机器学习算法系列(〇)- 基础知识
阅读本文需要的背景知识点:一丢丢数学知识
一、引言
人工智能(AI)在现代生活中起到越来越重要的地位,各种语音助手、旧电影颜色修复、淘宝京东等电商网站的智能推荐、拍照软件的智能美颜背景虚化等等功能背后都离不开人工智能的支持。
在搜索引擎搜索人工智能的时候会发现机器学习会被同时联想出来,机器学习作为人工智能的一个分支学科,就是为了解决人工智能中的各种问题而提出来的。本算法系列文章将力求通俗易懂的介绍机器学习中的各种算法实现与应用。
古人云,“墙高基下,虽得必失”,没有稳固的基础是没法做成大事的,所以本文从基础知识开始,一步一步了解掌握机器学习的相关知识。
二、机器学习
维基百科中对机器学习1的定义:
- 机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能。
- 机器学习是对能通过经验自动改进的计算机算法的研究。
- 机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。
相较于维基百科中的定义,我觉得张志华老师在机器学习导论2中总结更利于理解。
机器学习(Machine learning) = 矩阵(Matrix) + 统计(statistics) + 算法(algorithm) + 优化(optimation)。
机器学习就是从一堆数据(矩阵)中,通过建立模型(统计),经过各种优化后的算法,最后从中获得知识的学科。可以看到机器学习离不开数学,其中又以线性代数和微积分最为重要。下面两个小节将介绍机器学习中所用到的线性代数和微积分知识点。
三、线性代数
线性代数作为数学中一个重要的分支,其内容极其庞大,本文只能选择性的介绍一些机器学习中所用到的线性代数知识,想更深入的了解这门课程,请参看其他的教材书籍。
向量
机器学习中大量使用到向量,例如线性组合里面的权重系数就可以表示为一个 n 维向量,将一个看起来很复杂的连加运算,变成一个相对简单的向量点积的运算。
定义
同时具有大小和方向的量称为向量,例如以一定速度(大小)朝某个方位(方向)飞出的子弹就是一个向量。在数学上,用坐标点的形式表示一个向量,也可以使用矩阵的形式表示一个向量,如下就表示一个三维空间中的一个向量。
v ⃗ = ( 1 , 2 , 3 ) 或 [ 1 2 3 ] \vec{v}=(1,2,3) \text { 或 } \left[\begin{array}{l} 1 \\ 2 \\ 3 \end{array}\right] v=(1,2,3) 或 ⎣⎡123⎦⎤
对于任意向量a,不论方向如何,若其大小为单位长度,则称其为a方向上的单位向量。另外只有大小的量成为标量,例如数字 5 就是一个标量。
向量的模
向量的模即为向量的长度,用两个单竖线或者两个双竖线表示,计算方法如下式:
∥ v ⃗ ∥ = 1 2 + 2 2 + 3 2 = 14 ∥ v n → ∥ = v 1 2 + v 2 2 + … + v n 2 = ∑ i = 1 n v i 2 \begin{array}{c} \|\vec{v}\|=\sqrt{1^{2}+2^{2}+3^{2}}=\sqrt{14} \\ \left\|\overrightarrow{v_{n}}\right\|=\sqrt{v_{1}^{2}+v_{2}^{2}+\ldots+v_{n}^{2}}=\sqrt{\sum_{i=1}^{n} v_{i}^{2}} \end{array} ∥v∥=12+22+32=14∥∥∥vn∥∥∥=v12+v22+…+vn2=∑i=1nvi2
向量运算
A ⃗ = ( 1 , 2 , 3 ) B ⃗ = ( 4 , 5 , 6 ) \vec{A}=(1,2,3) \quad \vec{B}=(4,5,6) A=(1,2,3)B=(4,5,6)
-
向量的加法 - 向量的各个维度对应相加
A ⃗ + B ⃗ = ( 1 + 4 , 2 + 5 , 3 + 6 ) = ( 5 , 7 , 9 ) \vec{A}+\vec{B}=(1+4,2+5,3+6)=(5,7,9) A+B=(1+4,2+5,3+6)=(5,7,9) -
向量的减法 - 向量的各个维度对应相减
A ⃗ − B ⃗ = ( 1 − 4 , 2 − 5 , 3 − 6 ) = ( − 3 , − 3 , − 3 ) \vec{A}-\vec{B}=(1-4,2-5,3-6)=(-3,-3,-3) A−B=(1−4,2−5,3−6)=(−3,−3,−3) -
向量与标量的乘法 - 向量的各个维度与这个标量相乘
2 A ⃗ = ( 2 × 1 , 2 × 2 , 2 × 3 ) = ( 2 , 4 , 6 ) 2 \vec{A}=(2 \times 1,2 \times 2,2 \times 3)=(2,4,6) 2A=(2×1,2×2,2×3)=(2,4,6) -
向量与向量的点积 - 两个向量各个维度相乘再求和,注意两个向量的点积为一个标量值
A ⃗ ⋅ B ⃗ = 1 × 4 + 2 × 5 + 3 × 6 = 32 \vec{A} \cdot \vec{B}=1 \times 4+2 \times 5+3 \times 6=32 A⋅B=1×4+2×5+3×6=32 -
两个向量的夹角 - 两个向量的点积除以两个向量模的乘积等于两个向量夹角的余弦值,当两个单位向量的夹角为 0 度时,说明这两个向量同向并共线,此时他们的点积最大为1
cos θ = A ⃗ ⋅ B ⃗ ∥ A ⃗ ∥ ∥ B ⃗ ∥ \cos \theta=\frac{\vec{A} \cdot \vec{B}}{\|\vec{A}\|\|\vec{B}\|} cosθ=∥A∥∥B∥A⋅B
矩阵
机器学习中也需要使用到矩阵,例如对于输入有 M 个特征 N 个数据的训练集 X 可以表示成一个 M x N 的矩阵。
定义
按照行和列排列的标量值形成的矩形阵列称为矩阵,矩阵也可以认为是多个向量的组合,矩阵一般用 M 表示。如下就表示了一个 2 行 3 列的矩阵,记为 2 x 3 矩阵,也可以看成由上面A、B向量组合而成的矩阵
M = [ 1 2 3 4 5 6 ] M=\left[\begin{array}{lll} 1 & 2 & 3 \\ 4 & 5 & 6 \end{array}\right] M=[142536]
特殊矩阵
-
方阵 - 行数和列数相同的矩阵
M = [ 1 2 3 4 5 6 7 8 9 ] M=\left[\begin{array}{lll} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{array}\right] M=⎣⎡147258369⎦⎤ -
三角矩阵 - 从左上到右下的对角线以下或者以上的元素都为 0 的方阵
M = [ 1 2 3 0 5 6 0 0 9 ] 或 [ 1 0 0 4 5 0 7 8 9 ] M=\left[\begin{array}{lll} 1 & 2 & 3 \\ 0 & 5 & 6 \\ 0 & 0 & 9 \end{array}\right] \text { 或 }\left[\begin{array}{lll} 1 & 0 & 0 \\ 4 & 5 & 0 \\ 7 & 8 & 9 \end{array}\right] M=⎣⎡100250369⎦⎤ 或 ⎣⎡147058009⎦⎤ -
对角矩阵 - 从左上到右下的对角线以外的元素都为 0 的方阵
M = [ 1 0 0 0 5 0 0 0 9 ] M=\left[\begin{array}{lll} 1 & 0 & 0 \\ 0 & 5 & 0 \\ 0 & 0 & 9 \end{array}\right] M=⎣⎡100050009⎦⎤ -
单位矩阵 - 从左上到右下的对角线的元素都是 1 的对角矩阵,单位矩阵一般用 I 表
I = [ 1 0 0 0 1 0 0 0 1 ] I=\left[\begin{array}{lll} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right] I=⎣⎡100010001⎦⎤
矩阵运算
A = [ 1 2 3 4 5 6 ] B = [ 3 2 1 6 5 4 ] C = [ 1 2 3 4 5 6 ] A=\left[\begin{array}{lll} 1 & 2 & 3 \\ 4 & 5 & 6 \end{array}\right] \quad B=\left[\begin{array}{lll} 3 & 2 & 1 \\ 6 & 5 & 4 \end{array}\right] \quad C=\left[\begin{array}{ll} 1 & 2 \\ 3 & 4 \\ 5 & 6 \end{array}\right] A=[142536]B=[362514]C=⎣⎡135246⎦⎤
-
矩阵的加法 - 矩阵的对应行列相加
A + B = [ 1 + 3 2 + 2 3 + 1 4 + 6 5 + 5 6 + 4 ] = [ 4 4 4 10 10 10 ] A+B=\left[\begin{array}{ccc} 1+3 & 2+2 & 3+1 \\ 4+6 & 5+5 & 6+4 \end{array}\right]=\left[\begin{array}{ccc} 4 & 4 & 4 \\ 10 & 10 & 10 \end{array}\right] A+B=[1+34+62+25+53+16+4]=[410410410] -
矩阵的减法 - 矩阵的对应行列相减
A − B = [ 1 − 3 2 − 2 3 − 1 4 − 6 5 − 5 6 − 4 ] = [ − 2 0 2 − 2 0 2 ] A-B=\left[\begin{array}{lll} 1-3 & 2-2 & 3-1 \\ 4-6 & 5-5 & 6-4 \end{array}\right]=\left[\begin{array}{lll} -2 & 0 & 2 \\ -2 & 0 & 2 \end{array}\right] A−B=[1−34−62−25−53−16−4]=[−2−20022] -
矩阵与标量的乘法 - 矩阵的对应行列与这个标量相乘
2 A = [ 2 × 1 2 × 2 2 × 3 2 × 4 2 × 5 2 × 6 ] = [ 2 4 6 8 10 12 ] 2 A=\left[\begin{array}{lll} 2 \times 1 & 2 \times 2 & 2 \times 3 \\ 2 \times 4 & 2 \times 5 & 2 \times 6 \end{array}\right]=\left[\begin{array}{ccc} 2 & 4 & 6 \\ 8 & 10 & 12 \end{array}\right] 2A=[2×12×42×22×52×32×6]=[28410612] -
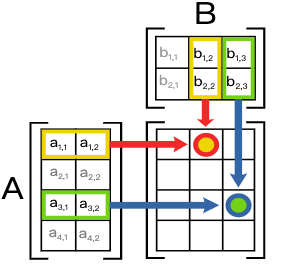
矩阵与矩阵的乘积 - 行向量与对应列向量的点积组成新矩阵的元素,如下图所示。注意两个矩阵只有第一个被乘矩阵的列数与第二个乘矩阵的行数相同才能做乘法。A 是 m x n 矩阵,B 是 n x p 矩阵,则 A x B 是 m x p 矩阵。
A × C = [ ( 1 ∗ 1 + 2 ∗ 3 + 3 ∗ 5 ) ( 1 ∗ 2 + 2 ∗ 4 + 3 ∗ 6 ) ( 4 ∗ 1 + 5 ∗ 3 + 6 ∗ 5 ) ( 4 ∗ 2 + 5 ∗ 4 + 6 ∗ 6 ) ] = [ 22 28 49 64 ] A \times C=\left[\begin{array}{ll} (1 * 1+2 * 3+3 * 5) & (1 * 2+2 * 4+3 * 6) \\ (4 * 1+5 * 3+6 * 5) & (4 * 2+5 * 4+6 * 6) \end{array}\right]=\left[\begin{array}{ll} 22 & 28 \\ 49 & 64 \end{array}\right] A×C=[(1∗1+2∗3+3∗5)(4∗1+5∗3+6∗5)(1∗2+2∗4+3∗6)(4∗2+5∗4+6∗6)]=[22492864]
-
矩阵的转置 - 将矩阵的行列交换位置,A 是 m x n 矩阵,则A的转置是 n x m 矩阵。
A T = [ 1 4 2 5 3 6 ] A^{T}=\left[\begin{array}{ll} 1 & 4 \\ 2 & 5 \\ 3 & 6 \end{array}\right] AT=⎣⎡123456⎦⎤ -
逆矩阵 - 给定一个方阵 A,若存在一个方阵 B,使得 A x B = B x A = I (单位矩阵),则称方阵 A 可逆,方阵 B 是 A 的逆矩阵。由于只有方阵才有可能存在逆矩阵,应用上有局限性,所以人们又提出了一个广义的逆矩阵,被称为伪逆矩阵,使得任意矩阵都存在伪逆矩阵。
A × A − 1 = I A \times A^{-1}=I A×A−1=I -
行列式 - 方阵 A 的行列式记作det(A)或|A|,当方阵 A 不可逆时,行列式为 0。行列式可通过拉普拉斯展开通过递归的方式得到,下式就是其中一种拉普拉斯展开的形式。
∣ M ∣ = ( − 1 ) ( 1 + 1 ) ⋅ M 1 , 1 × ∣ M ( 1 , 1 ) ∣ + ( − 1 ) ( 2 + 1 ) ⋅ M 2 , 1 × ∣ M ( 2 , 1 ) ∣ + ⋯ + ( − 1 ) ( n + 1 ) M n , 1 × ∣ M ( n , 1 ) ∣ M ( i , j ) 表 示 原 矩 阵 去 掉 第 i 行 和 第 j 列 后 组 成 的 新 矩 阵 \begin{array}{c} |M| = (-1)^{(1+1)} \cdot M_{1,1} \times\left|M^{(1,1)}\right|+(-1)^{(2+1)} \cdot M_{2,1} \times\left|M^{(2,1)}\right|+\cdots+(-1)^{(n+1)} M_{n, 1} \times\left|M^{(n, 1)}\right| \\ M^{(i, j)} 表示原矩阵去掉第 i 行和第 j 列后组成的新矩阵 \end{array} ∣M∣=(−1)(1+1)⋅M1,1×∣∣M(1,1)∣∣+(−1)(2+1)⋅M2,1×∣∣M(2,1)∣∣+⋯+(−1)(n+1)Mn,1×∣∣M(n,1)∣∣M(i,j)表示原矩阵去掉第i行和第j列后组成的新矩阵 -
特征值与特征向量 - 给定一个方阵 A,它的特征向量经过线性变换后,得到的新向量仍然与原向量保持在同一直线上,但长度也许会改变。
A ⋅ v ⃗ = λ ⋅ v ⃗ A 为方阵, v ⃗ 为 A 的特征向量, λ 为特征值 \begin{array}{c} A \cdot \vec{v}=\lambda \cdot \vec{v} \\ A \text { 为方阵, } \vec{v} \text { 为 } A \text { 的特征向量, } \lambda \text { 为特征值 } \end{array} A⋅v=λ⋅vA 为方阵, v 为 A 的特征向量, λ 为特征值 -
奇异值分解(SVD)- 任意一个 m x n 矩阵都可以分解成三个简单矩阵的乘积的形式。
M = U ⋅ Σ ⋅ V ∗ U 是 m × m 阶西矩阵 Σ 是 m × n 阶非负实数对角矩阵 V ∗ 为 V 的共轭转置, 是 n × n 阶酉矩阵 \begin{array}{c} M=U \cdot \Sigma \cdot V^{*} \\ U \text { 是 } m \times m \text { 阶西矩阵 } \\ \Sigma \text { 是 } m \times n \text { 阶非负实数对角矩阵 } \\ V^{*} \text { 为 } V \text { 的共轭转置, 是 } n \times n \text { 阶酉矩阵 } \end{array} M=U⋅Σ⋅V∗U 是 m×m 阶西矩阵 Σ 是 m×n 阶非负实数对角矩阵 V∗ 为 V 的共轭转置, 是 n×n 阶酉矩阵 -
矩阵的迹 - 方阵 A 的迹是从左上到右下的对角线上的元素的总和,记作 tr(A)。一个矩阵的迹是其特征值的总和。
tr ( A ) = A 1 , 1 + A 2 , 2 + ⋯ + A n , n \operatorname{tr}(A)=A_{1,1}+A_{2,2}+\cdots+A_{n, n} tr(A)=A1,1+A2,2+⋯+An,n
四、微分
微积分是研究极限、微分、积分的一个数学分支,在机器学习中大部分只需要了解微分学的知识,所以本文只介绍微分相关的基础知识点。
导数
-
极限 - 当一个有顺序的数列往前延伸时,如果存在一个有限数(非无限大的数),使这个数列可以无限地接近这个数,这个数就是这个数列的极限。当 x 越大时,该函数趋近于 0,表示方式如下:
lim x → ∞ 1 x = 0 \lim _{x \rightarrow \infty} \frac{1}{x}=0 x→∞limx1=0 -
导数3 - 函数在某一点的导数为这一点附近的变化率,其几何意义为函数在这一点上的切线的斜率。下图直观的表达了导数的定义
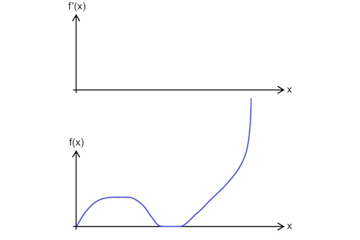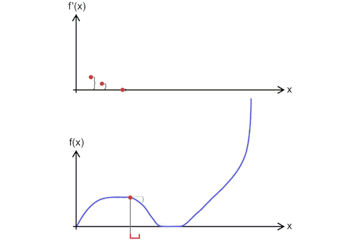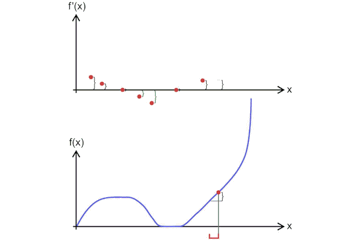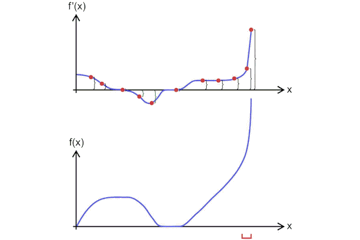
f ′ ( x 0 ) = lim x → x 0 f ( x ) − f ( x 0 ) x − x 0 f^{\prime}\left(x_{0}\right)=\lim _{x \rightarrow x_{0}} \frac{f(x)-f\left(x_{0}\right)}{x-x_{0}} f′(x0)=x→x0limx−x0f(x)−f(x0) -
导数列表 - 常见函数的导数
原函数 导函数 f ( x ) = C f ′ ( x ) = 0 f ( x ) = x u ( u ≠ 0 ) f ′ ( x ) = u x u − 1 f ( x ) = e x f ′ ( x ) = e x f ( x ) = ln x f ′ ( x ) = 1 x f ( x ) = sin x f ′ ( x ) = cos x f ( x ) = cos x f ′ ( x ) = − sin x f ( x ) = tan x f ′ ( x ) = 1 cos 2 x x \begin{array}{cc} \text { 原函数 } & \text { 导函数 } \\ f(x)=C & f^{\prime}(x)=0 \\ f(x)=x^{u}(u \neq 0) & f^{\prime}(x)=u x^{u-1} \\ f(x)=e^{x} & f^{\prime}(x)=e^{x} \\ f(x)=\ln x & f^{\prime}(x)=\frac{1}{x} \\ f(x)=\sin x & f^{\prime}(x)=\cos x \\ f(x)=\cos x & f^{\prime}(x)=-\sin x \\ f(x)=\tan x & f^{\prime}(x)=\frac{1}{\cos ^{2} x} x \end{array} 原函数 f(x)=Cf(x)=xu(u=0)f(x)=exf(x)=lnxf(x)=sinxf(x)=cosxf(x)=tanx 导函数 f′(x)=0f′(x)=uxu−1f′(x)=exf′(x)=x1f′(x)=cosxf′(x)=−sinxf′(x)=cos2x1x -
导数运算
原函数 导函数 f ( x ) = g ( x ) + h ( x ) f ′ ( x ) = g ′ ( x ) + h ′ ( x ) f ( x ) = g ( x ) h ( x ) f ′ ( x ) = g ( x ) h ′ ( x ) + g ′ ( x ) h ( x ) f ( x ) = g ( x ) h ( x ) f ′ ( x ) = g ′ ( x ) h ( x ) − g ( x ) h ′ ( x ) h 2 ( x ) f ( x ) = g ( h ( x ) ) f ′ ( x ) = g ′ ( h ( x ) ) h ′ ( x ) \begin{array}{cc} \text { 原函数 } & \text { 导函数 } \\ f(x)=g(x)+h(x) & f^{\prime}(x)=g^{\prime}(x)+h^{\prime}(x) \\ f(x)=g(x) h(x) & f^{\prime}(x)=g(x) h^{\prime}(x)+g^{\prime}(x) h(x) \\ f(x)=\frac{g(x)}{h(x)} & f^{\prime}(x)=\frac{g^{\prime}(x) h(x)-g(x) h^{\prime}(x)}{h^{2}(x)} \\ f(x)=g(h(x)) & f^{\prime}(x)=g^{\prime}(h(x)) h^{\prime}(x) \end{array} 原函数 f(x)=g(x)+h(x)f(x)=g(x)h(x)f(x)=h(x)g(x)f(x)=g(h(x)) 导函数 f′(x)=g′(x)+h′(x)f′(x)=g(x)h′(x)+g′(x)h(x)f′(x)=h2(x)g′(x)h(x)−g(x)h′(x)f′(x)=g′(h(x))h′(x)
高阶导数
-
偏导数 - 一个多变量的函数对其中一个变量求导数,其他变量保持不变
f ( x , y ) = x 3 + x y + y 2 ∂ f ∂ x = 3 x 2 + y ∂ f ∂ y = x + 2 y \begin{array}{c} f(x, y)=x^{3}+x y+y^{2} \\ \frac{\partial f}{\partial x}=3 x^{2}+y \\ \frac{\partial f}{\partial y}=x+2 y \end{array} f(x,y)=x3+xy+y2∂x∂f=3x2+y∂y∂f=x+2y -
梯度 - 在多变量函数在点 P 的梯度是函数在点 P 上的偏导数为分量的向量。梯度不是零向量时,它的方向是函数在 P 上最大增长的方向,大小是其增长率
∇ f ( x , y ) = ( ∂ f ∂ x , ∂ f ∂ y ) \nabla f(x, y)=\left(\frac{\partial f}{\partial x}, \frac{\partial f}{\partial y}\right) ∇f(x,y)=(∂x∂f,∂y∂f) -
雅可比矩阵(Jacobians Matrix)- 由多变量函数的一阶偏导数按一定方式排列的矩阵
J = [ ∂ f ∂ x 1 ⋯ ∂ f ∂ x n ] = [ ∂ f 1 ∂ x 1 ⋯ ∂ f 1 ∂ x n ⋮ ⋱ ⋮ ∂ f m ∂ x 1 ⋯ ∂ f m ∂ x n ] \begin{array}{l} \mathbf{J}=\left[\begin{array}{ccc} \frac{\partial \mathbf{f}}{\partial x_{1}} & \cdots & \frac{\partial \mathbf{f}}{\partial x_{n}} \end{array}\right]=\left[\begin{array}{ccc} \frac{\partial f_{1}}{\partial x_{1}} & \cdots & \frac{\partial f_{1}}{\partial x_{n}} \\ \vdots & \ddots & \vdots \\ \frac{\partial f_{m}}{\partial x_{1}} & \cdots & \frac{\partial f_{m}}{\partial x_{n}} \end{array}\right] \end{array} J=[∂x1∂f⋯∂xn∂f]=⎣⎢⎡∂x1∂f1⋮∂x1∂fm⋯⋱⋯∂xn∂f1⋮∂xn∂fm⎦⎥⎤ -
黑塞矩阵(Hessian Matrix)- 由多变量函数的二阶偏导数按一定方式排列的方阵
H = [ ∂ 2 f ∂ x 1 2 ∂ 2 f ∂ x 1 ∂ x 2 ⋯ ∂ 2 f ∂ x 1 ∂ x n ∂ 2 f ∂ x 2 ∂ x 1 ∂ 2 f ∂ x 2 2 ⋯ ∂ 2 f ∂ x 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ 2 f ∂ x n ∂ x 1 ∂ 2 f ∂ x n ∂ x 2 ⋯ ∂ 2 f ∂ x n 2 ] \mathbf{H}=\left[\begin{array}{cccc} \frac{\partial^{2} f}{\partial x_{1}^{2}} & \frac{\partial^{2} f}{\partial x_{1} \partial x_{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{1} \partial x_{n}} \\ \frac{\partial^{2} f}{\partial x_{2} \partial x_{1}} & \frac{\partial^{2} f}{\partial x_{2}^{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{2} \partial x_{n}} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial^{2} f}{\partial x_{n} \partial x_{1}} & \frac{\partial^{2} f}{\partial x_{n} \partial x_{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{n}^{2}} \end{array}\right] H=⎣⎢⎢⎢⎢⎢⎡∂x12∂2f∂x2∂x1∂2f⋮∂xn∂x1∂2f∂x1∂x2∂2f∂x22∂2f⋮∂xn∂x2∂2f⋯⋯⋱⋯∂x1∂xn∂2f∂x2∂xn∂2f⋮∂xn2∂2f⎦⎥⎥⎥⎥⎥⎤
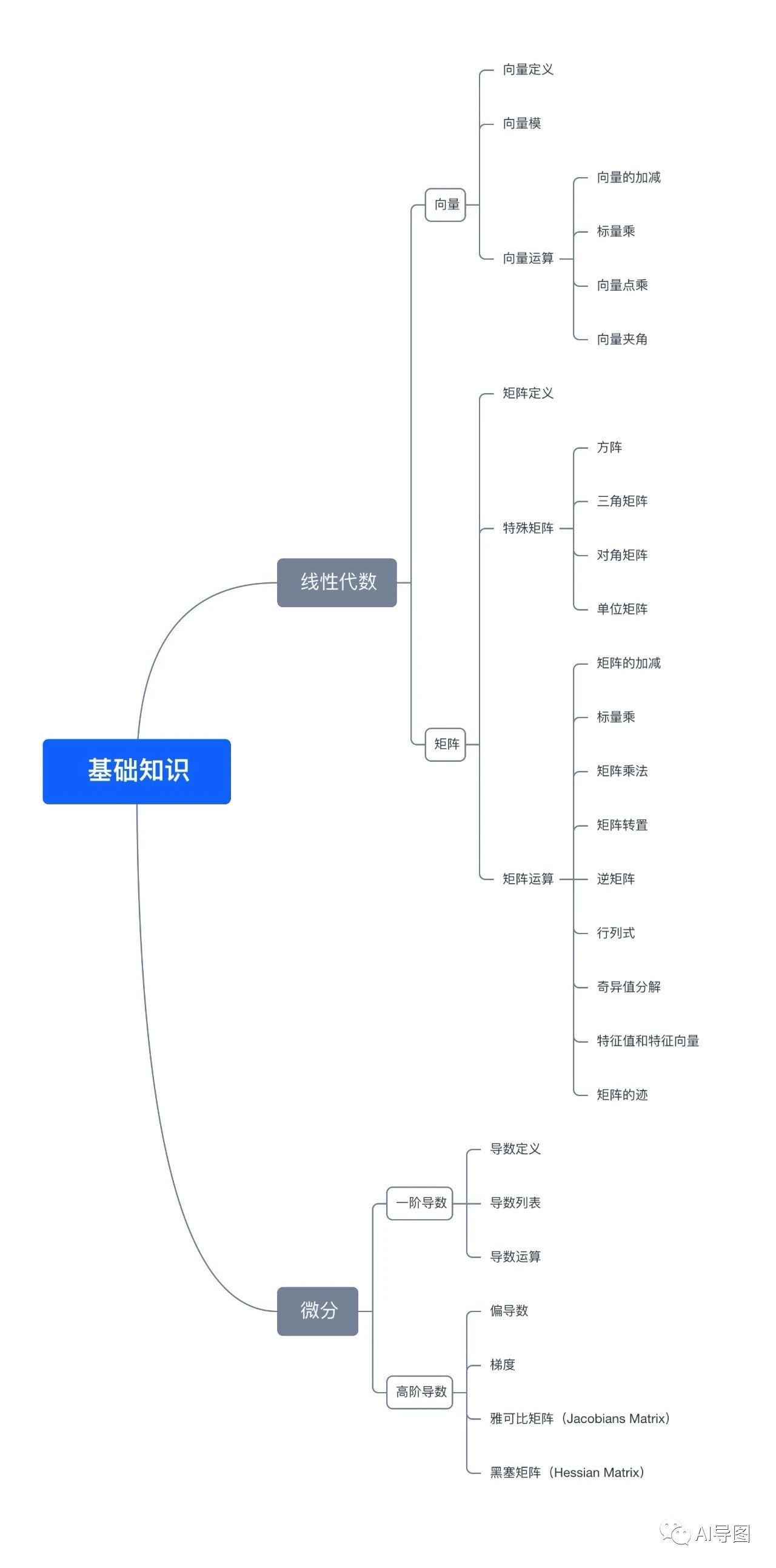
五、思维导图
六、参考资料
- https://zh.wikipedia.org/wiki/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0
- http://ocw.sjtu.edu.cn/G2S/OCW/cn/CourseDetails.htm?Id=397
- https://zh.wikipedia.org/wiki/%E5%AF%BC%E6%95%B0
完整演示请点击这里
注:本文力求准确并通俗易懂,但由于笔者也是初学者,水平有限,如文中存在错误或遗漏之处,恳请读者通过留言的方式批评指正
本文首发于微信公众号——AI导图,欢迎关注!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)