导入大数据量多sheet的excel文件
excel导出
·
今天做大数据量导入数据库的操作
测试代码:
@Autowired
@Qualifier("threadPoolExecutor")
private ThreadPoolExecutor executorService;
@Test
public void readExcel(){
String fileName = "d:\\test.xlsx";
List<Callable<Object>> tasks = new ArrayList<>();
for (int i = 0;i<500;i++){
int num = i;
tasks.add(()->{
EasyExcel.read(fileName,Example.class,new ImportListener<Example>(iExampleService)).sheet(num).doRead();
return null;
});
}
try {
executorService.invokeAll(tasks);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
ImportListener.class
package com.example.admin.execl;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.read.listener.ReadListener;
import com.alibaba.excel.util.ListUtils;
import com.alibaba.fastjson2.JSON;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.baomidou.mybatisplus.extension.service.IService;
import com.example.admin.mapper.ExampleMapper;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.scheduling.annotation.Async;
import org.springframework.transaction.annotation.Transactional;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author yss
* @date 2023/3/3
*/
@Slf4j
@RequiredArgsConstructor
public class ImportListener<T> implements ReadListener<T> {
private final IService<T> iService;
/**
* 每隔10000条存储数据库,然后清理list ,方便内存回收
*/
private static final int BATCH_COUNT = 10000;
/**
* 缓存的数据
*/
// private List<T> cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
private ThreadLocal<List<T>> cachedDataList = ThreadLocal.withInitial(ArrayList::new);
private static AtomicInteger count = new AtomicInteger(0);
private final ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(100,
100,
60,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>());
// 1. 多线程批量读 2.转化为list 校验 3.多线程往数据库存
@Override
@Transactional(rollbackFor = Exception.class)
public void invoke(T entity, AnalysisContext analysisContext) {
// 在这做校验
cachedDataList.get().add(entity);
// 达到BATCH_COUNT了,需要去存储一次数据库,防止数据几万条数据在内存,容易OOM
if (cachedDataList.get().size() >= BATCH_COUNT) {
batchInsert();
// asyncBatchInsert();
}
}
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
batchInsert();
// asyncBatchInsert();
log.info("所有数据解析完成!");
}
public void batchInsert() {
if (!cachedDataList.get().isEmpty()){
log.info("第"+count.addAndGet(1)+"次插入"+cachedDataList.get().size()+"条数据");
iService.saveBatch(cachedDataList.get());
// 释放内存
cachedDataList.get().clear();
log.info("存储数据库成功!");
}
}
public void batchInsert(List<T> lists) {
log.info("lists大小:"+lists.size());
iService.saveBatch(lists);
log.info("第"+count.addAndGet(1)+"次插入"+lists.size()+"条数据");
lists.clear();
log.info("存储数据库成功!");
}
@Async
public void asyncBatchInsert() {
if (!cachedDataList.get().isEmpty()){
List<T> lists = new ArrayList<>(cachedDataList.get());
// 开启另外一个线程来批量插入数据库
threadPoolExecutor.submit(()->{
log.info("lists大小:"+lists.size());
iService.saveBatch(lists);
// log.info("第"+count.addAndGet(1)+"次插入"+lists.size()+"条数据");
// lists.clear();
// log.info("存储数据库成功!");
});
// 释放内存
cachedDataList.get().clear();
}
}
}
这里有一个问题: 多线程并发写入数据库时,发现无法存入数据库,也没有报任何错误,在这个调试上耗费了蛮多时间,故退而求其次,单线程写入。
多线程读取excel文档,然后每个线程把list数据插入数据库
结果:
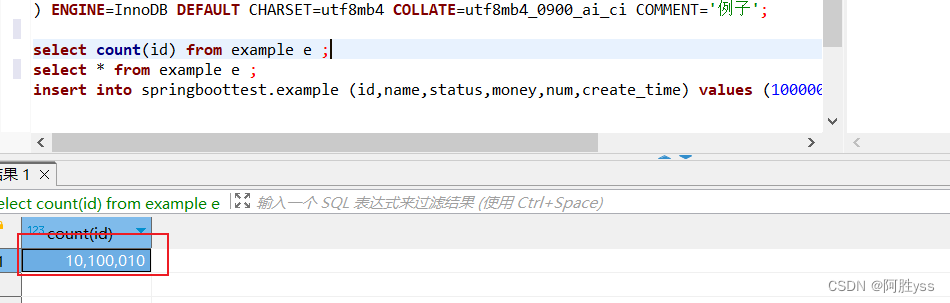
耗时大概100s左右,不错。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)