命名实体识别(NER)任务的几种处理思路(自然语言处理项目感悟)
今天和华泰总部的陈姓算法总监聊天,聊到了当前较为实用的处理NER任务的算法方案;今天借着这个机会和大家简单交流下,有心的小伙伴拿好小本子,要开始记笔记了!!!我们算法组陆陆续续做了HTZQ的81个大类的序列标注任务,个人这边做了接近30个类别的NER任务,属实是试验了多种多样的NER方案,感受颇多。接下来我这边针对金融领域上市公司的公告数据中的实体识别任务,进行简单总结:1、金融领域数据特点:数据
·
今天和华泰总部的陈姓算法总监聊天,聊到了当前较为实用的处理NER任务的算法方案;今天借着这个机会和大家简单交流下,有心的小伙伴拿好小本子,要开始记笔记了!!!

我们算法组陆陆续续做了HTZQ的81个大类的序列标注任务,个人这边做了接近30个类别的NER任务,属实是试验了多种多样的NER方案,感受颇多。接下来我这边针对金融领域上市公司的公告数据中的实体识别任务,进行简单总结:
1、金融领域数据特点:
- 数据稀缺,金融领域的数据稀缺程度超出了我的想象,在我亲自操刀处理的近30个类别中,数据较为充盈的训练集+验证集+测试集全部数据也就300-400条,例如:股份转让、借款类的关联交易等;而更多的是数据稀缺的类别,例如:申请破产清算和法院受理破产清算等,全量数据仅50-60条;
- 数据标注质量参差不齐,其实这个问题也可以理解,一共就这么点数据,还没标顺手呢,就结束了…,还有一个问题就是各个类别之间要素标注差异较大,很难确定一个一锤定音的标准。
2、个人尝试NER方案包括:
- LSTM + CRF
- BERT + CRF
- LAC(分词 + NER) + textcnn 分类(字模型、词模型)
- 规则(文本 + 表格)
3、各方案效果介绍
在起初尝试的相关类别数据上,数据量408条:
- LSTM + CRF :召回率不足70%;
- BERT + CRF:召回率不足72%;
- LAC(分词 + NER) + textcnn 分类(字模型):召回率接近76%;
- LAC(分词 + NER) + textcnn 分类(词模型):召回率超过80%;
4、各分项准召率数据展示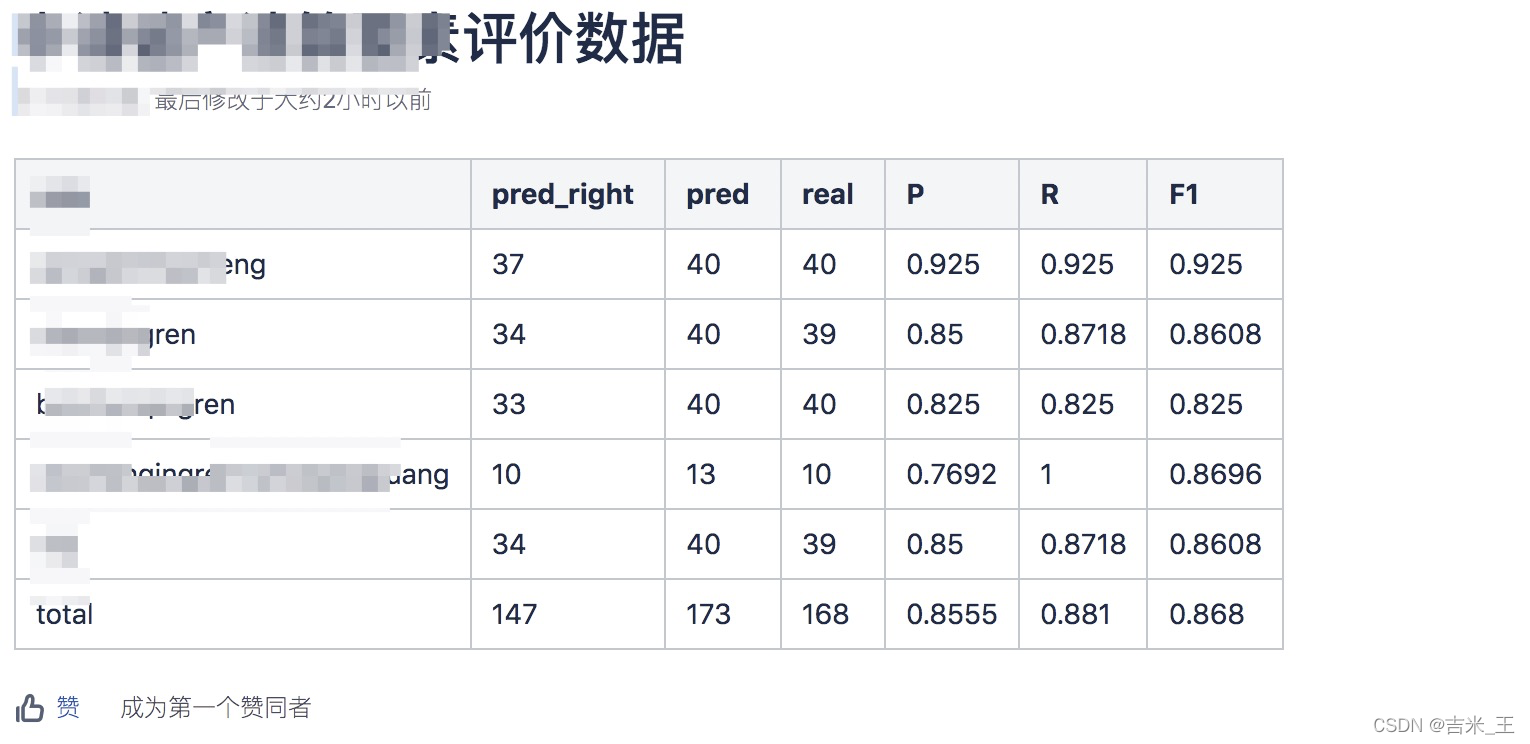

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)