阿里云PAI自定义算法的使用教程
阿里云PAI是一个一站式的算法平台,上面集成了部分常用的机器学习算法,如GBDT二分类、逻辑回归等算法进行了封装,在使用时只需要拖拽相关组件即可,在PAI中不仅仅集成一些机器学习算法,而且集成了机器学习中的数据预处理、特征工程、模型评估等相关方法的组件,这些组件根据解决的问题类型进行了分类,如果对PySpark的熟悉的同学,应该一眼可以看出阿里云PAI的封装组件其实就是目前PySpark.ML支持的一些算法及功能,当然也不乏一些阿里云独立开发的功能,至于是否都好用还要一一验证: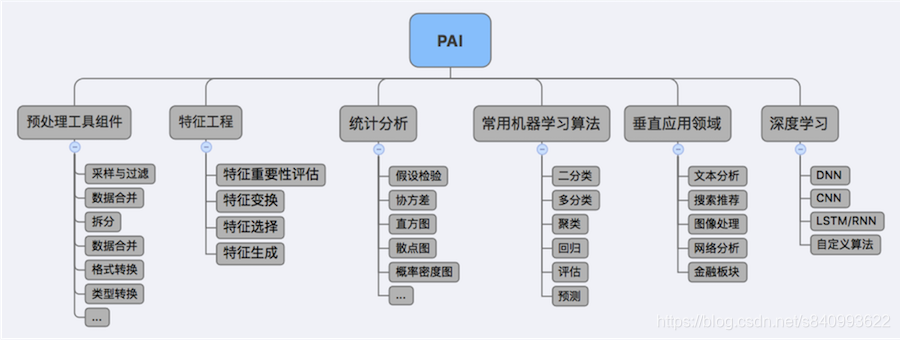
言归正传,阿里云PAI除了这些现有的封装好的机器学习组件,阿里云PAI也支持自定义算法的封装,下面我们就说一说阿里云PAI自定义算法的一些无料可查的问题:
1.阿里云PAI自定义算法本地测试:
阿里云官方也给出了本地的算法测试教程:算法本地调试说明
根据官方给出的教程基本能够完成整个流程的测试,但是也有一些需要注意的地方:
1.1 JDK、Scala、Python
JDK版本:1.7+,1.8+最佳
Scala版本:2.11
Python版本:Python2.7,支持Pyspark
1.2 客户端配置
需要注意的有两点,在本地测试时需要配置:
spark.sql.catalogImplementation=odps
spark.master=local[4]
1.3 测试
按照官方教程基本无大问题,说一下提交代码的命令行:
cd $SPARK_HOME
./bin/spark-submit --driver-class-path cupid/odps-spark-datasource_2.11-3.3.8.jar --py-files python/lib/pyspark.zip,python/lib/py4j-0.10.6-src.zip ~/Desktop/a.py(文件a.py的路径) inputTable1=输入表名 outputTable1=输出表名 idCol=id列名 contentCol=内容列名
上面的两条命令是官方给出的算法本地提交测试的命令,解析一下这个命令,其实很容易看懂的,其中py4j-0.10.6-src.zip是python和Java的一个解析包,支持python和java之间的调用。
同时还需注意,在代码执行时,需要在代码中定义main入口
1.4 算法环境:
阿里云PAI自定义算法支持三种算法框架:SQL、SPARK、PYSPARK
2.阿里云PAI自定义算法上传:
2.1 打包
在本地将测试完成的代码进行打包上传,以pyspark为例,将文件打包为.zip文件,在文件打包时要注意:无需单独命名文件夹保存后打包,直接将所有相关代码文件打包即可
2.2 上传

要特别注意入口文件与入口函数的部分,此步骤出错会在最终完成配置,而后代码执行过程中报错,所以此步骤出错会导致后续大量工作白费
2.3 配置
版本号自定义即可
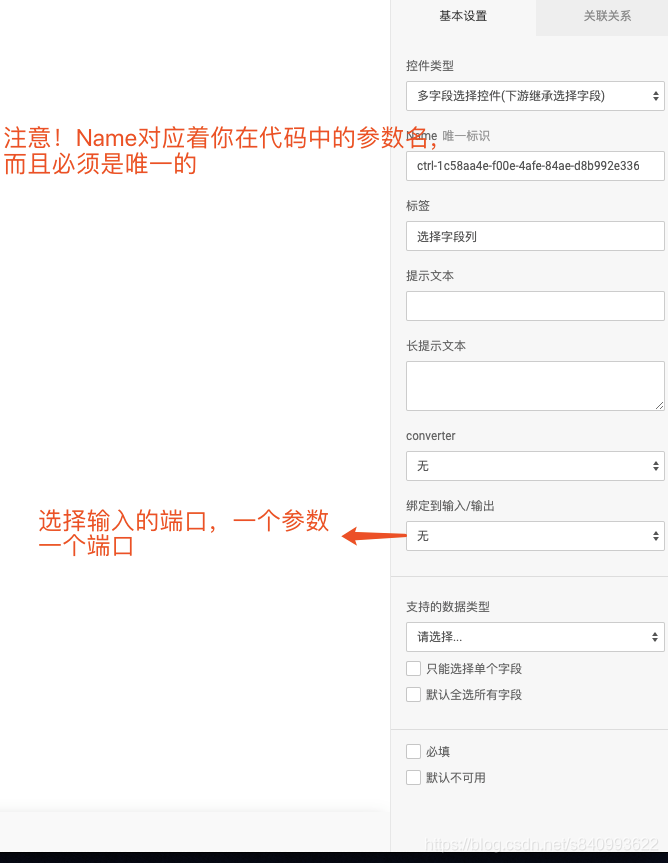
需要注意的是在PAI中如果需要调整Spark的相关配置,比如memory、cores、timeout等参数需要在参数配置页进行配置,在代码中配置无效,参数配置页即上述界面,如下图: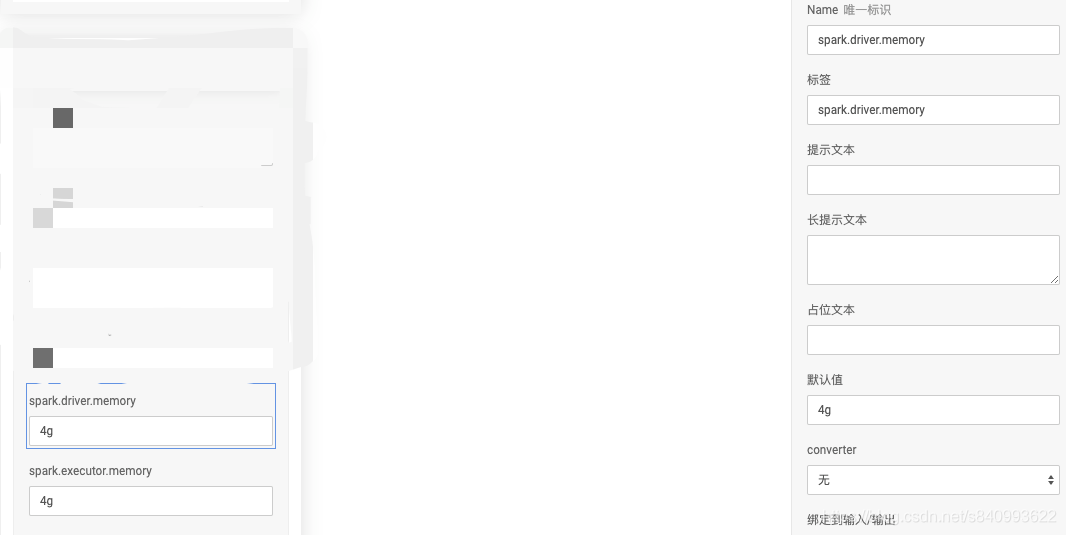
还有注意的是:阿里云PAI中的默认设置与spark的官方默认设置是一致的,而且官方并未就这一配置进行说明,PAI的执行环境及相关配置,只字未提,如果不知其中的官方配置,可参考Spark的官方配置
如若需要对其中相关的参数进行调整,则需要在算法组件上添加相应的控件,切记在代码中添加是无效的。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)