简单粗暴提升yolov5小目标检测能力
和yolov5最开始做的focus是类似的,对于输入的特征图(长宽为S),从左到右以及从上到下每scale个像素采样一次,假设scale=2,采样方式就和上图一样,经过这样采样的输出长宽就是S/2,最后将采样后的输出进行concatenate,通道数就是scale的平方,即4。左侧是yolov5原始模型的网络架构,右图则是增加SPD结构的yolov5网络架构,其中红框部分就是两网络的区别之处。在原
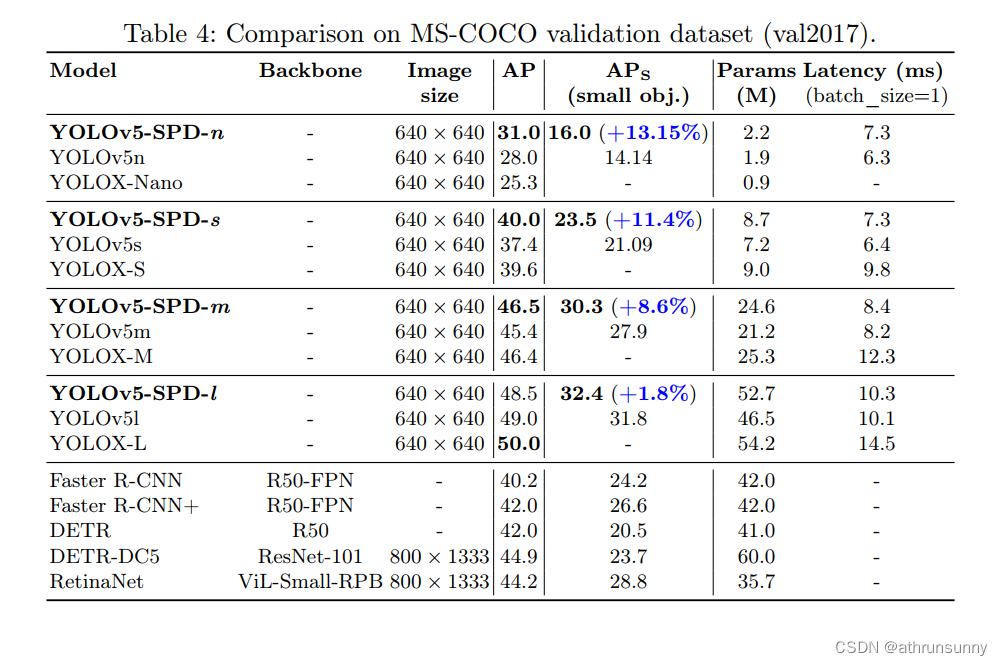
作者提出一种SPD组件,提升了yolov5各个模型在小目标上的检测能力,先看一下结论:
该组件作者给出了数学上的解释:

其实解释起来很简单,结合下图:
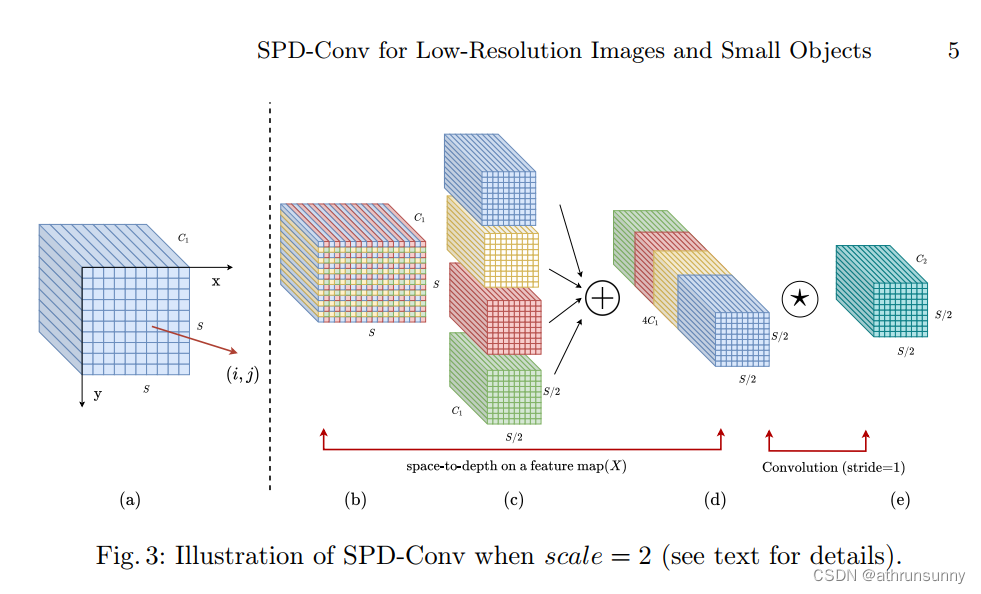
和yolov5最开始做的focus是类似的,对于输入的特征图(长宽为S),从左到右以及从上到下每scale个像素采样一次,假设scale=2,采样方式就和上图一样,经过这样采样的输出长宽就是S/2,最后将采样后的输出进行concatenate,通道数就是scale的平方,即4。
具体的应用,首先对比下网络架构的配置文件
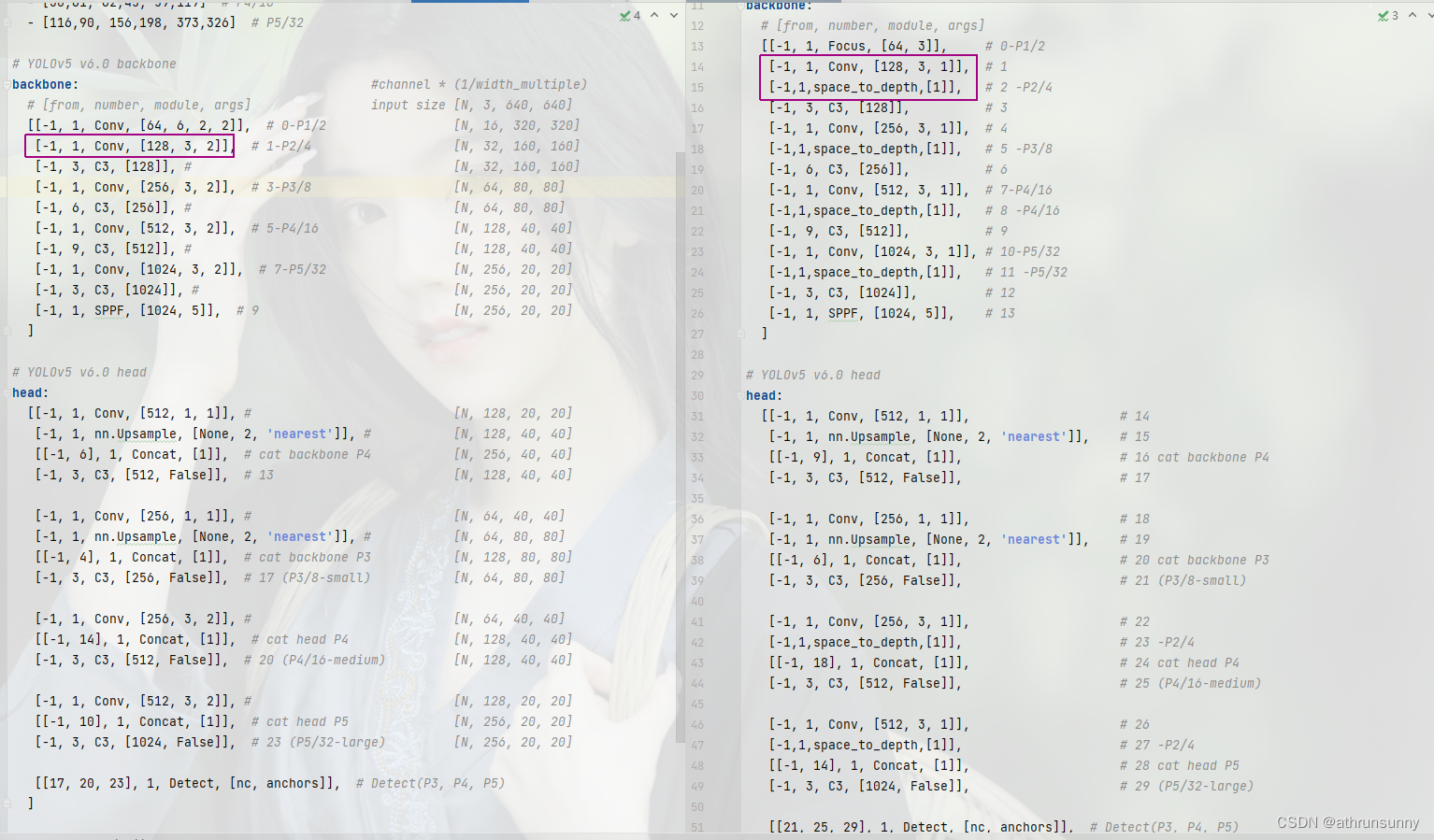
左侧是yolov5原始模型的网络架构,右图则是增加SPD结构的yolov5网络架构,其中红框部分就是两网络的区别之处 。
代码的实现也比较简单:
class space_to_depth(nn.Module):
# Changing the dimension of the Tensor
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
return torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
# size_tensor = x.size()
# return torch.cat([x[...,0:size_tensor[2]//2,0:size_tensor[3]//2],
# x[...,0:size_tensor[2]//2,size_tensor[3]//2:],
# x[...,size_tensor[2]//2:,0:size_tensor[3]//2],
# x[...,size_tensor[2]//2:,size_tensor[3]//2:] ],1)在coco val2017上的效果:

其中红色箭头就是两者的区别。
在原文中作者还将该结构应用在分类模型上,分类性能上也有一定的提升,感兴趣的可以看看原文。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)