复试项目(Day_1:机器学习与深度学习)
K最近邻居(,简称KNN一种监督学习算法,用于分类和回归问题。它的基本思想是通过测量不同数据点之间的距离来进行预测。KNN的工作原理可以概括为以下几个步骤:①距离度量:KNN使用距离度量(通常是欧氏距离)来衡量数据点之间的相似性。②确定邻居数量K③投票机制类似于二叉树的判断(如下例)朴素贝叶斯一种基于贝叶斯定理的简单且高效的分类算法。其核心思想是:给定一个待分类项,通过计算该项属于各个类别的概率,
一、机器学习与深度学习介绍,深度学习基本知识
1、机器学习简介
一般是基于数学,或者统计学的方法,具有很强的可解释性.//可解释性让我们知道模型为什么这样做,而不可解释性则意味着我们无法直观地理解模型的决策过程.
例如: KNN, 决策树,朴素贝叶斯
※算法介绍 (KNN、决策树、朴素贝叶斯)
KNN:K最近邻居(K-Nearest Neighbors,简称KNN)
一种监督学习算法,用于分类和回归问题。它的基本思想是通过测量不同数据点之间的距离来进行预测。KNN的工作原理可以概括为以下几个步骤:
①距离度量: KNN使用距离度量(通常是欧氏距离)来衡量数据点之间的相似性。
②确定邻居数量K
③投票机制
决策树:
类似于二叉树的判断(如下例)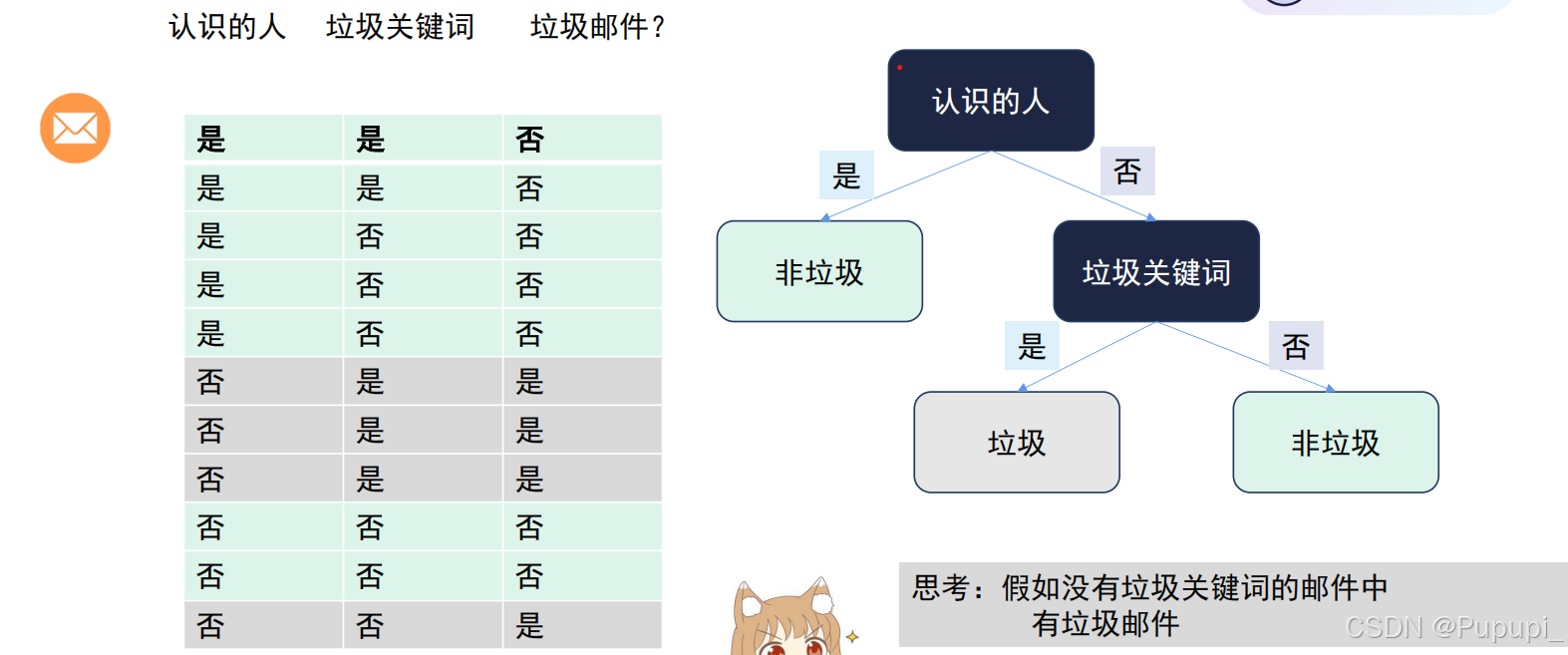
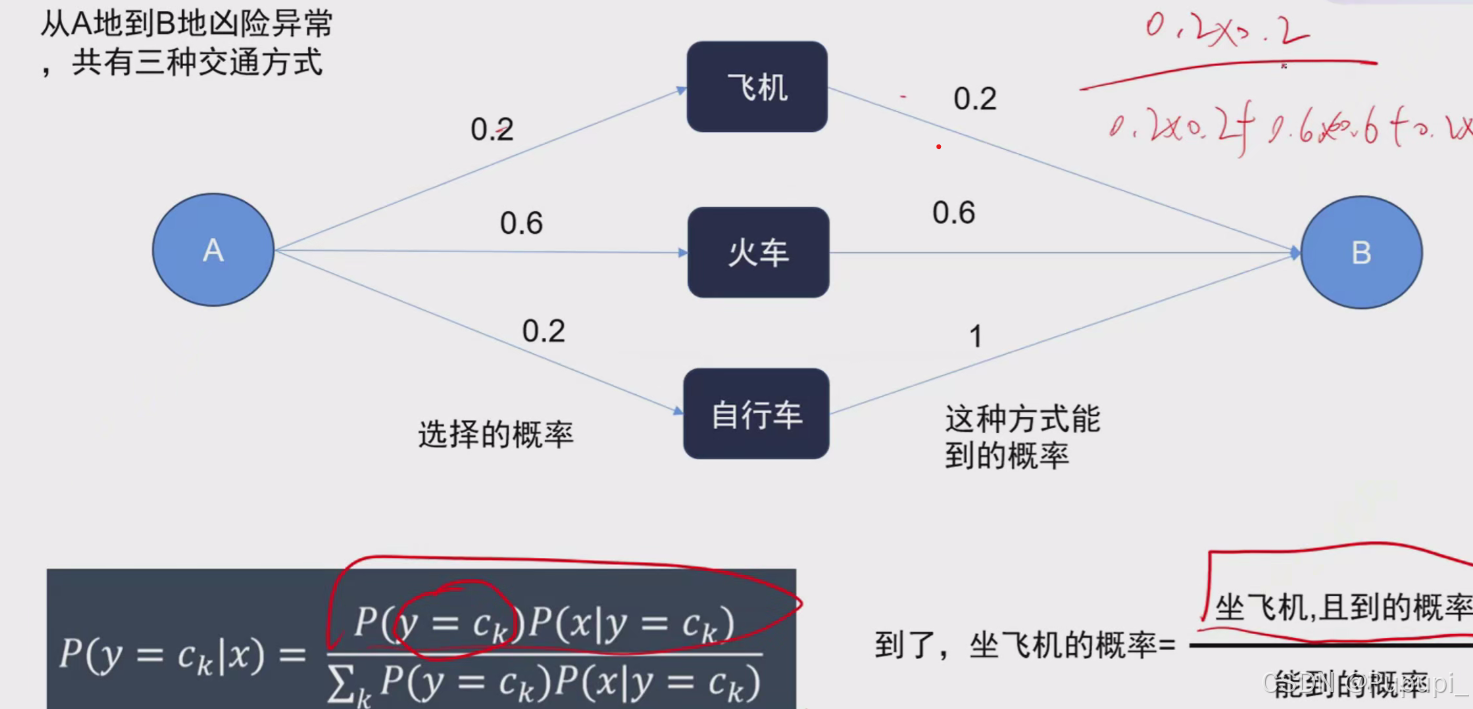
2、深度学习简介

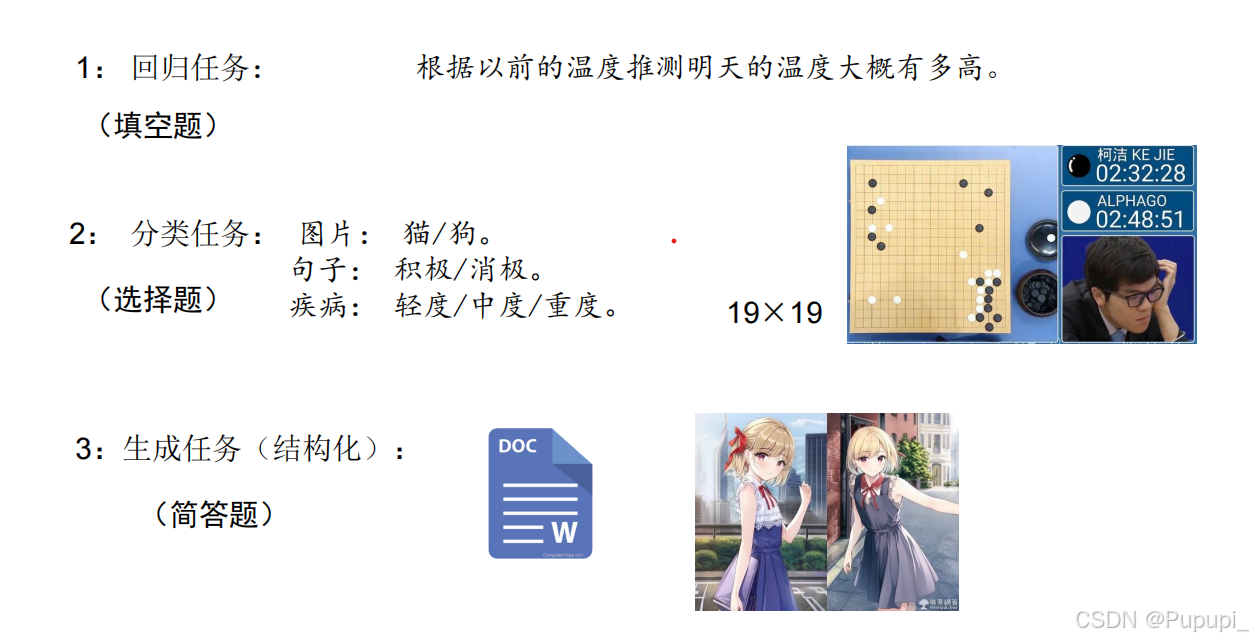
二、回归与神经元
1、如何开始深度学习
①定义一个函数(模型)

②定义一个合适的损失函数

③根据损失,对模型进行优化


MAE:均绝对误差
-
定义:MAE通过计算每个样本的预测值与真实值之间的差的绝对值,然后对这些绝对值求平均来得到。它衡量的是预测值与实际值之间的平均绝对差异。
-
公式:MAE =
其中n为样本数量,yi为真实值,ŷi为预测值。
-
特点:
- 简单直观:MAE的计算过程简单明了,易于理解和应用。
- 对异常值敏感度低:由于MAE计算的是差的绝对值,因此它对异常值的敏感度相对较低,这使得它在处理具有异常值的数据集时表现更加稳健。
- 大误差不敏感:然而,MAE对大误差的惩罚力度不如MSE,因此在某些情况下可能无法准确反映模型的预测性能。
MSE:均方误差
-
定义:MSE通过计算模型预测值与实际观测值之间误差的平方的平均值来量化模型预测性能的优劣。它衡量的是预测值与真实值之间差异的平方的平均值。
-
公式:MSE =
,其中n为样本数量,yi为真实值,ŷi为预测值。
-
特点:
- 敏感性高:MSE对预测误差非常敏感,即使是小的误差也会导致MSE值显著增加。这使得MSE在评估模型预测精度时具有较高的分辨率。
- 放大异常值影响:由于MSE计算的是误差的平方,因此异常值对MSE的影响会被放大。这可能导致模型在异常值较多的数据集上表现不佳。
- 优化友好:MSE是光滑的函数,因此在优化过程中更容易处理。许多机器学习算法都使用MSE作为损失函数来优化模型参数。
-
应用场景:MSE在统计学、数学以及机器学习领域中广泛应用。在数学与统计学中,MSE是评估回归模型性能的重要工具;在时间序列预测中,MSE可以帮助研究人员评估预测模型对未来数据点的预测精度;在假设检验中,MSE则用于衡量样本数据与假设值之间的差异。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)