《吴恩达深度学习》深度神经网络课后作业(Python)
就是参考吴老师指导一步一步写的。
就是参考吴老师指导一步一步写的
1.初始化参数
import numpy as np
import h5py
import matplotlib.pyplot as plt
from dnn_utils_v2 import sigmoid, sigmoid_backward, relu, relu_backward
%matplotlib inline
plt.rcParams['figure.figsize'] = (5.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
%load_ext autoreload
%autoreload 2
np.random.seed(1)
def initialize_parameters(n_x, n_h, n_y):
""""
Argument:
n_x -- size of the input layer
n_h -- size of the hidden layer
n_y -- size of the output layer
Returns:
parameters -- python dictionary containing your parameters:
W1 -- weight matrix of shape (n_h, n_x)
b1 -- bias vector of shape (n_h, 1)
W2 -- weight matrix of shape (n_y, n_h)
b2 -- bias vector of shape (n_y, 1)
"""
np.random.seed(1)
W1 = np.random.randn(n_h, n_x) * 0.01
b1 = np.zeros((n_h, 1))
W2 = np.random.randn(n_y, n_h) * 0.01
b2 = np.zeros((n_y, 1))
assert(W1.shape == (n_h, n_x))
assert(b1.shape == (n_h, 1))
assert(W2.shape == (n_y, n_h))
assert(b2.shape == (n_y, 1))
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
def initialize_parameters_deep(layer_dims):
np.random.seed(3)
parameters = {}
L = len(layer_dims)
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layer_dims[l],layer_dims[l-1])*0.01
parameters['b' + str(l)] = np.zeros((layer_dims[l], 1))
assert(parameters['W' + str(l)].shape == (layer_dims[l], layer_dims[l-1]))
assert(parameters['b' + str(l)].shape == (layer_dims[l], 1))
return parameters
parameters = initialize_parameters_deep([5,4,3])
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))W1 = [[ 0.01788628 0.0043651 0.00096497 -0.01863493 -0.00277388]
[-0.00354759 -0.00082741 -0.00627001 -0.00043818 -0.00477218]
[-0.01313865 0.00884622 0.00881318 0.01709573 0.00050034]
[-0.00404677 -0.0054536 -0.01546477 0.00982367 -0.01101068]]
b1 = [[0.] [0.] [0.] [0.]]
W2 = [[-0.01185047 -0.0020565 0.01486148 0.00236716]
[-0.01023785 -0.00712993 0.00625245 -0.00160513]
[-0.00768836 -0.00230031 0.00745056 0.01976111]]
b2 = [[0.] [0.] [0.]]
2. 功能函数
def sigmoid(Z):
"""
Implements the sigmoid activation in numpy
Arguments:
Z -- numpy array of any shape
Returns:
A -- output of sigmoid(z), same shape as Z
cache -- returns Z as well, useful during backpropagation
"""
A = 1/(1+np.exp(-Z))
cache = Z
return A, cache
def relu(Z):
"""
Implement the RELU function.
Arguments:
Z -- Output of the linear layer, of any shape
Returns:
A -- Post-activation parameter, of the same shape as Z
cache -- a python dictionary containing "A" ; stored for computing the backward pass efficiently
"""
A = np.maximum(0,Z)
assert(A.shape == Z.shape)
cache = Z
return A, cache
3. 向前传播
def linear_forward(A, W, b):
Z = W@A + b
assert(Z.shape == (W.shape[0], A.shape[1]))
cache = (A, W, b)
return Z, cache
np.random.seed(1)
A = np.random.randn(3,2)
W = np.random.randn(1,3)
b = np.random.randn(1,1)
Z, linear_cache = linear_forward(A, W, b)
print("Z = " + str(Z))Z = [[ 3.26295337 -1.23429987]]
def linear_activation_forward(A_prev, W, b, activation):
if (activation == "sigmoid"):
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = sigmoid(Z)
elif activation == "relu":
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = relu(Z)
assert(A.shape == (W.shape[0], A_prev.shape[1]))
cache = (linear_cache, activation_cache)
return A, cache
np.random.seed(2)
A_prev = np.random.randn(3,2)
W = np.random.randn(1,3)
b = np.random.randn(1,1)
Z, linear_cache = linear_forward(A, W, b)
print("Z = " + str(Z))
A, linear_activation_cache = linear_activation_forward(A_prev, W, b, activation = "sigmoid")
print("With sigmoid: A = " + str(A))
A, linear_activation_cache = linear_activation_forward(A_prev, W, b, activation = "relu")
print("With ReLU: A = " + str(A))(linear_cache, activation_cache)这里分别是 “执行Z=W@A+B”之前的A,以及 W,B“
"本次激活函数执行的Z"
Z = [[-0.34998845 2.55442447]]
With sigmoid: A = [[0.96890023 0.11013289]]
With ReLU: A = [[3.43896131 0. ]]
4.L-layer Module
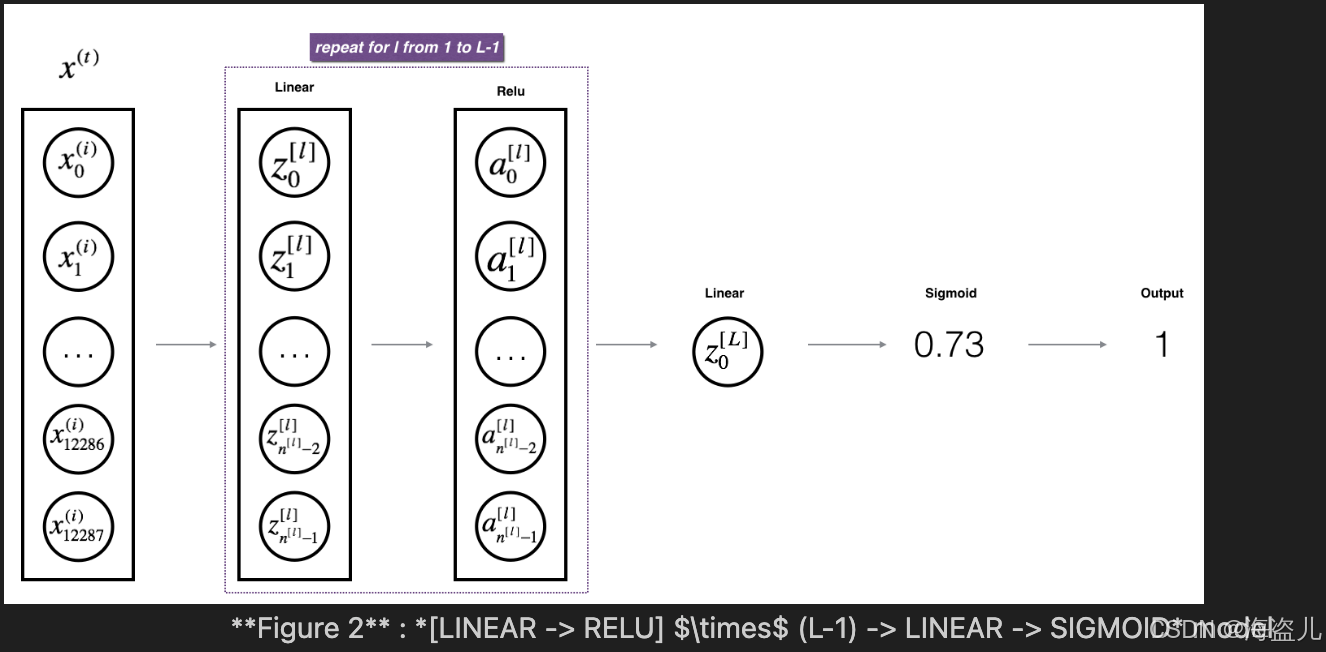
def L_model_forward(X, parameters):
#Arguments:
#X -- data, numpy array of shape (input size, number of examples)
#parameters -- output of initialize_parameters_deep()
caches = []
L = len(parameters) // 2
A = X
for l in range(1, L):
A_prev = A
A, cache = linear_activation_forward(A_prev, parameters["W" + str(l)], parameters["b" + str(l)], activation = "relu")
caches.append(cache)
AL, cache = linear_activation_forward(A, parameters["W" + str(L)], parameters["b" + str(L)], activation = "sigmoid")
caches.append(cache)
assert(AL.shape == (1, X.shape[1]))
return AL, caches5.cost function
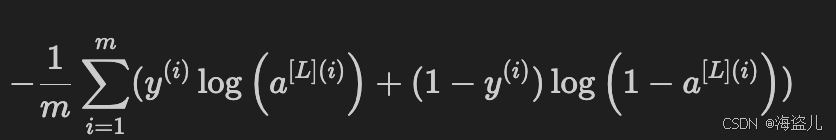
def compute_cost(AL, Y):
m = Y.shape[1]
cost1 = np.dot(Y,np.log(AL).T) + np.dot((1-Y), np.log(1-AL).T)
cost = -(cost1).sum()/m
cost = np.squeeze(cost) # To make sure your cost's shape is what we expect (e.g. this turns [[17]] into 17).
assert(cost.shape == ())
return cost
Y = np.asarray([[1, 1, 1]])
aL = np.array([[.8,.9,0.4]])
print("cost = " + str(compute_cost(aL, Y)))cost = 0.414931599615397
6. 向后传播
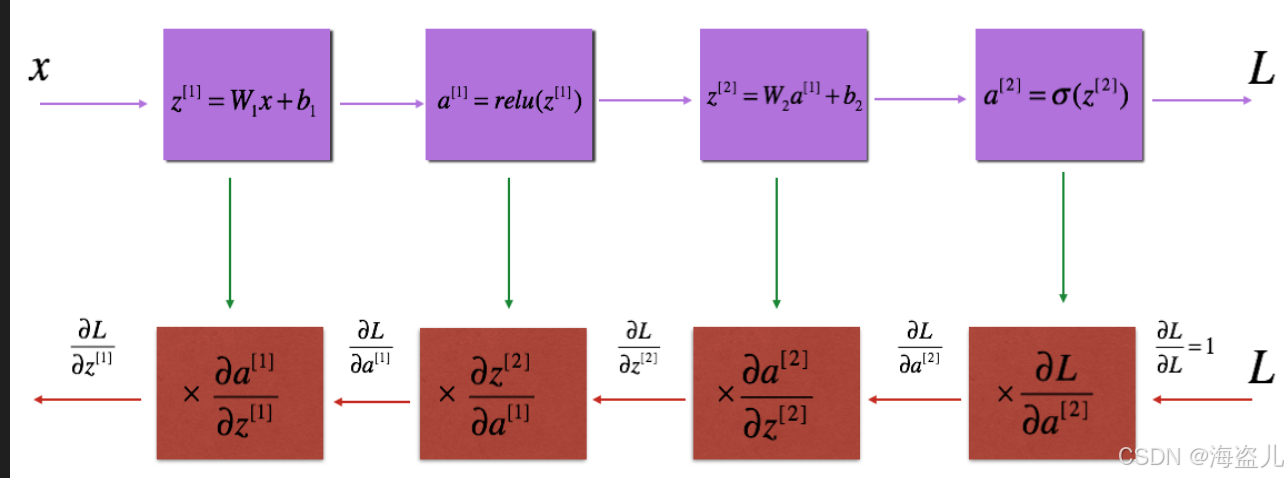
6.1 linear backward
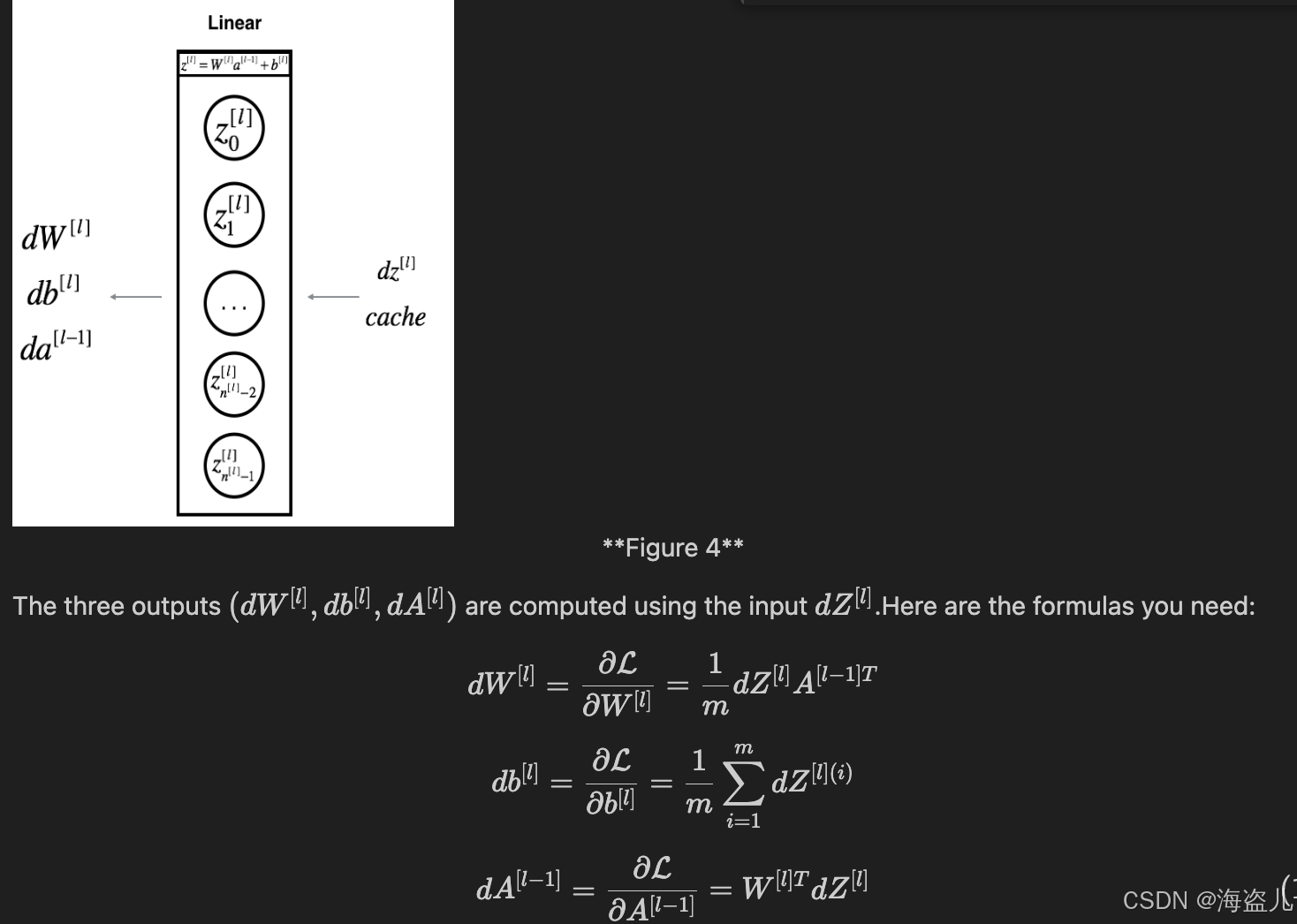
def linear_backward(dZ, cache):
A_prev, W, b = cache
m = A_prev.shape[1]
dW = np.dot(dZ, A_prev.T)/m
db = np.sum(dZ, axis=1,keepdims=True)/m
dA_prev = np.dot(W.T,dZ)
return dA_prev, dW, db
6.2 Linear-Activation backward
![]()
def relu_backward(dA, cache):
"""
Implement the backward propagation for a single RELU unit.
Arguments:
dA -- post-activation gradient, of any shape
cache -- 'Z' where we store for computing backward propagation efficiently
Returns:
dZ -- Gradient of the cost with respect to Z
"""
Z = cache
dZ = np.array(dA, copy=True) # just converting dz to a correct object.
# When z <= 0, you should set dz to 0 as well.
dZ[Z <= 0] = 0
assert (dZ.shape == Z.shape)
return dZdef sigmoid_backward(dA, cache):
"""
Implement the backward propagation for a single SIGMOID unit.
Arguments:
dA -- post-activation gradient, of any shape
cache -- 'Z' where we store for computing backward propagation efficiently
Returns:
dZ -- Gradient of the cost with respect to Z
"""
Z = cache
s = 1/(1+np.exp(-Z))
dZ = dA * s * (1-s)
assert (dZ.shape == Z.shape)
return dZdef linear_activation_backward(dA, cache, activation):
linear_cache, linear_activation_cache = cache
if activation == "relu":
dZ = relu_backward(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
elif activation == "sigmoid":
dZ = sigmoid_backward(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
return dA_prev, dW, db
np.random.seed(2)
dA = np.random.randn(1,2)
A = np.random.randn(3,2)
W = np.random.randn(1,3)
b = np.random.randn(1,1)
Z = np.random.randn(1,2)
linear_cache = (A, W, b)
activation_cache = Z
linear_activation_cache = (linear_cache, activation_cache)
dA_prev, dW, db = linear_activation_backward(dA, linear_activation_cache, activation = "sigmoid")
print ("sigmoid:")
print ("dA_prev = "+ str(dA_prev))
print ("dW = " + str(dW))
print ("db = " + str(db) + "\n")
dA_prev, dW, db = linear_activation_backward(dA, linear_activation_cache, activation = "relu")
print ("relu:")
print ("dA_prev = "+ str(dA_prev))
print ("dW = " + str(dW))
print ("db = " + str(db))sigmoid:
dA_prev = [[ 0.11017994 0.01105339] [ 0.09466817 0.00949723] [-0.05743092 -0.00576154]]
dW = [[ 0.10266786 0.09778551 -0.01968084]]
db = [[-0.05729622]]
relu:
dA_prev = [[ 0.44090989 0. ] [ 0.37883606 0. ] [-0.2298228 0. ]]
dW = [[ 0.44513824 0.37371418 -0.10478989]]
db = [[-0.20837892]]
7. L model backward
温习一下:
(linear_cache, activation_cache)这里分别是 “执行Z=W@A+B”之前的A,以及 W,B“
"本次激活函数执行的Z"
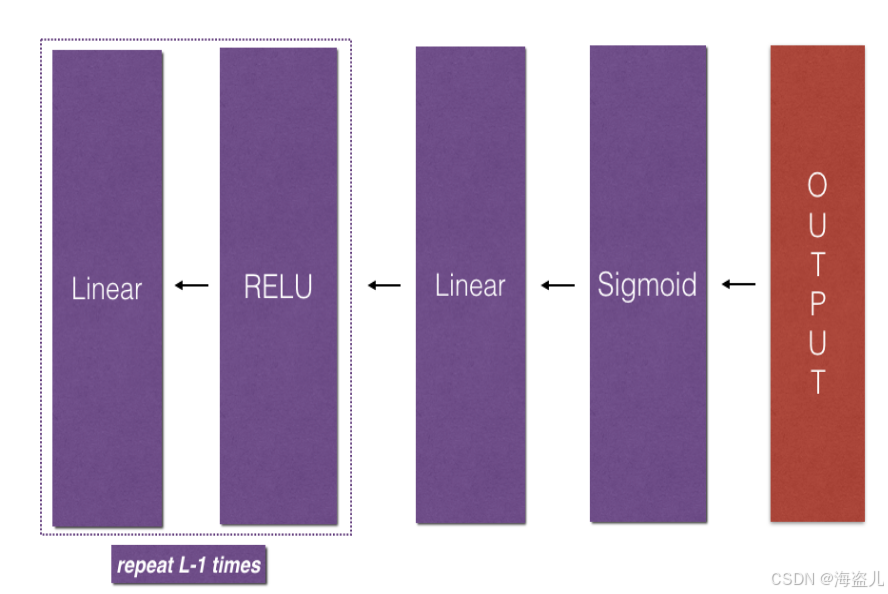
def L_model_backward(AL, Y, caches):
grads = {}
L = len(caches)
dAL = - (np.divide(Y, AL) - np.divide(1 - Y, 1 - AL))
current_cache = caches[L-1]
grads["dA" + str(L)], grads["dW" + str(L)], grads["db" + str(L)] = linear_activation_backward(dAL, current_cache, "sigmoid")
for l in reversed(range(L-1)):
dA_prev_temp, dW_temp, db_temp = linear_activation_backward(grads["dA" + str(l + 2)],current_cache,activation = "relu")
grads["dA" + str(l + 1)] = dA_prev_temp
grads["dW" + str(l + 1)] = dW_temp
grads["db" + str(l + 1)] = db_temp
return grads8.更新参数
def update_parameters(parameters, grads, learning_rate):
L = len(parameters) // 2 # number of layers in the neural network
for l in range(1,L+1):
parameters["W" + str(l)] = parameters["W" + str(l)] - learning_rate* grads["dW" + str(l)]
parameters["b" + str(l)] = parameters["b" + str(l)] - learning_rate* grads["db" + str(l)]
return parameters
9 建立模型
# GRADED FUNCTION: two_layer_model
def two_layer_model(X, Y, layers_dims, learning_rate = 0.0075, num_iterations = 3000, print_cost=False):
"""
Implements a two-layer neural network: LINEAR->RELU->LINEAR->SIGMOID.
Arguments:
X -- input data, of shape (n_x, number of examples)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat), of shape (1, number of examples)
layers_dims -- dimensions of the layers (n_x, n_h, n_y)
num_iterations -- number of iterations of the optimization loop
learning_rate -- learning rate of the gradient descent update rule
print_cost -- If set to True, this will print the cost every 100 iterations
Returns:
parameters -- a dictionary containing W1, W2, b1, and b2
"""
np.random.seed(1)
grads = {}
costs = [] # to keep track of the cost
m = X.shape[1] # number of examples
(n_x, n_h, n_y) = layers_dims
# Initialize parameters dictionary, by calling one of the functions you'd previously implemented
### START CODE HERE ### (≈ 1 line of code)
parameters = initialize_parameters(n_x,n_h,n_y)
### END CODE HERE ###
# Get W1, b1, W2 and b2 from the dictionary parameters.
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
# Loop (gradient descent)
for i in range(0, num_iterations):
# Forward propagation: LINEAR -> RELU -> LINEAR -> SIGMOID. Inputs: "X, W1, b1". Output: "A1, cache1, A2, cache2".
### START CODE HERE ### (≈ 2 lines of code)
A1, cache1 = linear_activation_forward(X,W1,b1,activation="relu")
A2, cache2 = linear_activation_forward(A1,W2,b2,activation="sigmoid")
### END CODE HERE ###
# Compute cost
### START CODE HERE ### (≈ 1 line of code)
cost = compute_cost(A2,Y)
### END CODE HERE ###
# Initializing backward propagation
dA2 = - (np.divide(Y, A2) - np.divide(1 - Y, 1 - A2))
# Backward propagation. Inputs: "dA2, cache2, cache1". Outputs: "dA1, dW2, db2; also dA0 (not used), dW1, db1".
### START CODE HERE ### (≈ 2 lines of code)
dA1, dW2, db2 = linear_activation_backward(dA2,cache2,activation="sigmoid")
dA0, dW1, db1 = linear_activation_backward(dA1,cache1,activation="relu")
### END CODE HERE ###
# Set grads['dWl'] to dW1, grads['db1'] to db1, grads['dW2'] to dW2, grads['db2'] to db2
grads['dW1'] = dW1
grads['db1'] = db1
grads['dW2'] = dW2
grads['db2'] = db2
# Update parameters.
### START CODE HERE ### (approx. 1 line of code)
parameters = update_parameters(parameters,grads,learning_rate)
### END CODE HERE ###
# Retrieve W1, b1, W2, b2 from parameters
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
# Print the cost every 100 training example
if print_cost and i % 100 == 0:
print("Cost after iteration {}: {}".format(i, np.squeeze(cost)))
if print_cost and i % 100 == 0:
costs.append(cost)
# plot the cost
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per tens)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters
parameters = two_layer_model(train_x, train_y, layers_dims = (n_x, n_h, n_y), num_iterations = 2500, print_cost=True)# GRADED FUNCTION: L_layer_model
def L_layer_model(X, Y, layers_dims, learning_rate = 0.0075, num_iterations = 3000, print_cost=False):#lr was 0.009
"""
Implements a L-layer neural network: [LINEAR->RELU]*(L-1)->LINEAR->SIGMOID.
Arguments:
X -- data, numpy array of shape (number of examples, num_px * num_px * 3)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat), of shape (1, number of examples)
layers_dims -- list containing the input size and each layer size, of length (number of layers + 1).
learning_rate -- learning rate of the gradient descent update rule
num_iterations -- number of iterations of the optimization loop
print_cost -- if True, it prints the cost every 100 steps
Returns:
parameters -- parameters learnt by the model. They can then be used to predict.
"""
np.random.seed(1)
costs = [] # keep track of cost
parameters = initialize_parameters_deep(layers_dims)
# Loop (gradient descent)
for i in range(0, num_iterations):
# Forward propagation: [LINEAR -> RELU]*(L-1) -> LINEAR -> SIGMOID.
AL, caches = L_model_forward(X, parameters)
# Compute cost.
cost = compute_cost(AL,Y)
# Backward propagation.
grads = L_model_backward(AL,Y,caches)
# Update parameters.
parameters = update_parameters(parameters,grads,learning_rate)
# Print the cost every 100 training example
if print_cost and i % 100 == 0:
print ("Cost after iteration %i: %f" %(i, cost))
if print_cost and i % 100 == 0:
costs.append(cost)
# plot the cost
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per tens)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters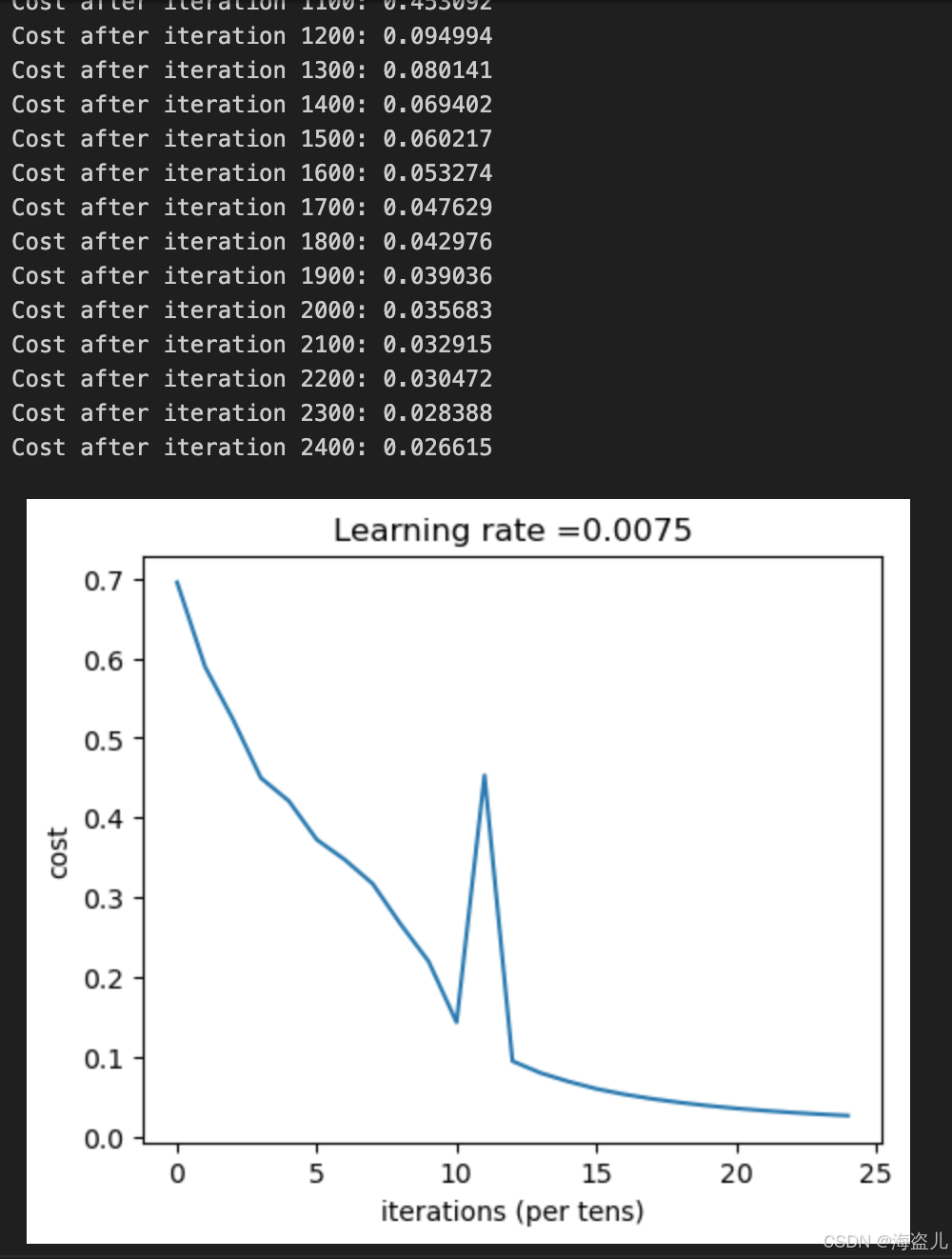
10 输入数据
这里跟逻辑回归里面读入数据一样。
train_x_orig, train_y, test_x_orig, test_y, classes = load_data()
m_train = train_x_orig.shape[0]
num_px = train_x_orig.shape[1]
m_test = test_x_orig.shape[0]
print ("Number of training examples: " + str(m_train))
print ("Number of testing examples: " + str(m_test))
print ("Each image is of size: (" + str(num_px) + ", " + str(num_px) + ", 3)")
print ("train_x_orig shape: " + str(train_x_orig.shape))
print ("train_y shape: " + str(train_y.shape))
print ("test_x_orig shape: " + str(test_x_orig.shape))
print ("test_y shape: " + str(test_y.shape))
# Reshape the training and test examples
train_x_flatten = train_x_orig.reshape(train_x_orig.shape[0], -1).T # The "-1" makes reshape flatten the remaining dimensions
test_x_flatten = test_x_orig.reshape(test_x_orig.shape[0], -1).T
# Standardize data to have feature values between 0 and 1.
train_x = train_x_flatten/255.
test_x = test_x_flatten/255.
print ("train_x's shape: " + str(train_x.shape))
print ("test_x's shape: " + str(test_x.shape))预测
def predict(X, y, parameters):
"""
This function is used to predict the results of a L-layer neural network.
Arguments:
X -- data set of examples you would like to label
parameters -- parameters of the trained model
Returns:
p -- predictions for the given dataset X
"""
m = X.shape[1]
n = len(parameters) // 2 # number of layers in the neural network
p = np.zeros((1,m))
# Forward propagation
probas, caches = L_model_forward(X, parameters)
# convert probas to 0/1 predictions
for i in range(0, probas.shape[1]):
if probas[0,i] > 0.5:
p[0,i] = 1
else:
p[0,i] = 0
#print results
#print ("predictions: " + str(p))
#print ("true labels: " + str(y))
print("Accuracy: " + str(np.sum((p == y)/m)))
return p
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)