决策树_机器学习
前言:决策树也是一种简单的分类模型,主要应用在反信用卡诈骗,骚扰邮件过滤。这里主要结合:1: 乳腺癌预测例子2 破腹产预测例子https://archive.ics.uci.edu/ml/datasets/Caesarian+Section+Classification+Dataset3 学生购买电脑的例子讲述...
前言:
决策树也是一种简单的分类模型,主要应用在反信用卡诈骗,骚扰邮件过滤。
这里主要结合:
1: 乳腺癌预测例子
2 破腹产预测例子
https://archive.ics.uci.edu/ml/datasets/Caesarian+Section+Classification+Dataset
3 学生购买电脑的例子讲述一下相关的原理
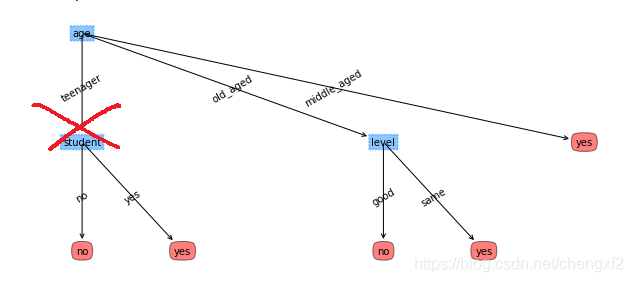
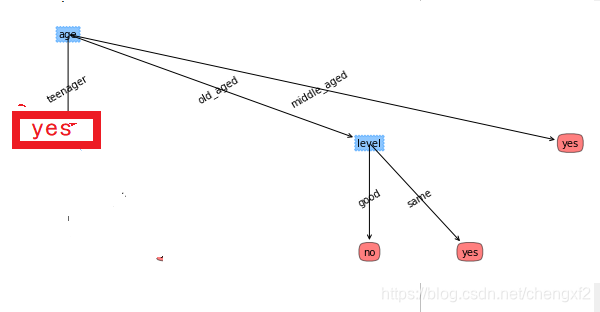
生成的树如下:
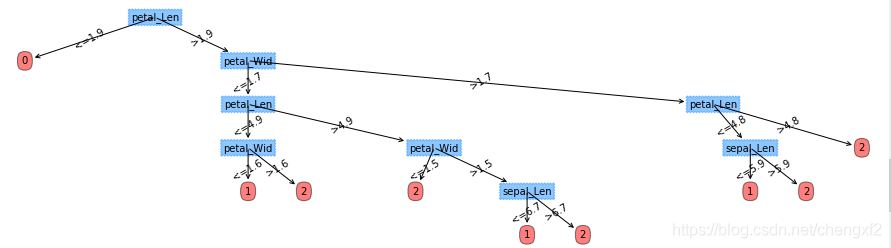
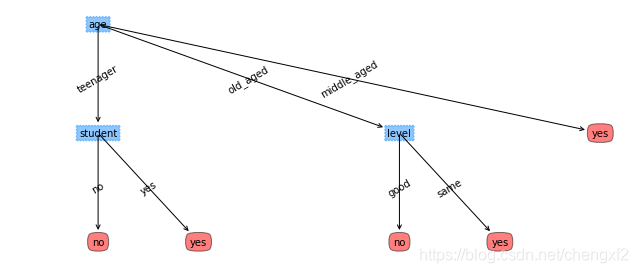
数据集2,预测是否会购买电脑
目录:
- 决策树简介
- 决策树算法流程
- 决策树三种主要算法(ID3,C4.5, CART)
- 决策树剪枝
- 例子
- 问题
一 决策树简介
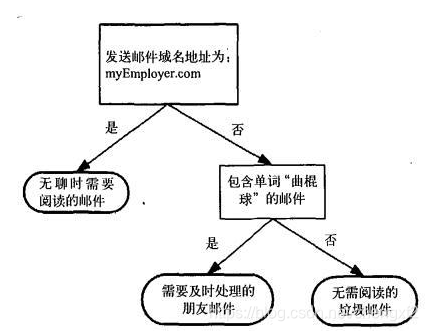
垃圾邮件分类决策树模型:
决策树主要由四部分组成:
根节点(属性)
子节点(属性)
分枝(属性值)
叶子节点(标签
二 决策树流程:
2.1 CreateNode(创建节点)
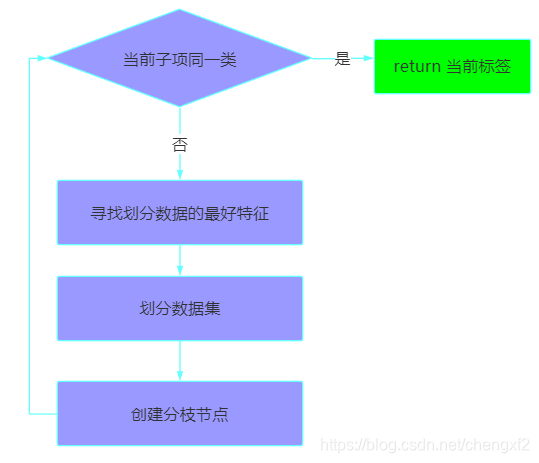
2.2 总体流程:

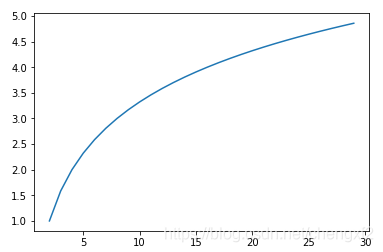
2.3 熵
反应离散随机事件出现的概率
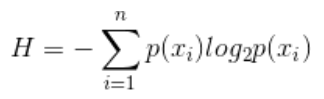
熵也是一个有约束的凸函数

可以通过琴声不等式证明p 取1/n 时候值最大,且范围值为
证明:
由定理1:
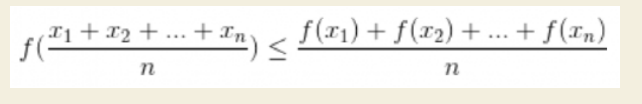
其中
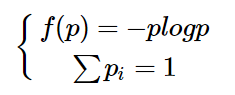
因为是上凸,所有
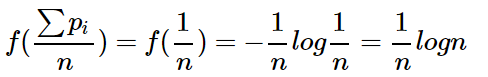
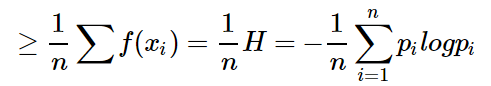
可以看出下面三点
1: 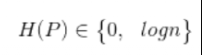
2: 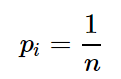 时候为熵的极大值
时候为熵的极大值
3: 分类种类越多,熵值越大。
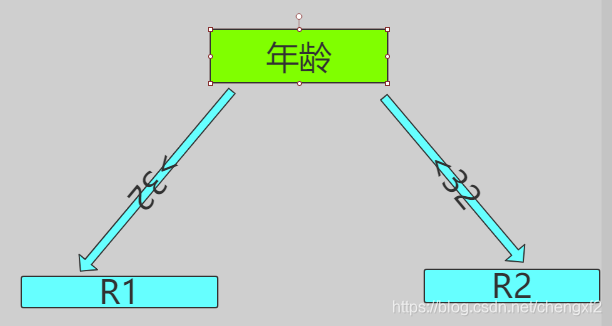
2.4 信息增益
假设有K类,A代表具体属性,比如上面 年龄,D_i 是按照年龄中一个具体的划分,比如老年
取的数据集
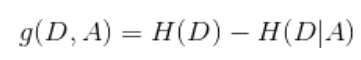
其中:
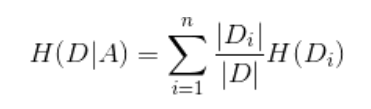
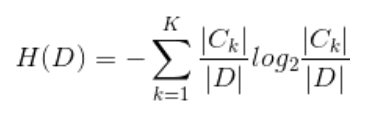
2.5 信息增益比
信息增益划分,会偏向选择较多特征的一列,为了纠正这一问题,可以选择信息增益比
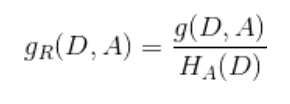
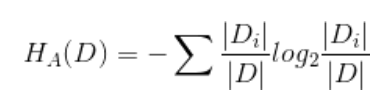
三 决策树三种主要算法
3.1 ID3
输入:
训练数据集D , 和 特征集A, 阀值![]()
输出:
决策树
步骤:
1: 若D中所有的实例都是同一类,则T为单节点树,![]() 作为叶节点返回
作为叶节点返回
2: 若特征集为空集, 则T为单节点树,将D中实例数最多的类![]() 作为叶节点返回
作为叶节点返回
3: 计算特征集A中信息增益,选择信息增益最大的特征Ag
3: 计算特征集A中信息增益比,选择信息增益比最大的特征Ag
4: 如果该信息增益小于阀值e, 则T为单节点树,返回![]()
5 对A中每个属性a,将D 按照a 划分为若干个非空集合Di, 构建新的节点树,该节点和其子节点构成
树T,返回T 例如:{A2:{a21:value, a22:{...},...}
6: 对第i个子节点,以Di为训练集,以A-{Ag}为特征集,递归上面步骤1--5
3.2 C4.5

唯一的区别选择了信息增益比
3.3 CART
最小二乘回归树生成算法
可以对连续数据处理
输入:
训练集D
输出:
回归树f(x),也是二分树
1: 选择最优切分变量j 和 切分点s, 求解
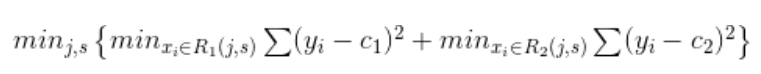
遍历遍历j,对固定的切分遍历j扫描切分点s, 选择使得上面达到最小的(j,s)
![]()
2: 对选定的对(j,s)划分区域 ,并决定对应的输出值
![]()
3: 继续对两个子区域调用步骤1,2 直到满足停止条件
4: 将输入空间划分为M个区域![]() 生成决策树
生成决策树
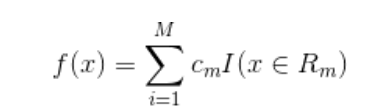
停止条件:
当前的每个叶节点方差和小于一定值,例如上面乳腺癌按照年龄分,只分一次
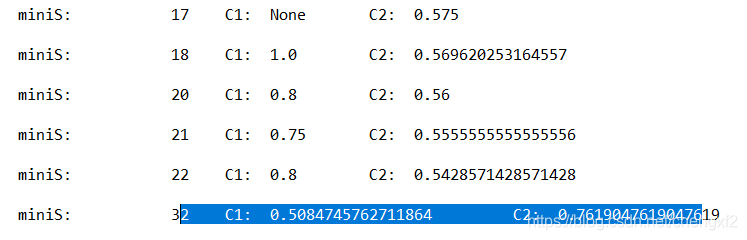
"""
根据最小标准差方差获得最优的切分点
原理上就是数据尽量是同类
Args
j: 属性,某一列
dataList: 数据集
retrun
j, s 最优切分点,这里考虑的只是连续数据
"""
def MiniTree(j, dataList):
#print("j: ",j, "\n data",dataList)
sList =[int(item[j]) for item in dataList]
sList.sort()
setS = set(sList)
print("\n ******setS******** ",setS )
miniVar = float("inf")
miniS = 0
leftR = []
rightR = []
for s in setS:
leftR.clear()
rightR.clear()
for item in dataList:
a = int(item[j])
y = int(item[-1])
if a <s:
leftR.append(y)
else:
rightR.append(y)
var1 = 0
var2 = 0
C1 = None
C2 = None
if len(leftR)>0:
var1 = np.var(leftR)*len(leftR)
C1 = np.mean(leftR)
if len(rightR)>0:
var2 = np.var(rightR)*len(rightR)
C2 = np.mean(rightR)
var = var1+var2
#print("s: ",s, "\t currQ ",var)
if var <miniVar:
miniVar = var
miniS = s
print("\n miniS: \t ",s,"\t C1: ",C1, "\t C2: ",C2)
基尼指数 : CART中用来选择最优特征,反应样本集合的不确定性
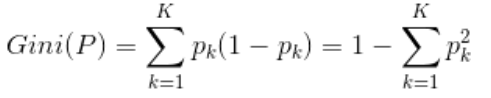
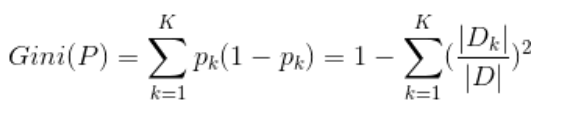
如何证明Gini 极大值是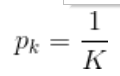
证明:
根据约束条件,加上一个仿射函数,配成
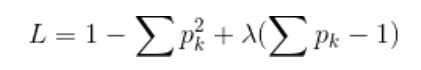
对 ![]() 求偏导数
求偏导数
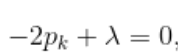
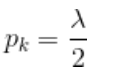
重新带入上式
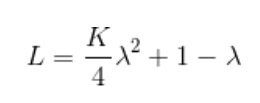
对 ![]() 求偏导数, 则
求偏导数, 则
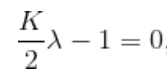
![]()
则:
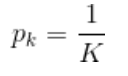 为极值点
为极值点
CART生成算法:
输入:
训练数据集D,停止计算条件
输出:
CART决策树
s1: 设结点的训练数据集为D,计算现有特征对该数据集的基尼系数,对每一个特征A,对每一个取值a
根据样本点取值对A=a ,将数据集分割成D1,D2两部分
s2: 在所有可能的特征A 以及它们的切分点a,选择基尼指数最小的特征A及对应的切分点a作为最优切分点
生成两个子结点,将数据集划分到对应的两个子结点中去,
s3: 对两个子结点,递归调用s1,s2,直到满足停止条件
s4: 生成CART树
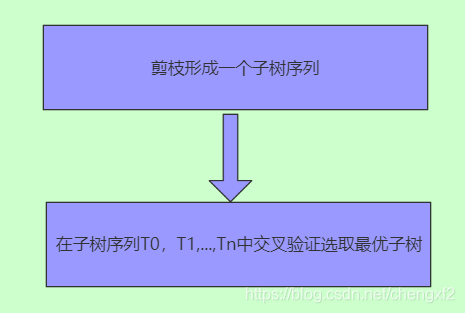
四 剪枝
主要防止过拟合,增加泛化能力
分为预剪枝,和后剪枝
常见的后剪枝算法为: REP, PEP, CCP等算法
4.1 决策树剪枝:
输入:
算法生成整个树T, 参数![]()
输出:
修剪后的树 Tn
4.1 计算每个结点的经验熵
4.2 递归从树的叶结点回缩(结点)
4.3 设一组叶结点回缩前和回缩后整树分别为![]() ,对应的损失函数分别为
,对应的损失函数分别为![]()
如果![]() ,则进行剪枝,父结点变成新的叶结点
,则进行剪枝,父结点变成新的叶结点
4.4 返回4.2 直到不能继续
损失函数:T为叶节点个数
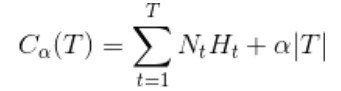
经验熵:
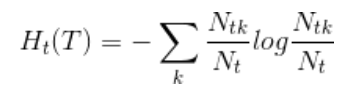
则上面也可以写为:
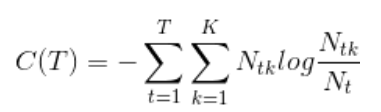
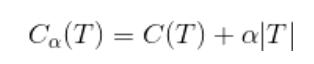
算法里面:
需要先找到叶节点,然后递归回父节点,遍历出同一个父节点下面的其它叶节点
才能得到剪枝后T数目
剪枝后
4.2 CART 剪枝
子树序列形成:
对于固定的![]() ,存在不同的剪枝方案,但存在一个最优的子树
,存在不同的剪枝方案,但存在一个最优的子树![]()

以 t为单结点的子树t损失函数:
![]()
以 t 为根结点损失函数为:
![]()
可以调整参数a,使得二者相等
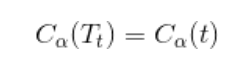
此刻:
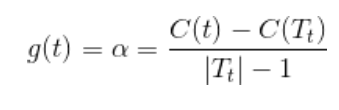 表示剪枝后,整体损失函数减少程度
表示剪枝后,整体损失函数减少程度
在剪枝得到的子树序列T0,T1.....Tn中交叉验证选取最优子树![]()
利用独立数据集,测试子树序列的基尼系数,或者平方误差,这里面的每一轮生成一个最优的Tree
下一轮在前一轮基础上,重新剪枝
算法流程:
输入:
CART算法生成的决策树T0
输出:
最优决策树![]()
1 : 设k = 0, T= T0
2: ![]()
3 自下而上对内部各个结点t计算![]() 以及
以及
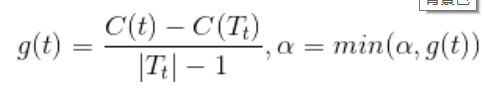
这里Tt表示以t为根结点的子树,C(Tt)是对训练集的预测误差,|T_t|是Tt的叶结点个数
4: ![]()
的内部结点的子树,进行剪枝,以多数表决法得到树
5: 设k=k+1,![]() ,
,
6: Tk 不是由根结点以及两个叶结点构成的树,否则Tk= Tn
7: 采用交叉验证得到子树T0,T1,...Tn选择最优子树
这里注意:
剪枝后,一定要保证各个叶结点的精度。
代码实现:
为了方便,生成树后先给不同叶结点打上唯一的Tag
"""
给叶结点打上唯一的标签
"""
def AddTag(self, tree):
keys =['left', 'right']
for key in keys:
subTree = tree[key]
if self.IsTree(subTree):
self.AddTag(subTree)
else:
Tag = "TAG_"+key
if Tag not in tree:
x = self.LeafTag.pop(0)
tree[Tag] = x
这里面给出一种单轮选择最优Gini系数的方案,不同轮即上面k=k+1,最好使用不同的数据集
同时也要注意,剪枝后,要使用数据集对新生成的Tree验证
"""
剪枝
Args
dataList: 数据集
tree: 树
return
None
"""
def Prunch(self, dataList, dataLabel,tree):
ct = 0.0
c_Beaf = 0.0
if not self.IsTree(tree) or len(dataLabel)<1:
return
BeafNum = self.GetLeafs(tree) ##叶结点数目|T|
ct = self.GetGini(dataLabel)
if BeafNum<2: ###本身已经是叶结点了
return
dict_beaf={}
i = 0
for data in dataList:
perdict_Label, Tag_ID = self.Perdict(tree,data)
if Tag_ID not in dict_beaf:
dict_beaf[Tag_ID] =[]
test_label = dataLabel[i]
beaf_List = dict_beaf[Tag_ID]
beaf_List.append(test_label)
i = i+1
#keyList = dict_beaf.keys()
# print("\n ****keyList***\n\t ",keyList, "\t len: ",len(keyList))
c_Beaf = self.GetBeafGini(dict_beaf)
alpha = (ct-c_Beaf)/(BeafNum-1)
name = tree['name']
feat = self.train_feature.index(name)
val = tree['feature']
# print("\n ct: \t",ct, "\t c_Beaf: \t",c_Beaf, "\t alpha: ",alpha)
print("\n name: ",name , "\t val : ",val)
print("\n t为根结点Gini :\t %.3f"%ct, "\t t为树的Gini:\t %.3f"%c_Beaf, "\t alpha: %.3f"%alpha)
L_Data, L_Label, R_Data, R_Label =self.SplitData(dataList, feat, val, dataLabel)
LTree= tree['left']
RTree =tree['right']
self.Prunch(L_Data,L_Label ,LTree)
self.Prunch(R_Data, R_Label,RTree )
return None
name: worst perimeter val : 106.2
t为根结点Gini : 0.371 t为树的Gini: 0.089 alpha: 0.017
name: worst smoothness val : 0.1777
t为根结点Gini : 0.042 t为树的Gini: 0.032 alpha: 0.001
name: worst concave points val : 0.1607
t为根结点Gini : 0.022 t为树的Gini: 0.019 alpha: 0.000
name: mean area val : 698.8
t为根结点Gini : 0.022 t为树的Gini: 0.019 alpha: 0.000
name: perimeter error val : 4.138
t为根结点Gini : 0.022 t为树的Gini: 0.019 alpha: 0.000
name: worst texture val : 30.25
t为根结点Gini : 0.022 t为树的Gini: 0.019 alpha: 0.001
name: mean fractal dimension val : 0.05628
t为根结点Gini : 0.124 t为树的Gini: 0.114 alpha: 0.003
name: smoothness error val : 0.007499
t为根结点Gini : 0.077 t为树的Gini: 0.073 alpha: 0.002
name: mean radius val : 12.77
t为根结点Gini : 0.000 t为树的Gini: 0.000 alpha: 0.000
name: mean radius val : 12.77
t为根结点Gini : 0.000 t为树的Gini: 0.000 alpha: 0.000
name: mean texture val : 15.56
t为根结点Gini : 0.349 t为树的Gini: 0.222 alpha: 0.021
name: mean perimeter val : 102.5
t为根结点Gini : 0.346 t为树的Gini: 0.267 alpha: 0.079
name: worst smoothness val : 0.1021
t为根结点Gini : 0.262 t为树的Gini: 0.217 alpha: 0.011
name: mean radius val : 18.08
t为根结点Gini : 0.000 t为树的Gini: 0.000 alpha: 0.000
name: worst concavity val : 0.1932
t为根结点Gini : 0.265 t为树的Gini: 0.220 alpha: 0.022
name: mean radius val : 16.02
t为根结点Gini : 0.375 t为树的Gini: 0.333 alpha: 0.042
五 例子
1: 乳腺癌例子
# -*- coding: utf-8 -*-
"""
Created on Mon Sep 9 16:49:01 2019
@author: chengxf2
"""
import numpy as np
import matplotlib.pyplot as plt
import sys,os
from sklearn.datasets import load_breast_cancer
class CART:
def IsTree(self, obj):
bTree =(type(obj).__name__=='dict')
return bTree
"""
获得叶结点个数
Args
tree: 树
return
num
"""
def GetLeafs(self, tree):
numLeaf = 0
keys =['left', 'right']
for key in keys:
subTree = tree[key]
if self.IsTree(subTree):
numLeaf += self.GetLeafs(subTree)
else:
numLeaf +=1
return numLeaf
"""
获得树的深度
Args
tree: 树
return
depth
"""
def GetDepth(self, tree):
print("====depth##########")
maxDepth = 0
keys =['left', 'right']
for key in keys:
subTree = tree[key]
if self.IsTree(subTree):
depth =1+ self.GetDepth(subTree)
else:
depth = 1
if depth >maxDepth:
maxDepth = depth
return maxDepth
"""
加载数据集
Args:
None
return
feature_names:
['mean radius' 'mean texture' 'mean perimeter' 'mean area'
'mean smoothness' 'mean compactness' 'mean concavity'
'mean concave points' 'mean symmetry' 'mean fractal dimension'
'radius error' 'texture error' 'perimeter error' 'area error'
'smoothness error' 'compactness error' 'concavity error'
'concave points error' 'symmetry error' 'fractal dimension error'
'worst radius' 'worst texture' 'worst perimeter' 'worst area'
'worst smoothness' 'worst compactness' 'worst concavity'
'worst concave points' 'worst symmetry' 'worst fractal dimension']
target_Name:
['malignant' 恶性 'benign' 良性]
### 数据总长 569 ,300用来Train ,269 用来测试,剪枝
"""
def LoadData(self):
cancer = load_breast_cancer()
data = cancer['data']
target = cancer['target']
target_Name = cancer['target_names']
DESCR = cancer['DESCR']
feature_names = cancer['feature_names']
#print("\n data: \n ", data)
#print("\n target: \n ", target)
#print("\n target_Name: \n ", target_Name)
#print("\n DESCR: \n ", DESCR)
#print("\n feature_names: \n ", feature_names)
self.trainData = data[0:300]
self.train_target = target[0:300]
self.target_name= target_Name
self.train_feature = feature_names.tolist()
self.testData = data[300:-1]
self.test_target= target[300:-1]
"""
分割数据
Args
dataMat: 输入矩阵
col: 列
val: 值
Returns
L_Data: 小于该值的矩阵
L_Labels: 左边标签
R_Data: 右边矩阵
R_Labels: 右边标签
"""
def SplitData(self, dataList, col, val, Labels):
L_Data =[]; L_Label=[]
R_Data =[]; R_Label=[]
m,n = np.shape(dataList)
# print("\n m: ",m, "n: ",n)
for i in range(m):
cur = dataList[i][col]
data = dataList[i]
#print("\n data ",data)
label = Labels[i]
if cur<val:
L_Data.append(data)
L_Label.append(label)
else:
R_Data.append(data)
R_Label.append(label)
# print("\n =R_Mat= \n ",np.shape(R_Data))
#print("======================\n")
#print("\n L_Data: \n ",np.shape(L_Data))
return L_Data, L_Label, R_Data, R_Label
"""
分割数据
Args
dataMat: 输入矩阵
col: 列
val: 值
Returns
L_Data: 小于该值的矩阵
L_Labels: 左边标签
R_Data: 右边矩阵
R_Labels: 右边标签
"""
def GetSubLabel(self, dataList, col, val, Labels):
L_Label=[]
R_Label=[]
m,n = np.shape(dataList)
for i in range(m):
cur = dataList[i][col]
label = Labels[i]
if cur<val:
L_Label.append(label)
else:
R_Label.append(label)
return L_Label,R_Label
def GetGini(self, Labels):
m = len(Labels)
dictItem ={}
gini = 0.0
if m <1:
return None
for label in Labels:
if label not in dictItem:
dictItem[label]=0
dictItem[label]=dictItem[label]+1
for key in dictItem.keys():
prob = np.power(dictItem[key]/m,2)
gini +=prob
return 1-gini
"""
选择最优特征
Args
dataList: 数据集
Labels: 标签集
return
L_Data
R_Data
L_Label
R_Label
"""
def ChooseBestFeatures(self, dataList, Labels):
m,n = np.shape(dataList)
miniGini = float("inf") ##Gini 系数选择最小的
bestCol= 0 ##最佳特征
bestFeature = 0 ##划分点
for i in range(n):
item = [data[i] for data in dataList]
setFeature = set(item)
for feature in setFeature:
L_Label, R_Label= self.GetSubLabel(dataList, i, feature, Labels)
m1 = len(L_Label)
m2 = len(R_Label)
if m1==0 or m2 ==0: continue
gini = (m1*self.GetGini(L_Label)+m2*self.GetGini(R_Label))/m
if gini<miniGini:
miniGini = gini
bestCol = i
bestFeature = feature
print("\n minGini ",miniGini, "bestCol ",self.train_feature[bestCol], "\t bestFeature ",bestFeature)
return bestCol, bestFeature
"""
创建树
Args
dataList: 数据集
Labels: 分类结果
return
Tree
"""
def CreateTree(self, dataList, Labels):
setLabel = set(Labels)
m = len(dataList) ##样本个数
if 1 == len(setLabel): ###只有一个分类
return Labels[0]
elif 1 ==m: ##只有一个样本
return Labels[0]
feat, val = self.ChooseBestFeatures(dataList, Labels)
tree ={}
tree['feature']=val
tree['name'] = self.train_feature[feat]
L_Data, L_Label, R_Data, R_Label =self.SplitData(dataList, feat, val, Labels)
tree['left']=self.CreateTree(L_Data,L_Label )
tree['right']=self.CreateTree(R_Data, R_Label )
return tree
"""
分类
Args
myTree 决策树
Labels 标签
testVec 当前数据集
return
测试出来的标签
"""
def Perdict(self, myTree, data):
keyList= ['left','right']
name = myTree['name']
feature = myTree['feature']
col = self.train_feature.index(name)
cur = data[col]
if cur<feature:
subTree = myTree['left']
else:
subTree = myTree['right']
if self.IsTree(subTree):
label = self.Perdict(subTree, data)
else:
label =subTree
return label
"""
训练
"""
def Train(self):
tree = self.CreateTree(self.trainData, self.train_target)
depth = self.GetDepth(tree)
num = self.GetLeafs(tree)
print("\n tree: \n ",tree)
print("\n 叶结点数: \t",num)
print("\n 树深度: \t ",depth )
print("\n ***************树已生成*******************\n")
num = len(self.testData)
err = 0
for i in range(num):
data = self.testData[i]
true_label = self.test_target[i]
label= self.Perdict(tree, data)
print("\n label ",label, "\t target ",true_label)
if true_label != label:
err=err+1
print("\n 测试样本: \t", num, "测试错误率: \t ",err/num, "\t err: ",err)
"""
初始化
Args
None
return
None
"""
def __init__(self):
self.LoadData()
self.Train()
cart =CART()
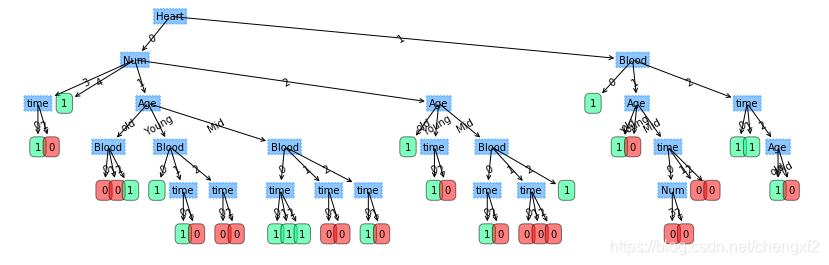
2: 剖腹产预测例子
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 28 13:59:01 2019
@author: chengxf2
"""
"""
决策树
"""
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
from matplotlib import cm
import os,sys
import operator
import math
from decimal import *
import treePlot
from imp import reload
import copy
import miniTree as mini
#import csvFun
"""
数据集2: 根据学生情况,预测是否购买电脑
self.dataList=[['teenager' ,'high', 'no' ,'same', 'no'],
['teenager', 'high', 'no', 'good', 'no'],
['middle_aged' ,'high', 'no', 'same', 'yes'],
['old_aged', 'middle', 'no' ,'same', 'yes'],
['old_aged', 'low', 'yes', 'same' ,'yes'],
['old_aged', 'low', 'yes', 'good', 'no'],
['middle_aged', 'low' ,'yes' ,'good', 'yes'],
['teenager' ,'middle' ,'no', 'same', 'no'],
['teenager', 'low' ,'yes' ,'same', 'yes'],
['old_aged' ,'middle', 'yes', 'same', 'yes'],
['teenager' ,'middle', 'yes', 'good', 'yes'],
['middle_aged' ,'middle', 'no', 'good', 'yes'],
['middle_aged', 'high', 'yes', 'same', 'yes'],
['old_aged', 'middle', 'no' ,'good' ,'no']]
self.Labels=['age','input','student','level']
RID age income student credit_rating class:buys_computer
"""
#
from csvFun import LoadFile
class Shannon:
'''
学生购买电脑例子
Args
None
return
data
'''
def LoadDataStudent(self):
self.dataList=[['teenager' ,'high', 'no' ,'same', 'no'],
['teenager', 'high', 'no', 'good', 'no'],
['middle_aged' ,'high', 'no', 'same', 'yes'],
['old_aged', 'middle', 'no' ,'same', 'yes'],
['old_aged', 'low', 'yes', 'same' ,'yes'],
['old_aged', 'low', 'yes', 'good', 'no'],
['middle_aged', 'low' ,'yes' ,'good', 'yes'],
['teenager' ,'middle' ,'no', 'same', 'no'],
['teenager', 'low' ,'yes' ,'same', 'yes'],
['old_aged' ,'middle', 'yes', 'same', 'yes'],
['teenager' ,'middle', 'yes', 'good', 'yes'],
['middle_aged' ,'middle', 'no', 'good', 'yes'],
['middle_aged', 'high', 'yes', 'same', 'yes'],
['old_aged', 'middle', 'no' ,'good' ,'no']]
self.dataLabel =['age','input','student','level','result']
"""
降维
Args
age:连续数据
return
离散数据
"""
def ReduceDimension(self, age):
#print("age ",min(age), max(age))
DiAge =[]
for x in age:
if x<32:
DiAge.append("Y")
else:
DiAge.append("M")
return DiAge
"""
转换为高斯分布
Arg:
age: list
u: 平均值
return
复合高斯分布的数据
"""
def GetInfo(self, dataList):
age0 = []
age1 = []
for item in dataList:
print("-1 ",item)
if item[-1]=='0':
age0.append(int(item[0]))
else:
age1.append(int(item[0]))
#求方差
mean0 = np.mean(age0)
var0 = np.var(age0)
mean1 = np.mean(age1)
var1 = np.var(age1)
#求标准差
std0 = np.std(age0,ddof=1)
std1 = np.std(age1,ddof=1)
#print("mean0 ", mean0, " var0: ", var0, "\t mean1 ",mean1, "\t var1: ",var1)
#print("\n std0: ",std0, "\t std1: ",std1)
"""
如果属性集只有一个属性了,返回概率最高的那个
Args
数据
return
分类结果
"""
def MajorCnt(self, classList):
dictCount ={}
for item in classList:
# print("\n vote ",vote)
vote = item[-1]
if vote not in dictCount:
dictCount[vote] = 0
dictCount[vote]+=1
# print("\n classCount ",dictCount)
sortKey = sorted(dictCount.items(), key =lambda d:d[1], reverse= True)
return sortKey[0][0],dictCount
"""
获得数据集路径,以及保存Tree路径
arg:
None
return:
File Path
"""
def GetPath(self):
##
fileName = "caesarian.csv"
path = os.path.abspath(fileName)
self.path = path
self.treePath = os.path.abspath("tree")
"""
加载数据集
Args:
None
return
dataList
"""
def LoadData(self):
#labels = ['no surfacing','flippers'] ###相当于属性
#Caesarian 剖腹产
dataList = LoadFile(self.path)
self.dataList = dataList[1:]
print("\n ****************************\n")
#mini.MiniTree(0, self.dataList)
age = [int(item[0]) for item in self.dataList]
age = self.ReduceDimension(age)
for i in range(len(self.dataList)):
self.dataList[i][0]=age[i]
self.dataLabel = ['Age','Num','time','Blood','Heart','Result']
"""
计算单个熵
Args
prob
return
H: 熵
"""
def GetEnt(self, prob):
ent = 0.0
if prob==0 or prob ==1:
return 0
else:
ent = -prob*np.log2(prob)
return ent
"""
获得对应的熵
Args:
dataList
return
ent:熵
"""
def GetHD(self, dataList):
num = len(dataList)
# print("样本个数: ",num)
labelDict ={}
for i in range(num):
label = dataList[i][-1]
if label not in labelDict:
labelDict[label]=0
labelDict[label]= labelDict[label]+1
ent = 0.0
for key in labelDict:
prob = labelDict[key]/num
ent += self.GetEnt(prob)
#print("\n ent:::: ",ent)
return ent
"""
调试
"""
def Debug(self):
n = np.arange(2,30)
shanList =[]
for i in range(2,30):
p = 1/i
y = self.GetShan(p)
shanList.append(y*i)
plt.plot(n, shanList)
plt.show()
"""
根据指定的属性,获取对应的属性
Args
col: 对应的一列
attr: 属性
return
匹配的数据集
"""
def SpliteData(self,dataList, col, attr):
subData = []
for item in dataList:
curAttr = item[col]
#print("\n curAttr :",curAttr)
data= []
if curAttr == attr:
data1 = item[:col]
data2 = item[col+1:]
data.extend(data1)
data.extend(data2)
#print("\n data1: ",data1,"\t data2: ",data2, "curAttr: ",curAttr)
subData.append(data)
n = len(subData)
#print("n: ",n ,"\n subData ",subData)
return subData
"""
使用信息增益
args
dataList
return
对应列
"""
def ChooseAttr(self, dataList):
numAttr = len(dataList[0])-1 ##最后一个是属性
num = float(len(dataList))
baseHD = self.GetHD(dataList)
bestGain = 0.0
bestAttr = 0
for col in range(numAttr):
attrList = [data[col] for data in dataList]
setAttr = set(attrList)
HDa = 0.0
HA =0.0
for attr in setAttr:
subData = self.SpliteData(dataList, col, attr)
prob = len(subData)/num
ent = self.GetHD(subData)
HA += self.GetEnt(prob)
HDa +=prob*ent
gDA = (baseHD-HDa)/(HA+1.0) ##除以HA 就是隐形增益比
#print("HA ",HA)
#print("infoGain ",infoGain)
if (gDA> bestGain):
bestGain = gDA
bestAttr = col
#print("\n ******bestAttr*********", bestAttr)
return bestAttr,bestGain
"""
创建树
Args
DataSet, labels
return
treeDict
"""
def CreateTree(self, dataList, labels):
kind = [item[-1] for item in dataList] ##最后一列Result
if kind.count(kind[0])== len(kind):
return kind[0]
###只剩下一个属性了
if len(dataList[0]) ==1: ###只有一个属性了
label,dictCount = self.MajorCnt(dataList)
return label
bestAttr,bestGain = self.ChooseAttr(dataList) ##最佳一列
if bestGain<self.epsilon :
label,dictCount = self.MajorCnt(dataList)
if label =='Y':
print("***********error**********",dataList, "\t dict ",dictCount)
return label
#print("\n ",bestGain)
bestLabel = labels[bestAttr]
del labels[bestAttr] ##删除某一列
myTree ={bestLabel:{}}
###创建分枝
branch = [item[bestAttr] for item in dataList]
setBranch = set(branch)
for key in setBranch:
subLabel = labels[:]
subData = self.SpliteData(dataList, bestAttr, key)
subTree = self.CreateTree(subData, subLabel)
myTree[bestLabel][key] = subTree
return myTree
"""
训练
Args
None
return
树
"""
def Train(self):
label = copy.deepcopy(self.dataLabel)
tree = self.CreateTree(self.dataList, label)
#print("\n Train: dataLabel: ",self.dataLabel)
self.storeTree(tree)
self.grabTree()
#print("\n tree ",tree)
"""
获得叶节点数目
Args:
Tree
return
numLeaf
"""
def GetNumLeaf(self, myTree):
numLeaf = 0
firstNode = list(myTree.keys())[0]
#print("\n type::: ",type(firstNode))
secondDict = myTree[firstNode]
keys = list(secondDict.keys())
#print("\n keys::: ",keys)
for key in keys:
if type(secondDict[key]).__name__=='dict':
numLeaf += self.GetNumLeaf(secondDict[key])
else:
numLeaf+=1
return numLeaf
"""
获取树的深度
Args
Tree
return
Depth
"""
def GetTreeDepth(self, myTree):
maxDepth = 0
firstNode = list(myTree.keys())[0]
secondDict = myTree[firstNode]
keys = list(secondDict.keys())
for key in keys:
if type(secondDict[key]).__name__=='dict':
depth =1+ self.GetTreeDepth(secondDict[key])
else:
depth = 1
if depth>maxDepth:
maxDepth = depth
return maxDepth
"""
保存模型
Args
tree
fileName
return
None
"""
def storeTree(self, tree):
import pickle
fileName = self.treePath
fw = open(fileName,'wb')
pickle.dump(tree, fw)
#print("\n storeTree label: ",self.dataLabel)
fw.close()
"""
加载树
Args
fileNmae
return
tree
"""
def grabTree(self):
import pickle
fileName = self.treePath
fr = open(fileName,'rb')
tree = pickle.load(fr)
leaf = self.GetNumLeaf(tree)
print("leaf ",leaf)
#print("\n tree: ",tree)
#print("\n **********************\n ",tree)
reload(treePlot)
treePlot.createPlot(tree)
errorNum = 0
num = len(self.dataList)
print("\n grabTree label: ",self.dataLabel)
for item in self.dataList:
classifyLabel = self.classify(tree, self.dataLabel, item)
if classifyLabel != item[-1]:
errorNum= errorNum+1
#print("\n classifyLabel:", classifyLabel, " real: ",item[-1])
print("\n errorNUm ",errorNum, " total: ",num)
return tree
"""
分类
Args
myTree 决策树
Labels 标签
testVec 当前数据集
return
测试出来的标签
"""
def classify(self, myTree, Labels, testVec):
father = list(myTree.keys())[0]
childDict = myTree[father]
index = Labels.index(father)
for key in list(childDict.keys()):
if testVec[index]==key:
if type(childDict[key]).__name__=='dict':
testLabel = self.classify(childDict[key], Labels, testVec)
else:
testLabel = childDict[key]
return testLabel
def __init__(self):
self.epsilon = 0.01
self.m = 0
self.n = 0
self.fileName =""
self.GetPath()
self.LoadData()
#self.LoadDataStudent()
self.Train()
shannon = Shannon()
六 问题
1 有1000笔贷款,其中部分是10000以上,有部分是100以下,决策树准确率只有80%多,
如何设计决策树,保证发放贷款是盈利的。
2 剪枝主要是为了解决过拟合,但是当部分结点本身就欠拟合,或者精度不高,还需要剪枝?
3 生成结点的终止条件
参考文档:
《机器学习实战》
《机器学习与应用》
《统计学习方法》
https://blog.csdn.net/tkkzc3E6s4Ou4/article/details/83829616
https://www.cnblogs.com/paisenpython/p/10371644.html
https://blog.csdn.net/hot7732788/article/details/90070618
https://blog.csdn.net/ccblogger/article/details/82656185
https://www.cnblogs.com/beiyan/p/8321329.html
https://wenku.baidu.com/view/671df33631126edb6f1a101c.html
https://www.cnblogs.com/lpworkstudyspace1992/p/8030186.html
https://cuijiahua.com/blog/2017/12/ml_13_regtree_1.html

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)