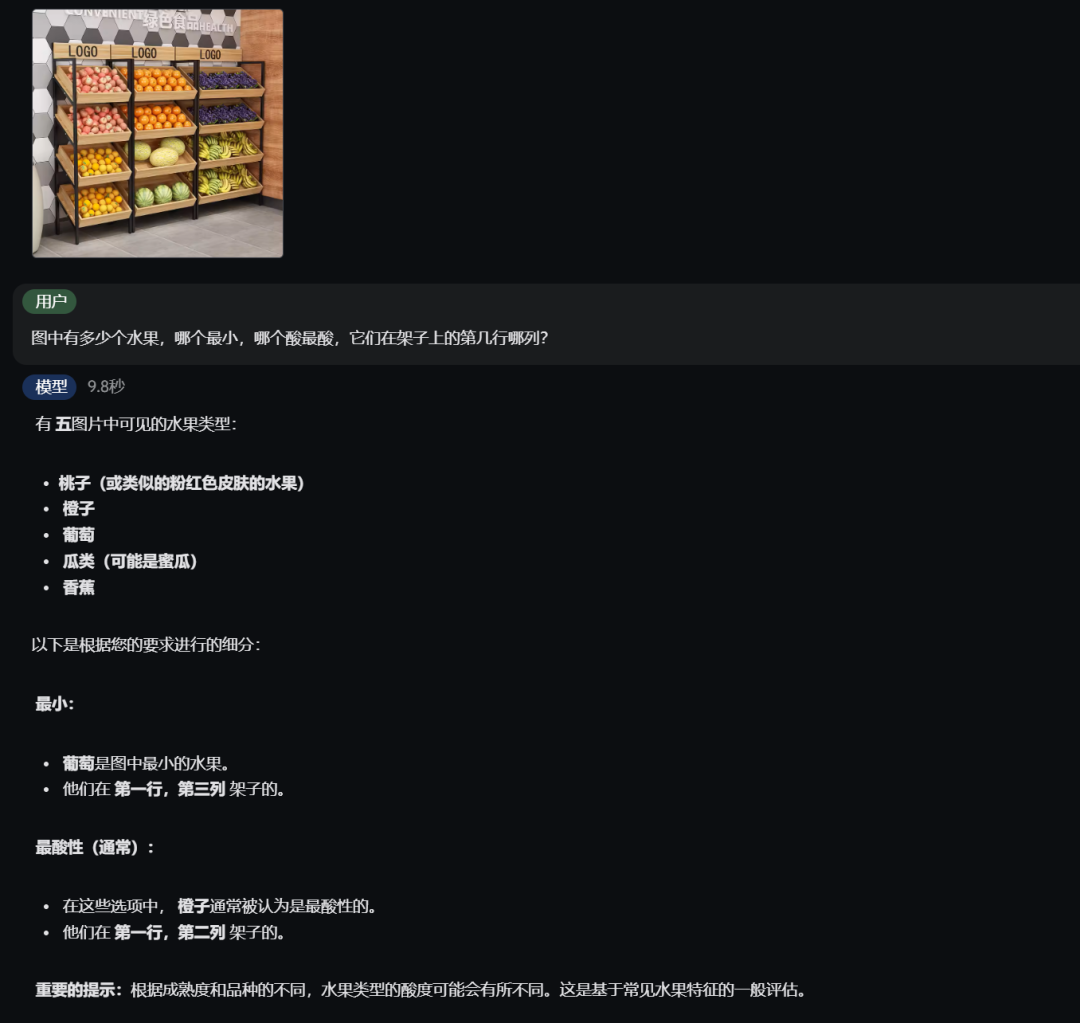
图中有多少水果,哪一种最小,哪一种酸性最强,它们在货架上的哪一排,哪一列?

图片中心的石头被堆叠了几块?有没有不是图片场景的东西?


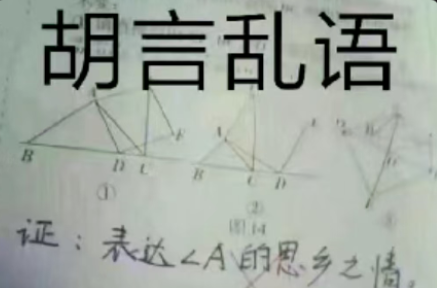
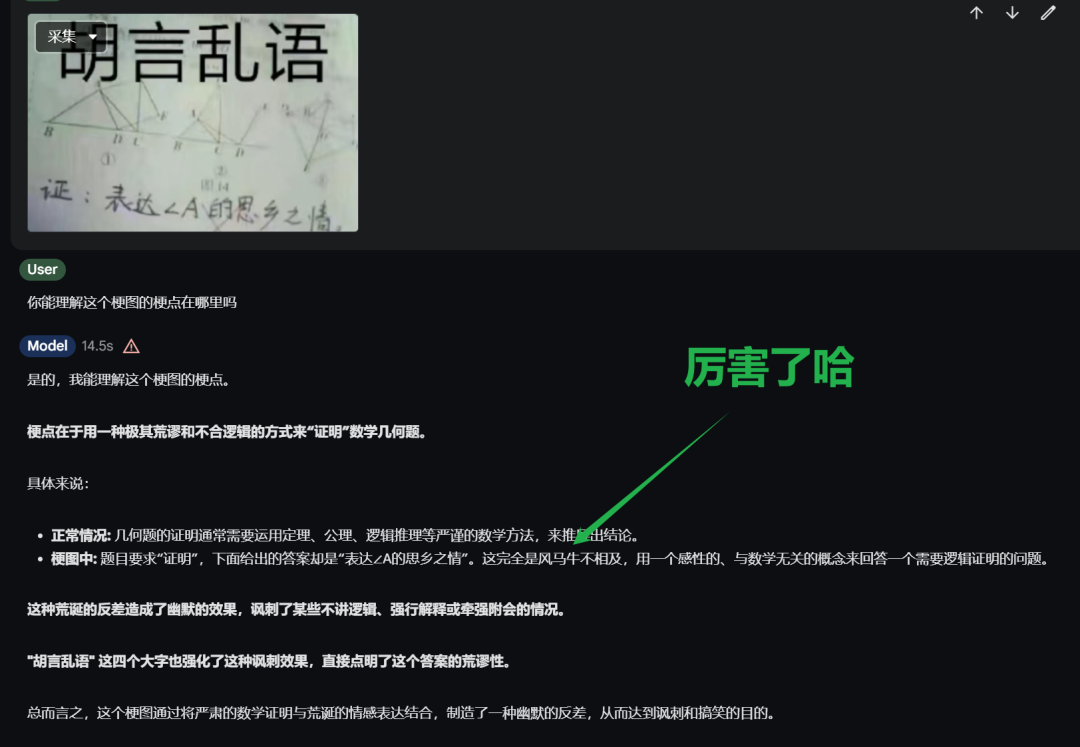
你能理解这个梗图的梗点在哪里吗?
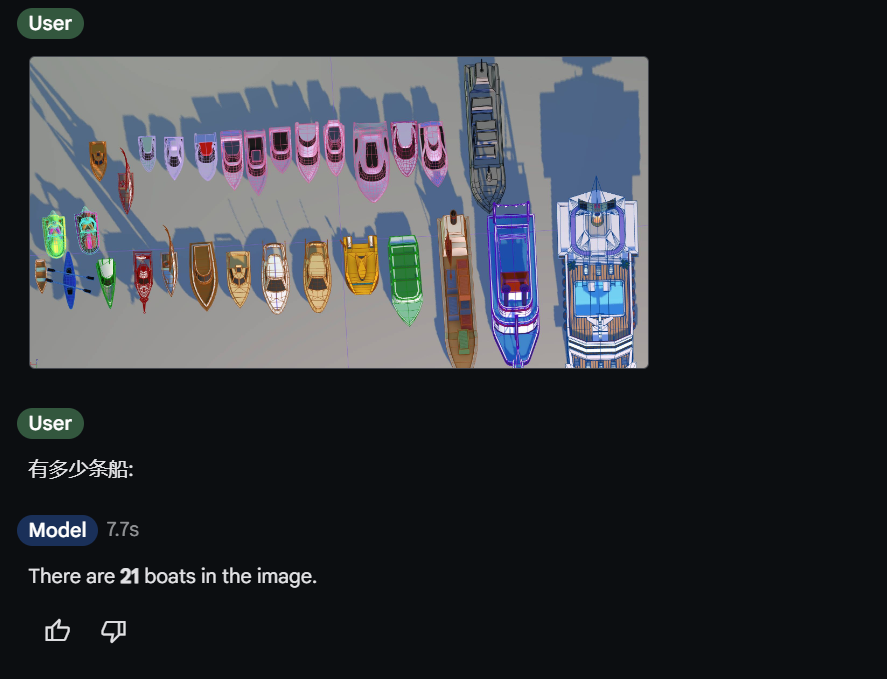
最后这个模型,在视觉计数上似乎不太完美,图1、图2分别应该是30条船和10条船:

🌟希望这篇文章对你有帮助,感谢阅读!如果你喜欢这系列文章请以 点赞 / 分享 / 在看 的方式告诉我,以便我用来评估创作方向。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)