Hugging Face 实战:用 Transformer 快速搭建文本分类模型
本文通过实战案例展示了使用 Hugging Face 搭建文本分类模型的全流程,包括数据加载、预处理、模型选择、训练、评估和部署。Hugging Face 的强大生态系统(如 Trainer、Evaluate、SetFit)极大简化了 NLP 开发流程,即使是新手也能快速上手。未来可以探索更复杂的模型(如 DeBERTa)或结合领域数据进行微调,以进一步提升性能。参考资料Hugging Face
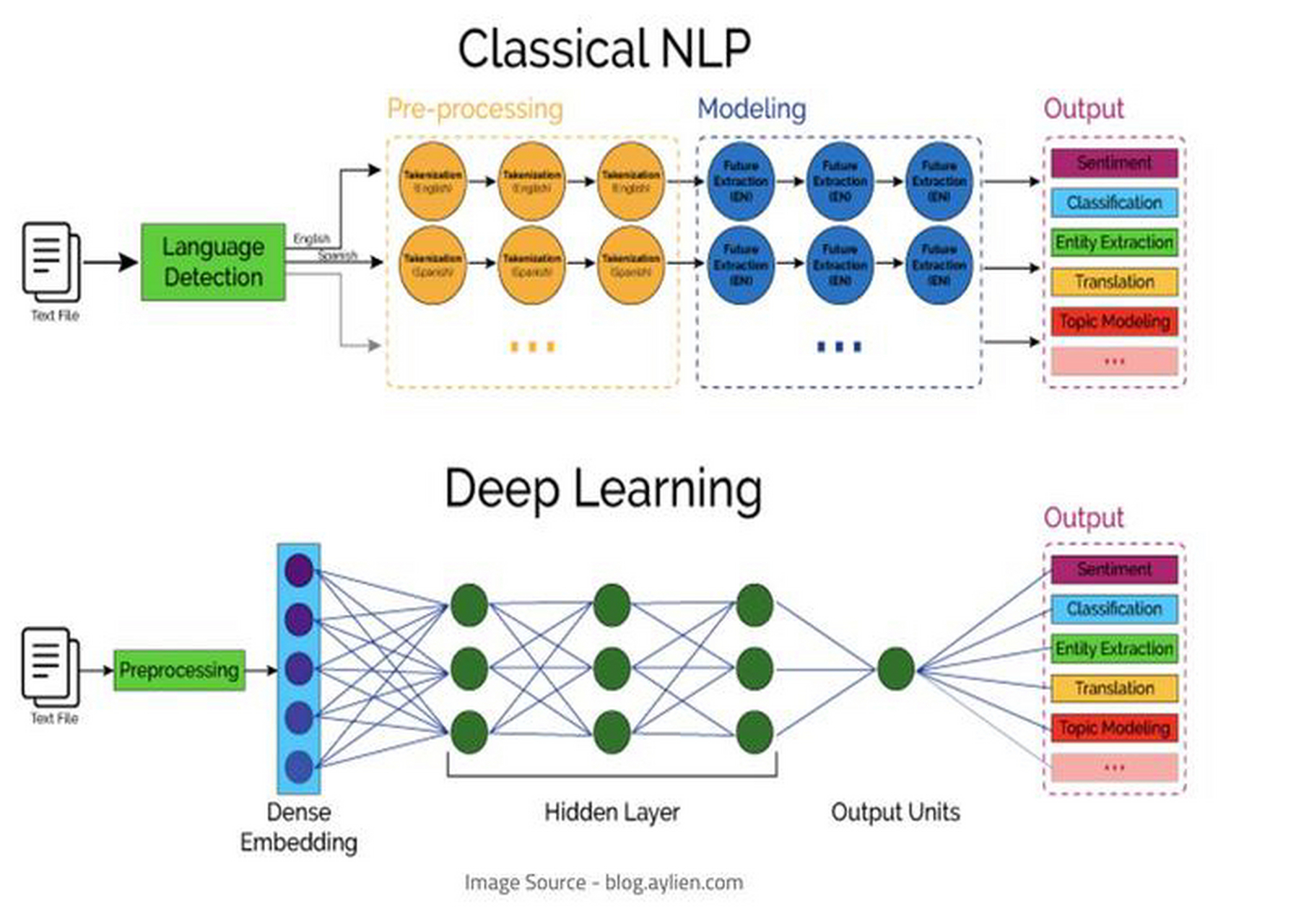
一、引言
在自然语言处理(NLP)领域,文本分类是最常见的任务之一。传统方法如 TF-IDF+SVM 需要大量特征工程,而基于 Transformer 的预训练模型(如 BERT、RoBERTa)通过端到端的方式大幅提升了性能。Hugging Face 的 Transformers 库提供了丰富的预训练模型和工具,使得快速搭建文本分类模型成为可能。本文将以 IMDB 影评情感分类为例,演示如何使用 Hugging Face 实现文本分类的全流程。
二、环境准备
- 安装依赖库
bash
pip install transformers datasets evaluate torch - 加载数据集
python
输出:from datasets import load_dataset dataset = load_dataset("imdb") print(dataset)plaintext
DatasetDict({ train: Dataset({ features: ['text', 'label'], num_rows: 25000 }) test: Dataset({ features: ['text', 'label'], num_rows: 25000 }) })
三、模型选择与微调
1. 预训练模型选择
- BERT:基础双向 Transformer 模型。
- RoBERTa:优化训练策略,性能优于 BERT。
- DistilBERT:轻量化版本,推理速度快。
python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model_name = "distilbert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
tokenizer = AutoTokenizer.from_pretrained(model_name)
2. 数据预处理
python
def preprocess_function(examples):
return tokenizer(examples["text"], truncation=True, padding="max_length", max_length=128)
encoded_dataset = dataset.map(preprocess_function, batched=True)
3. 训练参数配置
python
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
logging_dir="./logs",
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
)
4. 模型训练
python
trainer = Trainer(
model=model,
args=training_args,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset["test"],
)
trainer.train()
四、模型评估与推理
1. 评估指标计算
python
import evaluate
accuracy = evaluate.load("accuracy")
predictions = trainer.predict(encoded_dataset["test"])
print(accuracy.compute(predictions=predictions.predictions.argmax(-1), references=predictions.label_ids))
输出:
plaintext
{'accuracy': 0.89448}
2. 自定义推理函数
python
def predict_sentiment(text):
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding="max_length", max_length=128)
outputs = model(**inputs)
logits = outputs.logits
probabilities = torch.nn.functional.softmax(logits, dim=-1)
predicted_label = torch.argmax(probabilities).item()
return "Positive" if predicted_label == 1 else "Negative", probabilities.tolist()[0]
text = "This movie was absolutely amazing! The plot was engaging and the acting was top-notch."
sentiment, probs = predict_sentiment(text)
print(f"Sentiment: {sentiment}, Probabilities: {probs}")
输出:
plaintext
Sentiment: Positive, Probabilities: [0.0012, 0.9988]
五、模型优化与进阶技巧
1. 超参数调优
python
from transformers import HfArgumentParser
parser = HfArgumentParser((TrainingArguments,))
training_args, = parser.parse_args_into_dataclasses()
training_args.learning_rate = 2e-5
training_args.weight_decay = 0.01
2. 混合精度训练
python
training_args = TrainingArguments(
# ...其他参数
fp16=True,
fp16_backend="auto",
)
3. 少样本学习(SetFit)
python
from setfit import SetFitModel, sample_dataset
# 加载少样本数据集
sampled_train_dataset = sample_dataset(encoded_dataset["train"], num_samples=16)
# 初始化模型
model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
# 训练分类头
model.fit(
sampled_train_dataset,
batch_size=8,
num_iterations=20,
)
# 评估
predictions = model.predict(encoded_dataset["test"]["text"])
print(accuracy.compute(predictions=predictions, references=encoded_dataset["test"]["label"]))
六、模型部署与生产化
1. 模型保存与加载
python
# 保存模型和分词器
model.save_pretrained("./distilbert-imdb")
tokenizer.save_pretrained("./distilbert-imdb")
# 加载模型
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("./distilbert-imdb")
tokenizer = AutoTokenizer.from_pretrained("./distilbert-imdb")
2. 部署到 Hugging Face Hub
python
from huggingface_hub import login, push_to_hub
login(token="YOUR_TOKEN")
model.push_to_hub("distilbert-imdb-sentiment")
tokenizer.push_to_hub("distilbert-imdb-sentiment")
七、常见问题与解决方案
-
显存不足:
- 减少 batch_size
- 启用梯度累积:
gradient_accumulation_steps=2 - 混合精度训练:
fp16=True
-
训练速度慢:
- 使用更高效的模型(如 DistilBERT)
- 增加 GPU 数量
- 调整学习率
-
过拟合:
- 增加正则化:
weight_decay=0.01 - 早停法:
early_stopping_patience=3 - 数据增强
- 增加正则化:
八、总结
本文通过实战案例展示了使用 Hugging Face 搭建文本分类模型的全流程,包括数据加载、预处理、模型选择、训练、评估和部署。Hugging Face 的强大生态系统(如 Trainer、Evaluate、SetFit)极大简化了 NLP 开发流程,即使是新手也能快速上手。未来可以探索更复杂的模型(如 DeBERTa)或结合领域数据进行微调,以进一步提升性能。
参考资料:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)