广西民族大学高级人工智能课程—头歌实践教学实践平台-规则分词法
广西民族大学高级人工智能课程—头歌实践教学实践平台-规则分词法
1、正向最大匹配法
代码文件
def cutA(sentence, dictA):
# sentence:要分词的句子
result = []
sentenceLen = len(sentence)
n = 0
maxDictA = max([len(word) for word in dictA])
while n < sentenceLen:
matched = False
for i in range(maxDictA, 0, -1):
if n + i <= sentenceLen:
word = sentence[n:n + i]
if word in dictA:
result.append(word)
n += i
matched = True
break
if not matched:
result.append(sentence[n])
n += 1
print(result) # 输出分词结果
# 测试用例
if __name__ == "__main__":
dictA = set(["南京市", "长江", "大桥"])
sentences = ["南京市", "南京市长", "长江大桥", "大桥", "南京市长江大桥"]
for sentence in sentences:
cutA(sentence, dictA)
题目描述
任务描述
本关任务:根据本关所学有关中文分词的基础知识,采用规则分词法,完成正向最大匹配算法程序的编写并通过所有测试用例。
相关知识
为了完成本关任务,你需要掌握:
-
中文分词的含义;
-
规则分词各个算法的思想。
中文分词简介
在语言理解中,词是最小的能够独立活动的有意义的语言成分。将词确定下来是理解自然语言的第一步,只有跨越了这一步,中文才能像英文那样过渡到短语划分、概念抽取以及主题分析,以至自然语言理解,最终达到智能计算的最高境界。因此,每个 NLP 工作者都应掌握分词技术。
在汉语中,词以字为基本单位的,但是一篇文章的语义表达却仍然是以词来划分的。因此,在处理中文文本时,需要进行分词处理,将句子转化为词的表示。这个切词处理过程就是中文分词,它通过计算机自动识别出句子的词,在词间加入边界标记符,分隔出各个词汇。整个过程看似简单,然而实践起来却很复杂,最主要的困难就在于分词歧义。
现有的分词算法可分为三大类:
-
基于规则的分词方法;
-
基于统计的分词方法;
-
基于理解的分词方法。
本实训主要介绍的是基于字符串匹配的分词方法,即规则分词法。
什么是规则分词
基于规则的分词是一种机械分词方法,主要是通过维护词典,在切分语句时,将语句的每个字符串与词表中的词进行逐一匹配,找到则切分,否则不予切分。
按照匹配切分的方式,主要有正向最大匹配法、逆向最大匹配法以及双向最大匹配法三种方法,接下来我们将依次介绍这三种算法。
正向最大匹配法( MM 法)
1、算法描述 如图1所示,正向最大匹配算法的具体步骤为:
- 从左向右取待切分汉语句的 m 个字符作为匹配字段, m 是机器词典中最长词条的字符数;
- 查找机器词典并进行匹配。匹配成功则将匹配字段作为一个词切分出来,匹配失败则将匹配字段的最后一个字去掉,剩下的字符串作为新的匹配字段,进行再匹配,一直重复上述过程直到切分出所有词。
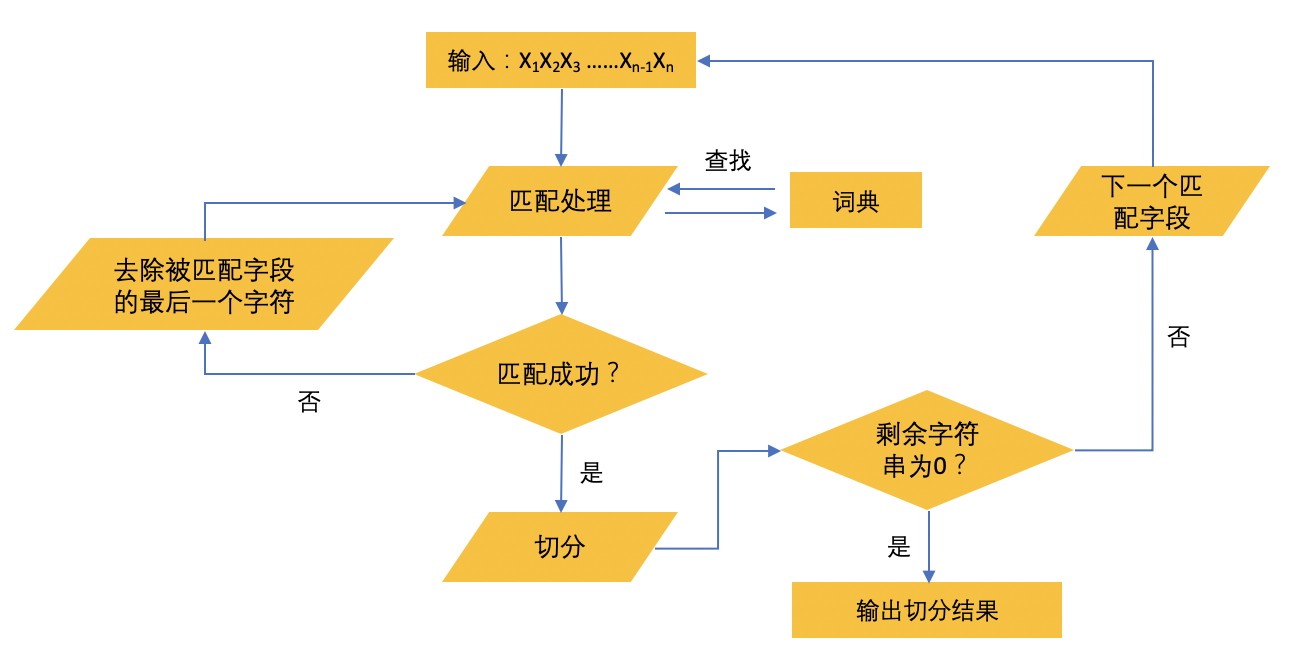
图 1 正向最大匹配
2、主要思想: 假定分词词典中最长词有 i 个汉字字符,则用被处理文档的当前字符串中的前 i 个字作为匹配字段,查找字典,从而得出分词结果。
3、范例 我们现有的分词词典中最长的长度为5,词典中有南京市、长江、大桥三词,现采用 MM 法对句子南京市长江大桥进行分词,那么首先从句子中取出前5个字南京市长江,发现词典中没有该词,于是缩小长度,取前4个字南京市长,发现词典中还是没有该词,于是继续缩小长度,取前3个字南京市,词典中存在该词,于是该词被确认切分。再将剩下的长江大桥按照同样方式进行切分,得到长江和大桥,最终切分为南京市/长江/大桥3个词。
编程要求
根据提示,在右侧编辑器中的 Begin-End 之间补充 Python 代码,实现正向最大匹配算法,基于所输入的词典,完成对 sentence 的分词并输出分词结果。其中词典的值和 sentence 均通过 input 从后台获取。
测试说明
平台将使用测试集运行你编写的程序代码,若全部的运行结果正确,则通关。 测试输入: 南京市 南京市长 长江大桥 大桥 南京市长江大桥
预期输出: ['南京市长', '江', '大桥']
开始你的任务吧,祝你成功!
2、逆向最大匹配法
代码文件
def cutB(sentence, dictB):
result = []
sentenceLen = len(sentence)
maxDictB = max([len(word) for word in dictB])
# 任务:完成逆向最大匹配算法的代码描述
# ********** Begin *********#
n = sentenceLen
while n > 0:
matched = False
for i in range(maxDictB, 0, -1):
if n - i < 0: # 如果超出句子起始位置,跳过
continue
word = sentence[n - i:n]
if word in dictB:
result.append(word)
n -= i
matched = True
break
if not matched: # 如果没有匹配到词,取一个字符作为词
result.append(sentence[n - 1])
n -= 1
# ********** End **********#
print(result[::-1], end="")
题目描述
任务描述
本关任务:根据本关所学有关中文分词的基础知识,采用规则分词法,完成逆向最大匹配算法程序的编写并通过所有测试用例。
相关知识
为了完成本关任务,你需要掌握:
-
逆向最大匹配算法的思想;
-
逆向最大匹配算法的步骤。
逆向最大匹配法( RMM 法)
1、算法描述 逆向最大匹配( RMM 法)法的基本思想与 MM 法相同,不同的是分词切分的方向与 MM 法相反。逆向最大匹配法从右到左来进行切分。每次取最右边(末端)的 m 个字符作为匹配字段, 若匹配失败,则去掉匹配字段最左边(前面)的一个字,继续匹配。
2、范例 比如:南京市长江大桥,按照逆向最大匹配,分词词典中最长词条的字符数长度为5,分词词典中有南京市长和长江大桥两词,现采用 RMM 法对句子南京市长江大桥进行分词,那么首先从句子中从右到左取出前5个字市长江大桥,发现词典中没有该词,于是缩小长度,取前4个字长江大桥,词典中存在该词,于是该词被确认切分。再将剩下的南京市按照同样方式进行切分,得到南京市,最终切分为南京市/长江大桥2个词。当然,如此切分并不代表完全正确,可能有个叫江大桥的南京市长也说不定。
由于汉语中偏正结构偏多,逆向最大匹配分词更多时候比正向最大匹配分词准确率高。
编程要求
根据提示,在右侧编辑器中的 Begin-End 之间补充 Python 代码,实现逆向最大匹配算法,基于所输入的词典,完成对 sentence 的分词并输出分词结果。其中词典的值和 sentence 均通过 input 从后台获取。
测试说明
平台将使用测试集运行你编写的程序代码,若全部的运行结果正确,则通关。 测试输入: 南京市 南京市长 长江大桥 大桥 南京市长江大桥
预期输出: ['南京市', '长江大桥']
开始你的任务吧,祝你成功!
3、双向最大匹配法
代码文件
class BiMM():
def __init__(self):
self.window_size = 3 # 字典中最长词数
def MMseg(self, text, dict): # 正向最大匹配算法
result = []
index = 0
text_length = len(text)
while text_length > index:
for size in range(self.window_size + index, index, -1):
piece = text[index:size]
if piece in dict:
index = size - 1
break
index += 1
result.append(piece)
return result
def RMMseg(self, text, dict): # 逆向最大匹配算法
result = []
index = len(text)
while index > 0:
for size in range(index - self.window_size, index):
piece = text[size:index]
if piece in dict:
index = size + 1
break
index = index - 1
result.append(piece)
result.reverse()
return result
def main(self, text, r1, r2):
# 比较两种分词方法的结果
if len(r1) != len(r2):
result = r1 if len(r1) < len(r2) else r2
else:
# 计算每个结果中单字词的数量
r1_single_chars = sum(len(word) == 1 for word in r1)
r2_single_chars = sum(len(word) == 1 for word in r2)
# 比较单字词数量,选择单字词较少的结果
result = r1 if r1_single_chars <= r2_single_chars else r2
# 打印结果而不是返回
print(result)
题目描述
任务描述
本关任务:根据本关所学有关中文分词的基础知识,采用规则分词法,完成双向最大匹配算法程序的编写并通过所有测试用例。
相关知识
为了完成本关任务,你需要掌握:
-
双向最大匹配法的思想;
-
双向最大匹配法的步骤。
双向最大匹配法
双向最大匹配的基本思想是将正向最大匹配法得到的分词结果和逆向最大匹配法得到的分词结果进行比较,然后按照最大匹配原则,选取词数切分最少的作为结果。该匹配算法的具体描述如下:
-
比较正向最大匹配和逆向最大匹配结果;
-
如果分词数量结果不同,那么取分词数量较少的那个;
-
在分词数量结果相同的情况下,如果分词结果相同,则可以返回任何一个;如果分词结果不同,则返回单字数比较少的那个。
比如北京大学生前来应聘这个句子,如果通过正向最大匹配算法得到的结果为北京大学 / 生前 / 来 / 应聘,其中分词数量为4,单字数为 1;而通过逆向最大匹配算法所得到的结果为北京/ 大学生/ 前来 / 应聘,其中分词数量为4,单字数为0。则根据双向最大匹配算法,逆向匹配单字数少,因此返回逆向匹配的结果。
经研究表明,90%的中文使用正向最大匹配分词和逆向最大匹配分词能得到相同的结果,而且保证分词正确;9%的句子是正向最大匹配分词和逆向最大匹配分词切分有分歧的,但是其中一定有一个是正确的;不到1%的句子是正向和逆向同时犯相同的错误:给出相同的结果但都是错的。因此,在实际的中文处理中,双向最大匹配分词能够胜任几乎全部的场景。
编程要求
根据提示,在右侧编辑器中的 Begin-End 之间补充 Python 代码,实现双向最大匹配算法,基于所输入的词典,完成对 sentence 的分词并输出分词结果。其中词典的值和 sentence 均通过 input 从后台获取。
测试说明
平台将使用测试集运行你编写的程序代码,若全部的运行结果正确,则通关。 测试输入: 研究 研究生 生命 的 起源 研究生命的起源 预期输出: ['研究', '生命', '的', '起源']
开始你的任务吧,祝你成功!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 20
20 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)