大连理工大学选修课——机器学习笔记(9):线性判别式与逻辑回归
线性判别式与逻辑回归
概述
判别式方法
产生式模型需要计算输入、输出的联合概率
- 需要知道样本的概率分布,定义似然密度的隐式参数
- 也称为基于似然的分类
判别式模型直接构造判别式gi(x∣θi)g_i(x|\theta_i)gi(x∣θi),显式定义判别式参数,不关心数据生成过程
基于判别式的方法只关注类区域之间的边界
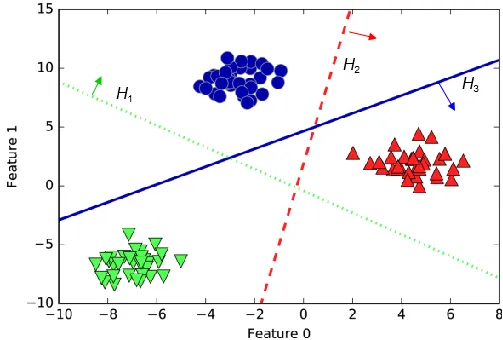
一般认为,估计样本集的类密度比估计类判别式更困难,因为构造判别式通常采用简单的模型
如,线性判别式:
gi(x∣wi,wi0)=wiT+wi0=∑j=1dwijxj+wi0 g_i(x|w_i,w_{i0})=w_i^T+w_{i0}=\sum_{j=1}^dw_{ij}x_j+w_{i0} gi(x∣wi,wi0)=wiT+wi0=j=1∑dwijxj+wi0
广义上,线性判别式代表了一类机器学习模型
- 逻辑回归
- 支持向量机
- 感知机
- 神经网络
狭义上,线性判别式仅代表逻辑回归
线性判别式
建立判别式
gi(x∣wi,wi0)=wiTx+wi0=∑j=1dwijxj+wi0 g_i(x|w_i,w_{i0})=w_i^Tx+w_{i0}=\sum_{j=1}^dw_{ij}x_j+w_{i0} gi(x∣wi,wi0)=wiTx+wi0=j=1∑dwijxj+wi0
最大熵模型的判别式还是从条件后验概率出发
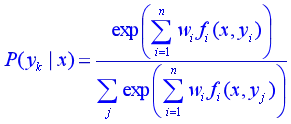
建模的条件
-
数据只有两类
-
线性可分
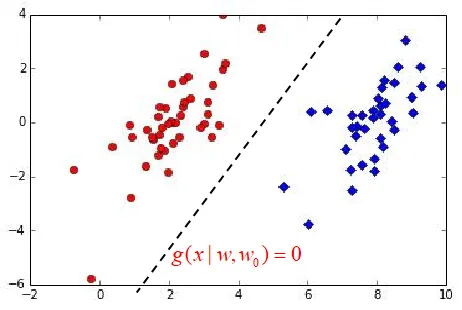
判别式模型不考虑数据集的概率分布,直接假定判别式的形式
模型的训练
gi(x∣wi,wi0)=wiTx+wi0=∑j=1dwijxj+wi0 g_i(x|w_i,w_{i0})=w_i^Tx+w_{i0}=\sum_{j=1}^dw_{ij}x_j+w_{i0} gi(x∣wi,wi0)=wiTx+wi0=j=1∑dwijxj+wi0
可以采用梯度法,牛顿法等
也可以采用全局优化算法,如遗传算法,模拟退火算法等
线性模型的推广
如果数据不是线性可分的,可以提高模型的复杂度,例如使用二次判别式
- 升维操作,增加高阶项
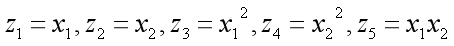
-
升维操作的一般形式
gi(x)=∑j=1kwjθij(x)+wi0 g_i(x)=\sum_{j=1}^kw_j\theta_{ij}(x)+w_i0 gi(x)=j=1∑kwjθij(x)+wi0
其中,θij\theta_{ij}θij是非线性函数,称为基函数
常用的基函数有sin,exp,log等
线性模型的及决策
原则上,每个类别对应一个判别式,二值分类一个判别式可以分类
g(x)>0 ? C1:C2g(x)>0\ ?\ C_1:C2g(x)>0 ? C1:C2
线性模型的几何意义
任取超平面的两个点x1,x2,x_1,x_2,x1,x2,有g(x1)=g(x2)g(x_1)=g(x_2)g(x1)=g(x2)
则wTw^TwT为超平面法线
x的新表达式为
x=xp+rw∣∣w∣∣ x=x_p+r\frac{w}{||w||} x=xp+r∣∣w∣∣w
其中,xpx_pxp是xxx到超平面的投影;r是x到超平面的距离r=g(x)∣∣w∣∣r=\frac{g(x)}{||w||}r=∣∣w∣∣g(x)
超平面到原点的距离为r0=wo∣∣w∣∣r_0=\frac{w_o}{||w||}r0=∣∣w∣∣wo
处理多类问题
当类别数大于2时,需要k个判别式,假定所有类均线性可分,则可以用线性判别式进行区分
对于属于类别CiC_iCi的样本xxx,我们期望其判别式函数gi(x)>0g_i(x)>0gi(x)>0,而其它判别式函数gj(x)<0g_j(x)<0gj(x)<0
但是现实中,多个类别的判别式可能同时给出g(x)>0g(x)>0g(x)>0
因此,我们取判别式值最大的类即预测类别=max gi(x)预测类别=max\ g_i(x)预测类别=max gi(x)
此方法称为线性分类器
如果类线性不可分,则可以采取
- 升维
- 逐对分离:假定各类别间逐对线性可分,那么,有K(K−1)2\frac{K(K-1)}{2}2K(K−1)个对,建立这么多个线性判别式
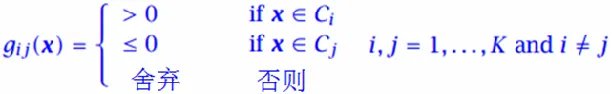
如果k既不属于i也不属于j,则在训练中舍弃样本xtx^txt,xtx^txt为其它类样本
这种不断排除的理念类似决策树
逻辑回归
讨论二值分类的对数线性模型
我们从后验概率P(Ci∣x)P(C_i|x)P(Ci∣x)的计算出发,建立学习模型
定义P(C1∣x)=y,P(C2∣x)=1−yP(C_1|x)=y,P(C_2|x)=1-yP(C1∣x)=y,P(C2∣x)=1−y
决策为:
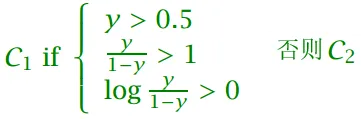
假设两个类别的数据C1,C2C_1,C_2C1,C2服从高斯分布,两类别共享协方差矩阵,在此假设下,贝叶斯分类器的判别式g(x)g(x)g(x)是线性的,推导如下:
根据高斯判别分析的结论:
- 后验概率P(C1∣x)P(C_1|x)P(C1∣x)可表示为:
logP(C1∣x)P(C2∣x)=wTx+w0 \begin{align} log\frac{P(C_1|x)}{P(C_2|x)}=w^Tx+w_0 \end{align} logP(C2∣x)P(C1∣x)=wTx+w0
- 由于P(C2∣x)=1−P(C1∣x)P(C_2|x)=1-P(C_1|x)P(C2∣x)=1−P(C1∣x),上式等价于:
logP(C1∣x)1−P(C1∣x)=wTx+w0=logit(P(C1∣x)) \begin{align} log\frac{P(C_1|x)}{1-P(C_1|x)}=w^Tx+w_0=logit(P(C_1|x)) \end{align} log1−P(C1∣x)P(C1∣x)=wTx+w0=logit(P(C1∣x))
这正是对数几率的定义
- 对(2)(2)(2)移项,得:
P(C1∣x)=11+e−(wT+w0) P(C_1|x)=\frac{1}{1+e^{-(w^T+w_0)}} P(C1∣x)=1+e−(wT+w0)1
(3)(3)(3)式为逻辑回归的模型形式,sigmoid。
Logistic函数(也称sigmoid)
P(C1∣x)=11+e−(wT+w0)=sigmoid(wTx+w0) P(C_1|x)=\frac{1}{1+e^{-(w^T+w_0)}}=sigmoid(w^Tx+w_0) P(C1∣x)=1+e−(wT+w0)1=sigmoid(wTx+w0)
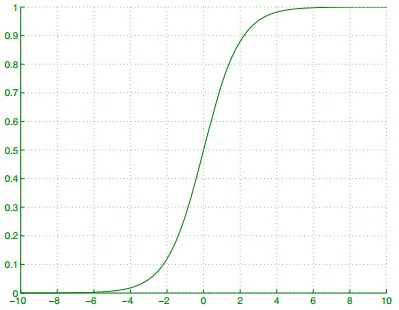
sigmoid函数图像,y>0.5,选C_1
Logistic函数的一般形式
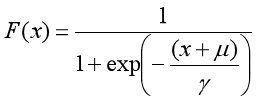
其中,μ\muμ为位置参数,γ>0\gamma>0γ>0为形状参数,关于(μ,12)(\mu,\frac{1}{2})(μ,21)对称
逻辑回归
逻辑回归的核心思想,在于不考虑数据分布,假定类似然密度的对数比为线性函数,那么:
log P(x∣C1)P(x∣C2)=wTx+w00 \begin{align} log\ \frac{P(x|C_1)}{P(x|C_2)}=w^Tx+w_0^0 \end{align} log P(x∣C2)P(x∣C1)=wTx+w00
通过贝叶斯定理,将后验概率转换为似然比和先验比的乘积:
logP(C1∣x)P(C2∣x)=logP(x∣C1)P(x∣C2)+logP(C1)P(C2) \begin{align} log\frac{P(C_1|x)}{P(C_2|x)}=log\frac{P(x|C_1)}{P(x|C_2)}+log\frac{P(C_1)}{P(C_2)} \end{align} logP(C2∣x)P(C1∣x)=logP(x∣C2)P(x∣C1)+logP(C2)P(C1)
由公式(2)(3)(4)(2)(3)(4)(2)(3)(4)得:
logit(P(C1∣x))=wTx+w00+logP(C1)P(C2) \begin{align}logit(P(C_1|x))=w^Tx+w^0_0+log\frac{P(C_1)}{P(C_2)} \end{align} logit(P(C1∣x))=wTx+w00+logP(C2)P(C1)
将w00+logP(C1)P(C2)w^0_0+log\frac{P(C_1)}{P(C_2)}w00+logP(C2)P(C1)合并为新的偏置项,那么先验概率P(Ck)P(C_k)P(Ck)被吸收到了偏置项,模型仍保持线性:
logit(P(C1∣x))=wTx+w00 logit(P(C_1|x))=w^Tx+w^0_0 logit(P(C1∣x))=wTx+w00
处理多类问题
我们推广二值分类至K>2K>2K>2的情形,假定:
logp(x∣Ci)p(x∣Ck)=wiT+wi00 \begin{align} log\frac{p(x|C_i)}{p(x|C_k)}=w_i^T+w_{i0}^0 \end{align} logp(x∣Ck)p(x∣Ci)=wiT+wi00
进而:
p(Ci∣x)p(Ck∣x)=ewiT+wi0,i=1,2,⋯ ,K−1 \begin{align} \frac{p(C_i|x)}{p(C_k|x)}=e^{w_i^T+w_{i0}},\quad i=1,2,\cdots,K-1 \end{align} p(Ck∣x)p(Ci∣x)=ewiT+wi0,i=1,2,⋯,K−1
∑i=1Kp(Ci∣x)p(CK∣x)=1p(Ck∣x)=1+∑j=1K−1ewjx+wj0 \begin{align} \sum_{i=1}^K\frac{p(C_i|x)}{p(C_K|x)}=\frac{1}{p(C_k|x)}= 1+\sum_{j=1}^{K-1}e^{w_jx+w_{j0}} \end{align} i=1∑Kp(CK∣x)p(Ci∣x)=p(Ck∣x)1=1+j=1∑K−1ewjx+wj0
于是:
p(Ck∣x)=11+∑j=1K−1ewjx+wj0 \begin{align} p(C_k|x)=\frac{1}{1+\sum_{j=1}^{K-1}e^{w_jx+w_{j0}}} \end{align} p(Ck∣x)=1+∑j=1K−1ewjx+wj01
对于其它类别i=1,⋯ ,K−1,i=1,\cdots,K-1,i=1,⋯,K−1,由公式(3)(3)(3)得:
p(Ci∣x)=ewix+wi01+∑j=1K−1ewjx+w0 \begin{align} p(C_i|x)=\frac{e^{w_ix+w_{i0}}}{1+\sum_{j=1}^{K-1}e^{w_jx+w_0}} \end{align} p(Ci∣x)=1+∑j=1K−1ewjx+w0ewix+wi0
将公式同一形式,对所有i=1,⋯ ,K:i=1,\cdots,K:i=1,⋯,K:
p(Ci∣x)=ewix+wi0∑j=1Kewjx+wj0,其中wK,wK0=0 p(C_i|x)=\frac{e^{w_ix+w_{i0}}}{\sum_{j=1}^Ke^{w_jx+w_{j0}}},其中w_K,w_{K0}=0 p(Ci∣x)=∑j=1Kewjx+wj0ewix+wi0,其中wK,wK0=0
softmax函数
yi=p^(Ci∣x)=ewix+w0∑ewjx+wj0 y_i=\hat p(C_i|x)=\frac{e^{w_ix+w_0}}{\sum e^{w_jx+w_{j0}}} yi=p^(Ci∣x)=∑ewjx+wj0ewix+w0
如果一个类C的判别式加权函数值明显大于其它类的加权和,那么yiy_iyi接近于1,将数值限定在了[0,1][0,1][0,1]之间,可以用概率表示。
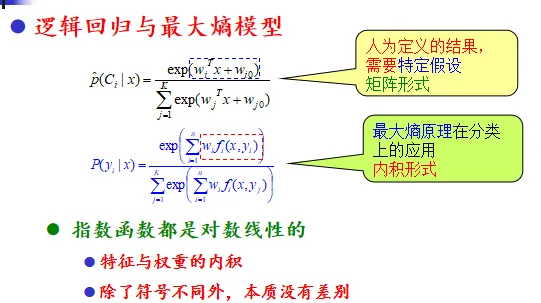
逻辑回归与最大熵模型
逻辑回归和最大熵模型可以认为是同一类模型的不同表现形式。
逻辑回归的训练——梯度下降法
逻辑回归交叉熵损失函数:
E=−∑[rlogy+(1−r)log(1−y)] E=-\sum [rlogy+(1-r)log(1-y)] E=−∑[rlogy+(1−r)log(1−y)]
对E求偏导,乘以学习率,为更新方向:
△wj=−η∂E∂wj=η∑(r−y)xj \triangle w_j=-\eta\frac{\partial E}{\partial w_j}=\eta\sum(r-y)x_j △wj=−η∂wj∂E=η∑(r−y)xj

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)