机器学习(11)-贝叶斯分类
贝叶斯分类
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。其中朴素贝叶斯分类是贝叶斯分类中最简单最常见的一种分类方法。朴素贝叶斯不能用于回归,但是是一个有效的分类器。
贝叶斯定理
贝叶斯定理,是18世纪由英国数学家托马斯·贝叶斯(Thomas Bayes)提出的重要概率论理论。贝叶斯定理解决了现实生活里经常遇到的问题:已知某条件概率,如何得到两个事件交换后的概率,即已知P(A|B),如何求得P(B|A)。
贝叶斯定理表示如下
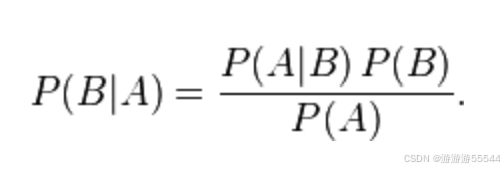
表述为后验概率 = (相似度 * 先验概率)/标淮化常量,其中
- P(A)是 A 的先验概率,之所以称为“先验”是因为它不考虑任何 B 方面的因素。
- P(A|B)是已知 B 发生后 A 的条件概率,也由于得自 B 的取值而被称作 A 的后验概率。
- P(B|A)是已知 A 发生后 B 的条件概率,也由于得自 A 的取值而被称作 B 的后验概率。
- P(B)是 B 的先验概率,也作标淮化常量(normalizing constant)。
贝叶斯决策论
贝叶斯决策论是概率论框架下实施决策的基本方法,是在贝叶斯公式计算出后验概率的基础上,进一步做归属的决定-分类。其主要包括两种决策方式,即最小错误贝叶斯决策和最小风险贝叶斯决策。前者是在比较理想或者各类类别地位均等的情况下的决策,而后者则要考虑决策本身带来的代价和各类别地位的不均等。
最小错误贝叶斯决策
在模式分类问题中,人们往往希望尽量减少分类的错误,从这样的要求出发,利用概率论中的贝叶斯公式,就能得出使错误率为最小的分类规则,称之为基于最小错误率的贝叶斯决策。
选择后验概率最大的分组或者类,则判断正确的可能性就是最大的,进而犯错的概率就是最小的,即最小错误贝叶斯决策 = 最大后验贝叶斯决策。由于概率非负,如果每一次决策错误率都最小,那么总的错误率也是最小的。
最小风险贝叶斯决策
在决策中,除了关心决策的正确与否,有时我们更关心错误的决策将带来的损失。比如在判断细胞是否为癌细胞的决策中,若把正常细胞判定为癌细胞,将会增加患者的负担和不必要的治疗,但若把癌细胞判定为正常细胞,将会导致患者失去宝贵的发现和治疗癌症的机会,甚至会影响患者的生命。这两种类型的决策错误所产生的代价是不同的。考虑各种错误造成损失不同时的一种最优决策,就是最小风险贝叶斯决策。
对于实际状态为wj的向量x,采取决策αi所带来的损失为
![]()
称为损失函数,通常可以用表格的形式给出,称为决策表,需要人为确定。
对于一个实际问题,对于样本xx,最小风险贝叶斯决策的计算步骤如下:
- 利用贝叶斯公式计算后验概率:
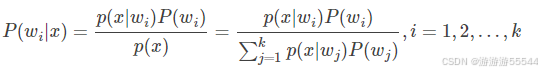
其中要求先验概率和类条件概率已知。
- 利用决策表,计算条件风险:
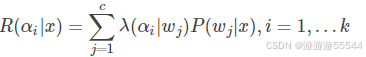
- 决策:选择风险最小的决策,即:
![]()
由于对两类错误带来的风险的认识不同,产生了与之前不同的决策。显然,但对不同类判决的错误风险一致时,最小风险贝叶斯决策就转化成最小错误率贝叶斯决策。最小错误贝叶斯决策可以看成是最小风险贝叶斯决策的一个特例。
朴素贝叶斯分类
基于贝叶斯定理计算后验概率P(B|A)的难点在于P(B|A)是全部属性上的联合概率,难以从有限的数据集中获得。为避开这一难点,朴素贝叶斯分类器对条件概率分布做了条件独立性的假设,即每个属性独立地对分类结果发生影响。
基于属性条件独立性假设,上面的贝叶斯定理表达式可改写为
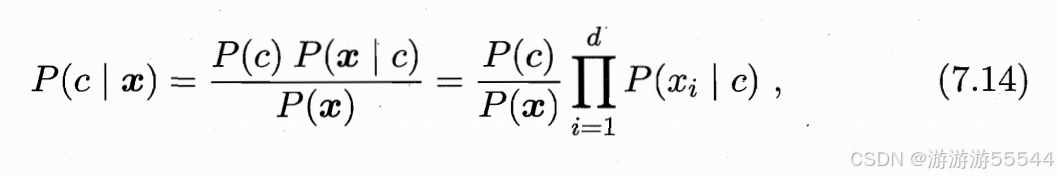
其中d为属性数目,xi为x在第i个属性上的取值。对于所有类别来说,P(x)都相同,基于贝叶斯决策论的贝叶斯判断准则,得到下式
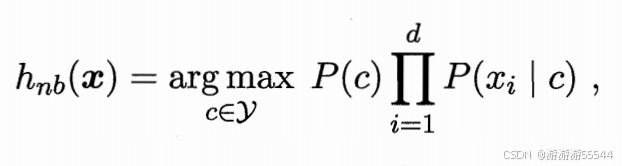
即为朴素贝叶斯分类器的表达式,可以看到,朴素贝叶斯分类器的训练过程就是基于训练集D,计算先验概率P(c),再为每个属性计算条件概率P(xi|c)。
半朴素贝叶斯分类
朴素贝叶斯(NB)的“朴素”体现在其假设各属性之间没有相互依赖,以简化贝叶斯公式中P(x|c)的计算。但事实上,属性直接完全没有依赖的情况是非常少的。如果简单就使用朴素贝叶斯建模,泛化能力和鲁棒性都难以达到令人满意。
由此提出了半朴素贝叶斯,其假定每个属性最多只依赖一个(或k个)其他属性。考虑属性间的相互依赖,但假定依赖只有一个(ODE)或k个(kDE)其他属性,故称为半朴素贝叶斯。即为
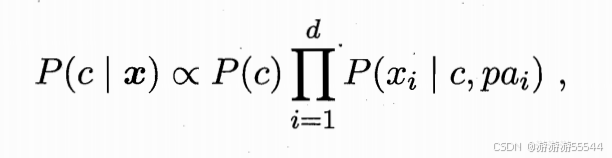
其中,pai 表示 xi 的父属性
Python实践-朴素贝叶斯分类
代码实现过程
import numpy as np
from collections import defaultdict
class NaiveBayesClassifier:
def __init__(self):
self.classes = None
self.class_priors = None
self.class_feature_means = None
self.class_feature_vars = None
def fit(self, X, y):
n_samples, n_features = X.shape
self.classes = np.unique(y)
self.class_priors = {}
self.class_feature_means = {}
self.class_feature_vars = {}
for cls in self.classes:
X_cls = X[y == cls]
self.class_priors[cls] = X_cls.shape[0] / n_samples
self.class_feature_means[cls] = np.mean(X_cls, axis=0)
self.class_feature_vars[cls] = np.var(X_cls, axis=0)
def _calculate_likelihood(self, cls, x):
mean = self.class_feature_means[cls]
var = self.class_feature_vars[cls]
numerator = np.exp(- (x - mean) ** 2 / (2 * var))
denominator = np.sqrt(2 * np.pi * var)
return numerator / denominator
def _calculate_posterior(self, x):
posteriors = {}
for cls in self.classes:
prior = self.class_priors[cls]
likelihood = np.prod(self._calculate_likelihood(cls, x))
posteriors[cls] = prior * likelihood
return posteriors
def predict(self, X):
y_pred = [max(self._calculate_posterior(x), key=self._calculate_posterior(x).get) for x in X]
return np.array(y_pred)
# 测试实现
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn import datasets
# 加载示例数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建并训练朴素贝叶斯分类器
clf = NaiveBayesClassifier()
clf.fit(X_train, y_train)
# 进行预测
y_pred = clf.predict(X_test)
# 评估模型
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Classification Report:")
print(classification_report(y_test, y_pred))
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))
使用sklearn库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn import datasets
# 加载示例数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建高斯朴素贝叶斯分类器
clf = GaussianNB()
# 训练模型
clf.fit(X_train, y_train)
# 进行预测
y_pred = clf.predict(X_test)
# 评估模型
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Classification Report:")
print(classification_report(y_test, y_pred))
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))
Reference
机器学习(西瓜书)
机器学习公式详解(南瓜书)
一文读懂贝叶斯原理(Bayes‘ theorem)_贝叶斯定理 原始参考文献-CSDN博客
【机器学习】贝叶斯分类(通过通俗的例子轻松理解朴素贝叶斯与半朴素贝叶斯)_半朴素贝叶斯实例-CSDN博客
最小错误贝叶斯决策简介和算法实现(含matlab代码和Python代码)_最小错误率贝叶斯决策判决函数-CSDN博客

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)