带你从入门到精通——机器学习(七. 特征降维)
七. 特征降维7.1 降维的含义特征对训练模型是非常重要的,但如果用于训练的数据集如果包含一些不重要的特征,则可能导致模型泛化性能不佳,例如:如果某些特征的取值较为接近,那么其所包含的信息也相对较少;如果两个特征的趋势同增同减、非常相关,那么它们不会给模型带来更多的信息。是指在某些限定条件下,降低特征个数,可以帮助我们有效地处理高维特征,防止维度灾难,属于,常用的方法有:低方差过滤法、主成分分析法
建议先阅读我之前的博客,掌握一定的机器学习前置知识后再阅读本文,链接如下:
带你从入门到精通——机器学习(一. 机器学习概述)-CSDN博客
带你从入门到精通——机器学习(二. KNN算法)-CSDN博客
带你从入门到精通——机器学习(三. 线性回归)-CSDN博客
带你从入门到精通——机器学习(四. 逻辑回归)-CSDN博客
带你从入门到精通——机器学习(六. 集成学习)-CSDN博客
目录
七. 特征降维
7.1 降维的含义
特征对训练模型是非常重要的,但如果用于训练的数据集如果包含一些不重要的特征,则可能导致模型泛化性能不佳,例如:如果某些特征的取值较为接近,那么其所包含的信息也相对较少;如果两个特征的趋势同增同减、非常相关,那么它们不会给模型带来更多的信息。
特征降维是指在某些限定条件下,降低特征个数,可以帮助我们有效地处理高维特征,防止维度灾难,属于无监督学习,常用的方法有:低方差过滤法、主成分分析法、相关系数法等等。
7.2 低方差过滤法
低方差过滤法是指删除方差低于某些阈值的一些特征,这是因为如果特征方差小,那么特征值的波动范围小,所包含的信息也少,模型很难学习到信息;如果特征方差大,特征值的波动范围大,包含的信息相对丰富,便于模型进行学习。
7.3 主成分分析法
主成分分析(Principal Component Analysis,PCA)法是指通过对数据维数进行压缩,在损失少量信息的前提下,尽可能降低原数据的维数(复杂度),是一种数据的压缩映射,降维后的数据不再与原数据一致。
PCA会把数据从原来的坐标系转换到新的坐标系,新坐标系的选择由数据本身决定,从数学层面理解,PCA的目标就是在高维数据中找到最大方差的几个方向,并将数据映射到一个维度 不大于原始数据的新的子空间上,子空间的坐标系必须为正交坐标系。
PCA 实际上是求一个投影矩阵P,用高维的原始数据乘以这个投影矩阵, 便可以将高维特征的维数下降到指定的维数,表达式如下:
![]()
第一个新坐标轴选择的是原始数据中方差最大的方向(也称第一主成分),第二个新坐标轴选择和第一个坐标轴正交且方差次大的方向(也称第二主成分)。此过程一直重复,重复次数最大为原始数据中特征的数目。
由于大部分方差都集中在最前面的几个新坐标轴中,因此,可以忽略余下的坐标轴,也就是对数据进行了降维处理。
那么,如何选取方差最大的几个新坐标轴呢?可以通过分析协方差矩阵选取。
协方差可以处理二维数据之间的相关性程度,如果是多维数据,就需要计算多个两两之间的协方差,用矩阵表示就是协方差矩阵,如下图所示:
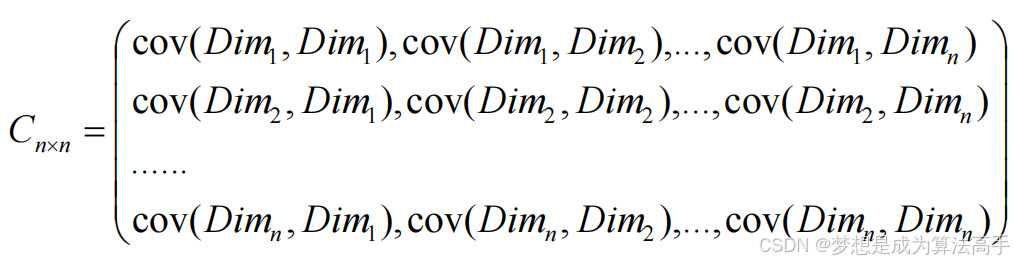
注意:协方差矩阵的对角元素即为各特征自身的方差;非对角元素即为两特征间的协方差。
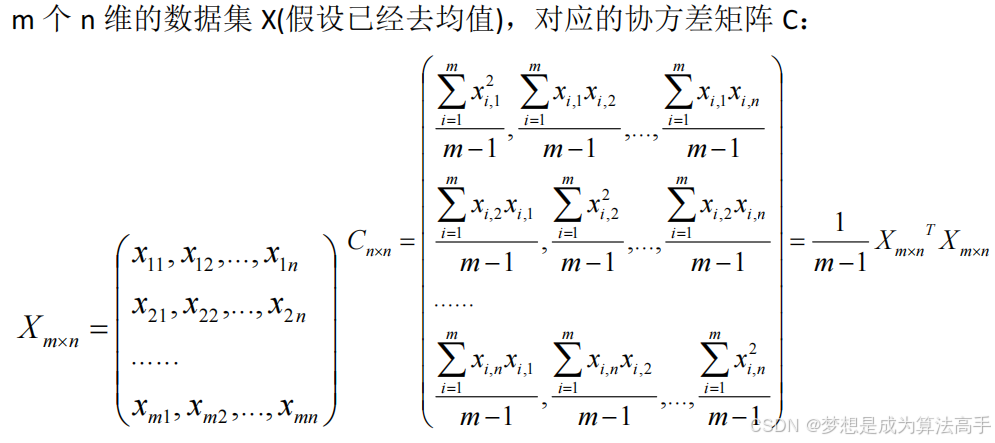
假设D是新空间下的Y的协方差矩阵:
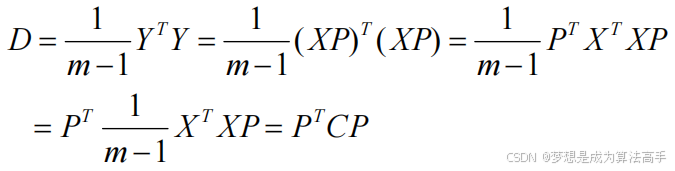
根据协方差矩阵的定义,矩阵C即为原始数据X的协方差矩阵(假设X已经去中心化),因此我们优化的目标为:使变换后的数据Y的特征向量间独立(即协方差为零)的同时,各特征自身的方差尽量大,也就是使得Y的协方差矩阵只有对角线上有数值,因为对角线上是自身方差的值。
因此,我们需要找到能使协方差矩阵C对角化的一个变换矩阵P ,使![]() 。
。
已知如下定理:

上述定理中D为对角矩阵,注意:正交矩阵的逆等于其转置。
2. 实对称矩阵不同特征值对应的特征向量必然正交。
3. 设特征值λ重数为r,则必然存在r个线性无关的特征向量对应于λ,因此可以将这r个特征向量单位正交化。
由于协方差矩阵C是实对称矩阵,因此将C对角化的方法即为求C的特征值与特征向量。
对角矩阵Λ中的对角元素即为各特征向量对应的特征值,将对角矩阵Λ中的特征值从大到小,对应的特征向量从左往右排列成特征矩阵P,取前r个特征向量作为低维空间基向量(n个向量a1,a2,...,an线性无关,n维空间的任意一个向量都可以由这n个向量线性表示,那么a1,a2,...,an称为一个基,a1,a2,...,an即为基向量),即可得到最终降维结果。
综上所述,PCA的算法具体流程如下:

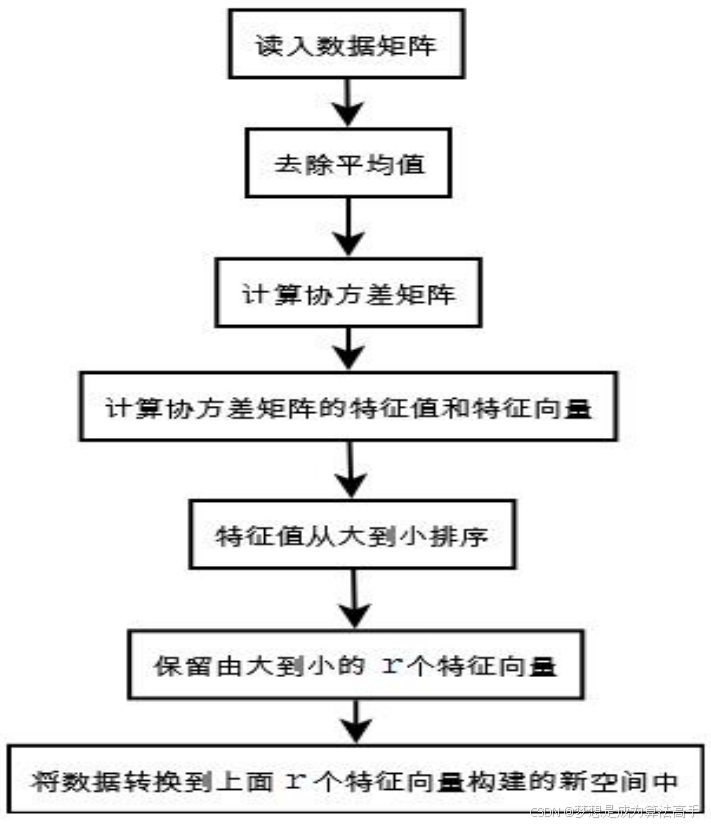
PCA可以帮助我们降低数据的复杂性,识别最重要的多个特征,但可能损失部分有用信息。
7.4 相关系数法
相关系数是反映特征列之间(变量之间)密切相关程度的统计指标,相关系数的值介于–1与+1之间。
当r > 0时,表示两变量正相关,r < 0 时,两变量为负相关。
当|r| = 1 时,表示两变量为完全相关,当r = 0时,表示两变量间完全不相关。
当|r|越接近1,两变量间线性关系越密切,当|r|越接近于0,表示两变量的线性相关越弱。
一般可按三级划分:|r| < 0.4为低度线性相关;0.4 ≤ |r| < 0.7为显著线性相关;0.7 ≤ |r| < 1为高度线性相关。
常见两个相关系数为皮尔逊相关系数和斯皮尔曼相关系数。
皮尔逊相关系数(Pearson correlation coefficient)的表达式如下:
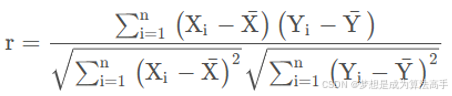
上式中,分母为X和Y的协方差,分子为X的标准差和Y的标准差的乘积。
斯皮尔曼相关系数(Spearman correlation coefficient)的表达式如下:
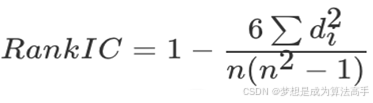
n为样本个数,d为两个变量之间的等级差,一个数的等级是指将它所在的一列数按从小到大排序后,这个数所在的位置,也就是排序后等级从小到大为1,2,…,n,当排序时有相同数值时,则将取它们所在的位置的算数平均值,示例如下: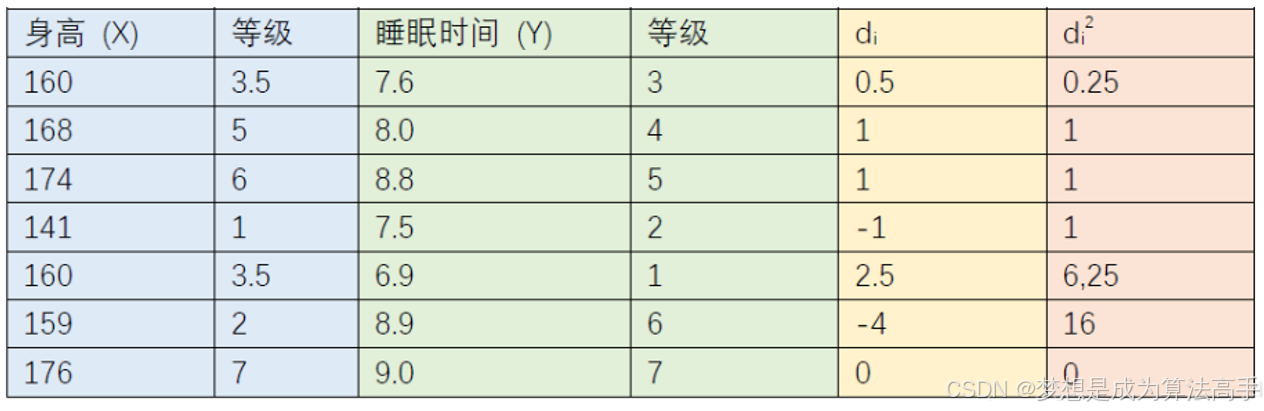
基于相关系数,我们可以选择与目标列最相关的几个特征,或者剔除相关性过高的特征(只保留其中一个特征)。
7.5 特征降维实例
对鸢尾花数据集进行特征降维的具体实现代码如下:
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
from sklearn.feature_selection import VarianceThreshold
from scipy.stats import pearsonr, spearmanr
# 加载鸢(yuān)尾花数据集
iris = load_iris()
# 获取特征和标签(ndarray类型)
X = iris.data
y = iris.target
# 使用主成分分析法降维,n_components=0.9表示保留方差占比至少为90%的特征
pca = PCA(n_components=0.9)
x1 = pca.fit_transform(X) # x1为降维后的特征
# 使用低方差过滤法, threshold=0.5表示保留方差大于0.5的特征
var_threshold = VarianceThreshold(threshold=0.5)
x2 = var_threshold.fit_transform(X) # x2为降维后的特征
# 将数据转换为DataFrame类型
data = pd.DataFrame(X, columns=iris.feature_names)
# 计算皮尔逊相关系数和斯皮尔曼相关系数
pearson = pearsonr(data['sepal length (cm)'], data['sepal width (cm)'])
spearman = spearmanr(data['petal length (cm)'], data['petal width (cm)'])
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 26
26 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)