机器学习---继k-means算法的meanshift聚类算法
k-means算法和meanshift算法都是机器学习中的无监督式学习,k-means算法的不足点是需要给定中心簇点点个数k,meanshift算法不要给定中心簇点个数(属于无参数的算法)。k-means算法是基于与中心簇点的距离来归类的,meanshift是根据当前点的偏移均值向密度高的方向偏移,所以meanshift也叫均值漂移算法。Meanshift算法是一个迭代的过程,是先算出以h为半径的
k-means算法和meanshift算法都是机器学习中的无监督式学习,k-means算法的不足点是需要给定中心簇点点个数k,meanshift算法不要给定中心簇点个数(属于无参数的算法)。k-means算法是基于与中心簇点的距离来归类的,meanshift是根据当前点的偏移均值向密度高的方向偏移,所以meanshift也叫均值漂移算法。
Meanshift算法理论:
1.Meanshift向量
对于n个样本点,对于x点,meanshift的向量基本形式:
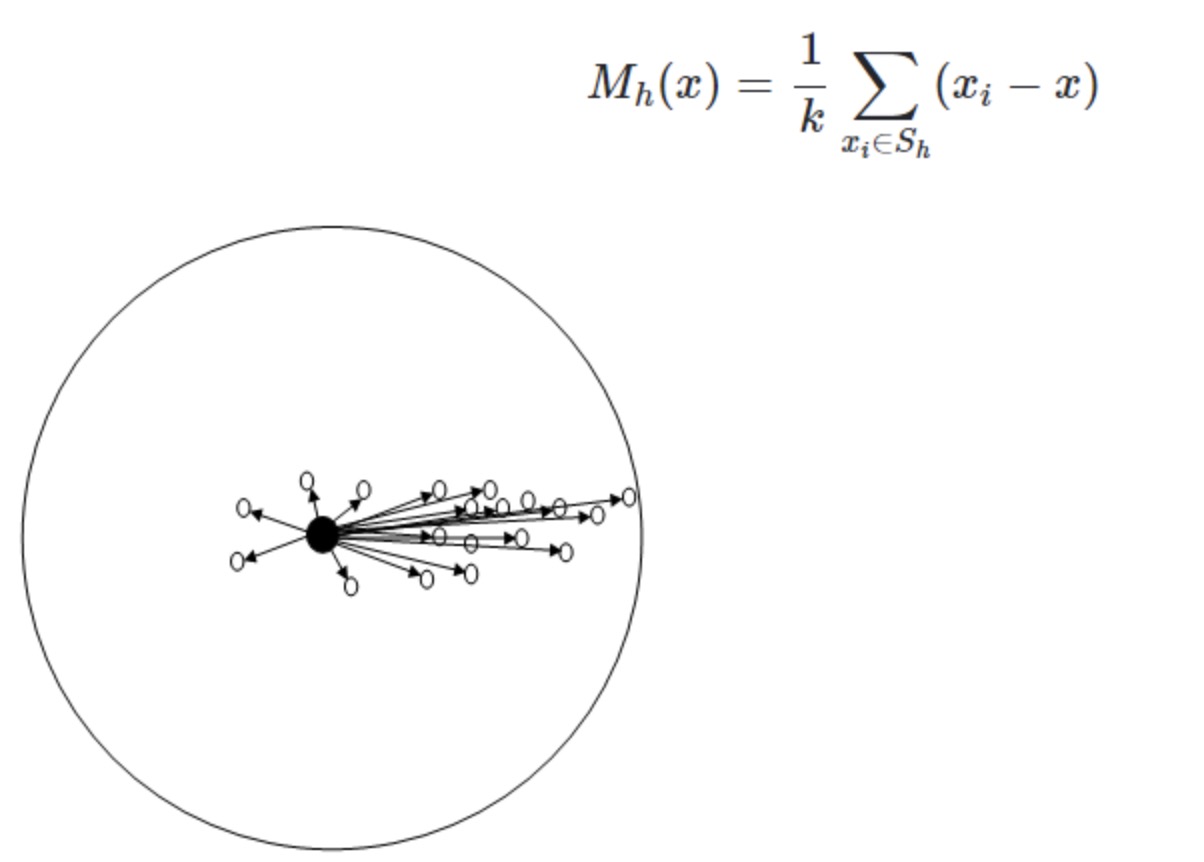
其中,S是指一个半径为h的高维球。M
是指以圆心为中心,h为半径,所有点与圆心为起点形成的向量相加的结果。
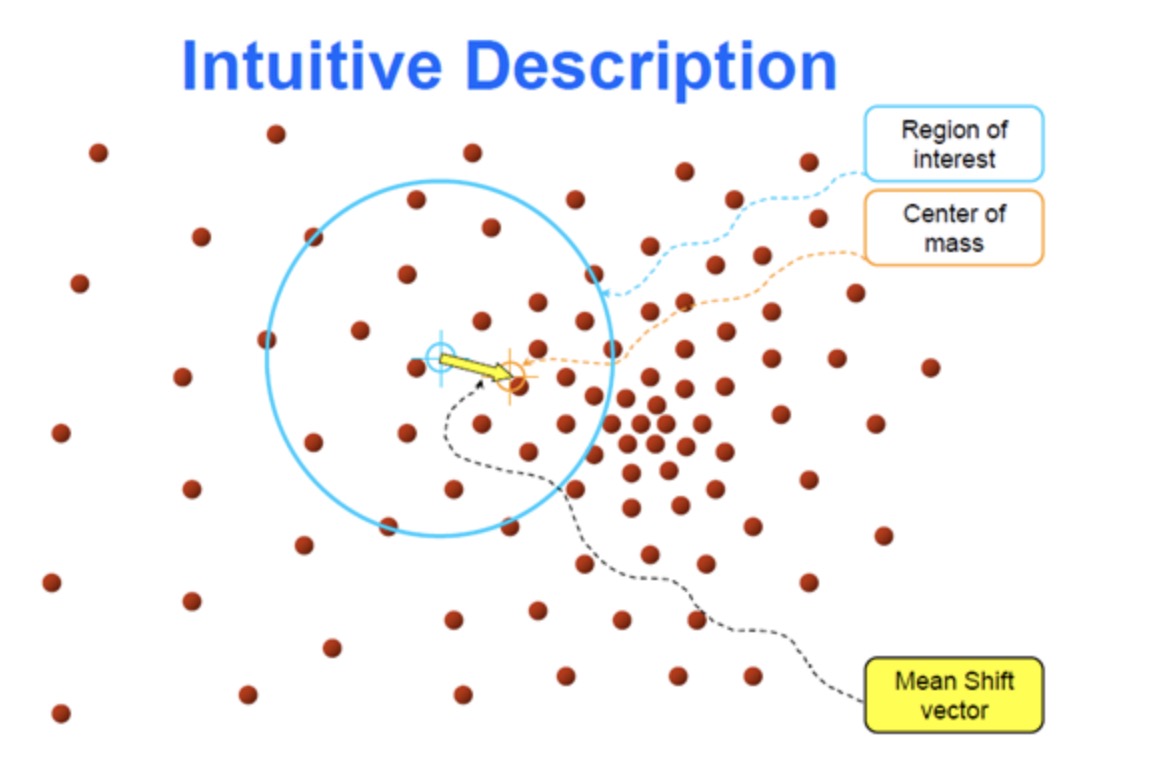
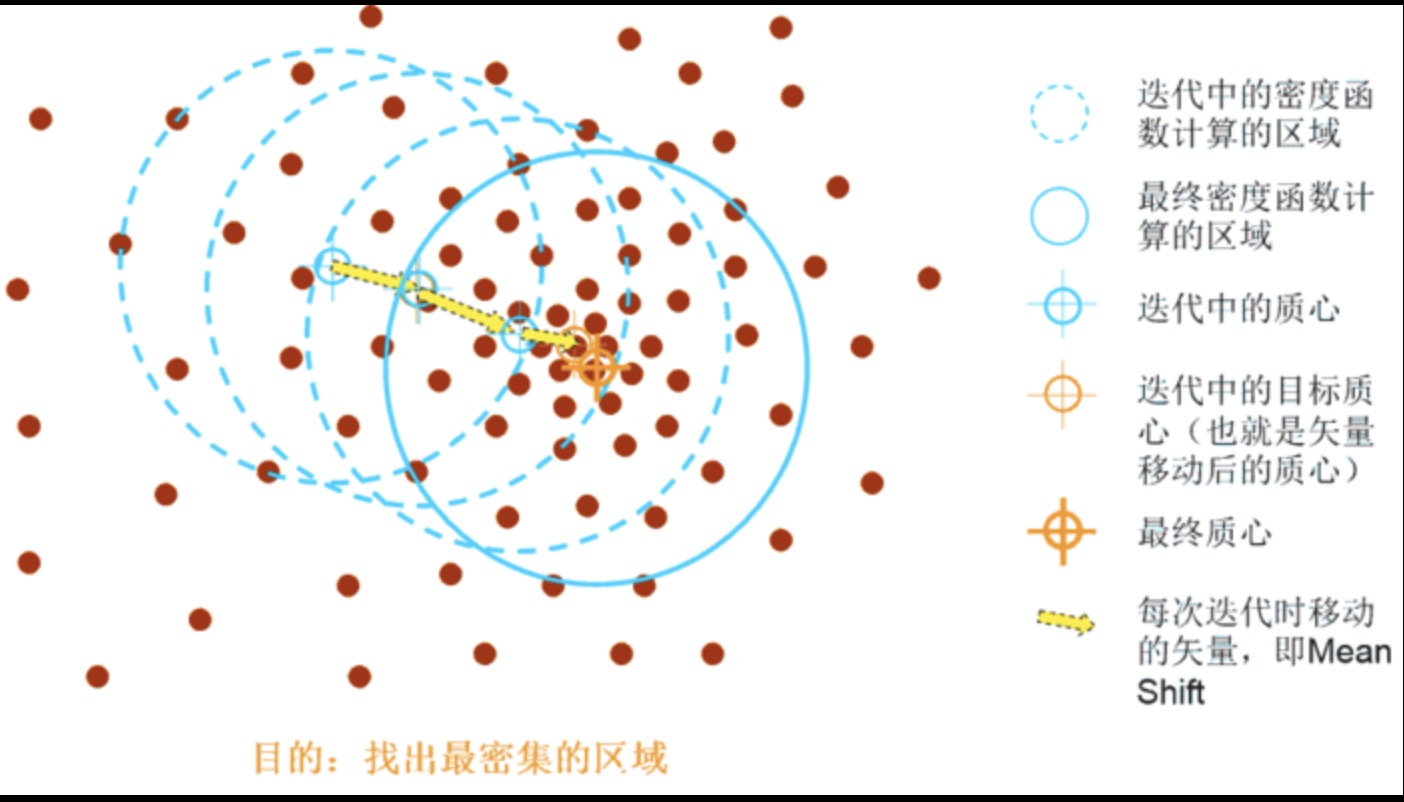
Meanshift算法是一个迭代的过程,是先算出以h为半径的高维圆的中心C的偏移均值d,然后将该中心C按照偏移均值d移动。再次以移动后的中心C1为起点计算出新的偏移均值d1,然后中心C1按照偏移均值d1进行移动,一直移动到满足最终条件,找出最密集的区域。
Meanshift实战:
1.创建数据集
2.使用meanshift机器学习并预测
3.矫正预测的数据
4.原始图和预测图画图
1.创建数据集
from sklearn.datasets import make_blobs import csv (x,y) = make_blobs(n_samples=500,centers=3) print(x,y) print(type(x)) print(type(y)) df = pandas.DataFrame({'v1':x[:,0], 'v2':x[:,1], 'result':y}) df.to_csv('/Users/zc/Desktop/v1-v2.csv',index=False)
2.使用meanshift机器学习并预测
from sklearn.metrics import accuracy_score from sklearn.cluster import MeanShift,estimate_bandwidth import pandas import nump csv_data = pandas.read_csv('/Users/zc/Desktop/v1-v2.csv') print(csv_data) x = csv_data.drop(['result'],axis=1) print(x) x1 = x.loc[:,'v1'] x2 = x.loc[:,'v2'] y = csv_data.loc[:,'result'] bw =estimate_bandwidth(x,n_samples=500) print(bw) ms = MeanShift(bandwidth=bw) ms.fit(x) y_predict_ms = ms.predict(x)
3.矫正预测的数据
y_predict_correct = []
for i in y_predict_ms:
if i == 0:
y_predict_correct.append(1)
elif i == 1:
y_predict_correct.append(0)
else:
y_predict_correct.append(2)
pd_y_predict = numpy.array(y_predict_correct)
print("accuarry_score:" + '\n' ,accuracy_score(y,pd_y_predict))
print(pandas.Series.value_counts(y),pandas.Series.value_counts(pd_y_predict))
4.原始图和预测图画图
from matplotlib import pyplot as plt
fig_1 = plt.subplot(121)
label0 = plt.scatter(x1[y==0],x2[y==0])
label1 = plt.scatter(x1[y==1],x2[y==1])
label2 = plt.scatter(x1[y==2],x2[y==2])
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.xlabel('x-v1')
plt.xlim(-10,10)
plt.ylabel('y-v2')
plt.ylim(-10,10)
plt.title('unlabel data')
fig_2 = plt.subplot(122)
label0 = plt.scatter(x1[pd_y_predict==0],x2[pd_y_predict==0])
label1 = plt.scatter(x1[pd_y_predict==1],x2[pd_y_predict==1])
label2 = plt.scatter(x1[pd_y_predict==2],x2[pd_y_predict==2])
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.xlabel('x-v1')
plt.xlim(-10,10)
plt.ylabel('y-v2')
plt.ylim(-10,10)
plt.title('predict data')
plt.show()
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)