【神经网络基础-09】:正则化(Dropout层使用)
介绍神经网络中的Dropout正则化方法
1 正则化
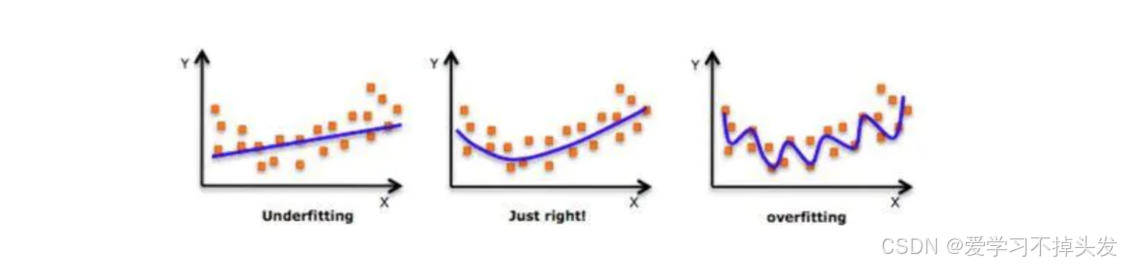
在设计机器学习算法时希望在新样本上的泛化能力强。许多机器学习算法都采用相关的策略来减小测试误差,这些策略被统称为正则化。
神经网络的强大的表示能力经常遇到过拟合,所以需要使用不同形式的正则化策略。
目前在深度学习中使用较多的策略有范数惩罚,DropOut,特殊的网络层等,接下来我们对其进行详细的介绍。
1.1 Dropout层原理
在训深层练神经网络时,由于模型参数较多,在数据量不足的情况下,很容易过拟合。Dropout(随机失活) 就是在神经网络中一种缓解过拟合的方法。
- Dropout层的作用
我们知道,缓解过拟合的方式就是降低模型的复杂度,而 Dropout 就是通过减少神经元之间的连接,把稠密的神经网络神经元连接,变成稀疏的神经元连接,从而达到降低网络复杂度的目的。
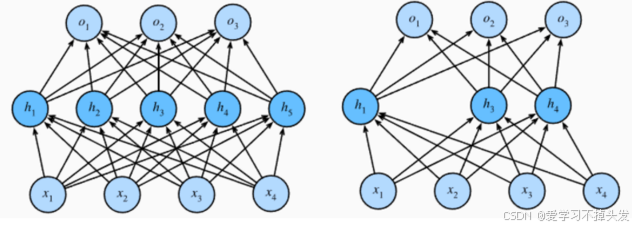
- 在训练过程中,Dropout的实现是让神经元以超参数p的概率停止工作或者激活被置为0,未被置为0的进行缩放,缩放比例为1/(1-p)。
- 训练过程可以认为是对完整的神经网络的一些子集进行训练,每次基于输入数据只更新子网络的参数。
- 在测试过程中,随机失活不起作用。
1.2 Dropout层使用效果
我们先通过一段代码观察下丢弃层的效果:
import torch
import torch.nn as nn
def test():
# 初始化丢弃层
dropout = nn.Dropout(p=0.8)
# 初始化输入数据
inputs = torch.randint(0, 10, size=[5, 8]).float()
print(inputs)
print('-' * 50)
# dropout之后会随机令一些值变为0
outputs = dropout(inputs)
print(outputs)
if __name__ == '__main__':
test()
'''
程序输出结果:
tensor([[1., 0., 3., 6., 7., 7., 5., 7.],
[6., 8., 4., 6., 2., 0., 4., 1.],
[1., 4., 6., 9., 3., 1., 2., 1.],
[0., 6., 3., 7., 1., 7., 8., 9.],
[5., 6., 8., 4., 1., 7., 5., 5.]])
--------------------------------------------------
tensor([[ 0., 0., 15., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 10., 0., 0., 0.],
[ 0., 0., 0., 45., 0., 0., 0., 0.],
[ 0., 0., 15., 0., 0., 0., 0., 0.],
[25., 0., 0., 0., 0., 0., 0., 25.]])
'''
- Dropout可以随机使张量中的一些值置为0
import torch
import torch.nn as nn
def test():
# 初始化随机失活层
dropout = nn.Dropout(p=0.4)
# 初始化输入数据:表示某一层的weight信息
inputs = torch.randint(0, 10, size=[1, 4]).float()
layer = nn.Linear(4,5) # 一层的网络
y = layer(inputs) # 经过网络训练之后
print("未失活FC层的输出结果:\n", y)
y = dropout(y)
print("失活后FC层的输出结果:\n", y)
if __name__ == '__main__':
test()

我们将 Dropout 层的概率 p 设置为 0.8,此时经过 Dropout 层计算的张量中就出现了很多 0 , 概率 p 设置值越大,则张量中出现的 0 就越多。上面结果的计算过程如下:
- 先按照 p 设置的概率,随机将部分的张量元素设置为 0
- 为了校正张量元素被设置为 0 带来的影响,需要对非 0 的元素进行缩放,其缩放因子为: 1 1 − p \frac {1}{1-p} 1−p1,上面代码中 p 的值为 0.8, 根据公式缩放因子为:1/(1-0.8) = 5
- 比如:第 3 个元素,原来是 5,乘以缩放因子之后变成 25。
我们也发现了,丢弃概率 p 的值越大,则缩放因子的值就越大,相对其他未被设置的元素就要更多的变大。丢弃概率 P 的值越小,则缩放因子的值就越小,相对应其他未被置为 0 的元素就要有较小的变大。
1.3 Dropout对于网络影响
当张量某些元素被设置为 0 时,对网络会带来什么影响?
比如上面这种情况,如果输入该样本,会使得某些参数无法更新,请看下面的代码:
import torch
import torch.nn as nn
# 设置随机数种子
torch.manual_seed(0)
def caculate_gradient(x, w):
y = x @ w
y = y.sum()
y.backward()
print('Gradient:', w.grad.reshape(1, -1).squeeze().numpy())
def test01():
# 初始化权重
w = torch.randn(15, 1, requires_grad=True)
# 初始化输入数据
x = torch.randint(0, 10, size=[5, 15]).float()
# 计算梯度
caculate_gradient(x, w)
def test02():
# 初始化权重
w = torch.randn(15, 1, requires_grad=True)
# 初始化输入数据
x = torch.randint(0, 10, size=[5, 15]).float()
# 初始化丢弃层
dropout = nn.Dropout(p=0.8)
x = dropout(x)
# 计算梯度
caculate_gradient(x, w)
if __name__ == '__main__':
test01()
print('-' * 70)
test02()
'''
程序输出结果:
Gradient: [19. 15. 16. 13. 34. 23. 20. 22. 23. 26. 21. 29. 28. 22. 29.]
----------------------------------------------------------------------
Gradient: [ 5. 0. 35. 0. 0. 45. 40. 40. 0. 20. 25. 45. 55. 0. 10.]
'''
从程序结果来看,经过 Dropout 层对梯度的计算产生了不小的影响,例如:经过 Dropout 层之后有一些梯度为 0,这使得参数无法得到更新,从而达到了降低网络复杂度的目的。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)