hadoop classpath_Hadoop大数据入门(七)Spark
目录序言理论基础生态介绍安装和配置多节点部署交互SparkHBase目标单纯的hadoop,包括HDFS和MR等,可以解决一部分问题,但是还是有些麻烦。Spark的诞生是为了使得在某些场景下分布式数据的处理更便捷,效率更高。Hadoop和Spark不是两个对立或需要二选一的工具,而是两个相互补充,以完成更全面的工作的两个朋友。这一篇,我们会从安装部署Spark开始,介绍如何通过Spark做类似的数

目录
- 序言
- 理论基础
- 生态介绍
- 安装和配置
- 多节点部署
- 交互
- Spark
- HBase
目标
单纯的hadoop,包括HDFS和MR等,可以解决一部分问题,但是还是有些麻烦。
Spark的诞生是为了使得在某些场景下分布式数据的处理更便捷,效率更高。Hadoop和Spark不是两个对立或需要二选一的工具,而是两个相互补充,以完成更全面的工作的两个朋友。
这一篇,我们会从安装部署Spark开始,介绍如何通过Spark做类似的数据处理。
安装Spark
Spark的安装和部署思路和hadoop一样,把需要的文件下载,放在某一个地方,让系统能找到它,然后做一些配置,就可以启动。
Spark的包可以从http://spark.apache.org/downloads.html来下载,如下图的页面。
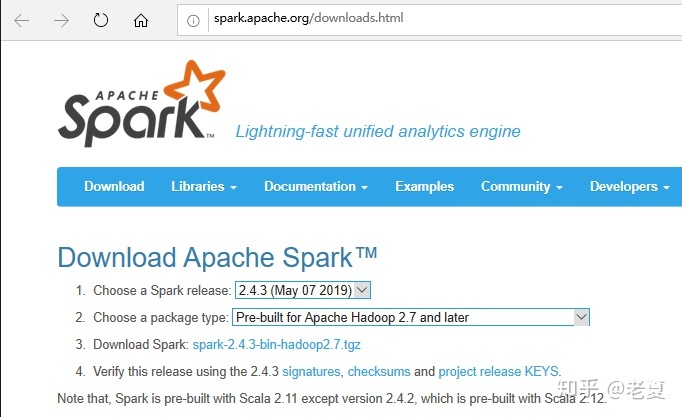
这里有两个下拉框,第一个是选当前可用的稳定版本,第二个是选不同的包类型,类为我们是基于hadoop进行安装和部署,所以选“Pre-built for Apache Hadoop 2.7 or later”。
然后点第三条的连接,把文件放在任何你愿意的位置,我把它放在我的hadoop根目录,也就是/home/admin/hadoop里面。
然后通过如下命令解压:
tar -zxf ~/hadoop/spark-2.4.3-bin-hadoop2.7.tgz -C ~/hadoop再通过如下命令修改目录名,这里我就把spark目录放到hadoop目录下了,但这个不是必须的,你可以把它放在任何期望的位置。
mv ~/hadoop/spark-2.4.3-bin-hadoop2.7 ~/hadoop/spark到这里我们已经“安装”完成了spark。把的根目录在我的hadoop根目录里面。接下来我们进行一些配置。
配置Spark
Spark的配置文件都在~/hadoop/spark/conf里面(根据实际情况确定目录)。我们主要修改三个文件。
- ~/.bashrc。这个文件我们前面已经修改过,主要是让系统能找到Hadoop,这里我们在最后再加两行,让系统可以找到spark。
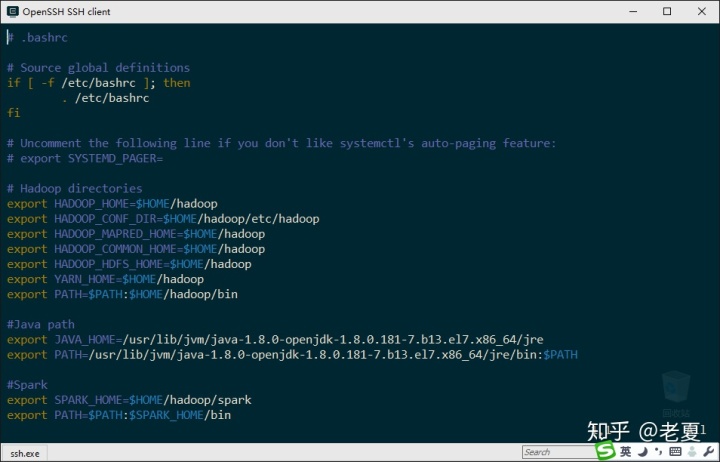
然后可以用如下命令使其生效:
source ~/.bashrc- spark-env.sh。目录里已经有了一个spark-env.sh.template文件,这是一个模板,里面有详细的说明,我们直接从template文件拷贝一份名字为spark-env.sh,然后在最后添加一行:
export SPARK_DIST_CLASSPATH=$(~/hadoop/bin/hadoop classpath)- slaves。同样如果有template文件,则拷贝一份新的,如果没有则新建。在里面写上所有DataNode节点的名字。比如我的是这样:
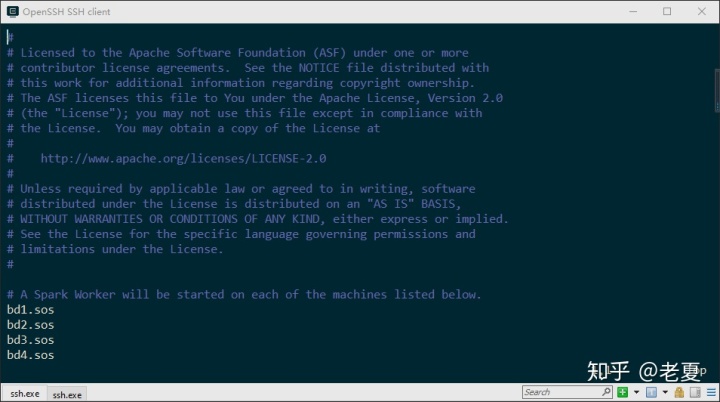
完成这两个配置文件后,Spark的配置就完成了。我们还需要把整个spark目录(我的是~/hadoop/spark目录)拷到所有的节点服务器上,位置相同。比如可以用命令:
scp ~/hadoop/spark admin@bd2.sos:/home/admin/hadoop启动Spark
配置完成,我们试着启动Spark:
~/hadoop/spark/sbin/start-all.sh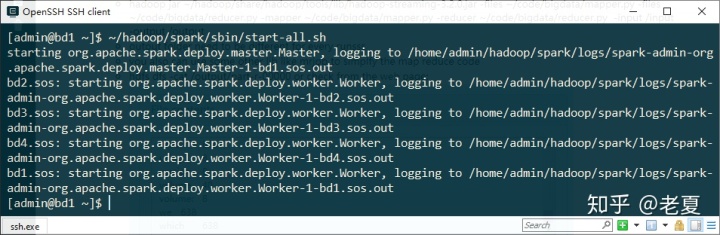
要停止Spark,可以用如下命令:
~/hadoop/spark/sbin/stop-all.sh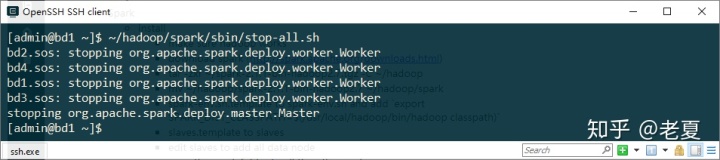
启动之后,我们可以通过网页看到Spark的状态:
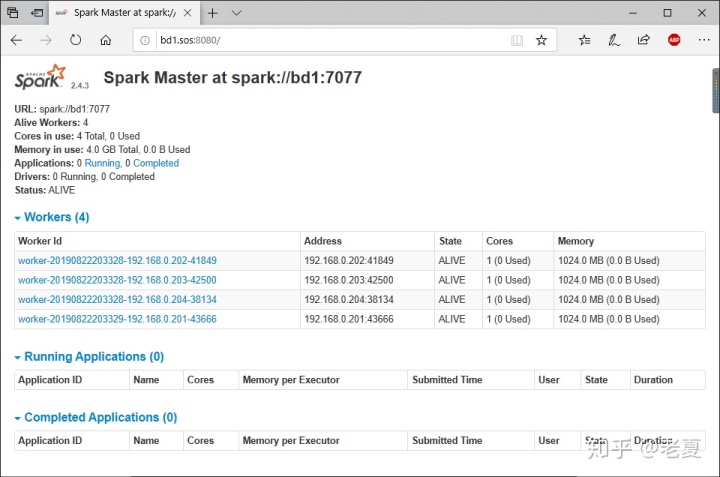
测试Spark
安装部署完成,也启动了,我们测试一下Spark是不是工作的。Spark自己带了示例程序,比如计算PI的值(去们先不管这看上去和分布式大数据处理有什么关系,但至少这可以让我们看到Spark是工作的)。
我们在命令行运行:
~/hadoop/spark/bin/run-example SparkPi 10会得到很多输出,但我们会看到计算出来的PI的结果(虽然不精确):
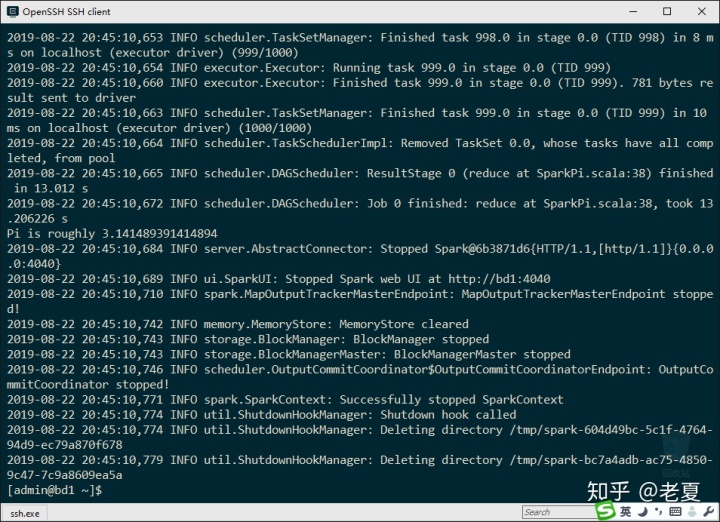
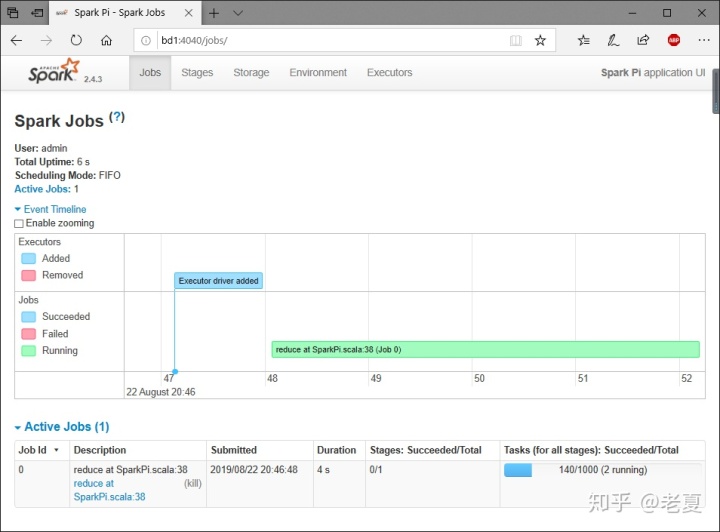
上图我们还可以看出,我们可以通过网页看到spark任务执行的状态,浏览器打开http://bd1:4040,其中bd1是我的服务器名,你需要替换成自己的。
但结果是:
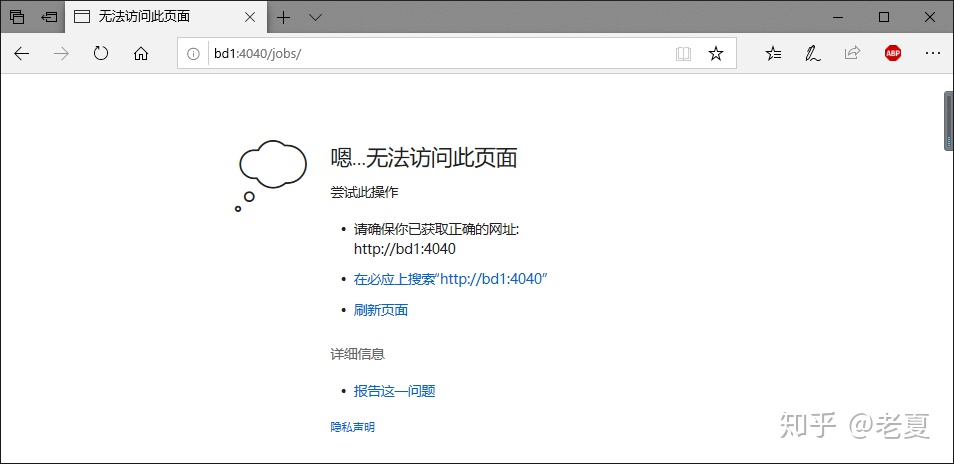
原因是,这个web服务只有在spark任务执行过程中才可以访问,而咱们这个任务实在太容易了,很快就结束了。计算PI的这个命令中的最后那个参数10是指的把整个任务分成几个子任务去执行,我们可以增大这个数来让整个任务执行得慢一些,这样就可以刷新出网页上的内容,比如:
Spark Shell
Spark是基于Scala实现的,它提供了一个Scala的实时解释器,就像Python那样。在里面我们可以通过直接运行一行行的Scala代码来操作Spark。
Scala的语法不在本篇的范围内,如果需要请自行搜索学习。
Spark Shell在Spark目录里的bin目录里,但我们已经将它加入到PATH中,所以可以直接在命令行启动它:
spark-shell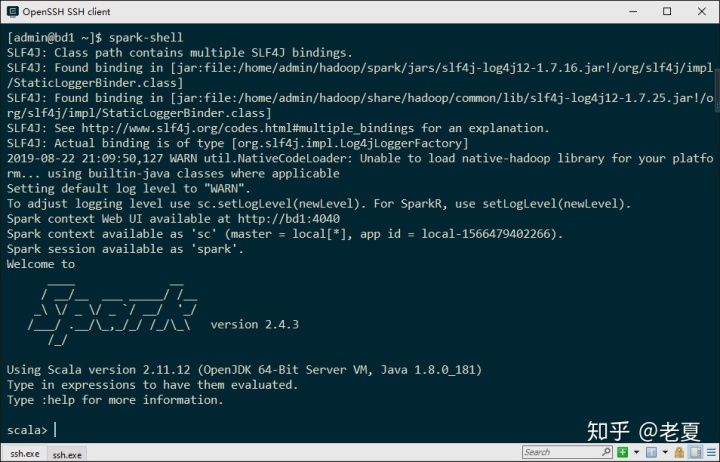
在使用Scala访问Spark时我们会遇到一个东西,RDD,这个东西开始总让人迷惑。它的全称是Resilient Distributed Dataset,翻译的话可以叫弹性分布式数据集合。它是Spark中的最基本的数据表示,也就是基本上在Spark里所有需要处理的数据都可以被变成RDD对象,而每个RDD对象都提供了一系列好用的方法。
我们可以通过两种方式创建RDD,一是读取一个文件,二是从现在的数据转换得到。我们用代码试一下。在Spark Shell里我们执行:
val rddFile= sc.textFile("hdfs:/input/big_random_strings.txt")这里的sc在Spark Shell刚启动的时候已经告诉我们,它是Spark Context,另外还有个叫spark的变量,它是Spark Session。
执行完这一行,Scala会打印出这个rddFile变量,如下图:

可见这个rddFile变量是个org.apache.spark.rdd.RDD[String]。
我们再执行:
val arr = Array("hello","this","is","an","array")
val rddFromArray = sc.parallelize(arr)得到:
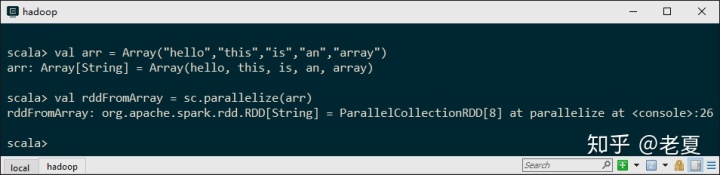
可见arr是个Array,rddFromArray是个RDD。
另外,在数据处理过程中,一个RDD会产生另一个RDD,而这些RDD可以写入HDFS也可以保存在内存中。
我们再做一些相关操作,以更好地理解RDD和我们可以对它做的事情:
rddFile.count()
val filterRDD = rddFile.filter(line => line.contains("abc"))
filterRDD.count()
rddFromArray.filter(v => v.contains("i")).count()
rddFile.first()
rddFile.take(8)结果如图:
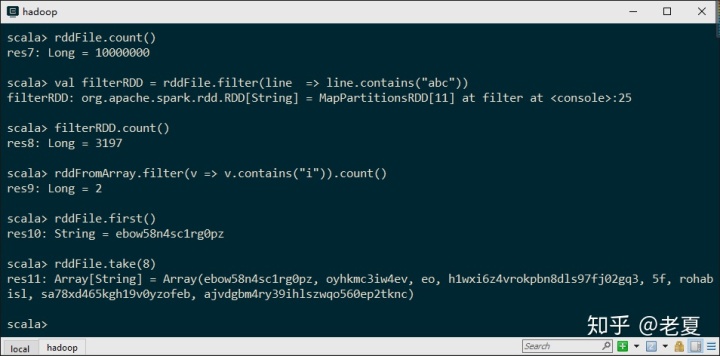
其中:
- count方法是计数。
- filter方法是过滤一个RDD,从而产生一个新的RDD。
- first方法获取一个RDD中的第一个元素。
- take方法从RDD中取得前几个元素。
另外还有几个方法:
rddFile其中:
- rddFile.partitions.length是取得这个RDD的partitions的长度,也就是个数。而partition是RDD的一个重要属性,可以理解为一个RDD被分成了几个部分,进而可以并行处理。对于从HDFS里读取的数据,默认partition的个数和这个文件的block个数一至。
- rddFile.cache()。这个操作会把这个RDD缓存在内存中,这是Spark一个很大的特点,当某些数据需要反复处理的时候,把它放在内存中的效率要远远大于每次都读写磁盘。但这个方法需要明确调用,否则Spark不帮我们缓存任何数据。
- rddFromArray.collect(),这个方法会把一个RDD中的数据以Array的形式返回。
另外,在运行Spark Shell的过程中,我们可以通过网页查看Spark的状态,因为这时候它的Web服务是启动着的。
Spark Shell版的Word Count
接下来我们看看在Spark Shell里怎么做前面做过Word Count练习。
其实太简单了……
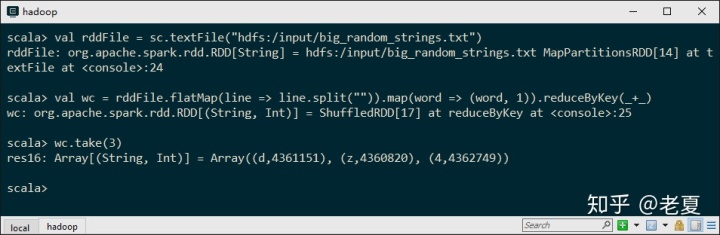
val rddFile = sc.textFile("hdfs:/input/big_random_strings.txt")
val wc = rddFile.flatMap(line => line.split("")).map(word => (word, 1)).reduceByKey(_+_)
wc.take(3)只有三行:
- 第一行是从HDFS里读取我们之前创建的随机字符串文件。
- 第二行是做Word Count实质的工作。这会产生一个新的RDD,具体Scala语法相关的请自行搜索。
- flatMap把文件里的数据按行分解, 产生一个新的RDD。
- map把前一步中每个“单词”拿过来,并且每个计数1。
- reduceByKey,把前一步中的结果按Key的不同(也就是word)来计数。
- 第三行从结果里面把前3个取出来。
这时候我们有了Word Count的结果,在wc这个RDD变量中,我们可以把它保存在HDFS中:
wc.saveAsTextFile("hdfs://output/spark_shell_wc")更详细的信息,可以细读官方Spark文档
Python版的Spark Word Count
除了在Spark Shell里可以做数据处理,我们也可以写Python代码。
首先需要安装pyspark包:
pip install pyspark我们如下写了一个Python脚本文件,取名为wc.py:
#!/usr/bin/env python
这段代码也很简单,而且重点是,它可以远程执行:
- 首先引入SparkContext,还记得Spark Shell里面那个sc吧,就是这个SparkContext。
- 初始化一个sc变量,指向我的spark主服务器,端口是7077。
- 从HDFS里读取我们的输入文件,这里的主机名和端口,参考自己的core-site.xml中的设置fs.defaultFS。
- 做Word Count的核心工作。(看上去跟Spark Shell里基本一样)
- 把结果存进HDFS文件。
我们可以直接在命令行执行这个python脚本:
~/code/bigdata/wc.py得到结果:
我们可以直接用hdfs命令或从网页上查看结果,因为我们已经把结果保存在了HDFS里/spark_count.out目录里。
声明
- 目录中的文章在陆续更新中,如果无法访问,请耐心等待。
- 本人是个实用主义者,有时候为了方便理解和记忆,并不一定完全严谨,欢迎交流。
- 文章中用到的一些图片是借来的,如有版权问题,请及时与我联系更换。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)