神经网络(Neural Network)
学习具体的神经网络类型之前首先要了解的内容
人工神经网络(Artificial Neural Network,ANN)是指一系列受生物学和神经科学启发的数学模型.这些模型主要是通过对人脑的神经元网络进行抽象, 构建人工神经元,并按照一定拓扑结构来建立人工神经元之间的连接,来模拟生物神经网络.在人工智能领域,人工神经网络也常常简称为神经网络(Neural Network,NN)或神经模型(NeuralModel).
在本章中,我们主要关注采用误差反向传播来进行学习的神经网络,即作为一种机器学习模型的神经网络. 从机器学习的角度来看,神经网络一般可以看作一个非线性模型,其基本组成单元为具有非线性激活函数的神经元,通过大量神经元之间的连接,使得神经网络成为一种高度非线性的模型.神经元之间的连接权重就是需要学习的参数,可以在机器学习的框架下通过梯度下降方法来进行学习。
神经元
人工神经元(ArtificialNeuron),简称神经元(Neuron),是构成神经网络的基本单元,其主要是模拟生物神经元的结构和特性,接收一组输入信号并产生输出。
假设一个神经元接收𝐷个输入,
,⋯,
,令向量𝒙=[
;
;⋯;
]来 表示这组输入, 并用净输入(NetInput)𝑧 ∈ ℝ表示一个神经元所获得的输入信号𝒙的加权和,
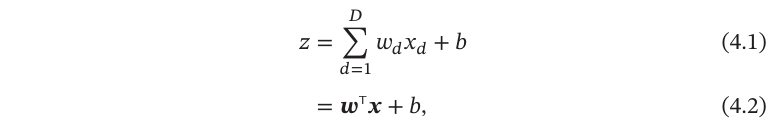
其中𝒘=[𝑤1;𝑤2;⋯;𝑤𝐷] ∈ 是𝐷维的权重向量,𝑏∈ℝ是偏置.
净输入𝑧在经过一个非线性函数𝑓(⋅)后,得到神经元的活性值(Activation),
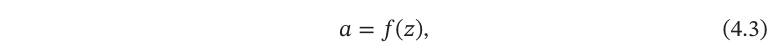
其中非线性函数𝑓(⋅)称为激活函数(ActivationFunction).
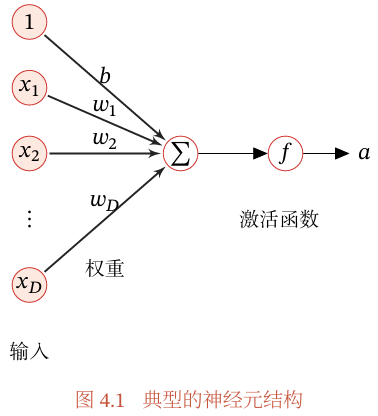
图4.1给出了一个典型的神经元结构示例.
1 激活函数
激活函数在神经元中非常重要.为增强网络的表示能力和学习能力,激活函数需要具备以下性质:
1) 连续并可导(允许少数点上不可导)的非线性函数.可导的激活函数可以直接利用数值优化的方法来学习网络参数.
2) 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率.
3) 激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性.
下面介绍几种在神经网络中常用的激活函数.
1.1 Sigmoid型函数
Sigmoid型函数是指一类S型曲线函数,为两端饱和函数.常用的Sigmoid 型函数有Logistic函数和Tanh函数。
饱和
对于函数𝑓(𝑥),若𝑥 →
时,其导数𝑓′(𝑥) → 0,则称其为左饱和.若𝑥 →
时,其导数𝑓′(𝑥) → 0,则称其为右饱和.当同时满足左、右饱和时,就称为两端饱和.
Logistic函数
定义为:
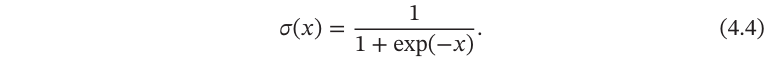
Logistic函数可以看成是一个“挤压”函数,把一个实数域的输入“挤压”到 (0, 1).当输入值在0附近时,Sigmoid型函数近似为线性函数;当输入值靠近两端时,对输入进行抑制.输入越小,越接近于0;输入越大,越接近于1.这样的特点 也和生物神经元类似,对一些输入会产生兴奋(输出为1),对另一些输入产生抑制(输出为0).和感知器使用的阶跃激活函数相比,Logistic函数是连续可导的,其数学性质更好.
因为Logistic函数的性质,使得装备了Logistic激活函数的神经元具有以下两点性质:
1)其输出直接可以看作概率分布,使得神经网络可以更好地和统计学习模型进行结合.
2)其可以看作一个软性门(SoftGate),用来控制其他神经元输出信息的数量.
“软性门”通常指的是一种在神经网络中用来控制信息流动的机制,其输出是连续的、介于0和1之间的值,而不是像“硬门”那样只有0或1的离散状态。这种机制常见于循环神经网络(RNN)的门控单元,如长短期记忆网络(LSTM)和门控循环单元(GRU)。
Tanh函数
定义为:
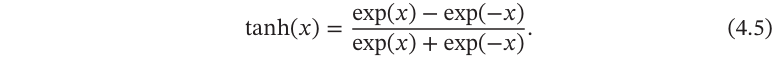
Tanh函数可以看作放大并平移的Logistic函数,其值域是(−1,1).
![]()
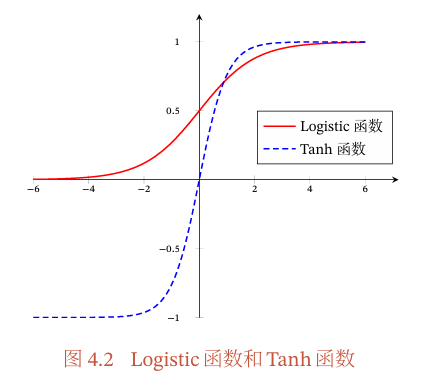
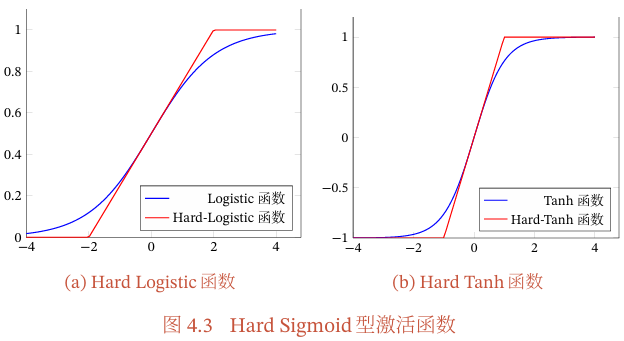
图4.2给出了Logistic函数和Tanh函数的形状.Tanh函数的输出是零中心化的(Zero-Centered),而Logistic函数的输出恒大于0.非零中心化的输出会使得其后一层的神经元的输入发生偏置偏移(BiasShift),并进一步使得梯度下降的收敛速度变慢.
Hard-Logistic函数和Hard-Tanh函数
Logistic函数和Tanh函数都是Sigmoid型函数,具有饱和性,但是计算开销较大.因为这两个函数都是在中间(0附近)近似线性,两端饱和.因此,这两个函数可以通过分段函数来近似.
以Logistic函数𝜎(𝑥)为例,其导数为𝜎′(𝑥) = 𝜎(𝑥)(1−𝜎(𝑥)).Logistic函数在0附近的一阶泰勒展开(Taylorexpansion)为
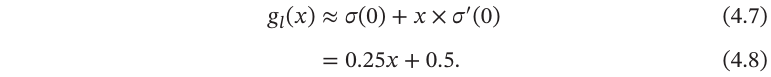
这样Logistic函数可以用分段函数hard-logistic(𝑥)来近似.
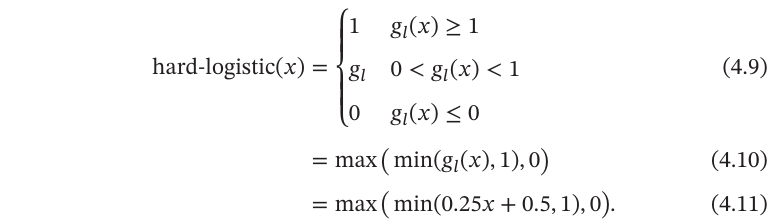
同样,Tanh函数在0附近的一阶泰勒展开为
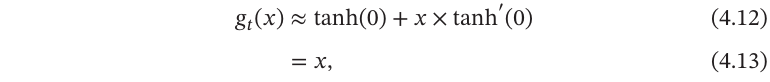
这样Tanh函数也可以用分段函数hard-tanh(𝑥)来近似.
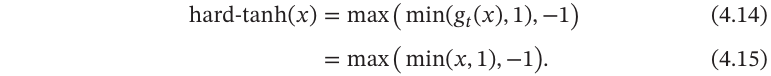
图4.3给出了Hard-Logistic函数和Hard-Tanh函数的形状.
1.2 ReLU函数
ReLU(Rectified Linear Unit,修正线性单元),也叫Rectifier函数,是目前深度神经网络中经常使用的激活函数.ReLU实际上是一个斜坡(ramp)函数,定义为
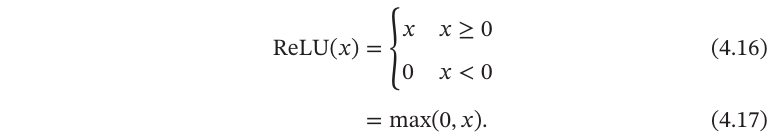
优点:采用ReLU的神经元只需要进行加、乘和比较的操作,计算上更加高效. ReLU函数也被认为具有生物学合理性(Biological Plausibility),比如单侧抑制、宽兴奋边界(即兴奋程度可以非常高).在生物神经网络中,同时处于兴奋状态的神经元非常稀疏.人脑中在同一时刻大概只有1%∼4%的神经元处于活跃状态.Sigmoid型激活函数会导致一个非稀疏的神经网络,而ReLU却具有很好的稀疏性,大约50%的神经元会处于激活状态. 在优化方面,相比于Sigmoid型函数的两端饱和,ReLU函数为左饱和函数, 且在𝑥 >0时导数为1,在一定程度上缓解了神经网络的梯度消失问题,加速梯度下降的收敛速度.
缺点:ReLU函数的输出是非零中心化的,给后一层的神经网络引入偏置偏移,会影响梯度下降的效率. 此外,ReLU神经元(指采用 ReLU作为激活函数的神经元)在训练时比较容易“死亡”.在训练时,如果参数在一次不恰当的更新后,第一个隐藏层中的某个ReLU神经元在所有的训练数据上都不能被激活,那么这个神经元自身参数的梯度永远都会是 0, 在以后的训练过程中永远不能被激活.这种现象称为死亡ReLU问题(Dying ReLUProblem),并且也有可能会发生在其他隐藏层. 在实际使用中,为了避免上述情况,有几种ReLU的变种也会被广泛使用.
带泄露的ReLU
带泄露的ReLU(LeakyReLU)在输入𝑥<0时,保持一个很小的梯度𝛾.这样当神经元非激活时也能有一个非零的梯度可以更新参数,避免永远不能被激活.带泄露的ReLU的定义如下:
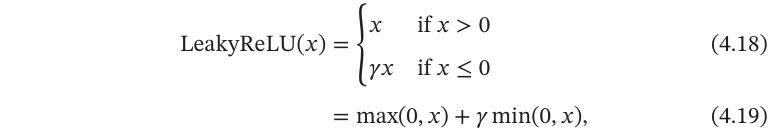
其中𝛾是一个很小的常数,比如0.01.当𝛾<1时,带泄露的ReLU也可以写为
![]()
相当于是一个比较简单的maxout单元.
带参数的ReLU
带参数的ReLU(Parametric ReLU,PReLU)引入一个可学习的参数,不同神经元可以有不同的参数.对于第𝑖个神经元,其PReLU的定义为
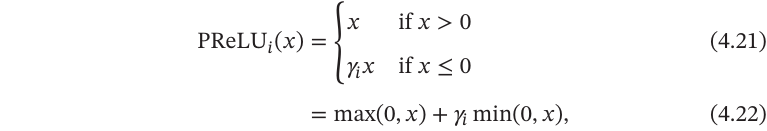
其中𝛾𝑖为𝑥 ≤ 0时函数的斜率.因此,PReLU是非饱和函数.如果𝛾𝑖 = 0,那么PReLU就退化为ReLU.如果𝛾𝑖为一个很小的常数,则PReLU可以看作带泄露的ReLU.PReLU可以允许不同神经元具有不同的参数,也可以一组神经元共享一个参数.
ELU函数
ELU(Exponential Linear Unit,指数线性单元)是一 个近似的零中心化的非线性函数,其定义为
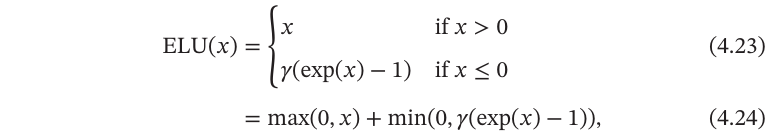
其中𝛾≥0是一个超参数,决定𝑥≤0时的饱和曲线,并调整输出均值在0附近.
Softplus函数
Softplus 函数可以看作Rectifier函数的平滑版本,其定义为
![]()
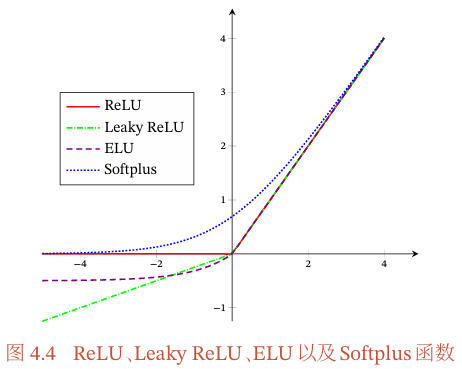
Softplus函数其导数刚好是Logistic函数.Softplus函数虽然也具有单侧抑制、宽兴奋边界的特性,却没有稀疏激活性.图4.4给出了ReLU、LeakyReLU、ELU以及Softplus函数的示例.
1.3 Swish函数
Swish函数是一种自门控(Self-Gated)激活函数,定义为
![]()
其中𝜎(⋅)为Logistic函数,𝛽为可学习的参数或一个固定超参数.𝜎(⋅) ∈ (0,1)可 以看作一种软性的门控机制.当𝜎(𝛽𝑥)接近于1时,门处于“开”状态,激活函数的输出近似于𝑥本身;当𝜎(𝛽𝑥)接近于0时,门的状态为“关”,激活函数的输出近似于0.
图4.5给出了Swish函数的示例.
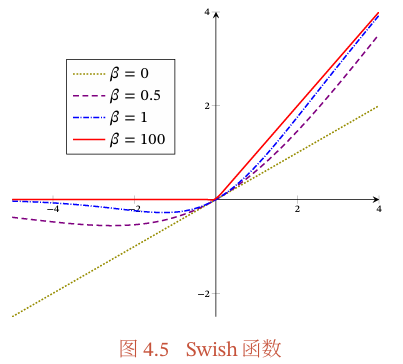
当𝛽=0时,Swish函数变成线性函数𝑥/2.当𝛽=1时,Swish函数在𝑥 > 0时近似线性,在𝑥 < 0时近似饱和,同时具有一定的非单调性.当𝛽 → +∞时,𝜎(𝛽𝑥)趋向于离散的0-1函数,Swish函数近似为ReLU函数.因此,Swish函数可以看作线性函数和ReLU函数之间的非线性插值函数,其程度由参数𝛽控制.
1.4 GELU函数
GELU(GaussianErrorLinearUnit,高斯误差线性单元)也是一种通过门控机制来调整其输出值的激活函数,和Swish函数比较类似.
![]()
其中𝑃(𝑋 ≤𝑥)是高斯分布𝒩(𝜇,𝜎2)的累积分布函数,其中𝜇,𝜎为超参数,一般设𝜇=0,𝜎=1即可.由于高斯分布的累积分布函数为S型函数,因此GELU函数可以用Tanh函数或Logistic函数来近似,
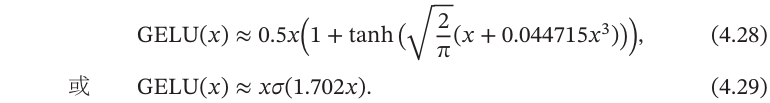
当使用Logistic函数来近似时,GELU相当于一种特殊的Swish函数.
1.5 Maxout单元
Maxout单元也是一种分段线性函数.Sigmoid型函数、ReLU等激活函数的输入是神经元的净输入𝑧,是一个标量.而Maxout单元的输入是上一层神经元的全部原始输出,是一个向量𝒙=[;
;⋯;
]. 每个Maxout单元有𝐾个权重向量
和偏置
(1≤𝑘≤𝐾).对于输 入𝒙,可以得到𝐾个净输入
,1≤𝑘≤𝐾.
![]()
其中为第𝑘个权重向量.
Maxout单元的非线性函数定义为
![]() Maxout单元不单是净输入到输出之间的非线性映射,也是整体学习输入到输出之间的非线性映射关系.Maxout激活函数可以看作任意凸函数的分段线性近似,并且在有限的点上是不可微的.
Maxout单元不单是净输入到输出之间的非线性映射,也是整体学习输入到输出之间的非线性映射关系.Maxout激活函数可以看作任意凸函数的分段线性近似,并且在有限的点上是不可微的.
2 网络结构
要想模拟人脑的能力,单一的神经元远远不够,需要通过很多神经元一起协作来完成复杂的功能.通过一定的连接方式或信息传递方式进行协作的神经元可以看作一个网络,就是神经网络. 到目前为止,研究者已经发明了各种各样的神经网络结构.目前常用的神经网络结构有以下三种:
2.1 前馈网络
前馈网络中各个神经元按接收信息的先后分为不同的组.每一组可以看作一个神经层.每一层中的神经元接收前一层神经元的输出,并输出到下一层神经元.整个网络中的信息是朝一个方向传播,没有反向的信息传播,可以用一个有向无环路图表示.前馈网络包括全连接前馈网络和卷积神经网络等.前馈网络可以看作一个函数,通过简单非线性函数的多次复合,实现输入空间到输出空间的复杂映射.这种网络结构简单,易于实现.
2.2 记忆网络
记忆网络,也称为反馈网络,网络中的神经元不但可以接收其他神经元的信息,也可以接收自己的历史信息.和前馈网络相比,记忆网络中的神经元具有记忆功能,在不同的时刻具有不同的状态.记忆神经网络中的信息传播可以是单向或双向传递,因此可用一个有向循环图或无向图来表示.记忆网络包括循环神经网络、Hopfield网络、玻尔兹曼机、受限玻尔兹曼机等.
记忆网络可以看作一个程序,具有更强的计算和记忆能力.为了增强记忆网络的记忆容量,可以引入外部记忆单元和读写机制,用来保存一些网络的中间状态,称为记忆增强神经网络(MemoryAugmentedNeural Network,MANN),比如神经图灵机和记忆网络等.
2.3 图网络
前馈网络和记忆网络的输入都可以表示为向量或向量序列.但实际应用中 很多数据是图结构的数据,比如知识图谱、社交网络、分子(Molecular)网络等.前馈网络和记忆网络很难处理图结构的数据.
图网络是定义在图结构数据上的神经网络.图中每个节点都由一个或一组神经元构成.节点之间的连接可以是有向的,也可以是无向的.每个节点可以收到来自相邻节点或自身的信息. 图网络是前馈网络和记忆网络的泛化,包含很多不同的实现方式,比如图卷积网络(GraphConvolutional Network,GCN)、图注意力网络(GraphAttention Network,GAT)、消息传递神经网络(MessagePassing Neural Network,MPNN)等.
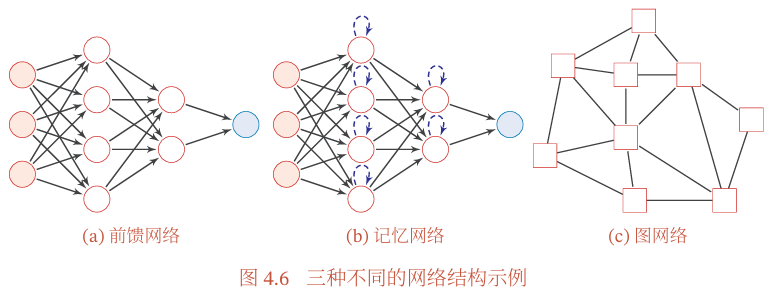
图4.6给出了前馈网络、记忆网络和图网络的网络结构示例,其中圆形节点表示一个神经元,方形节点表示一组神经元.
前馈神经网络在下面链接
卷积神经网络在下面链接
循环神经网络在下面链接

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)