机器学习——KNN算法
K-近邻(K-Nearest Neighbors,简称KNN)是一种基于实例的学习或局部逼近的分类算法。它是一种简单且易于实现的监督学习算法,常用于分类任务。通俗的讲:我们将通过KNN算法对一个东西进行分类,只需通过判断与之最相近的k个类别里出现频率最多次的,即将这个东西判定为该类别。KNN算法的主要优点包括:1. 简单、直观、易于理解。2. 无需复杂的模型训练过程,易于实现和调试。然而,KNN算
目录
KNN算法简介
K-近邻(K-Nearest Neighbors,简称KNN)是一种基于实例的学习或局部逼近的分类算法。它是一种简单且易于实现的监督学习算法,常用于分类任务。
通俗的讲:我们将通过KNN算法对一个东西进行分类,只需通过判断与之最相近的k个类别里出现频率最多次的,即将这个东西判定为该类别。
距离的计算
我们一般考虑用欧氏距离来计算:
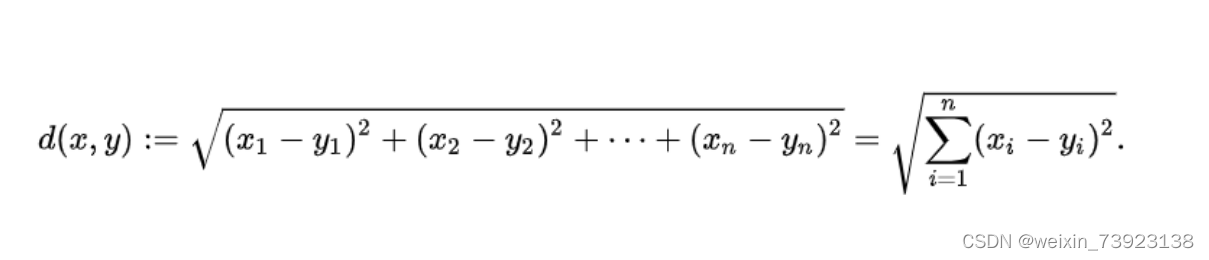
代码实现
以电影爱情片和动作片的分类为例。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def classify0(inX,dataSet,k):
"""
KNN分类器
inX:要预测的数据集
dataSet:训练集
k:KNN算法的K值,即距离最近的k个点
返回:
result:分类结果
"""
result = []
#计算欧氏距离
dist = list((((dataSet.loc[:,['打斗镜头','接吻镜头']] - inX)**2).sum(1))**0.5) #将得出的欧氏距离列表
dist_l = pd.DataFrame({
'dist':dist,
'labels':(dataSet.loc[:,'电影类型'])
})
#按距离列进行升序排列,然后选取距离最小的前k个
dr = dist_l.sort_values(by='dist')[:k]
print(dr.head(k))
#统计前k个点所在类别出现的频率
r = dr['labels'].value_counts()
result.append(r.index[0]) #预测结果即为r.index[0]
return result
plt.rcParams['font.sans-serif']=['Simhei'] #显示中文字体 黑体
plt.rcParams['axes.unicode_minus']=False #显示负号
#创建原始数据集
rowdata = {
'电影名称':['无问西东','后来的我们','前任3','红海行动','唐人街探案','战狼2','古惑仔','泰坦尼克号','Shameless'],
'打斗镜头':[1,5,12,108,112,115,120,2,50],
'接吻镜头':[101,89,97,5,9,8,22,10,110],
'电影类型':['爱情片','爱情片','爱情片','动作片','动作片','动作片','动作片','爱情片','爱情片']
}
movie_data = pd.DataFrame(rowdata)
print(movie_data.head(10)) #输出表格
# 进行映射
color_mapping = {
'爱情片': 'orange',
'动作片': 'blue'
}
movie_data['颜色'] = movie_data['电影类型'].map(color_mapping) #爱情片橙色,动作片蓝色
#创建画布
plt.figure(figsize=(6,4),dpi = 80) #dpi-像素
#绘制散点图
plt.scatter(movie_data.打斗镜头,movie_data.接吻镜头,c = movie_data.颜色,marker='*',s=80)
plt.title('电影分类',fontsize = 12)
plt.xlabel('打斗镜头',fontsize = 10)
plt.ylabel('接吻镜头',fontsize = 10)
plt.xlim(0,130)
plt.ylim(0,120)
#测试样本数据
plt.scatter(70,60,c='r',s=100)
plt.show()
#测试函数运行结果
k = 3
new_data = [70,60]
inX = new_data
dataSet = movie_data
print(classify0(inX,dataSet,k))
运行结果
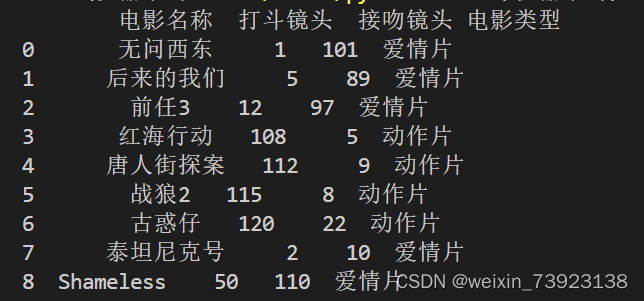
上图是训练集展示,下图是k值为3时,距离最近的前三个类别和最终判断结果展示
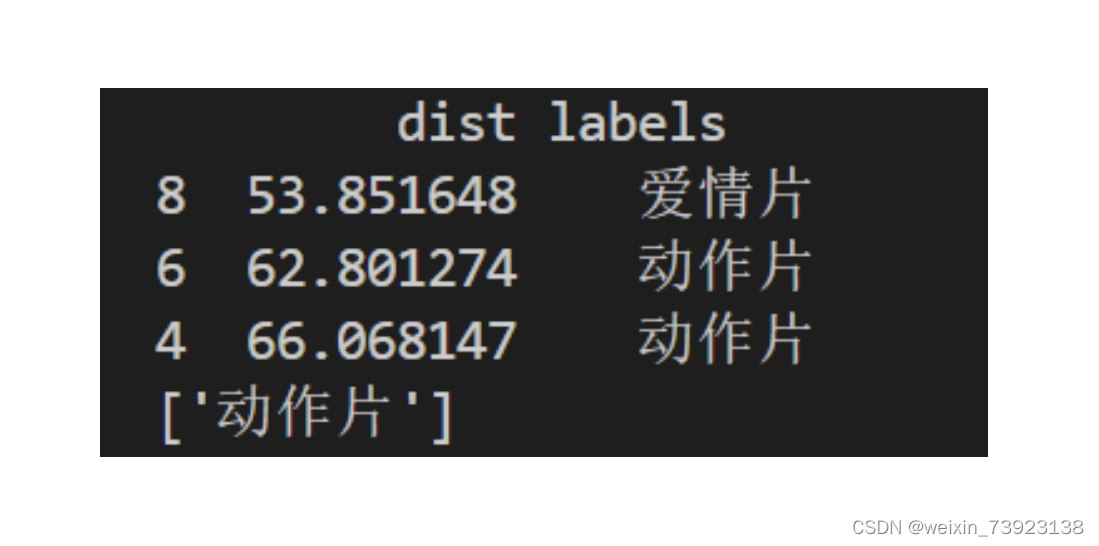
输入的测试数据为new_data = [70,60] ,k = 3。 数据集意为:动作镜头有70处,接吻镜头有60处。
得到散点图:
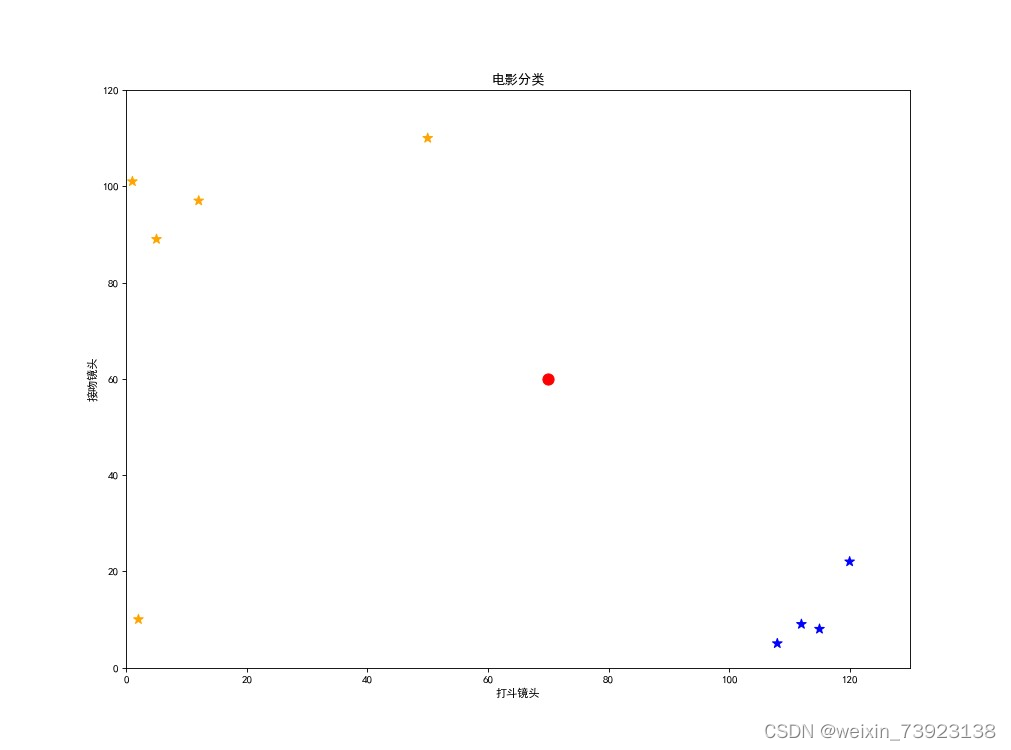
红点为新的预测点,黄点指爱情片,蓝点指动作片。由图易得:
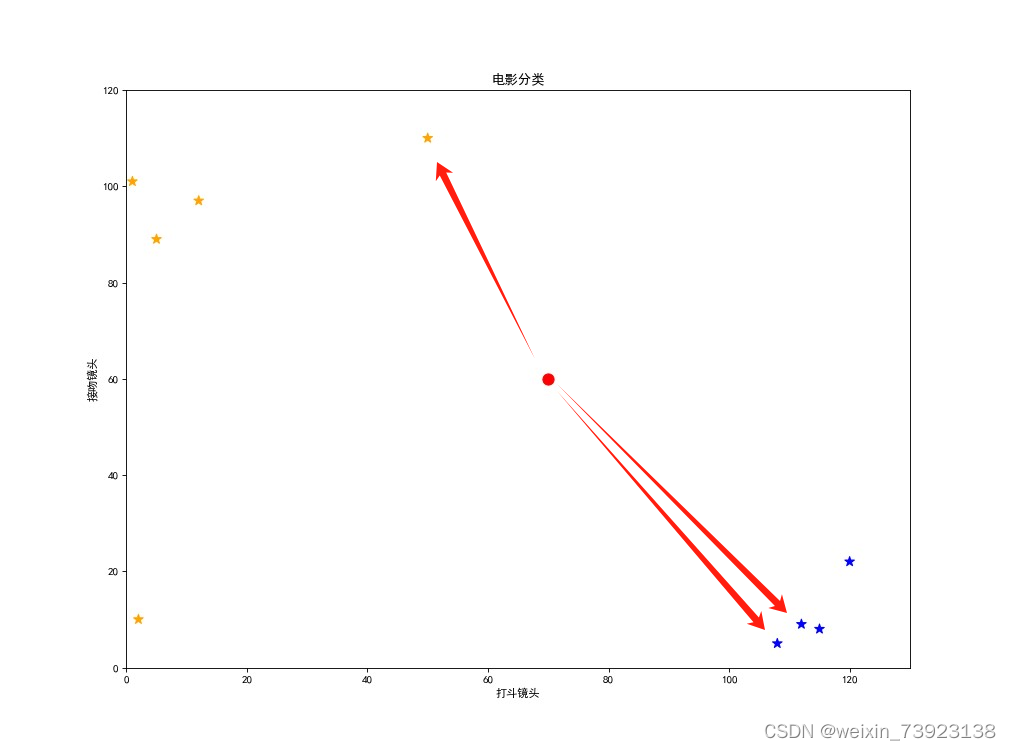
距离红点(预测点)最近的黄点(爱情片)只有一个,而最近的蓝点(动作片)有两个,所以新的预测数据结果表明,该电影应分类为动作片。
不同的K值对比实验
当k = 1时,距离红点最近的即为黄点(爱情片),所以归为爱情片一类。
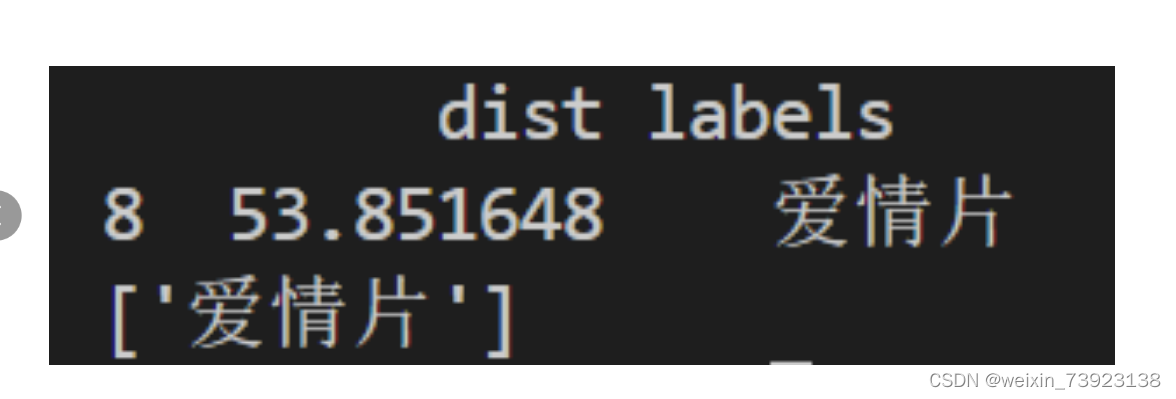

当k = 3时,归为动作片一类。
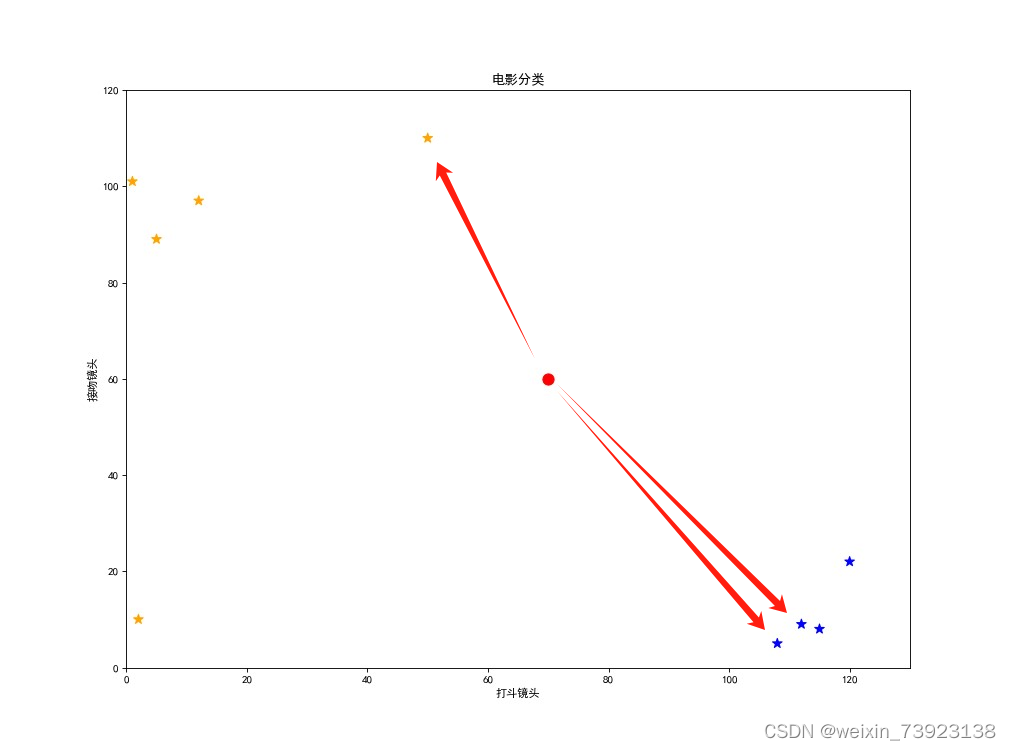
实验结果分析
可见k值的大小对于分类结果有一定的影响。k值越大,越不容易受异常点的影响,泛化能力也更好,但是k值太大也会导致欠拟合;k值太小又会导致过拟合,容易受异常点的影响,所以k值的取值应当取适当大小,根据具体情况而定。
KNN算法优缺点总结
KNN算法的主要优点包括:1. 简单、直观、易于理解。
2. 无需复杂的模型训练过程,易于实现和调试。
然而,KNN算法也有一些缺点: 1.计算复杂度较高,尤其是在大规模数据集上,需要遍历所有训
练样本以找到最近的k个邻居。
2. 对参数的选择比较敏感,例如k值的确定需要依赖经验和尝试不同的候选值进行评估。
3. 对样本特征的缩放敏感,要求输入特征在特征空间中具有一定的可分性。
总的来说,KNN算法是一种非常基础且广泛应用的机器学习算法,适用于分类和回归任务,但需要谨慎处理其缺点以提高性能和准确性。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)