十二、人工神经网络及其应用
12、人工神经网络及其应用
写在前面
这部分内容老师说很重要,不管是实验还是考试占比都非常大
AIGC的全称是“Artificial Intelligence Generated Content”,即人工智能生成内容。这一术语通常用于指代通过人工智能技术自动生成的各种类型的内容,如文本、图像、音频和视频等。随着AI技术的发展,AIGC在多个领域展现出广泛应用前景,例如自动新闻撰写、个性化推荐、智能客服、自动化设计等。
Begin
神经元与神经网络结构
首先介绍了生物神经元结构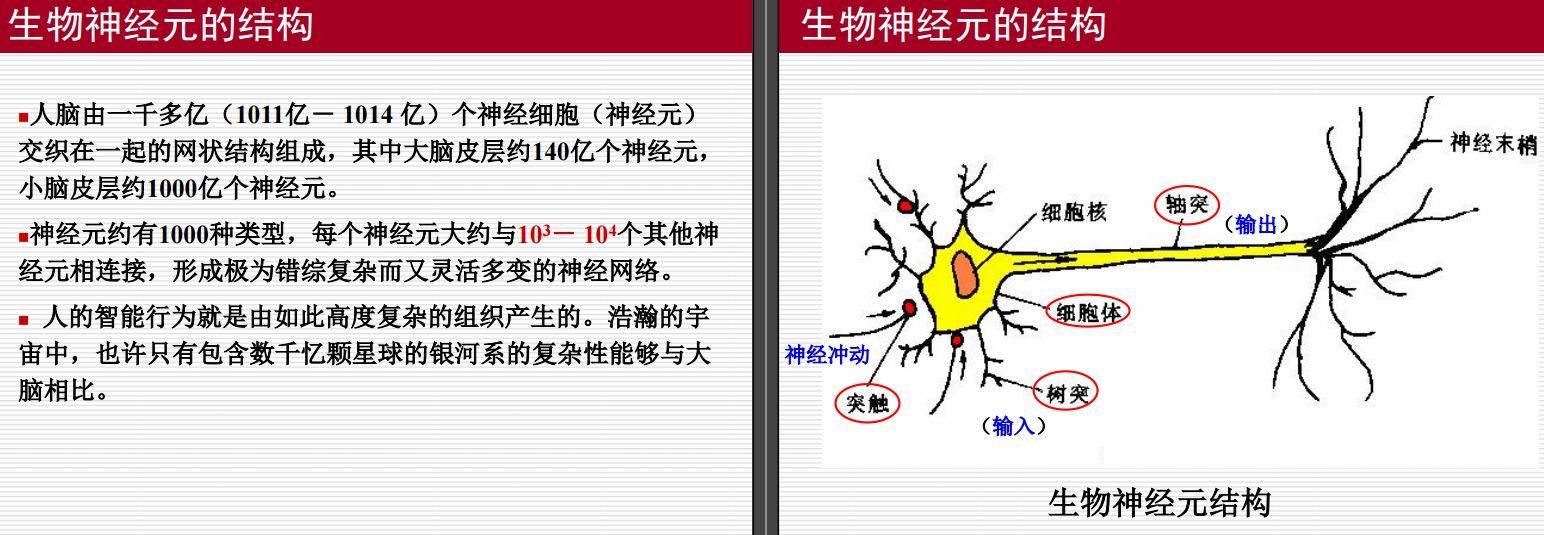
上述四张ppt老师讲的比较少,我觉得应该不是重点,大部分的内容在高中也是学习过的。
下面开始步入正题:
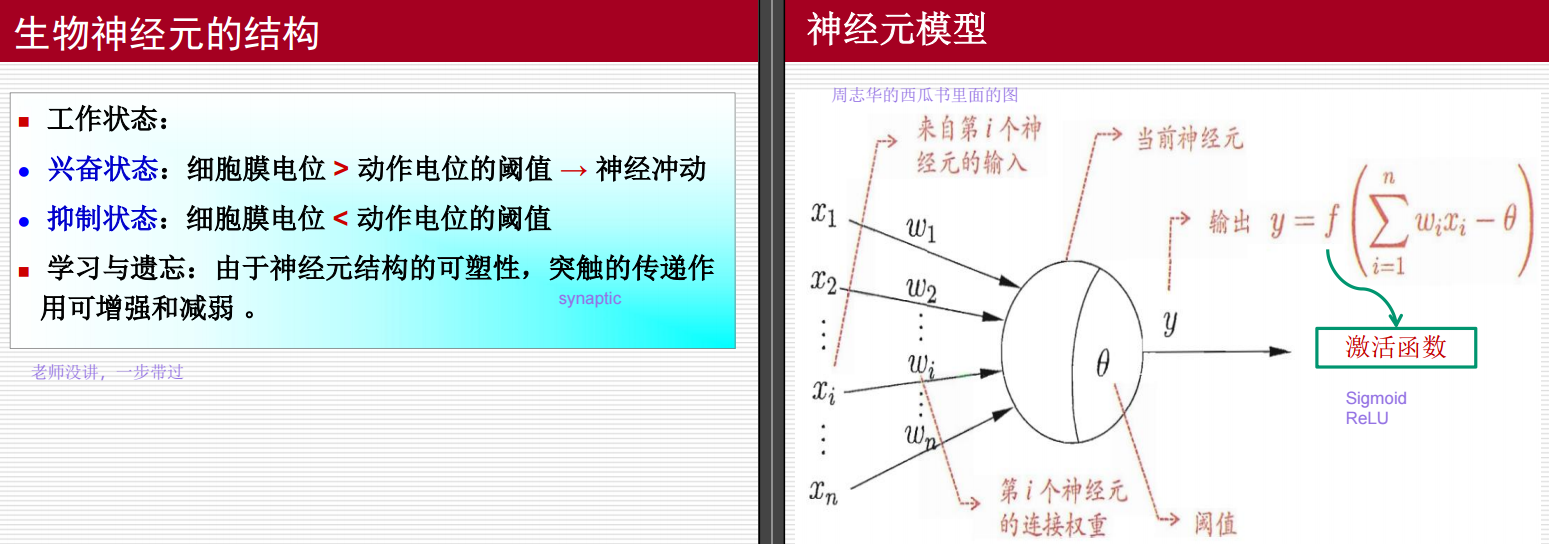
首先介绍了神经元模型中的激活函数: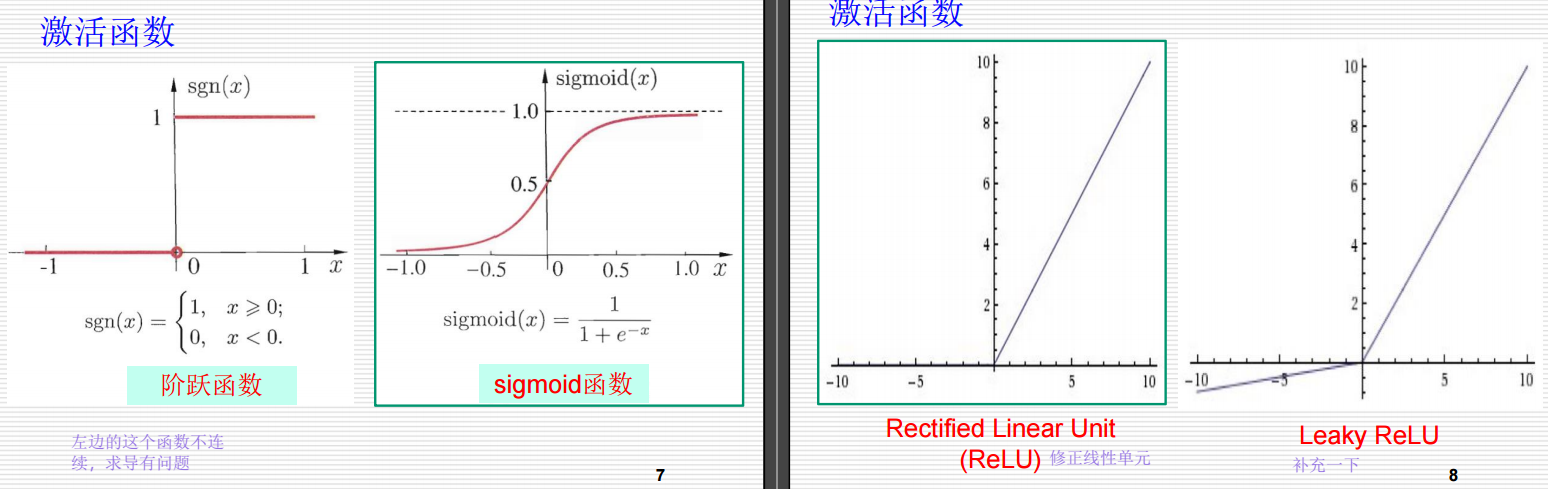
Rectified Linear Unit(修正线性单元),通常简写为ReLU,是人工神经网络中常用的一种激活函数。它的定义非常简单:对于输入x,如果x大于0,则输出x;如果x小于等于0,则输出0。用数学公式表示就是f(x) = max(0, x)。
ReLU函数由于其实现简单、计算效率高,并且能够有效缓解传统sigmoid和tanh等激活函数在深层网络训练过程中常见的梯度消失问题,因此在深度学习领域得到了广泛应用。不过,ReLU也有其缺点,比如可能导致某些神经元永远不被激活(即“死亡ReLUs”问题),针对这一问题,后来又出现了ReLU的变体,如Leaky ReLU、Parametric ReLU等,它们试图通过不同的方式解决这个问题。
神经网络的结构与工作方式
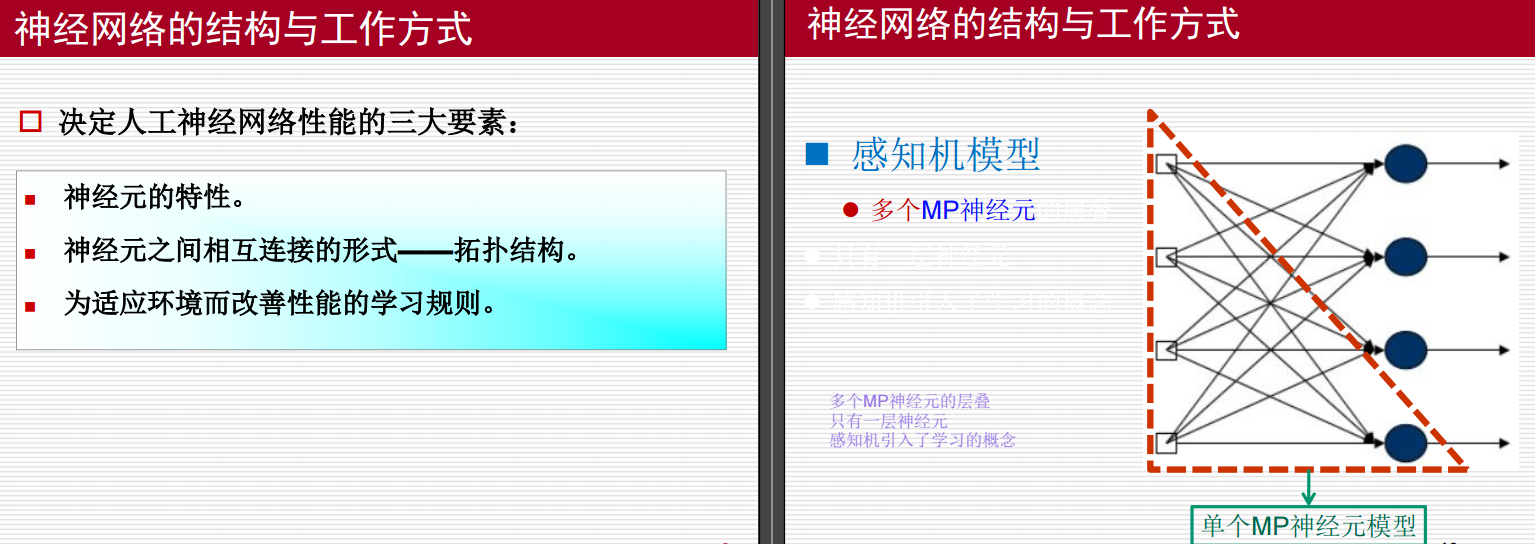
对于上图涉及到的文字,做出如下说明:
-
多个MP神经元的层叠:
- MP神经元指的是McCulloch-Pitts神经元模型,它是早期的人工神经元模型之一。这个模型由Warren McCulloch和Walter Pitts在1943年提出,是现代人工神经网络的基础。
- 当提到“多个MP神经元的层叠”时,这实际上是指构建一个具有多层结构的人工神经网络。每层包含多个这样的神经元(节点),它们接收来自前一层的输入,并将处理后的结果传递给下一层。这种层叠的方式能够增加网络的深度,从而允许它学习更复杂的模式。
-
只有一层神经元:
- 这里的描述可能是在指单层感知机(Single-layer Perceptron)。单层感知机是一种仅包含输入层和输出层(没有隐藏层)的线性分类器。它的功能有限,只能解决线性可分的问题,即可以用一条直线(在二维情况下)或超平面(在多维情况下)分开的数据集问题。
-
感知机引入了学习的概念:
- 感知机是由Frank Rosenblatt在1957年提出的,它不仅是一个简单的线性分类模型,而且引入了通过训练数据自动调整权重的学习算法。这意味着感知机可以通过一系列的训练样本来优化其内部参数(权重),以提高对新数据进行正确分类的能力。这是机器学习中非常重要的一个里程碑,因为它首次展示了如何让机器从数据中“学习”。

单层感知机的工作原理
单层感知机通过学习确定一个决策边界(即上述提到的直线、平面或超平面),该边界用于区分不同的类别。对于给定的输入向量 xxx,感知机计算其与权重向量 www 的内积加上偏置 bbb:f(x)=w⋅x+bf(x)=w \cdot x + bf(x)=w⋅x+b。如果 f(x)f(x)f(x) 大于某个阈值,则预测为一类;否则,预测为另一类。
为什么只能解决线性可分的问题?
因为单层感知机仅使用线性组合(即加权和)加上一个简单的激活函数来做出决策,所以它本质上是在寻找一个线性的决策边界。这意味着它只能处理那些能够用线性方式分割的数据集。一旦数据集中的类别不能被任何线性边界清晰地分开(即非线性可分),单层感知机就无法正确地对所有样本进行分类。
关于上述内容,做如下说明:
给定训练数据集,单层感知机的权重 wiw_iwi 与阈值 θ\thetaθ 可以很容易通过学习得到。
这句话的意思是,在给定一组训练数据后,单层感知机可以通过学习算法调整其权重 wiw_iwi 和阈值 θ\thetaθ,以优化分类性能。
在单层感知机中,神经元的阈值 θ\thetaθ 可看作一个固定输入为 -1 的“哑结点”所对应的连接权重 wm+1w_{m+1}wm+1,这样,权重和阈值的学习就统一为权值的学习了。
在单层感知机中,阈值 θ\thetaθ 可以被视为一个特殊的权重 wm+1w_{m+1}wm+1,它对应于一个固定的输入值为 -1 的“哑结点”。这意味着阈值可以被包含在权重向量中,从而简化了权重更新的过程。
数学上,假设输入向量为 x=[x1,x2,…,xm]x = [x_1, x_2, \dots, x_m]x=[x1,x2,…,xm],则加上阈值后的权重向量可以表示为
w=[w1,w2,…,wm,wm+1]w = [w_1, w_2, \dots, w_m, w_{m+1}]w=[w1,w2,…,wm,wm+1],其中 wm+1w_{m+1}wm+1 对应于阈值 θ\thetaθ。输入向量也相应地扩展为 x′=[x1,x2,…,xm,−1]x' = [x_1, x_2, \dots, x_m, -1]x′=[x1,x2,…,xm,−1],这样权重更新就可以统一处理。
对训练样例 (x,y)(x, y)(x,y),若当前感知机的输出为 y^\hat{y}y^,则感知机权重调整规则为:wi←wi+Δwiw_i \leftarrow w_i + \Delta w_iwi←wi+Δwi,其中 Δwi=l(y−y^)xi\Delta w_i = l (y - \hat{y}) x_iΔwi=l(y−y^)xi。
这里描述的是权重更新的规则。对于每个训练样本 (x,y)(x, y)(x,y),感知机的预测输出为 y^\hat{y}y^,如果预测错误(即 y≠y^y \neq \hat{y}y=y^),则需要调整权重。
更新规则如下:wi←wi+Δwiw_i \leftarrow w_i + \Delta w_iwi←wi+Δwi其中,Δwi=l(y−y^)xi\Delta w_i = l (y - \hat{y}) x_iΔwi=l(y−y^)xi
- lll 是学习率,通常是一个介于 0 和 1 之间的值,用于控制权重更新的速度。
- yyy 是实际标签。
- y^\hat{y}y^ 是感知机的预测输出。
- xix_ixi 是输入特征向量中的第 iii 个元素。
假定损失函数是平方误差函数,即:L=12(y−y^)2L = \frac{1}{2} (y - \hat{y})^2L=21(y−y^)2
广义上的损失函数是用来衡量模型预测值与真实值之间的差异的。对于单层感知机,常用的损失函数是平方误差函数,因为它简单且易于计算梯度。
若感知机对训练样例 (x,y)(x, y)(x,y) 预测正确,则感知机不发生变化;否则根据错误程度进行权重的调整。
如果感知机对某个训练样本的预测是正确的(即 y=y^y = \hat{y}y=y^),那么权重不需要更新。如果预测错误(即 y≠y^y \neq \hat{y}y=y^),则根据错误的程度(y−y^y - \hat{y}y−y^)调整权重。
对于为啥是上面这样计算的,下面给出一定的解释说明:
感知机的权重更新可以看作是一个简单的梯度下降过程。假设损失函数为平方误差函数:
L=12(y−y^)2L = \frac{1}{2} (y - \hat{y})^2L=21(y−y^)2我们希望最小化这个损失函数。根据梯度下降法,权重的更新方向应该是损失函数对权重 wiw_iwi 的偏导数的负方向:
Δwi=−l⋅∂L∂wi\Delta w_i = -l \cdot \frac{\partial L}{\partial w_i}Δwi=−l⋅∂wi∂L
计算偏导数:
首先,感知机的输出为:y^=f(w⋅x+b)\hat{y} = f(w \cdot x + b)y^=f(w⋅x+b)其中 fff 是激活函数(如阶跃函数)。
假设激活函数暂时忽略(或简化为线性激活),则误差对权重的偏导数为:
∂L∂wi=∂L∂y^⋅∂y^∂wi\frac{\partial L}{\partial w_i} = \frac{\partial L}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial w_i}∂wi∂L=∂y^∂L⋅∂wi∂y^
∂L∂y^=−(y−y^)\frac{\partial L}{\partial \hat{y}} = -(y - \hat{y})∂y^∂L=−(y−y^)
∂y^∂wi=xi\frac{\partial \hat{y}}{\partial w_i} = x_i∂wi∂y^=xi (因为 y^=w⋅x+b\hat{y} = w \cdot x + by^=w⋅x+b)
因此:Δwi=l(y−y^)xi\Delta w_i = l (y - \hat{y}) x_iΔwi=l(y−y^)xi
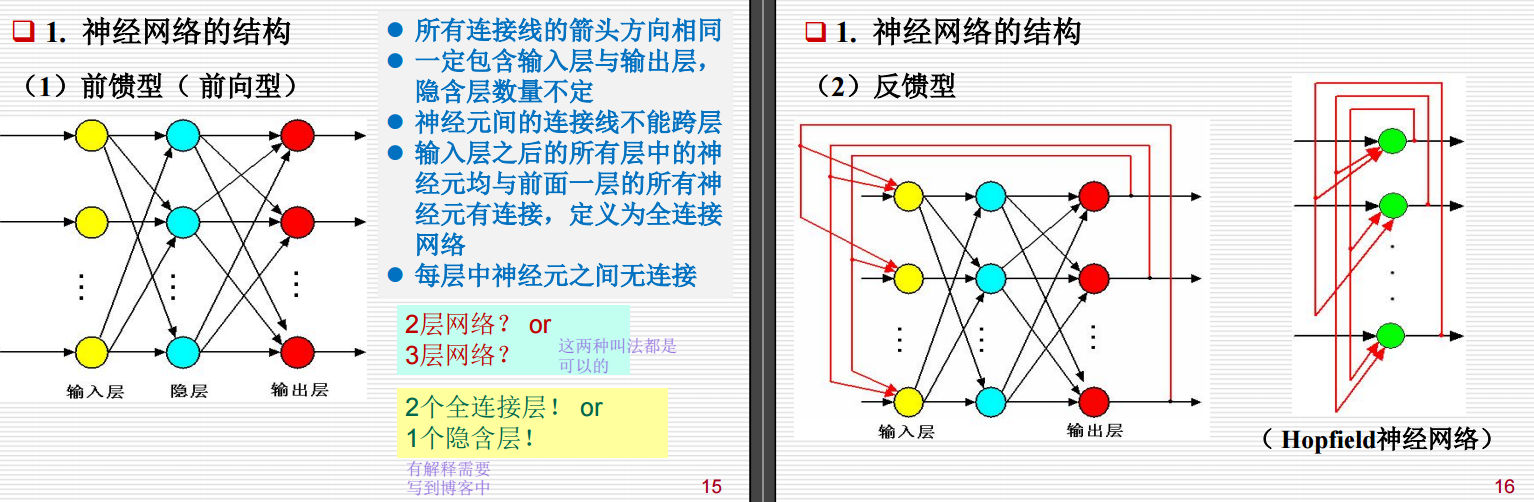
对于上述左边的图,这四种叫法都是可以的,只是从不同的角度来叫的:
-
2层网络 vs 3层网络:
- 图中显示了输入层、隐含层和输出层。
- 如果将输入层和输出层算作一层,则可以称为“3层网络”。
- 如果只计算实际处理数据的层(即隐含层),则可以认为是“2层网络”。
- 文字说明中提到:“这两种叫法都是可以的”,因此两种说法都正确。
-
2个全连接层 vs 1个隐含层:
- 全连接层是指每一层的神经元与前一层的所有神经元都有连接。
- 在图中,输入层到隐含层以及隐含层到输出层都是全连接的,因此可以说有“2个全连接层”。
- 隐含层只有一个,所以也可以说有“1个隐含层”。
- 这两种说法从不同角度描述了网络结构,因此也是正确的。
-
2层网络:
- 这种说法通常包括输入层、隐含层(或多个隐含层)以及输出层。也就是说,从结构上讲,每一层都被计算在内。因此,在你的例子中,如果考虑到输入层、一个隐含层和输出层,整个网络可以被描述为一个“3层网络”。
-
3层网络:
- 另一方面,有时候输入层不被视为网络的一层,尤其是在描述网络的深度时。这是因为输入层实际上并不执行任何转换操作;它只是数据进入网络的地方。基于这个观点,只有实际进行计算的层(即隐含层和输出层)才被计入网络的层数。因此,在你的例子中,如果仅考虑执行计算的层,则该网络可以被描述为一个“2层网络”,即一个隐含层加上一个输出层。
- 另一方面,有时候输入层不被视为网络的一层,尤其是在描述网络的深度时。这是因为输入层实际上并不执行任何转换操作;它只是数据进入网络的地方。基于这个观点,只有实际进行计算的层(即隐含层和输出层)才被计入网络的层数。因此,在你的例子中,如果仅考虑执行计算的层,则该网络可以被描述为一个“2层网络”,即一个隐含层加上一个输出层。
两层网络(线性模型)
对于一个简单的两层网络(即没有隐含层,只有输入层和输出层),我们可以将其视为一个线性分类器。假设输入为 x∈Rnx \in \mathbb{R}^nx∈Rn,权重向量为 w∈Rnw \in \mathbb{R}^nw∈Rn,偏置项为 bbb,则该模型的决策函数可以表示为:
f(x)=w⋅x+b f(x) = w \cdot x + b f(x)=w⋅x+b这里的点积 w⋅xw \cdot xw⋅x 表示权重向量和输入向量的内积。
如果 f(x)>0f(x) > 0f(x)>0,我们预测类别为1;如果 f(x)<0f(x) < 0f(x)<0,则预测类别为-1(或0,取决于二分类问题的具体设定)。这实际上定义了一个超平面 w⋅x+b=0w \cdot x + b = 0w⋅x+b=0 作为决策边界。因此,任何仅使用线性组合的模型只能生成线性的决策边界。
三层网络(包含非线性激活函数的模型)
当我们在网络中加入至少一个隐含层,并且每个神经元都应用非线性激活函数时,模型的表达能力会大大增强。考虑一个简单的三层网络,其结构包括输入层、一个隐含层和输出层。设输入为 x∈Rnx \in \mathbb{R}^nx∈Rn,隐含层有 mmm 个神经元,每个神经元都有自己的权重向量 Wi∈RnW_i \in \mathbb{R}^nWi∈Rn 和偏置项 bib_ibi,以及一个非线性激活函数 g(⋅)g(\cdot)g(⋅),如Sigmoid函数或ReLU函数等。
对于隐含层的第 iii 个神经元,其输出可以表示为:hi=g(Wi⋅x+bi) h_i = g(W_i \cdot x + b_i) hi=g(Wi⋅x+bi)最终输出层的决策函数可以写成所有隐含层神经元输出的加权和:
f(x)=∑i=1mvihi+c=∑i=1mvig(Wi⋅x+bi)+c f(x) = \sum_{i=1}^m v_i h_i + c = \sum_{i=1}^m v_i g(W_i \cdot x + b_i) + c f(x)=i=1∑mvihi+c=i=1∑mvig(Wi⋅x+bi)+c这里 viv_ivi 是连接隐含层到输出层的权重,ccc 是输出层的偏置项。
由于使用了非线性激活函数 g(⋅)g(\cdot)g(⋅),这个模型不再是一个简单的线性模型。它能够模拟更复杂的函数关系,从而实现任意形状的决策边界。理论上,只要隐含层足够宽(即 mmm 足够大),这种三层网络可以逼近任何连续函数(通用逼近定理)。
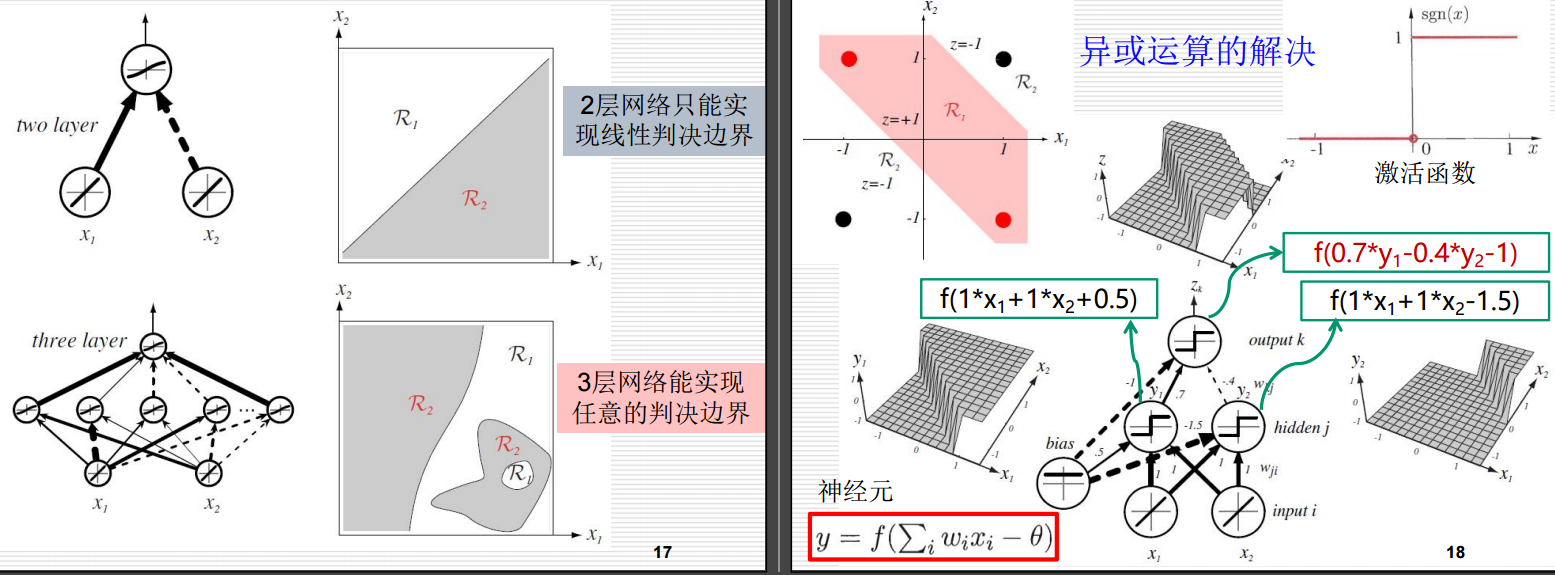
对于右侧的图片
1.异或运算的决策边界
在左上角的图像中,我们看到四个点:两个红色点和两个黑色点,分别表示不同的类别。这些点分布在二维平面上,坐标分别为 (0,0), (0,1), (1,0) 和 (1,1),对应于异或运算的四种情况。可以看到,用一条直线无法将这两类点分开,因此这是一个非线性可分的问题。
2.激活函数
右上角的图像展示了一个常见的激活函数——符号函数(sign function),记为 sgn(x)\text{sgn}(x)sgn(x)。该函数定义如下:sgn(x)={1if x>0−1if x<0\text{sgn}(x) = \begin{cases} 1 & \text{if } x > 0 \\-1 & \text{if } x < 0 \end{cases}sgn(x)={1−1if x>0if x<0 这个函数用于将神经元的加权输入转换为输出值。
3.神经元模型
中间部分展示了单个神经元的计算过程。每个神经元的输出 yyy 可以通过以下公式计算:
y=f(∑iwixi−θ)y = f\left(\sum_{i} w_i x_i - \theta\right)y=f(∑iwixi−θ)
其中,wiw_iwi 是权重,xix_ixi 是输入,θ\thetaθ 是偏置项,f(⋅)f(\cdot)f(⋅) 是激活函数。
4.三层神经网络结构
在中间下方的图像中,我们可以看到一个三层神经网络的具体结构:
- 输入层:有两个节点 x1x_1x1 和 x2x_2x2,分别对应输入变量。
- 隐藏层:有两个节点 y1y_1y1 和 y2y_2y2,它们的计算公式分别为:
y1=f(1⋅x1+1⋅x2+0.5)y_1 = f(1 \cdot x_1 + 1 \cdot x_2 + 0.5)y1=f(1⋅x1+1⋅x2+0.5)
y2=f(1⋅x1+1⋅x2−1.5)y_2 = f(1 \cdot x_1 + 1 \cdot x_2 - 1.5)y2=f(1⋅x1+1⋅x2−1.5) - 输出层:有一个节点 zkz_kzk,其计算公式为:
zk=f(0.7⋅y1−0.4⋅y2−1)z_k = f(0.7 \cdot y_1 - 0.4 \cdot y_2 - 1)zk=f(0.7⋅y1−0.4⋅y2−1)
5.决策面的形成
在左侧的三维图像中,展示了隐藏层神经元 y1y_1y1 和 y2y_2y2 的决策面。这两个决策面共同作用,使得最终的输出层能够实现对异或问题的正确分类。
神经网络学习算法

上述定理的证明比较难,有兴趣的可以去看看相关文章。
L₂型连续函数通常指的是在某个定义域内(图中是 [0,1]n[0,1]^n[0,1]n)的函数,其平方积分是有限的。更具体地说,对于一个函数 f:[0,1]n→Rmf: [0,1]^n \to \mathbb{R}^mf:[0,1]n→Rm 被称为 L₂函数,如果它满足以下条件∫[0,1]n∥f(x)∥2dx<∞ \int_{[0,1]^n} \|f(x)\|^2 dx < \infty ∫[0,1]n∥f(x)∥2dx<∞这里,∥f(x)∥\|f(x)\|∥f(x)∥ 表示向量值函数 f(x)f(x)f(x) 的欧几里得范数(即 f(x)f(x)f(x) 在 Rm\mathbb{R}^mRm 空间中的长度),而积分是对整个定义域 [0,1]n[0,1]^n[0,1]n 进行的。
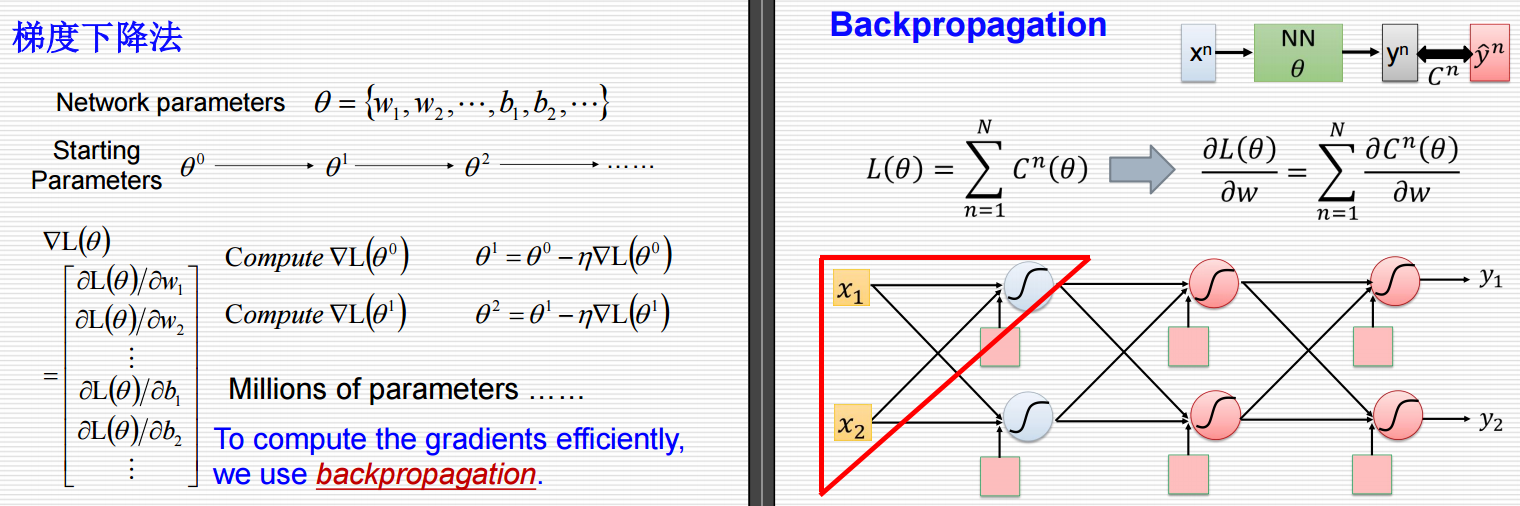 左侧:梯度下降法
左侧:梯度下降法
1.网络参数:
网络的参数集合表示为 θ={w1,w2,⋯ ,b1,b2,⋯ }\theta = \{w_1, w_2, \cdots, b_1, b_2, \cdots\}θ={w1,w2,⋯,b1,b2,⋯},其中 wiw_iwi 表示权重,bib_ibi 表示偏置。
2.起始参数:
训练过程从一组初始参数 θ0\theta^0θ0 开始,然后通过迭代更新参数到 θ1,θ2,⋯\theta^1, \theta^2, \cdotsθ1,θ2,⋯。
3. 损失函数的梯度:
损失函数 L(θ)L(\theta)L(θ) 对于参数 θ\thetaθ 的梯度定义为:
∇L(θ)=[∂L(θ)∂w1∂L(θ)∂w2⋮∂L(θ)∂b1∂L(θ)∂b2⋮] \nabla L(\theta) = \begin{bmatrix} \frac{\partial L(\theta)}{\partial w_1} \\ \frac{\partial L(\theta)}{\partial w_2} \\ \vdots \\ \frac{\partial L(\theta)}{\partial b_1} \\ \frac{\partial L(\theta)}{\partial b_2} \\ \vdots \end{bmatrix} ∇L(θ)=
∂w1∂L(θ)∂w2∂L(θ)⋮∂b1∂L(θ)∂b2∂L(θ)⋮
这个梯度向量包含了所有参数对损失函数的偏导数。
4. 参数更新:
在每次迭代中,使用梯度下降法更新参数:
θk+1=θk−η∇L(θk) \theta^{k+1} = \theta^k - \eta \nabla L(\theta^k) θk+1=θk−η∇L(θk)
其中 η\etaη 是学习率,控制着每次更新的步长。
5. 高效计算梯度:
- 由于神经网络可能包含数百万个参数,直接计算梯度会非常耗时。因此,需要使用反向传播算法来高效地计算这些梯度。
右侧:反向传播(Backpropagation)
1.损失函数:
总损失函数 L(θ)L(\theta)L(θ) 定义为所有样本损失 Cn(θ)C^n(\theta)Cn(θ) 的总和:
L(θ)=∑n=1NCn(θ) L(\theta) = \sum_{n=1}^{N} C^n(\theta) L(θ)=n=1∑NCn(θ)
2. 梯度计算:
使用链式法则计算损失函数关于权重 www 的梯度:
∂L(θ)∂w=∑n=1N∂Cn(θ)∂w \frac{\partial L(\theta)}{\partial w} = \sum_{n=1}^{N} \frac{\partial C^n(\theta)}{\partial w} ∂w∂L(θ)=n=1∑N∂w∂Cn(θ)
3. 神经网络结构:
图中展示了一个简单的神经网络结构,输入层有 x1x_1x1 和 x2x_2x2,隐藏层有多个节点,输出层有 y1y_1y1 和 y2y_2y2。
红色箭头表示反向传播的方向,即从输出层向输入层传递误差信号,用于计算各层参数的梯度。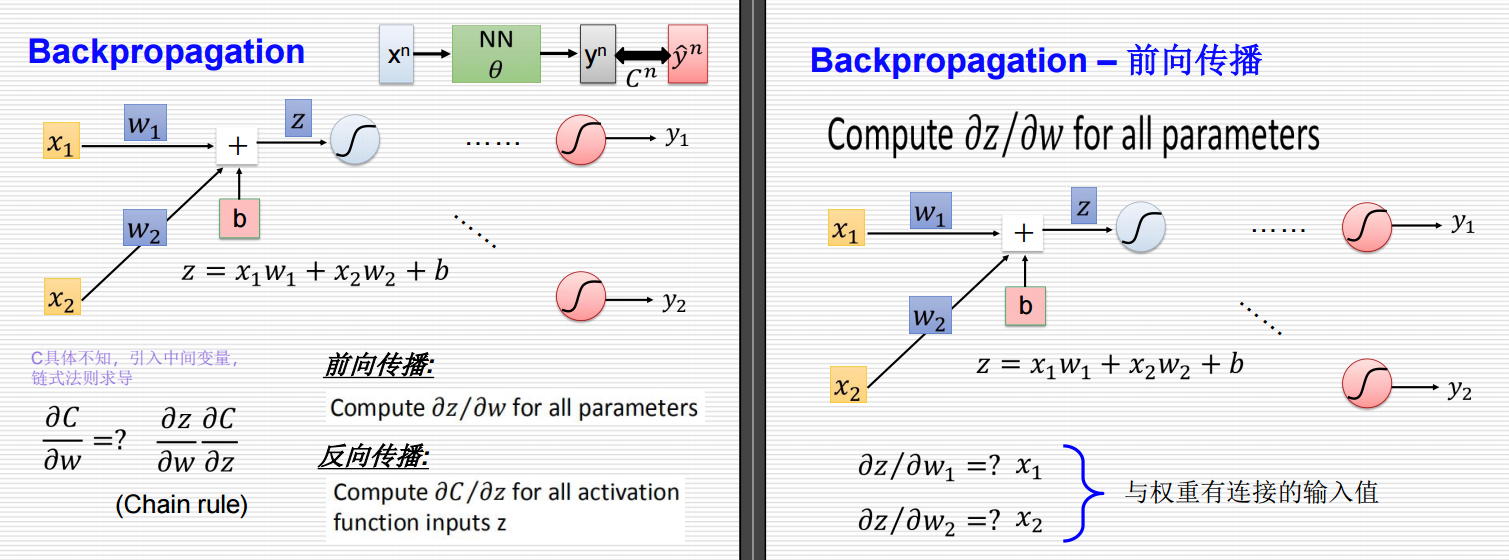
左侧:反向传播概述
1.神经网络结构:
输入层有 x1x_1x1 和 x2x_2x2,权重为 w1w_1w1 和 w2w_2w2,偏置为 bbb。
隐藏层有一个节点 zzz,通过激活函数 σ\sigmaσ 输出 y1y_1y1 和 y2y_2y2。
2. 前向传播:
计算隐藏层的输入 zzz: z=x1w1+x2w2+b z = x_1 w_1 + x_2 w_2 + b z=x1w1+x2w2+b通过激活函数 σ\sigmaσ 得到输出 y1y_1y1 和 y2y_2y2。
3. 损失函数:
损失函数 CCC 具体形式未知,但可以通过链式法则求导。
4. 梯度计算:
使用链式法则计算损失函数关于权重 www 的梯度:
∂C∂w=∂z∂w∂C∂z \frac{\partial C}{\partial w} = \frac{\partial z}{\partial w} \frac{\partial C}{\partial z} ∂w∂C=∂w∂z∂z∂C
右侧:前向传播与梯度计算
1.计算 ∂z∂w\frac{\partial z}{\partial w}∂w∂z 对所有参数:
对于权重 w1w_1w1 和 w2w_2w2,分别计算 ∂z∂w1\frac{\partial z}{\partial w_1}∂w1∂z 和 ∂z∂w2\frac{\partial z}{\partial w_2}∂w2∂z。
2. 具体计算:
∂z∂w1=x1\frac{\partial z}{\partial w_1} = x_1∂w1∂z=x1,因为 z=x1w1+x2w2+bz = x_1 w_1 + x_2 w_2 + bz=x1w1+x2w2+b,所以对 w1w_1w1 求导得到 x1x_1x1。
∂z∂w2=x2\frac{\partial z}{\partial w_2} = x_2∂w2∂z=x2,同理,对 w2w_2w2 求导得到 x2x_2x2。
3. 总结:
与权重有连接的输入值直接作为 ∂z∂w\frac{\partial z}{\partial w}∂w∂z 的结果。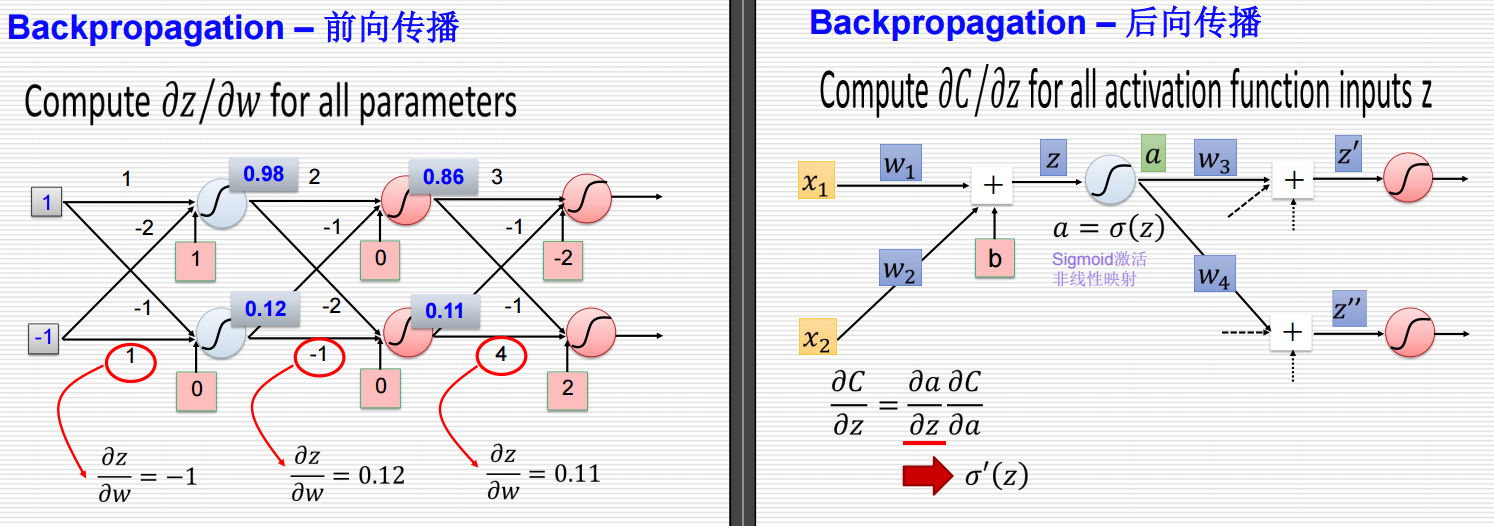
Backpropagation – 前向传播
计算 ∂z∂w\frac{\partial z}{\partial w}∂w∂z 对所有参数
图解说明
- 输入层:两个输入节点 x1x_1x1 和 x2x_2x2。
- 隐藏层:两个隐藏节点,每个节点通过激活函数(假设为sigmoid函数)进行非线性变换。
- 权重和偏置:每个连接都有一个权重值,例如 w1,w2,…w_1, w_2, \ldotsw1,w2,…,以及一个偏置值 bbb。
数学公式
-
计算隐藏层的输入 zzz:
z=x1w1+x2w2+b z = x_1 w_1 + x_2 w_2 + b z=x1w1+x2w2+b -
激活函数:
a=σ(z) a = \sigma(z) a=σ(z)
其中 σ(z)\sigma(z)σ(z) 是sigmoid函数,定义为:
σ(z)=11+e−z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1 -
梯度计算:
- 对于每个权重 wiw_iwi,计算 ∂z∂wi\frac{\partial z}{\partial w_i}∂wi∂z:
∂z∂wi=xi \frac{\partial z}{\partial w_i} = x_i ∂wi∂z=xi - 例如,在图中:
∂z∂w1=x1=1 \frac{\partial z}{\partial w_1} = x_1 = 1 ∂w1∂z=x1=1
∂z∂w2=x2=−1 \frac{\partial z}{\partial w_2} = x_2 = -1 ∂w2∂z=x2=−1
- 对于每个权重 wiw_iwi,计算 ∂z∂wi\frac{\partial z}{\partial w_i}∂wi∂z:
Backpropagation – 后向传播
计算 ∂C∂z\frac{\partial C}{\partial z}∂z∂C 对所有激活函数输入 zzz
图解说明
- 输出层:一个输出节点 yyy。
- 损失函数:假设为 CCC。
- 权重和偏置:每个连接都有一个权重值,例如 w3,w4w_3, w_4w3,w4,以及一个偏置值 bbb。
数学公式
-
计算输出层的输入 z′z'z′: z′=aw3+b z' = a w_3 + b z′=aw3+b
-
激活函数:
y=σ(z′) y = \sigma(z') y=σ(z′) -
损失函数:
C=Loss(y,y^) C = \text{Loss}(y, \hat{y}) C=Loss(y,y^) -
梯度计算:
- 计算 ∂C∂z′\frac{\partial C}{\partial z'}∂z′∂C:
∂C∂z′=∂C∂y⋅∂y∂z′ \frac{\partial C}{\partial z'} = \frac{\partial C}{\partial y} \cdot \frac{\partial y}{\partial z'} ∂z′∂C=∂y∂C⋅∂z′∂y
其中 ∂y∂z′=σ′(z′)\frac{\partial y}{\partial z'} = \sigma'(z')∂z′∂y=σ′(z′) 是sigmoid函数的导数:
σ′(z′)=σ(z′)(1−σ(z′)) \sigma'(z') = \sigma(z')(1 - \sigma(z')) σ′(z′)=σ(z′)(1−σ(z′))
- 计算 ∂C∂z′\frac{\partial C}{\partial z'}∂z′∂C:
-
更新权重和偏置:
- 更新 w3w_3w3 和 bbb:
Δw3=−η∂C∂z′⋅a \Delta w_3 = -\eta \frac{\partial C}{\partial z'} \cdot a Δw3=−η∂z′∂C⋅a
Δb=−η∂C∂z′ \Delta b = -\eta \frac{\partial C}{\partial z'} Δb=−η∂z′∂C - 更新 w1w_1w1 和 w2w_2w2:
Δw1=−η∂C∂z′⋅w3⋅σ′(z)⋅x1 \Delta w_1 = -\eta \frac{\partial C}{\partial z'} \cdot w_3 \cdot \sigma'(z) \cdot x_1 Δw1=−η∂z′∂C⋅w3⋅σ′(z)⋅x1
Δw2=−η∂C∂z′⋅w3⋅σ′(z)⋅x2 \Delta w_2 = -\eta \frac{\partial C}{\partial z'} \cdot w_3 \cdot \sigma'(z) \cdot x_2 Δw2=−η∂z′∂C⋅w3⋅σ′(z)⋅x2
- 更新 w3w_3w3 和 bbb:
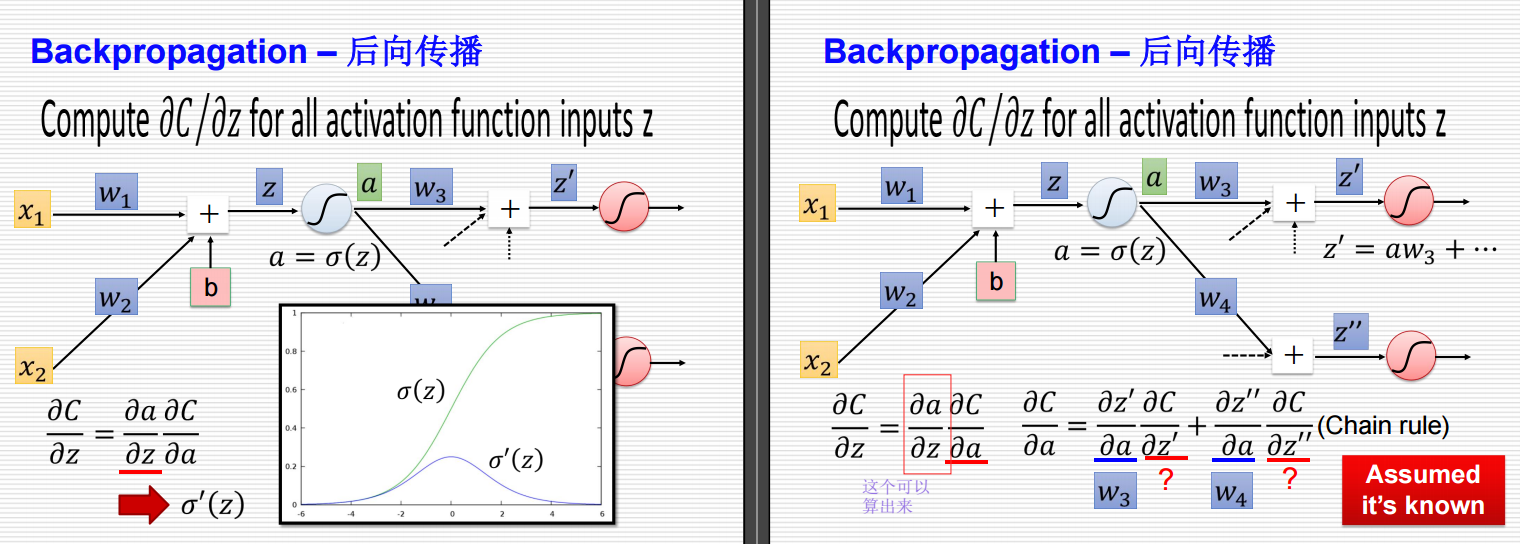

Backpropagation – 后向传播
计算 ∂C∂z\frac{\partial C}{\partial z}∂z∂C 对所有激活函数输入 zzz
左侧:前向传播
图解说明
- 输入层:两个输入节点 x1x_1x1 和 x2x_2x2。
- 隐藏层:一个隐藏节点 zzz,通过激活函数 σ(z)\sigma(z)σ(z) 输出 aaa。
- 输出层:两个输出节点 z′z'z′ 和 z′′z''z′′。
数学公式
-
计算隐藏层的输入 zzz:
z=x1w1+x2w2+b z = x_1 w_1 + x_2 w_2 + b z=x1w1+x2w2+b -
激活函数:
a=σ(z) a = \sigma(z) a=σ(z)
其中 σ(z)\sigma(z)σ(z) 是sigmoid函数,定义为:
σ(z)=11+e−z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1 -
计算输出层的输入 z′z'z′ 和 z′′z''z′′:
z′=aw3+b′ z' = a w_3 + b' z′=aw3+b′
z′′=aw4+b′′ z'' = a w_4 + b'' z′′=aw4+b′′
右侧:反向传播
图解说明
- 损失函数:假设为 CCC。
- 梯度计算:计算每个激活函数输入 zzz 的梯度 ∂C∂z\frac{\partial C}{\partial z}∂z∂C。
数学公式
-
计算梯度 ∂C∂z\frac{\partial C}{\partial z}∂z∂C:
∂C∂z=σ′(z)[w3∂C∂z′+w4∂C∂z′′] \frac{\partial C}{\partial z} = \sigma'(z) \left[ w_3 \frac{\partial C}{\partial z'} + w_4 \frac{\partial C}{\partial z''} \right] ∂z∂C=σ′(z)[w3∂z′∂C+w4∂z′′∂C]
其中 σ′(z)\sigma'(z)σ′(z) 是sigmoid函数的导数:
σ′(z)=σ(z)(1−σ(z)) \sigma'(z) = \sigma(z)(1 - \sigma(z)) σ′(z)=σ(z)(1−σ(z)) -
具体步骤:
- 计算 ∂C∂z′\frac{\partial C}{\partial z'}∂z′∂C 和 ∂C∂z′′\frac{\partial C}{\partial z''}∂z′′∂C:
∂C∂z′=链式法则 \frac{\partial C}{\partial z'} = \text{链式法则} ∂z′∂C=链式法则
∂C∂z′′=链式法则 \frac{\partial C}{\partial z''} = \text{链式法则} ∂z′′∂C=链式法则
- 计算 ∂C∂z′\frac{\partial C}{\partial z'}∂z′∂C 和 ∂C∂z′′\frac{\partial C}{\partial z''}∂z′′∂C:
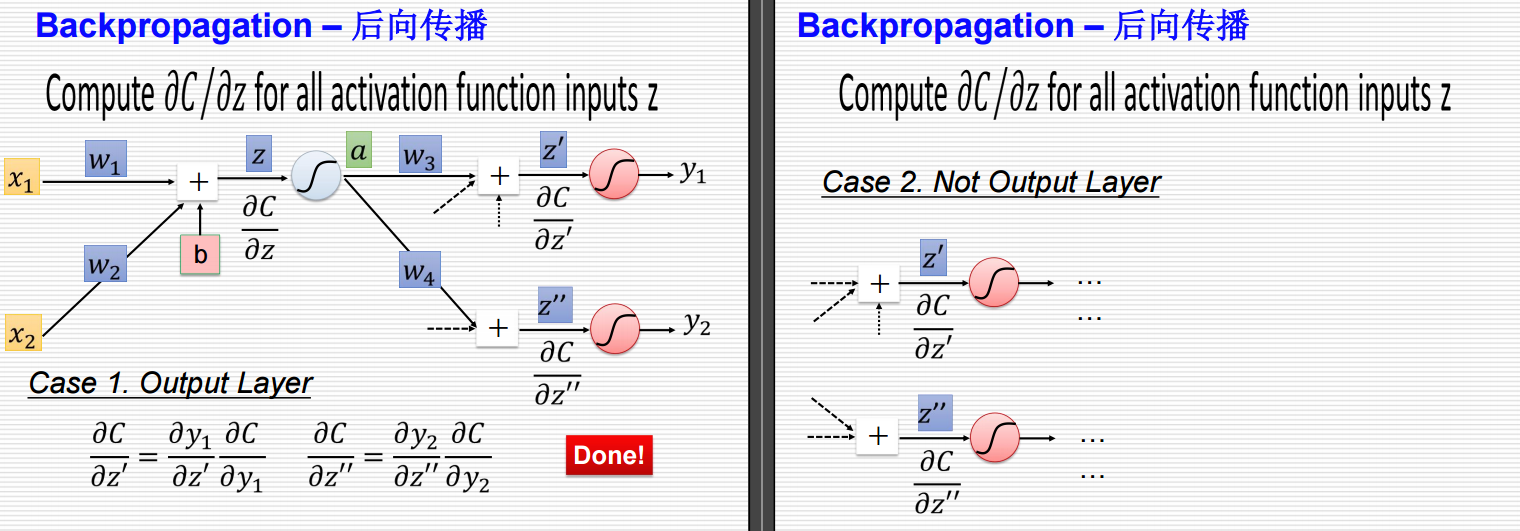
要是对于左侧输出层的情况,结果就直接出来了,要是该层还不是输出层的话,就还需要进行处理。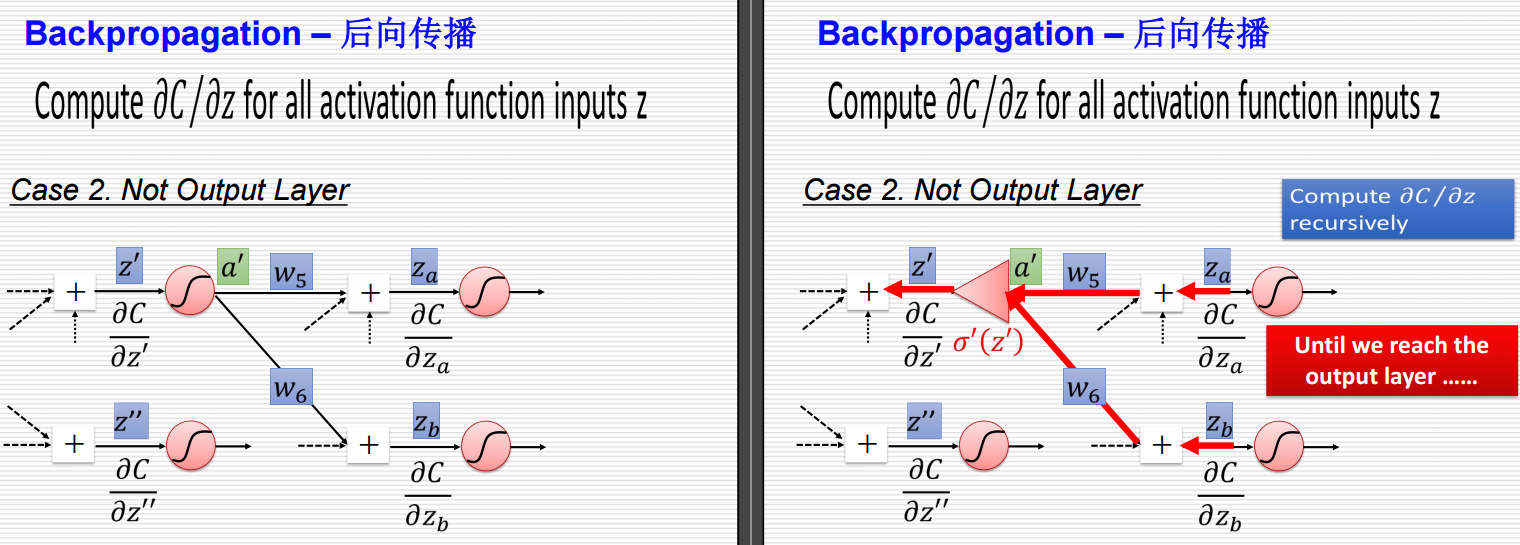
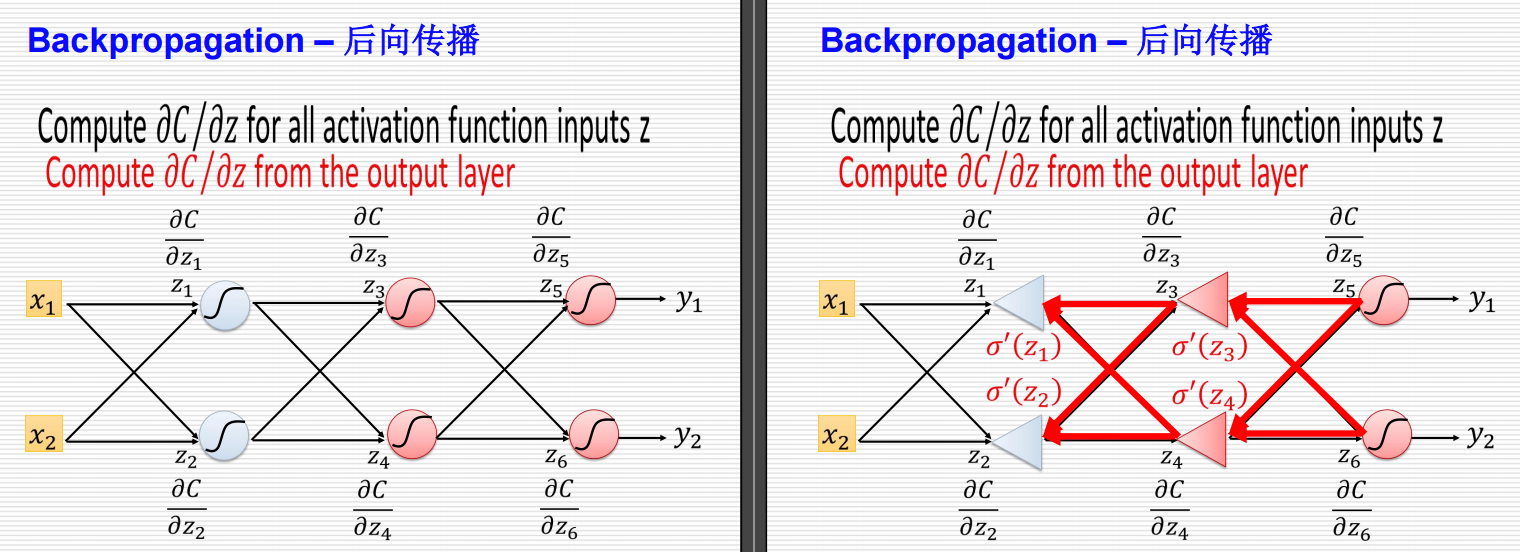
Backpropagation – 后向传播
计算 ∂C∂z\frac{\partial C}{\partial z}∂z∂C 对所有激活函数输入 zzz
左侧:前向传播
图解说明
- 输入层:两个输入节点 x1x_1x1 和 x2x_2x2。
- 隐藏层:两个隐藏节点 z1,z2z_1, z_2z1,z2 和 z3,z4z_3, z_4z3,z4。
- 输出层:两个输出节点 y1y_1y1 和 y2y_2y2。
数学公式
-
计算隐藏层的输入 zzz:
zi=∑jwijxj+bi z_i = \sum_{j} w_{ij} x_j + b_i zi=j∑wijxj+bi -
激活函数:
ai=σ(zi) a_i = \sigma(z_i) ai=σ(zi)
其中 σ(z)\sigma(z)σ(z) 是sigmoid函数,定义为:
σ(z)=11+e−z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1 -
计算输出层的输入 z′z'z′:
zi′=∑jwij′aj+bi′ z'_i = \sum_{j} w'_{ij} a_j + b'_i zi′=j∑wij′aj+bi′
右侧:反向传播
图解说明
- 损失函数:假设为 CCC。
- 梯度计算:计算每个激活函数输入 zzz 的梯度 ∂C∂z\frac{\partial C}{\partial z}∂z∂C。
数学公式
-
计算梯度 ∂C∂z\frac{\partial C}{\partial z}∂z∂C:
∂C∂zi=σ′(zi)[∑jwji′∂C∂zj′] \frac{\partial C}{\partial z_i} = \sigma'(z_i) \left[ \sum_{j} w'_{ji} \frac{\partial C}{\partial z'_j} \right] ∂zi∂C=σ′(zi)[j∑wji′∂zj′∂C]
其中 σ′(z)\sigma'(z)σ′(z) 是sigmoid函数的导数:
σ′(z)=σ(z)(1−σ(z)) \sigma'(z) = \sigma(z)(1 - \sigma(z)) σ′(z)=σ(z)(1−σ(z)) -
具体步骤:
- 计算 ∂C∂zj′\frac{\partial C}{\partial z'_j}∂zj′∂C:
∂C∂zj′=链式法则 \frac{\partial C}{\partial z'_j} = \text{链式法则} ∂zj′∂C=链式法则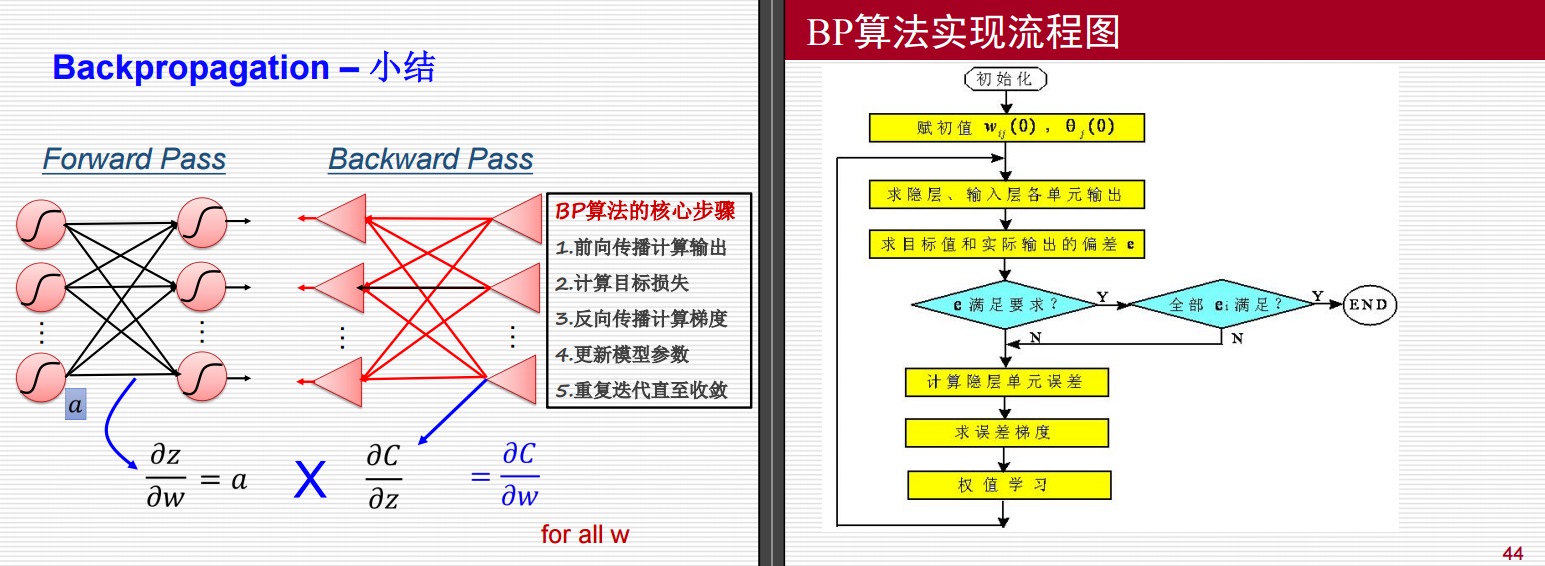
- 计算 ∂C∂zj′\frac{\partial C}{\partial z'_j}∂zj′∂C:
前向传播 (Forward Pass)
图解说明
- 输入层:两个输入节点 x1x_1x1 和 x2x_2x2。
- 隐藏层:两个隐藏节点 z1,z2z_1, z_2z1,z2 和 z3,z4z_3, z_4z3,z4。
- 输出层:两个输出节点 y1y_1y1 和 y2y_2y2。
数学公式
-
计算隐藏层的输入 zzz:
zi=∑jwijxj+bi z_i = \sum_{j} w_{ij} x_j + b_i zi=j∑wijxj+bi -
激活函数:
ai=σ(zi) a_i = \sigma(z_i) ai=σ(zi)
其中 σ(z)\sigma(z)σ(z) 是sigmoid函数,定义为:
σ(z)=11+e−z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1 -
计算输出层的输入 z′z'z′:
zi′=∑jwij′aj+bi′ z'_i = \sum_{j} w'_{ij} a_j + b'_i zi′=j∑wij′aj+bi′
后向传播 (Backward Pass)
图解说明
- 损失函数:假设为 CCC。
- 梯度计算:计算每个激活函数输入 zzz 的梯度 ∂C∂z\frac{\partial C}{\partial z}∂z∂C。
数学公式
-
计算梯度 ∂C∂z\frac{\partial C}{\partial z}∂z∂C:
∂C∂zi=σ′(zi)[∑jwji′∂C∂zj′] \frac{\partial C}{\partial z_i} = \sigma'(z_i) \left[ \sum_{j} w'_{ji} \frac{\partial C}{\partial z'_j} \right] ∂zi∂C=σ′(zi)[j∑wji′∂zj′∂C]
其中 σ′(z)\sigma'(z)σ′(z) 是sigmoid函数的导数:
σ′(z)=σ(z)(1−σ(z)) \sigma'(z) = \sigma(z)(1 - \sigma(z)) σ′(z)=σ(z)(1−σ(z)) -
具体步骤:
- 计算 ∂C∂zj′\frac{\partial C}{\partial z'_j}∂zj′∂C:
∂C∂zj′=链式法则 \frac{\partial C}{\partial z'_j} = \text{链式法则} ∂zj′∂C=链式法则
- 计算 ∂C∂zj′\frac{\partial C}{\partial z'_j}∂zj′∂C:
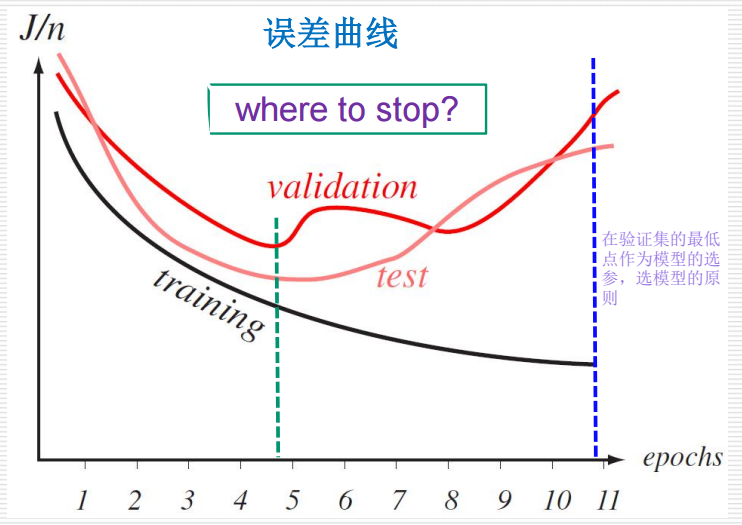
上图:
- 横轴 (epochs):表示训练的轮数(epoch),即模型在训练数据上迭代的次数。
- 纵轴 (J/n):表示平均损失函数值(J/n),通常用来衡量模型的预测误差。
曲线解释
-
训练集误差 (training):
- 随着训练轮数的增加,训练集的误差逐渐减小。
- 这是因为模型在不断学习训练数据,试图最小化训练集上的损失。
-
验证集误差 (validation):
- 在开始阶段,验证集的误差也随着训练轮数的增加而减小。
- 但在某个点之后,验证集的误差开始上升,这表明模型开始过拟合(overfitting),即模型在训练数据上表现很好,但在未见过的数据上表现不佳。
-
测试集误差 (test):
- 测试集的误差趋势与验证集相似,但通常比验证集稍高一些。
- 测试集用于评估模型在完全未见过的数据上的表现。
关键点
- 何时停止训练?:
- 根据图中的绿色框标注的“where to stop?”,最佳停止点通常是验证集误差最低的点。
- 在这个点之前,模型在验证集上的表现最好,这意味着模型泛化能力最强。
要确定模型在验证集上的最佳表现:
- 监控验证集误差,记录其变化。
- 使用早停法,在验证集误差不再改善时停止训练。
- 分析学习曲线,找到验证集误差最低的点。
- 利用自动化工具,简化监控和保存过程。
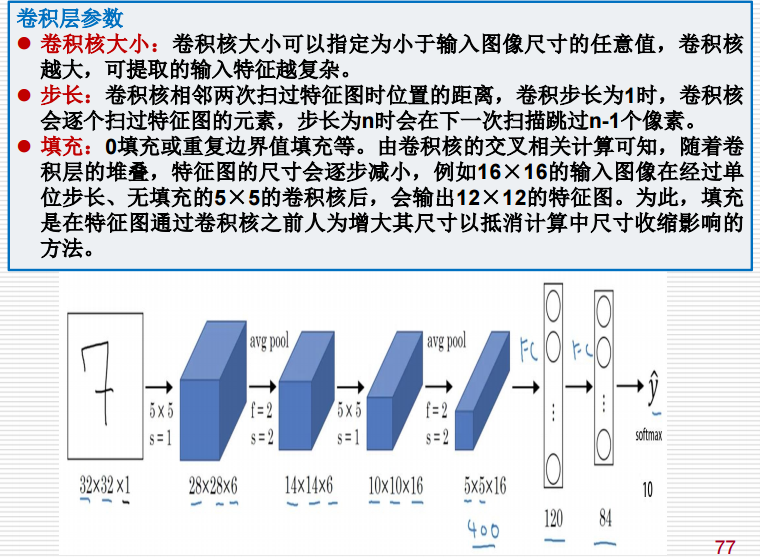
卷积神经网络
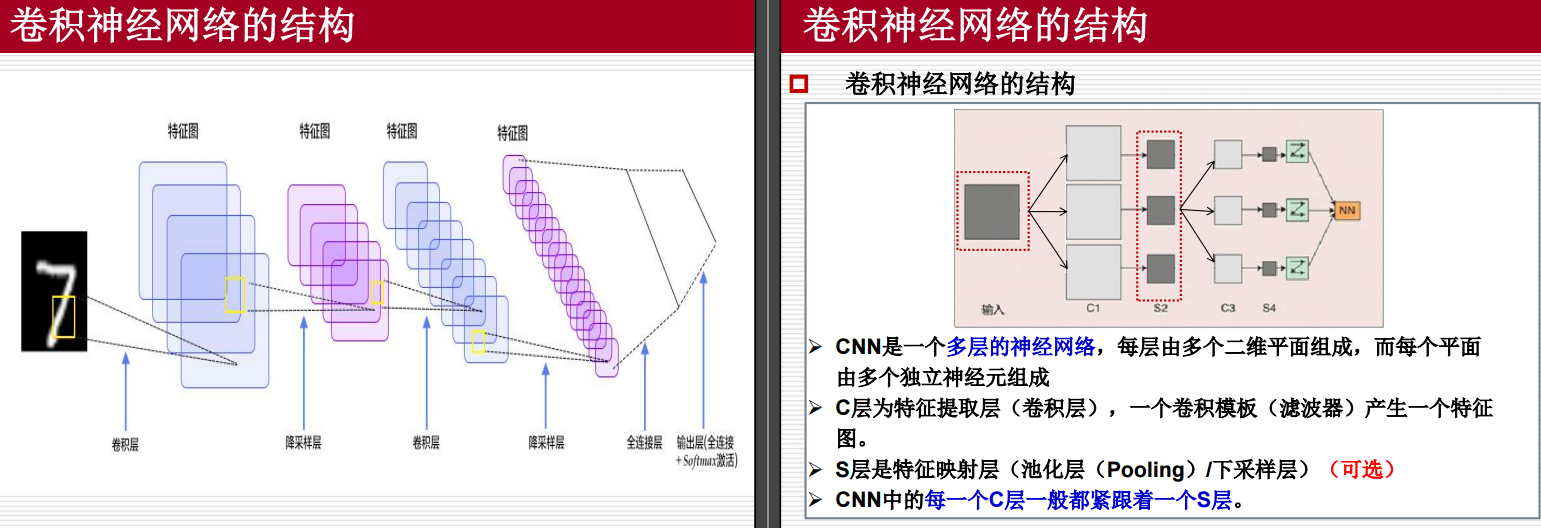
这里需要注意的是:卷积核(或滤波器)中的值是通过训练过程自动学习和确定的,而不是手动指定的
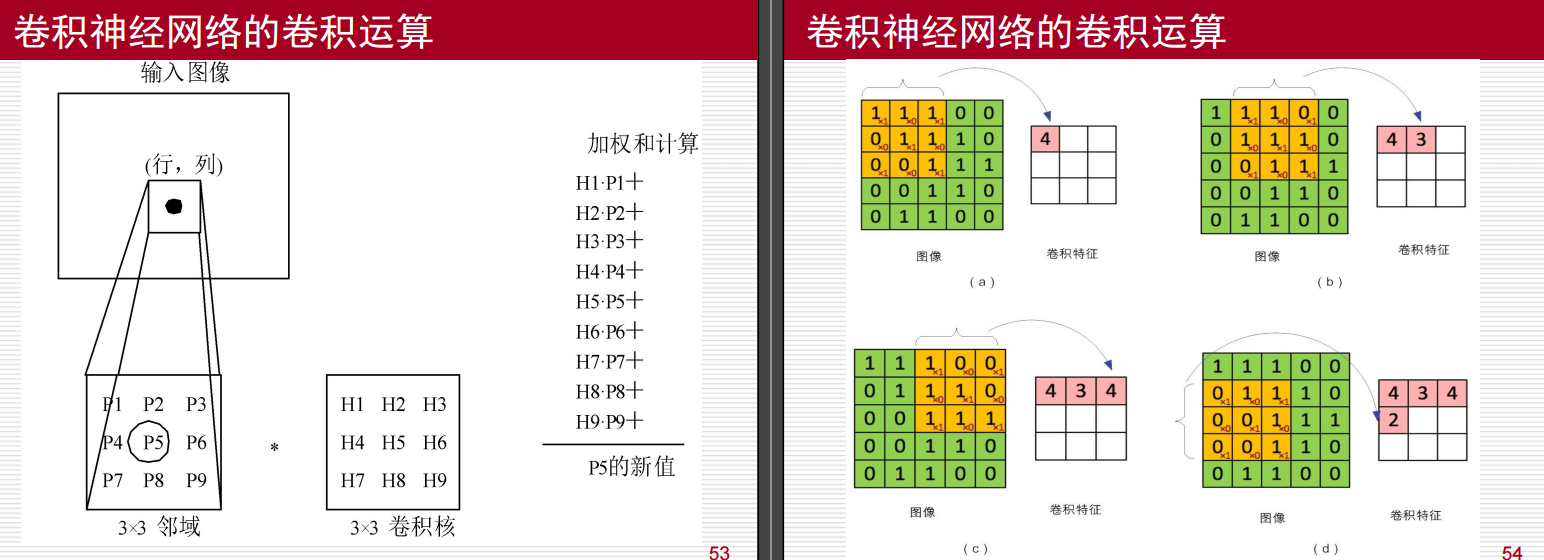
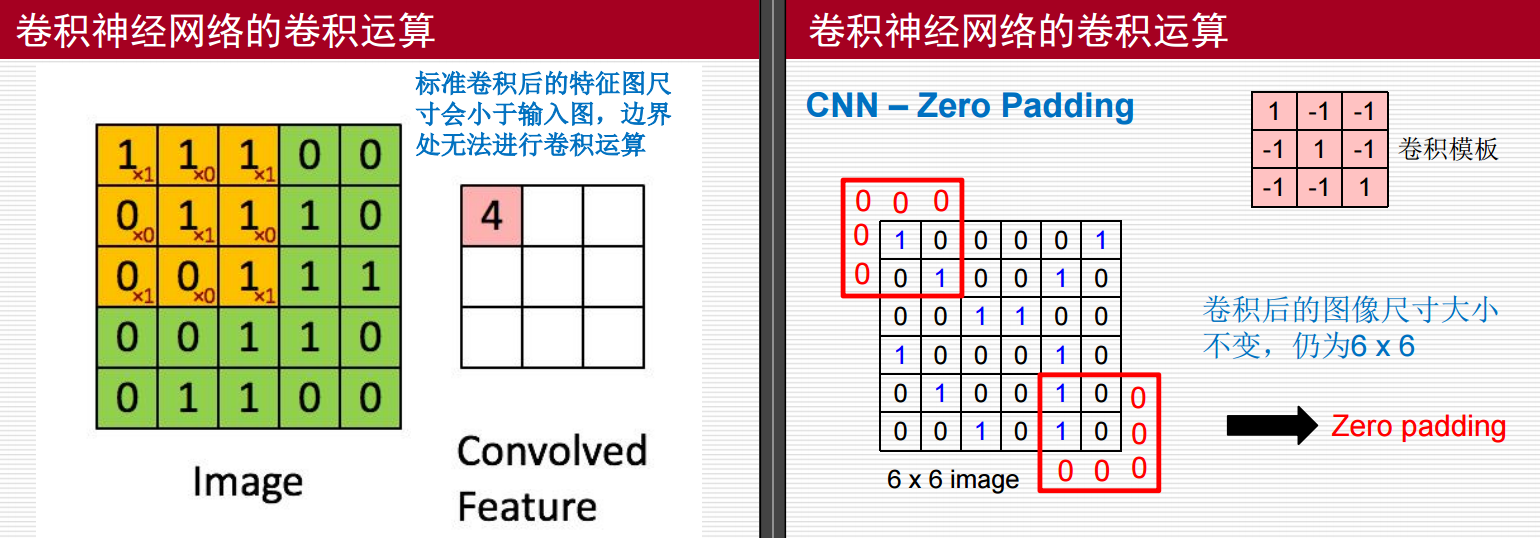
要是使用标准的卷积核的话,输出的图像尺寸是比原来的小的,要是不想这样的话,可以进行填充操作Padding(如上图右侧部分)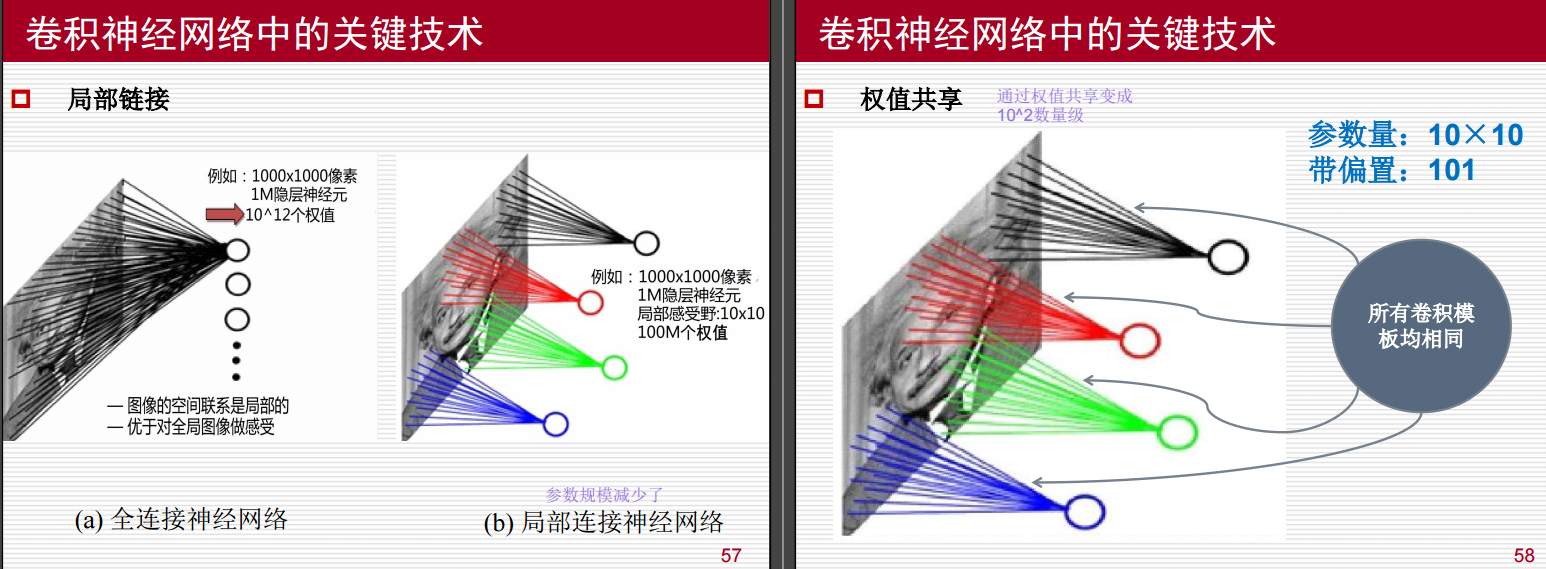
局部链接
全连接神经网络
- 特点:在全连接神经网络中,每个输入节点与所有输出节点之间都有直接的连接。
- 参数量巨大:例如,对于一个 1000×10001000 \times 10001000×1000 像素的图像和 1M1M1M 隐层神经元,需要 101210^{12}1012 个权值。这种巨大的参数量不仅计算复杂度高,而且容易导致过拟合。
局部连接神经网络
- 局部感受野:在局部连接神经网络中,每个输出节点只与输入图像中的局部区域相连,这个局部区域称为“局部感受野”。例如,一个 10×1010 \times 1010×10 的局部感受野意味着每个输出节点只与输入图像中的 10×1010 \times 1010×10 区域内的像素相连。
- 参数规模减少:通过局部链接,参数量显著减少。例如,对于同样的 1000×10001000 \times 10001000×1000 像素图像和 1M1M1M 隐层神经元,如果使用 10×1010 \times 1010×10 的局部感受野,则只需要 100M100M100M 个权值,大大减少了计算量和模型复杂度。
- 优势:局部链接更符合图像的空间联系是局部的特点,能够更好地捕捉图像中的局部特征,优于对全局图像做感受。
权值共享
- 定义:在卷积神经网络中,同一卷积核在不同位置上进行卷积操作时,其权重是相同的,这就是权值共享。
- 参数量进一步减少:通过权值共享,可以将参数量从 10810^8108 数量级减少到 10210^2102 数量级。例如,在一个 10×1010 \times 1010×10 的卷积核中,加上偏置项后,总共只有 10×10+1=10110 \times 10 + 1 = 10110×10+1=101 个参数。
- 所有卷积模板均相同:这意味着在整个图像的不同位置上,同一个卷积核会提取相似类型的特征,从而提高了模型的泛化能力。
- 示例:假设我们有一个 10×1010 \times 1010×10 的卷积核,它会在整个图像上滑动并进行卷积操作。无论在图像的哪个位置,该卷积核的权重都是相同的,这样就实现了权值共享。
全连接神经网络与卷积神经网络的区别与联系(maybe 考试)
区别
-
连接方式
- 全连接神经网络:每一层的每一个神经元都与下一层的所有神经元相连接。
- 卷积神经网络(CNN):采用局部连接和权值共享机制,使得每个神经元仅与其邻近的神经元相连,且相同类型的神经元共享相同的权值。
-
参数数量
- 全连接神经网络:由于每两个神经元之间的连接都需要单独的权重,因此参数数量随着网络层数和每层神经元数量的增加而急剧增长。
- 卷积神经网络(CNN):通过局部连接和权值共享,极大地减少了参数的数量,有助于降低过拟合并提高计算效率。
-
数据处理方式
- 全连接神经网络:通常需要将输入数据(如图像)展平成一维向量,忽略了数据本身的结构信息。
- 卷积神经网络(CNN):直接处理二维或三维的数据结构(如图像),保留了空间上的相关性,特别适合于处理具有网格结构的数据(如图像、语音等)。
-
适用场景
- 全连接神经网络:适用于处理较为简单的、不需要考虑数据内部结构的任务。
- 卷积神经网络(CNN):特别适用于处理复杂的、具有空间结构的数据,如图像识别、目标检测等领域。
联系
-
基础架构
- 无论是全连接神经网络还是卷积神经网络,它们的基础架构都是基于神经元和层次化的结构来构建的。两者都可以包含输入层、隐藏层和输出层。
-
训练方法
- 两种网络都依赖反向传播算法来进行训练,即通过最小化损失函数来调整网络参数。
-
应用场景扩展
- 在实际应用中,有时也会将全连接层和卷积层结合使用。例如,在一些深度学习模型中,先通过卷积层提取特征,再利用全连接层进行分类或其他任务。
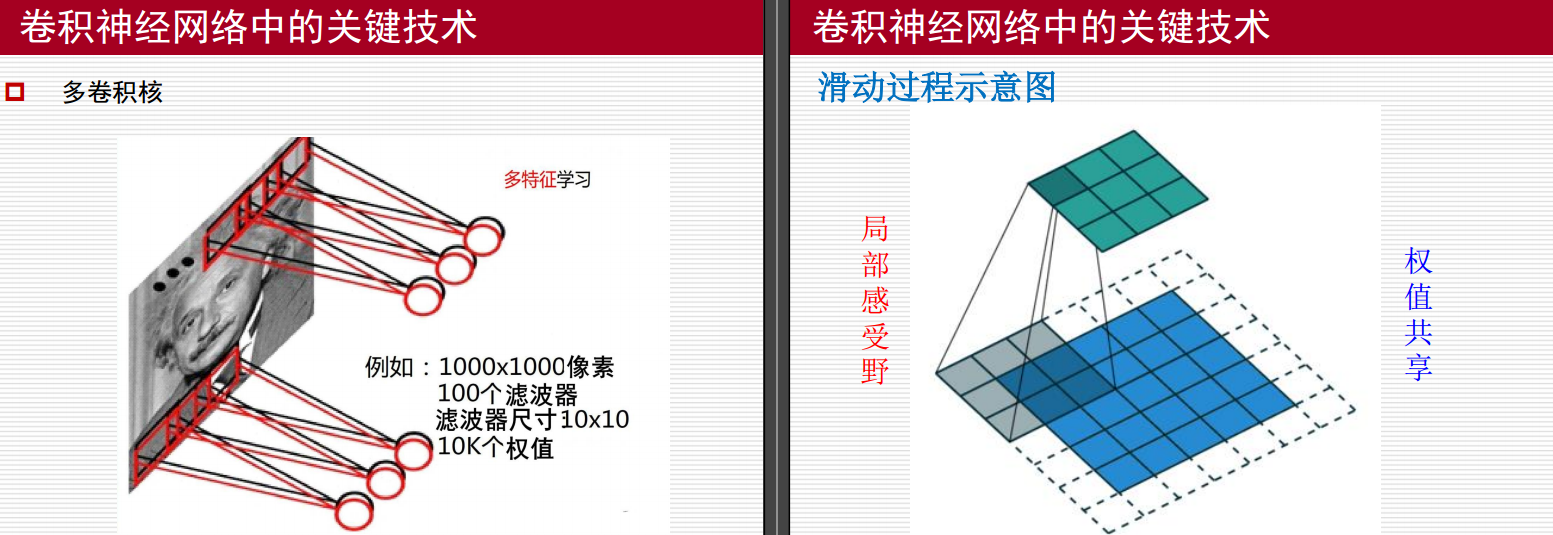
多卷积核
多特征学习
在卷积神经网络中,多卷积核用于从输入图像中提取多种不同的特征。每个卷积核可以看作是一个滤波器,它在图像上滑动并进行卷积操作,从而提取特定类型的特征。
示例
- 输入图像尺寸:1000x1000像素
- 滤波器数量:100个
- 滤波器尺寸:10x10
- 权值数量:10K个
每个滤波器会与输入图像的局部区域进行点乘运算,然后将结果相加得到一个输出值。通过多个滤波器,可以从图像的不同部分提取出多种特征,如边缘、纹理等。
滑动过程示意图
局部感受野
局部感受野是指每个神经元只与输入图像中的局部区域相连。这种设计使得神经元能够专注于图像的局部特征,而不是全局信息。例如,在一个10x10的滤波器中,每个神经元只与输入图像中的10x10区域内的像素相连。
权值共享
在卷积神经网络中,同一卷积核在不同位置上的权重是相同的,这就是权值共享。这种机制大大减少了参数的数量,降低了模型的复杂度,并且有助于提高模型的泛化能力。

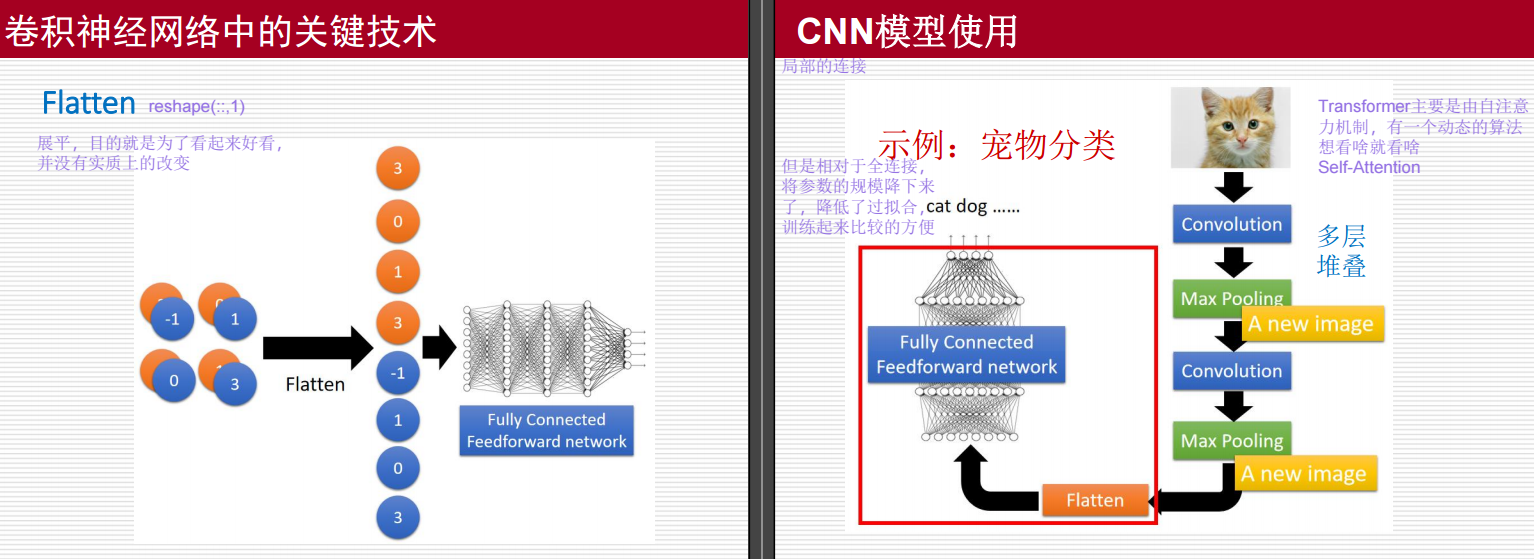
Flatten(展平)
-
定义:
- 展平操作将多维数据转换为一维向量,例如将一个 n×nn \times nn×n 的矩阵转换为长度为 n2n^2n2 的向量。
- 目的是为了方便后续的全连接层处理。虽然看起来只是形状上的改变,但并没有实质性的信息丢失。
-
示例:
- 假设输入是一个 2×22 \times 22×2 的矩阵,元素分别为 [−1,0],[1,3][-1, 0], [1, 3][−1,0],[1,3]。
- 经过 Flatten 操作后,得到一个一维向量 [−1,0,1,3][-1, 0, 1, 3][−1,0,1,3]。
- 这个一维向量可以作为全连接前馈网络(Fully Connected Feedforward Network)的输入。
全连接前馈网络
- 定义:
- 全连接层中的每个神经元都与上一层的所有神经元相连。
- 在图像分类等任务中,全连接层用于对特征进行综合分析和决策。


就是增加了两个通道,其余的感觉没啥变化。
关于 3D CNN 的相关知识,老师说不考,这里就不放上来了,有兴趣的自己去了解。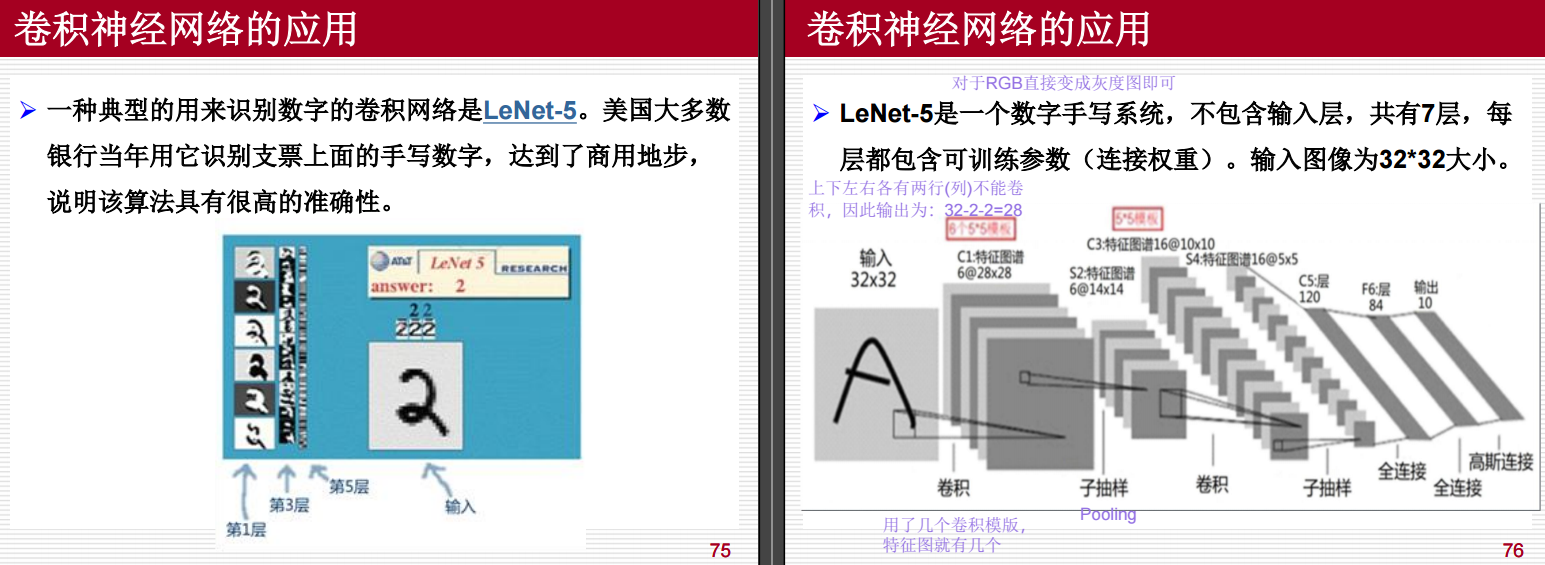
LeNet-5 的设计初衷是为了处理固定大小的输入图像,因此对 MNIST 数据集进行了零填充,将其从 28×28 扩展为 32×32。这样做的好处包括:
- 更好的适配卷积层的设计。
- 提高特征提取的灵活性。
- 但最终的特征图尺寸会随着网络的层数逐渐减小,直到适合全连接层的输入要求。
LeNet 中输入图像尺寸变化的解释
初始输入
- 输入图像大小为 32×3232 \times 3232×32(经过零填充后的 MNIST 图像)。
第一层卷积
- 卷积核大小:5×55 \times 55×5
- 步幅(stride):1
- 填充(padding):无(即 padding = 0)
根据卷积输出尺寸公式:
输出尺寸=输入尺寸−卷积核尺寸+2×填充步幅+1 \text{输出尺寸} = \frac{\text{输入尺寸} - \text{卷积核尺寸} + 2 \times \text{填充}}{\text{步幅}} + 1 输出尺寸=步幅输入尺寸−卷积核尺寸+2×填充+1对于 32×3232 \times 3232×32 的输入图像:
输出尺寸=32−5+2×01+1=28 \text{输出尺寸} = \frac{32 - 5 + 2 \times 0}{1} + 1 = 28 输出尺寸=132−5+2×0+1=28因此,第一层卷积后,特征图的尺寸从 32×3232 \times 3232×32 缩小为 28×2828 \times 2828×28。
第一层池化
- 池化窗口大小:2×22 \times 22×2
- 步幅(stride):2
根据池化输出尺寸公式:
输出尺寸=输入尺寸−池化窗口大小步幅+1 \text{输出尺寸} = \frac{\text{输入尺寸} - \text{池化窗口大小}}{\text{步幅}} + 1 输出尺寸=步幅输入尺寸−池化窗口大小+1对于 28×2828 \times 2828×28 的特征图:
输出尺寸=28−22+1=14 \text{输出尺寸} = \frac{28 - 2}{2} + 1 = 14 输出尺寸=228−2+1=14因此,第一层池化后,特征图的尺寸进一步缩小为 14×1414 \times 1414×14。
总结
- 输入图像从 32×3232 \times 3232×32 变为 28×2828 \times 2828×28 是由于 卷积层的操作 引起的。
- 后续的池化层则进一步缩小了特征图的尺寸,最终变为 14×1414 \times 1414×14。
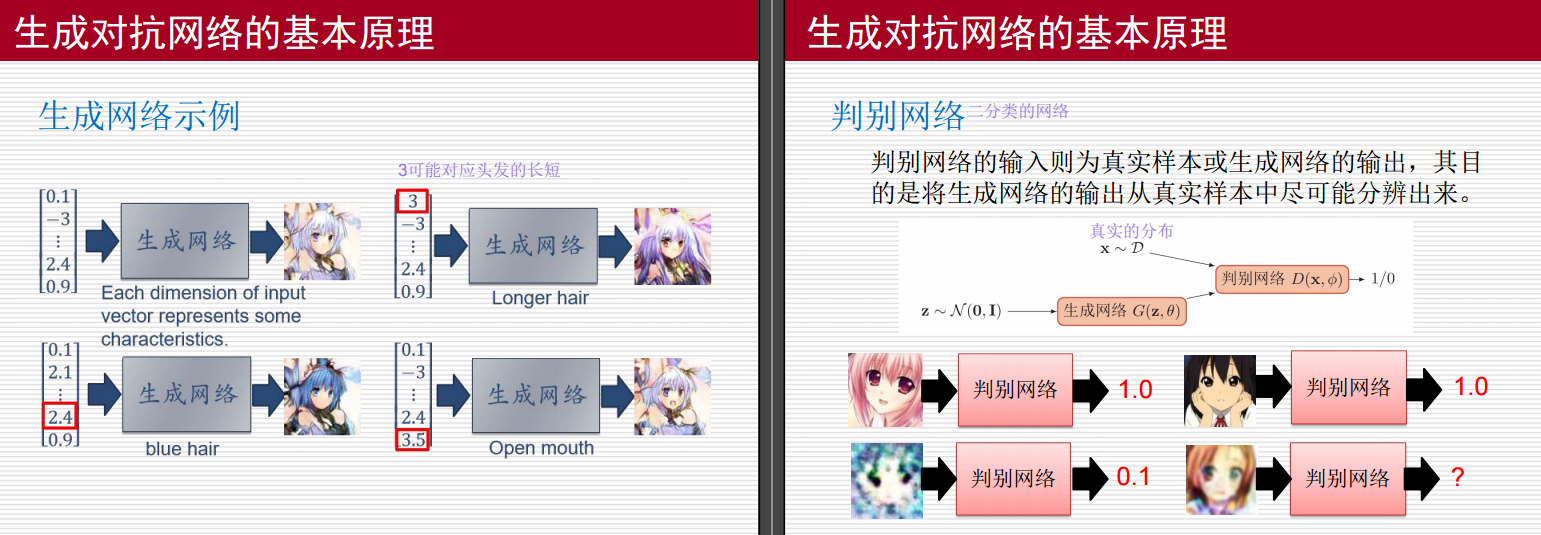
生成对抗网络及其应用

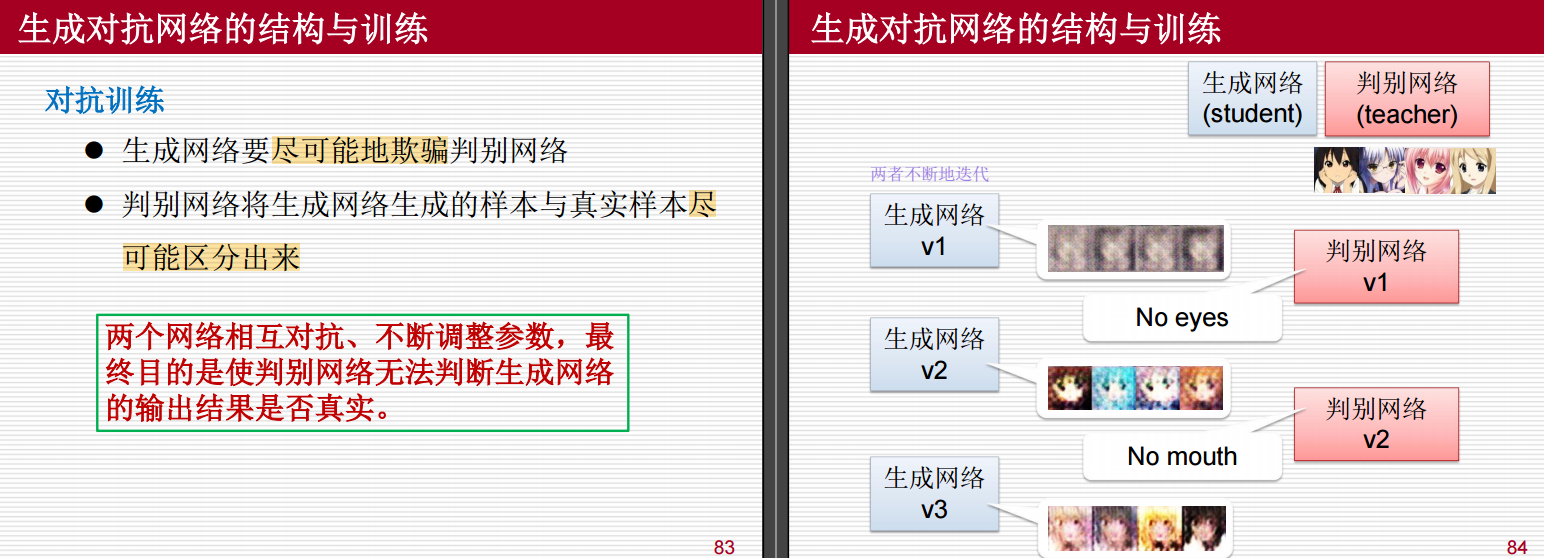







End

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)