机器学习之朴素贝叶斯
朴素贝叶斯引例•已知:非洲人10个中有9个黑人,1个白人,北美10个人中有3个黑人7个白人。•问:你在街上遇到1个黑人,那么他是非洲人还是北美人?•注:全球非洲12亿人口,北美3.6亿人口•A1:非洲人•A2:北美人•B1:白人•B2:黑人为什么有“朴素”二字“朴素”二字从何而来?x:样本属性,x**1:色泽,x**2:根蒂,…y:样本标签,是否是好瓜拉普拉斯修正拉普拉斯平滑处理•缺陷:受样本个数
·
朴素贝叶斯
引例
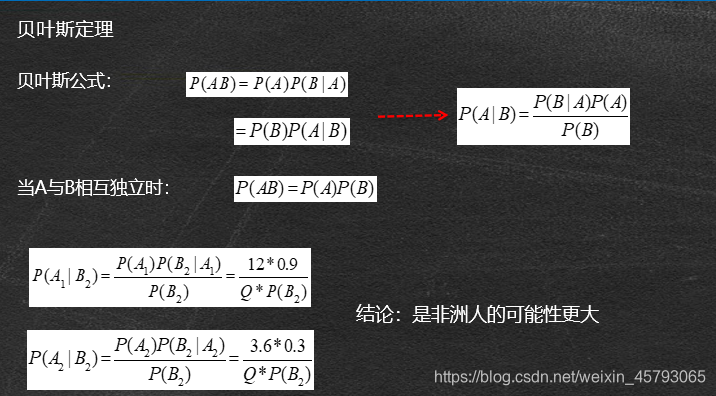
•已知:非洲人10个中有9个黑人,1个白人,北美10个人中有3个黑人7个白人。
•问:你在街上遇到1个黑人,那么他是非洲人还是北美人?
•注:全球非洲12亿人口,北美3.6亿人口
•A1:非洲人
•A2:北美人
•B1:白人
•B2:黑人

为什么有“朴素”二字
“朴素”二字从何而来?
x:样本属性,x**1:色泽,x**2:根蒂,…
y:样本标签,是否是好瓜



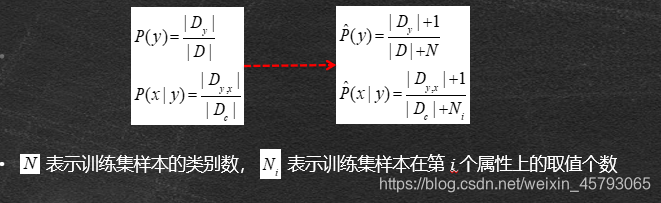
拉普拉斯修正
拉普拉斯平滑处理
•缺陷:受样本个数限制,若某个属性值在训练集中没有与某个同类同时出现过,如P清脆|是=P (敲声=清脆|好瓜=是)=0/8=0,则连乘公式 h (好瓜=是)则必为零,其他属性取任意值都不能改变这一结论。
•修正方法:拉普拉斯平滑处理


用高斯朴素贝叶斯算法解决鸢尾花分类问题
pthon实现
相关文档链接 sklearn.naive_bayes.GaussianNB
•naive Bayes is a decent classifier, but a bad estimator
•高斯朴素贝叶斯
•构造方法:sklearn.naive_bayes.GaussianNB
•GaussianNB 类构造方法无参数,属性值有:
• class_prior_ #每一个类的概率
• theta_ #每个类中各个特征的平均
• sigma_ #每个类中各个特征的方差
•注:GaussianNB 类无score 方法
多项式朴素贝叶斯——用于文本分类
构造方法:
sklearn.naive_bayes.MultinomialNB(alpha=1.0 #平滑参数
, fit_prior=True #学习类的先验概率
, class_prior=None) #类的先验概率
完整代码
import numpy as np
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split #分割训练集和测试集
from sklearn.metrics import classification_report #混淆矩阵分类报告
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
Y = np.array([1, 1, 1, 2, 2, 2])
clf = GaussianNB() # 构建模型
clf.fit(X, Y)
clf.predict([[-0.8, -1]])
iris = load_iris()
data_tr, data_te, label_tr, label_te = train_test_split(iris.data, iris.target, test_size=0.2)# 拆分专家样本集,8/10是训练样本,2/10是测试样本
clf.fit(data_tr, label_tr) # 模型训练
pre = clf.predict(data_te) # 模型预测
acc = sum(pre == label_te)/len(pre) # 模型在测试集样本上的预测精度
print(acc)
classification_report(label_te, pre) # 分类报告


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)