深度学习中的微调(Fine-tuning)&PyTorch 实践
简洁来说:微调(Fine-tuning)是一种迁移学习(Transfer Learning)方法,它基于已经训练好的模型进行优化,使其在新任务或新数据集上表现更佳。通常,我们会从一个在大规模数据集上预训练的模型(如ImageNet上的ResNet、BERT等)出发,对其进行小规模的更新,使其适应特定应用。预训练模型(Pre-trained Model):利用已有的深度学习模型,该模型已经在大规模数
在深度学习中,训练一个模型往往需要大量的数据和计算资源。微调(Fine-tuning)是一种有效的方法,它通过利用在大规模数据集上预训练的模型,将其适应到新的任务中。本文将结合图示,详细介绍深度学习网络的结构、微调的概念、如何冻结部分层,以及 PyTorch 代码实践。
1. 什么是微调?
简洁来说:微调(Fine-tuning)是一种迁移学习(Transfer Learning)方法,它基于已经训练好的模型进行优化,使其在新任务或新数据集上表现更佳。通常,我们会从一个在大规模数据集上预训练的模型(如ImageNet上的ResNet、BERT等)出发,对其进行小规模的更新,使其适应特定应用。
微调的基本思路:
- 预训练模型(Pre-trained Model):利用已有的深度学习模型,该模型已经在大规模数据集上学习到了丰富的特征表示。
- 冻结部分参数(Freezing Layers):为了防止过拟合,可以固定部分层的参数,仅训练某些特定层。
- 调整特定层(Fine-tune Layers):在新的数据集上调整部分或全部模型参数,使其适应新任务。
- 输出层替换(Replacing Output Layers):通常,我们需要替换原始的分类层,使其适配新的类别或任务。
下面将参考李沐老师的动手学深度学习系列进行更详细的介绍~
1.1 神经网络的基本架构
在深度学习模型中,神经网络通常可以分为两个主要部分:
- 特征提取(Feature Extraction):
- 由多个层(如卷积层、池化层)组成,作用是从输入数据(如图片)中提取特征。
- 低层次的特征(如边缘、纹理)更具通用性,而高层次的特征(如形状、语义信息)更依赖于数据集。
- 分类器(Classifier):
- 通过线性分类器(如全连接层+Softmax)来做最终的分类决策。
如下图展示的一个标准的神经网络架构,其中:
- 底层负责特征提取(Feature Extraction)。
- 顶层是输出层(Output Layer),用于分类。
- 采用 Softmax 回归 作为最终分类的方式。
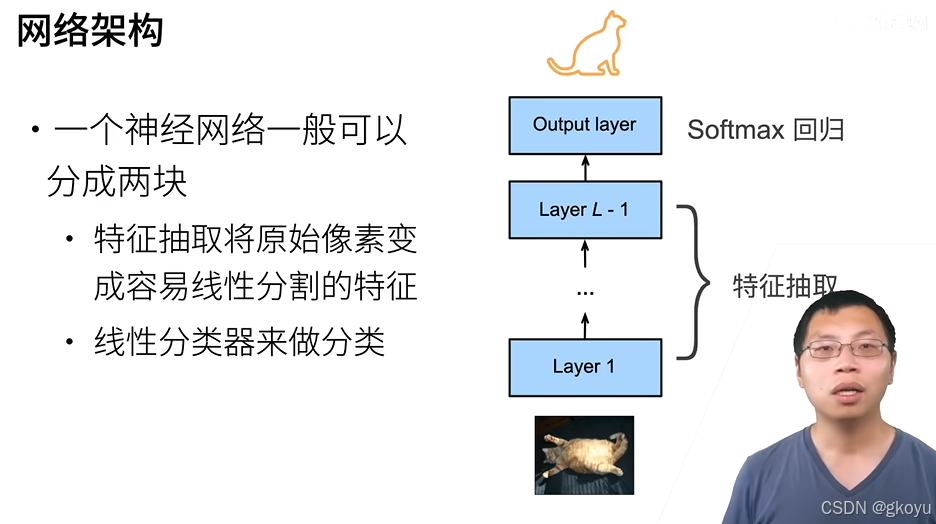
在训练过程中,深度学习模型会自动学习层次化的特征表示,低层负责简单特征,如边缘和纹理,而高层负责更复杂的语义信息。
1.2 为什么要进行微调?
训练一个深度学习模型通常需要大量数据,而在实际应用中,数据有限 或 计算资源不足。此时,我们可以利用在大规模数据集(如 ImageNet)上训练好的模型,并对其进行微调,使其适应新的任务。
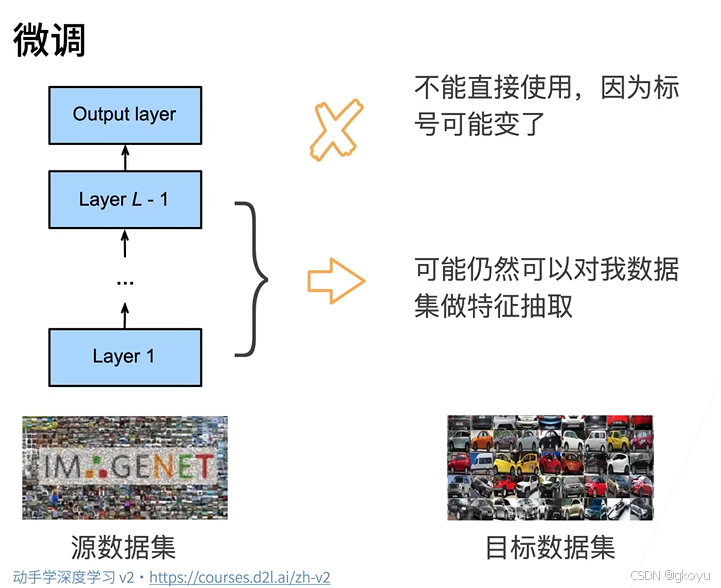
如图所示:
- 预训练模型在源数据集(如 ImageNet)上已经学到了通用的特征。(如图预训练模型是在 ImageNet 数据集 上训练的,而新任务的数据集可能是 车辆分类。)
- 直接使用预训练模型可能不适用于新任务,因为 分类标签可能不同。
- 但模型的前几层仍然可以用于新的数据集,因为它们提取的是通用特征。
1.3 冻结部分层
在微调过程中,我们通常不会修改整个神经网络,而是冻结底层部分,仅训练高层部分,这样可以:
- 利用底层的通用特征(如边缘、纹理)。
- 冻结底部层的参数,不参与更新,只训练高层

2. PyTorch 代码实践
本部分将以 ResNet-50 为例,进行 图像分类任务 的微调。
2.1 加载预训练模型
import torch
import torch.nn as nn
import torchvision.models as models
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
# 设备选择
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载 ResNet-50 预训练模型
model = models.resnet50(pretrained=True)
# 获取 ResNet 的全连接层输入特征数
num_features = model.fc.in_features
# 替换全连接层,适配 10 类分类任务
model.fc = nn.Linear(num_features, 10)
# 移动到 GPU/CPU
model = model.to(device)
2.2 数据预处理
通常,我们需要对输入图像进行归一化和数据增强:
# 数据增强和预处理
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整大小
transforms.ToTensor(), # 转换为 Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])
# 加载 CIFAR-10 数据集
train_dataset = datasets.CIFAR10(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.CIFAR10(root='./data', train=False, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
2.3 冻结部分层
默认情况下,微调的第一步是冻结卷积层,只训练新加的全连接层:
# 冻结所有层
for param in model.parameters():
param.requires_grad = False
# 只训练最后的全连接层
for param in model.fc.parameters():
param.requires_grad = True
2.4 训练模型
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.fc.parameters(), lr=0.001)
# 训练模型
num_epochs = 5
model.train()
for epoch in range(num_epochs):
running_loss = 0.0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}")
print("训练完成!")
2.5 评估模型
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f"测试集准确率: {accuracy:.2f}%")
3. 总结
- 神经网络可以分为特征提取部分和分类器,前者学习通用特征,后者执行任务特定的分类。
- 微调(Fine-tuning)可以利用预训练模型,减少数据需求,提高训练效率。
- 冻结部分层 可以保留通用特征,只更新任务相关的层,防止过拟合。
- PyTorch 代码实践 展示了如何加载预训练模型、冻结层,并进行微调。
4. 参考

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 52
52 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)