机器学习课程笔记---支持向量机
·
引言
机器学习三种方法:
1、经典的参数估计方法
局限性是需要样本的先验分布
2、非线性方法,如ann
局限性是全靠经验,缺少理论
3、统计学习理论针对小样本
误差:
1、一般误差
真实误差
2、经验误差
来自样本
机器学习的目标是最小化一般误差,但是实际都是最小化经验误差
支持向量机同时最小化经验风险和置信风险。
vc维大,则拟合函数的维度高。
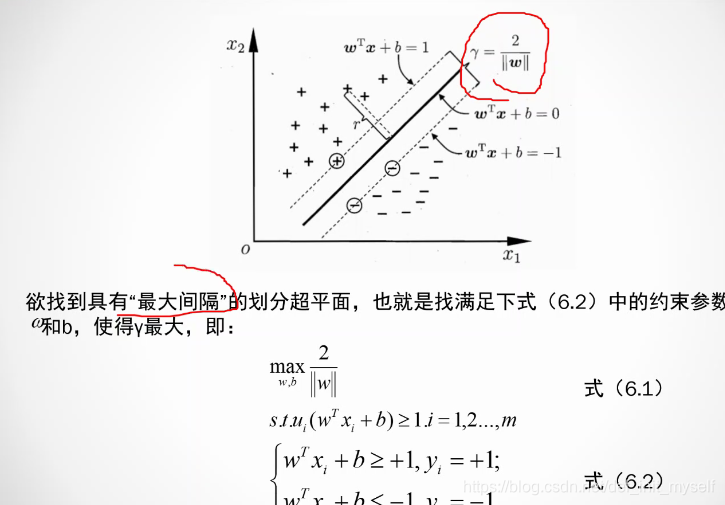
svm
基本型

这里的泛化能力最大就是说,正负类间隔最大。
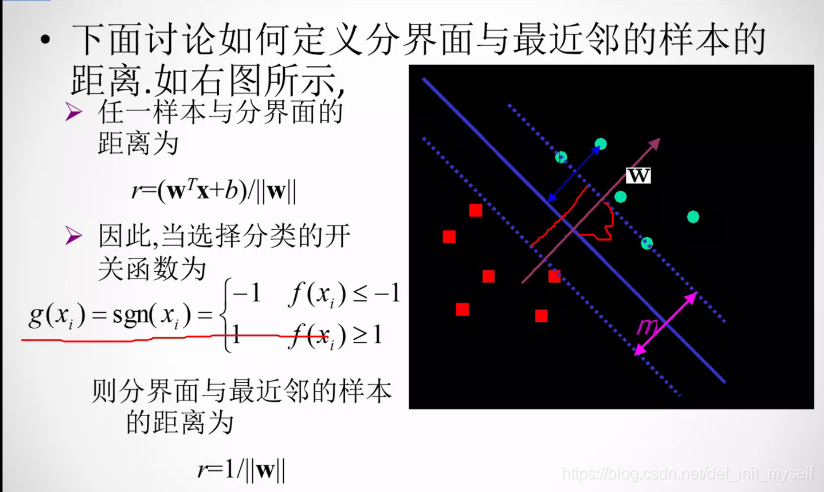

对偶问题

变成求aerfa。
解决不可分问题
映射
但是样本原来就是高维的怎么办?
因此引出了核
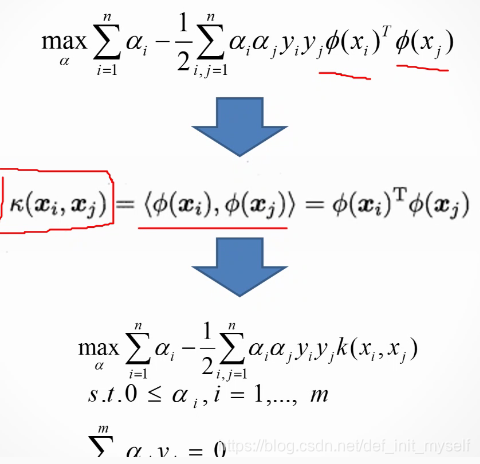
常用的核
效果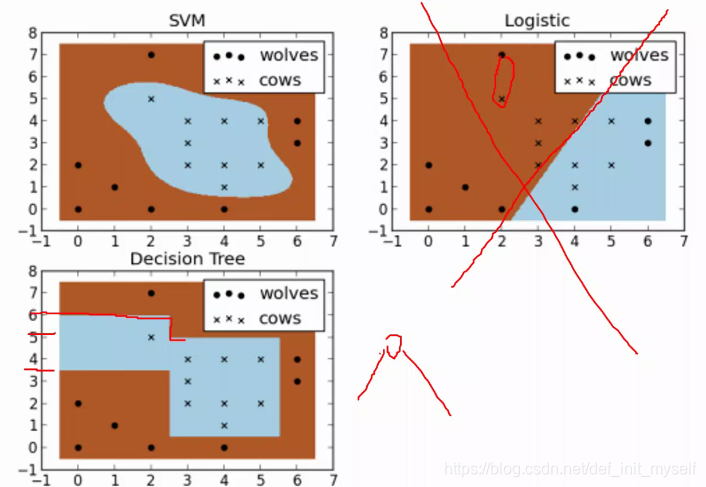
泛化问题
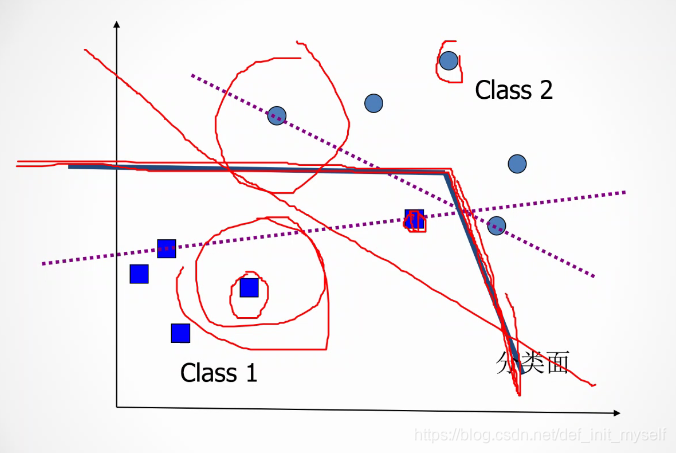
为了追求泛化能力强,可以容忍一个半个的样本错误。
被错分的样本离分解面的距离为kesai,然后把这些松弛变量的和最小。
与神经网络相比
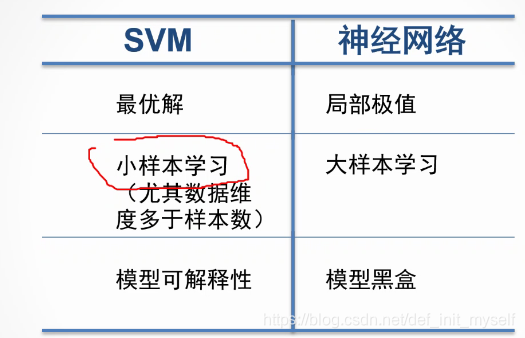
神经网络的模型黑盒导致很多严谨的地方不能用。比如航天。同时,比如dropout的存在让可复现性差。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)