CP-DETR:概念提示指南 DETR 实现更强大的通用目标检测论文阅读
通用目标检测的研究旨在将语言引入最先进的封闭集检测器中,并通过构建大规模(文本-区域)数据集进行训练,从而推广到开放集概念。然而,这些方法面临两个主要挑战:(i) 如何高效利用提示中的先验信息来泛化对象;(ii) 如何减少下游任务中的对齐偏差。封闭集目标检测:模型只需要识别出训练数据中出现过的目标,对于训练集以外的物体类别,模型不做识别或认为背景。开放集目标检测:模型不仅需要识别训练数据中已知的物
前言
这篇文章内容的主题是CP-DETR:Concept Prompt Guide DETR Toward StrongerUniversal Object Detection,也就是通过概念指导DETR实现更强大的通用目标检测。我将为大家讲一下文章主要内容,并把重点放在使用方法上。在学习此论文的时候,我遇到了许多不太清楚的概念,我在向AI提问后结合自己的理解,把它们也都放在了相应段落的后面。
一、文章总结
1.研究背景与问题
通用目标检测的研究旨在将语言引入最先进的封闭集检测器中,并通过构建大规模(文本-区域)数据集进行训练,从而推广到开放集概念。然而,这些方法面临两个主要挑战:(i) 如何高效利用提示中的先验信息来泛化对象;(ii) 如何减少下游任务中的对齐偏差。
封闭集目标检测:模型只需要识别出训练数据中出现过的目标,对于训练集以外的物体类别,模型不做识别或认为背景。
开放集目标检测:模型不仅需要识别训练数据中已知的物体类别,还要对训练数据中未知的物体具有一定的检测和区分能力。
先验信息:指的是在进行目标检测任务之前,从提示中所获得的预先存在的知识或信息。例如,文本提示中提到 “猫通常有四条腿和毛茸茸的身体”,这就是关于猫这个对象的先验信息,模型可以利用这些信息来辅助检测猫。
对齐偏差:是指在通用目标检测的下游任务中,模型的预测结果与实际目标之间存在的不一致或偏差。客观上,文本描述遵循长尾分布,不同的描述可能指向相同的图像区域,因此在预训练期间准确对齐所有文本和图像区域是不现实的。主观上,用户很难通过语言准确描述复杂对象。
2.方法
我们提出了一个强大的通用检测基础模型CP-DETR,该模型在几乎所有场景中都具有竞争力,且仅需一个预训练权重。具体来说,我们设计了一种高效的提示-视觉混合编码器,通过逐尺度和多尺度融合模块增强提示与视觉之间的信息交互。然后,通过提示多标签损失和辅助检测头,促使混合编码器充分利用提示信息。除了文本提示外,我们还设计了两种实用的概念提示生成方法:视觉提示和优化提示。
3.结论
CP-DETR在广泛的场景中展示了卓越的通用检测性能。
二、方法
我的方法内容可能与原文不太一样,我想的是要先知道文本提示、视觉提示、优化提示都是什么,然后再去学习它们与特征的混合过程。但其实提示的生成过程也有一些后面的内容比如说损失函数部分,所以大家还是整体地去理解比较好。我先来给大家介绍一下概念提示生成器中三种提示的生成与作用过程,再解释一下提示-视觉混合编码器,最后讲一下辅助检测头和提示多标签损失的作用。
1.概念提示生成器
文本提示
文本提示是将自然语言文本作为一种额外的信息,与图像数据结合,以帮助模型更准确地检测和识别物体。其原理是通过将文本中的语义信息转化为模型能够理解的特征或向量表示,与图像的视觉特征进行融合,从而引导模型关注图像中与文本描述相关的区域和目标。
操作方法:选用预训练的 CLIP 文本编码器提取文本特征,利用平均池化将词级文本特征聚合成句子级概念提示。为了减少检测幻觉(即预测输入图像中不存在的对象),我们在预训练中随机从文本字典中采样80个类别或描述作为负样本。然后,在CP-DETR的预训练中仅使用文本提示,整体训练目标是 的线性组合。
CLIP 文本编码器的主要作用是将文本输入转换为向量表示,以便与图像特征进行对比学习。通过这种方式,它能够学习到文本与图像之间的语义关联,使得模型可以理解文本描述与图像内容之间的对应关系。
工作原理:CLIP首先接收自然语言文本作为输入,然后通常经过transformer架构,对文本进行特征提取和编码,转换为一个向量,这个向量捕捉了文本的语义信息。然后该向量与经过CLIP图像编码器处理后的图像向量在特征空间中进行对比,计算它们之间的相似度,从而判断文本与图像是否匹配。
句子级概念提示:在使用文本编码器对一段文本处理时,会将文本中的每个词编码成向量表示,即词级文本特征。通过平均池化把每个词的向量融合为一个向量,即把语义信息融合到一个向量表示中,即得到了句子级概念提示。
负样本:负样本是当前图像中不存在的对象信息,模型在训练过程中,通过同时学习正样本(图像中实际存在的对象对应的文本和图像信息)和负样本(图像中不存在的对象的文本描述 ),可以逐渐学会区分真实存在和不存在的对象。负样本参与到损失函数的计算中,通过反向传播算法,促使模型的参数朝着能够正确区分正负样本的方向更新。
Ldecoder(解码器损失):由定位损失(包含 GIoU 损失和 L1 损失 )和对齐损失(焦点损失)组成。定位损失用于监督模型对目标物体位置的预测准确性,GIoU 损失关注预测框与真实框的重叠程度和相对位置关系,L1 损失衡量预测框坐标与真实框坐标之间的绝对误差,二者共同作用使模型精准定位目标。对齐损失则聚焦于模型预测结果与真实标签之间的分类一致性,焦点损失能够对难分类样本给予更大权重,增强模型对复杂或模糊样本的分类能力,从而确保模型在分类和定位任务上达到更好的效果。
Laux_head(辅助检测头损失):选择基于锚点的检测头,通过一对多的标签分配方式,为图像特征提供更密集、直接的监督信号。该损失由分类损失(焦点损失)、中心度损失(二元交叉熵损失)和 IoU 损失(GIoU 损失)构成。分类损失用于判断预测类别与真实类别的匹配程度;中心度损失衡量预测框中心与目标物体中心的接近程度,确保预测框能准确框住目标;IoU 损失进一步优化预测框与真实框的重叠度,辅助主检测头,提升模型对目标的检测精度。
Lprompt(提示多标签损失):在开放集预训练中,每个(图像,提示)对包含正提示和大量负提示,负提示在图像中无对应物体。通过对混合编码器输出的概念提示进行多标签分类损失计算,模型在融合过程中学习利用图像信息,抑制负概念提示,保留正提示,使融合后的概念提示更具判别力。
视觉提示
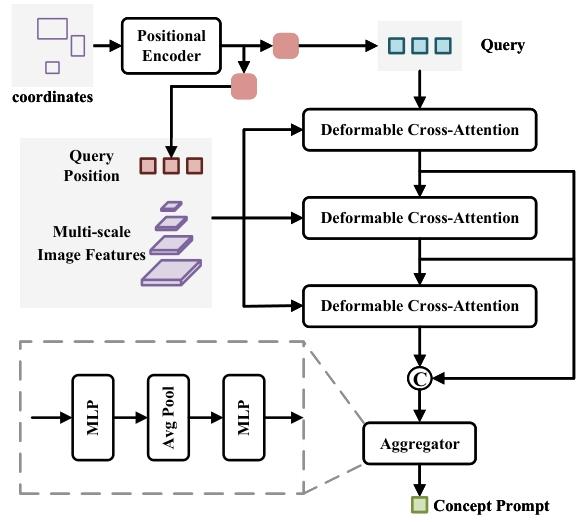
视觉提示直接使用图像信息来引用对象,避免了由于错误描述导致的对齐偏差。
操作方法:如图将 N 个归一化的框坐标经正弦余弦位置编码器编码,得到向量 ,再分别经两个线性层生成查询嵌入q和查询位置嵌入qpos 。借助交叉注意力机制从图像特征中提取概念信息,qpos限制提取范围以确保信息与框内容相关。通过三层注意力机制,并按通道拼接各层输出查询,最后经聚合器生成相应类别的概念提示。训练视觉提示编码器时,冻结预训练权重,采用Jiang et al.(2024)的框采样方法。训练目标除了解码器损失,还使用均方误差损失进行直接监督。训练目标如下
。
其中,K 是正类别的数量,表示通过视觉提示编码器获得的概念提示,
表示通过文本编码器获得的概念提示。
表示N个框中每个框坐标经过正弦-余弦位置编码器编码成了128维的向量。
优化提示
为了对概念提示进行优化,我们冻结所有模型参数,并使用可学习的嵌入层来初始化概念提示,然后通过微调对概念提示进行优化,使得它们能够更好地与模型的其他部分进行对齐。此外,我们提出了超类表示,考虑到下游场景中不同类别可能被标记为同一类别的情况。具体来说,类别 I 对应 M 个提示,通过映射表保存对应关系。最后,从 M 个提示中提取最大相似性值作为分类分数。由于不需要混合编码器优化,训练目标仅包含 Ldecoder。
可学习的嵌入层:它可以将离散的、高维的概念(比如文本中的单词、目标检测中的类别等 )映射为连续的、低维的向量表示。在这个场景中,可学习的嵌入层会根据数据的特点和模型的需求,为每个概念提示生成一个初始的向量表示。这个初始向量包含了概念的一些基本信息,但可能并不完全准确或与模型其他部分完美适配,所以需要进一步微调。
微调:这里的微调就是模型通过训练,根据损失函数来调整概念提示相关的参数。
2. 提示-视觉混合编码器
渐进式单尺度融合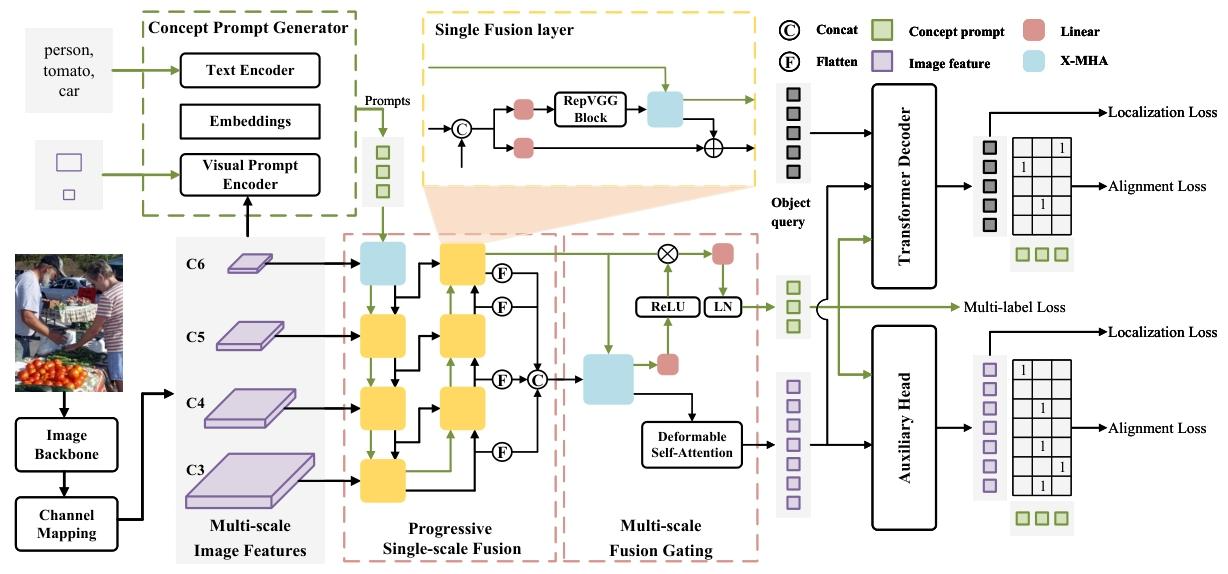
先使用跨模态多头注意力机制X-MHA将C6和提示P融合。其中,l表示提示融合的次数,t∈(0,1,2)表示阶段,0、1、2 分别表示无融合、自上而下融合和自下而上融合。然后,在自上而下和自下而上过程中,我们设计了一个单层融合层,如图 1 黄色虚线框所示,以两个相邻尺度的图像特征和提示作为输入。具体来说,相邻的特征图在通道上连接以获得混合特征
,并通过线性层和块(Ding et al., 2021)调整通道,以同时实现跨尺度和隐式跨模态信息融合。然后,使用 X - MHA 进行直接跨模态融合,获得更新的提示
和图像特征
。最后,通过逐元素求和输出阶段t中j尺度的图像特征
,将
与经过线性层后的
融合。公式如下:
C3、c4、c5、c6分别表示相对于原图1/8,1/16,1/32,1/64尺度的特征图。
X-MHA:跨模态多头注意力机制,通过计算注意力权重来实现跨模态交互。它会计算输入的图像特征(C6或
)与提示
之间的注意力分数根据计算得到的注意力权重,对输入的图像特征和提示进行加权求和等操作,从而得到更新后的提示
和图像特征变化量
(或更新后的特征图
)。更新后的提示
融合了图像特征的信息,语义更加丰富准确;图像特征
RepVGG Block:主要作用是通过卷积操作进一步提取特征,同时对不同通道的信息进行融合。
多尺度融合门控
为了避免由于逐尺度融合过程导致的信息丢失,我们提出在多尺度特征图上同时进行交互。将四个尺度的特征图展平并在空间维度上连接,形成全尺度特征。
和来自 PSF 的提示
的融合过程如下:
其中,DeformAttn是可变形自注意力(Zhu et al., 2021),LN是层归一化,表示通过可变形自注意力进行全尺度图像特征交互后混合编码器的图像部分输出.将四个尺度的特征图展平并连接形成全尺度特征,通过可变性自注意力和提示融合。
展平:展平操作就是将特征图从三维结构转换为一维向量。具体来说,就是把特征图在高度和宽度方向上的所有像素点按照一定的顺序(通常是按行或按列 )连接起来,忽略原来的空间位置关系,只保留通道维度上的信息。例如,对于一个大小为H×W×D的特征图,展平后会得到一个长度为H×W×D的一维向量。通过这种方式,将四个尺度的特征图都展平后,它们就从不同尺度的三维结构统一变成了一维向量形式。
3.辅助监督
辅助检测头
我们选择基于锚点的检测头以促进训练,这在封闭集检测中已被证明有效。辅助头采用一对多的标签分配,并通过锚点计算损失,锚点的数量与图像特征成正比,从而对图像特征应用更密集和直接的监督信号。我们使用对比层替换封闭集检测头中的分类层,并通过提示和图像特征的相似性 smn 表示类别分数,如下所示:
其中,d 是特征通道数,bias 是可学习的常数, 表示第 m 个锚点对应的图像特征,
表示第 n 个概念向量。通过这种简单的修改,封闭集检测头被转换为开放集形式,因此可以用于具有类别不确定性的预训练中的辅助监督。训练目标如下:
其中,是焦点损失,
是二元交叉熵损失,
是 GIoU 损失。这三个损失函数在文本提示那里已经说过了,便不再说明。
提示多标签损失
在开放集预训练中,每个(图像,提示)对中既有正提示也有大量负提示,负提示在图像中没有对应的对象。因此,我们可以在训练过程中统计提示的正负性,并自动生成多标签注释 g。例如,如果图像中有汽车,那么 “汽车” 提示就是正提示,对应的注释为 1;而 “飞机” 提示如果在图像中不存在,其注释为 0。混合编码器输出的概念提示通过 MLP 层映射到 1 维,然后与生成的多标签注释 g 一起计算二元交叉熵损失。
通过在单一模态上应用多标签分类损失,概念提示需要在融合过程中学习利用图像信息,从而拒绝负概念并保留正提示,使融合后的概念提示更具判别性。
总结
这篇内容与上篇内容一样,同样侧重于对文章大体上三种策略的解释。本文的主要创新就是把文本提示、视觉提示和优化提示融合为概念提示,然后设计了一种高效的提示-视觉混合编码器,通过渐进式单尺度融合和多尺度融合门控增强提示与视觉之间的信息交互,最后通过辅助检测头和提示多标签损失促使编码器充分利用提示信息。这篇文章内容还是比较多、比较难的,花费了2天左右的时间去完成,本来这篇论文我已经看过了,但是发现再去写博客的时候已经大脑空空。本篇内容仅供参考吧,大家发现不对劲的地方可以和我交流一下。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)