仙之侠道2玖章各个任务详情_这550道大数据面试题,绝对是HR最常出的面试题
写在前面——
上周我发布了675道Java面试题集,读者朋友们反响热烈,还有粉丝给我们发私信,希望可以再出一套大数据的面试题。
应广大读者和面试者需求,我们从各招聘公司和学员处收集了1200多道大数据面试题,其中不乏有京东、搜狐、新浪、爱艺奇等大企业面试题,我们从中筛选出其中550道最精华的部分组成这份面试题集,并在此分享给大家。
希望这份大数据面试题可以对你找工作有所帮助,一定要答完题后,再来找小编看答案哦!模块介绍
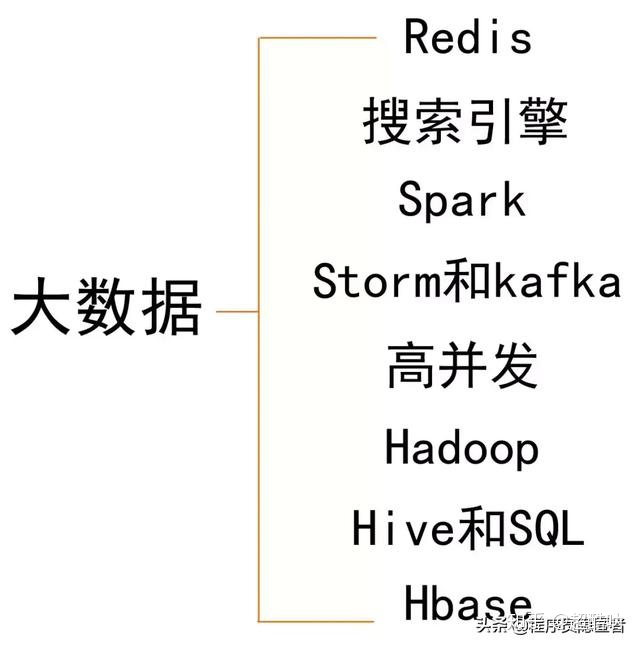
本题集包含Redis、搜索引擎、Spark、Storm和kafka、高并发、Hadoop、hive和SQL、Hbase八个模块,详情如下:
领取答案
①转发:转发此文
②关注小编
③私信小编关键字“面试”
新鲜出炉的答案,立马送到您手上具体题集
1
Redis
1、redis工作原理
2、kafka为什么要分多个partition?
3、有一个千万用户的网站,活跃用户在百万左右,用户ID是64位长整数。
4、redis bit操作?
5、redis用来做什么? 模型等,频繁调用的放在redis中,取其快
6、Redis中如何向Spark存东西一条一条插,还是一堆一堆插数据,怎么建立连接?
7、你在项目中redis的存储有哪些?
8、Redis是什么,使用场景?
9、redis支持的最大数据量是多少?redis集群下怎么从某一台集群查key-value。
10、列举一个常用的Redis客户端的并发模型。
11、什么是布隆过滤器,其实现原理是?False positive指的是?
12、memcache与redis的区别
13、Redis,传统数据库,hbase,hive 每个之间的区别(问的非常细)
14、HBase与Redis
16、redis支持的数据格式
17、基本操作,存储格式
18、下列对RDD特点描述错误的是()(单选)

19、Spark中的RDD的计算是以什么作为单位的?每个RDD都会实现什么函数以达到这个目的?
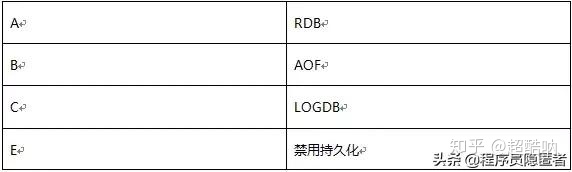
20、以下哪一个是Redis不支持的持久化策略( )(单选)
2
搜索引擎
21、用到哪些全文检索的技术
22、lunce和solr
23、搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。假设目前一个日志文件中有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门),请你统计最热门的10个查询串,要求使用的內存不能超过1G。
24、Elasticsearch使用一种叫做倒排索引的结构来实现快速的全文索,什么是倒排索引,请举例?
3
Spark
25、Spark框架
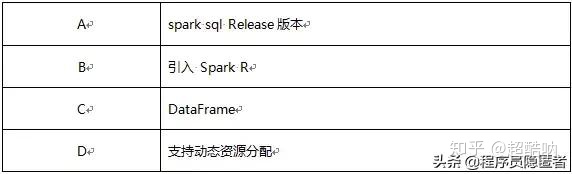
26、sparkSQL介绍下(RDD、DataFrame)
27、DSL和SQL用哪个比较多?
28、udf和udaf都写过哪些?
29、介绍下udaf
30、spark运行在Yarn上流程(cluster)
31、spark调优
32、宽窄依赖
33、sparkStreaming和Storm比较
34、SparkStreaming与Storm的应用场景
35、sparkon yarn 和mapreduce 中yarn有什么区别
36、spark原理
37、Spark支持的分布式部署方式是? ( )

38、Spark的四大组件下面哪个不是 ( )

39、下面哪个端口不是spark自带服务的端口 ( )

40、spark1.4版本的最大变化 ( )
41、SparkJob默认的调度模式( )

42、哪个不是本地模式运行的个条件( )

43、下面哪个不是RDD的特点( )

44、关于广播变量,下面哪个是错误的( )

45、关于累加器,下面哪个是错误的( )

46、Stage的Task的数量由什么决定( )

47、下面哪个操作是窄依赖( )

48、下面哪个操作肯定是宽依赖( )
49、spak的 master和 worker通过什么方式进行通信的( )

50、默认的存储级别 ( )

51、sparkdeploy recovery Mode不支持那种( )
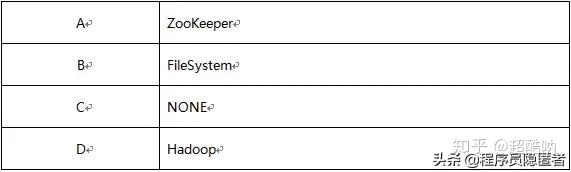
52、下列哪个不是RDD的缓存方法 ( )

53、Task运行在下来哪里个选项中 Executor上的工作单元( )
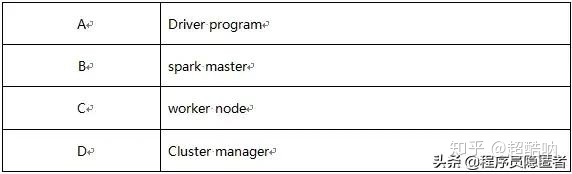
54、hive的元数据存储在derby和 MySQL中有什么区别( )
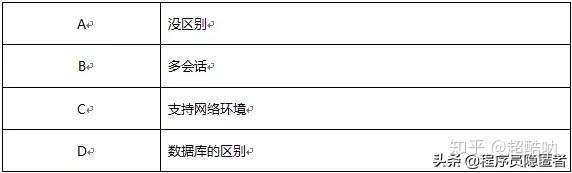
55、DataFrame和RDD最大的区别( )
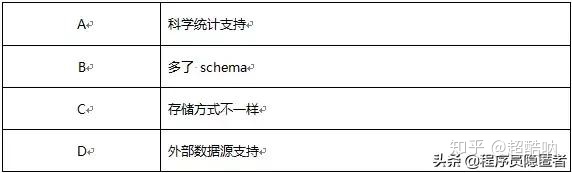
56、Master的 ElectedLeader事件后做了哪些操作( )

57、简述Spak工作的一个流程
58、spark作业远程提交。
59、sparkstreaming原理
60、使用spark对rddl里的每个元素乘以2,然后排序
61、Spark了解多少?
62、Spark源码
63、下面哪个是 spark的 actI on操作( )

64、spark血统的概念?
65、写完spark程序如何知道多少个task? (即资源如何调配的)
66、spark程序用什么语言写的?
67、spark和mr性能是不是差别很多?
68、Spark的运行模式
69、可以说一下sparkshuffle吗?
70、缓存这块熟悉吗,介绍缓存级别
71、说一下cache和checkpoint的区别
72、sql题

统计这个表每列的数字大于1的个数结果如下:

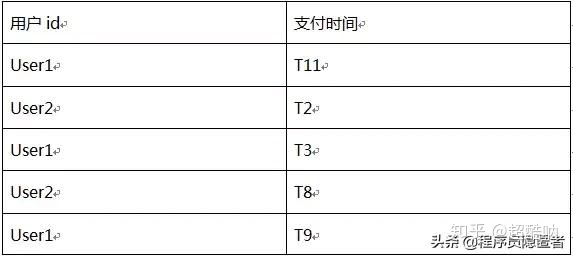
73、sparkcore业务题目,求出每个用户各次支付时间的间隔,如用户支付了三次,就要求出两条这个用户支付间隔时间
74、spark运行模式local local[] local[*]分别是什么
75、Spark怎么设置垃圾回收机制 ?
76、一台节点上以root用户执行一个spark 程序,以其他非root用户也同时在执行一个spark程序,这时以spark用户登录,这个节点上,使用Jps 会看到哪些线程?
77、Spark的提交方式?
78、cache和persist的区别 reduceBykey和groupByKey
79、请简要描述 Spark任务提交后的执行流程(大致步骤)
80、streaming在电商项目上是怎么用的
81、日流量10G没必要sparkstreaming
82、sparkstream窗口
83、spark为什么比hadoop快??
84、rdd的处理过程是什么,不要说概念
85、谈谈数据倾斜,并给出优化方案?
86、Spark里面 RDD Persist0和 RDD cacheo的区别?
87、Sparkexecutor的职责
88、集群上运行 Spark应用的过程?
89、画图讲解Spark工作流程。以及在集群上和各个角色的对应关系
90、spark哪些算子操作涉及到 shuffle?
91、Hadoop和 Spark的shuffle过程,你怎么在编程的时候注意避免一些问题?
92、有订单数据表为 server_id(服1D)、role_id(角色1D)、 money充值金额),统计每个服中累计充值金额排名前3的角色ID与总充值金额分别使用HIVESQL、 Spark算子实现?
93、用spark实现WordCount
94、分别列举hadoop和spark中的文件缓存方式
95、Hive与spark对于数据倾斜如何处理
96、请简要描述一下 Hadoop, Spark两种计算框架的特点以及分别适用于什么样的场景。
97、简要描述Spark分布式集群搭建的步骤? spark- submit的时候如何引入外部jar包?
98、sparkon yarn 和mapreduce 中yarn有什么区别?
99、简述将Spark工程文件打包上传到集群并提交运行的过程
100、有一亿个用户,被存储于表 Users中,其中有用户唯一字段UID,用户年龄age和用户消费总消费金额total,请以代码或技术方案阐述的方式分别用sql(Hive或 Spark Sql)和 Spark
按照用户年龄从大到小进行排序,如果年龄相同,则按照总消费金额按照从小到大排序
101、spark里面 RDD.persist()和RDD.cache()的区别?
102、Sparkexecutor的职责?
103、统计词频,单词之间采用空格分割,请使用 mapreduce及spark
代码,分别统计出前十名单词
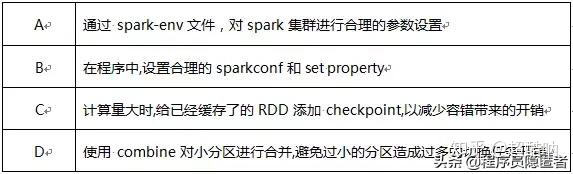
104、下列哪些方法可以对 Spark任务进行优化?()(多选)
105、怎么用spark做数据清洗?
106、spark、hive、MR数据清洗的区别?
107、你觉得spark可以完全替代hadoop 么?
108、下列对RDD特点描述错误的是()

109、Spark中的RDD的计算是以什么作为单位的?每个RDD都会实现什么函数以达到这个目的?
110、在做大数据计算时,涉及到几种join的方式?请阐述或用代码分别在Sql(Hive或 Spark,Hadoop三种大数据框架中的实现方式。
由于篇幅有限,后续题集小编就不都发出来了,需要的读者朋友可以找小编免费获取,领附赠一份编程学习所需的学习资料领取方式:转发此文,关注并私信小编关键字“学习”即可免费获取

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)