使用Pytorch、Transformers实现transformer encoder
·
使用Pytorch、Transformers实现transformer encoder
注意力机制
from torch import nn
from transformers import AutoConfig
from transformers import AutoTokenizer
model_ckpt = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
text = "time files like an arrow"
# add_special_tokens=False 去除了分词结果中的[CLS]和[SEP]
inputs = tokenizer(text, return_tensors="pt", add_special_tokens=False)
print(inputs.input_ids)
config = AutoConfig.from_pretrained(model_ckpt)
token_emb = nn.Embedding(config.vocab_size, config.hidden_size)
print(token_emb)
inputs_embeds = token_emb(inputs.input_ids)
print(inputs_embeds.size())
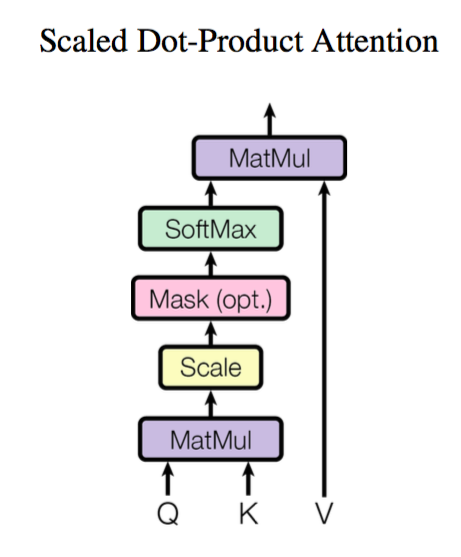
# 创建query, key, value向量序列 Q,K,V,并使用点积作为相似度函数来计算注意力分数
import torch
from math import sqrt
Q = K = V = inputs_embeds
dim_k = K.size(-1) # 768
# torch.bmm()向量点积运算
scores = torch.bmm(Q, K.transpose(1,2)) / sqrt(dim_k)
print(scores.size())
# 这里Q,K的序列长度都是5,因此生成了一个5x5的注意力分数矩阵
# 接下来应用Softmax标准化注意力权重
import torch.nn.functional as F
weights = F.softmax(scores, dim=-1)
print(weights.sum(dim=-1))
# 最后将注意力权重与value序列相乘
attn_outputs = torch.bmm(weights, V)
print(attn_outputs.shape)
print(attn_outputs.unsqueeze(-1))
运行结果

# 将上面的操作进行封装,方便后续使用
def scaled_dot_product_attention(query, key, value, query_mask=None, key_mask=None, mask=None):
dim_k = query.size(-1)
scores = torch.bmm(query, key.transpose(1, 2)) / sqrt(dim_k)
if query_mask is not None and key_mask is not None:
mask = torch.bmm(query_mask.unsqueeze(-1), key_mask.unsqueeze(1))
if mask is not None:
scores = scores.masked_fill(mask == 0, -float("inf"))
weight = F.softmax(scores, dim=-1)
return torch.bmm(weight, value)
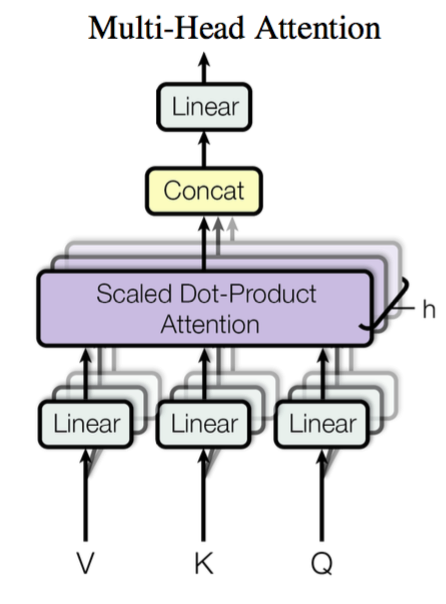
Multi-head Attention 多头注意力
# 实现多头注意力机制
# 首先实现一个头
from torch import nn
#实践中一般将 head_dim 设置为 embed_dim 的因数,这样 token 嵌入式表示的维度就可以保持不变,例如BERT有12个注意力头,因此每个头的维度被设置为 768/12=64
class AttentionHead(nn.Module):
def __init__(self, embed_dim, head_dim):
super().__init__()
self.q = nn.Linear(embed_dim, head_dim)
self.k = nn.Linear(embed_dim, head_dim)
self.v = nn.Linear(embed_dim, head_dim)
def forward(self, query, key, value, query_mask=None, key_mask=None, mask=None):
attn_outputs = scaled_dot_product_attention(
self.q(query), self.k(key), self.v(value), query_mask, key_mask, mask
)
return attn_outputs
# 最后拼接多个注意力头的输出就可以构建Multi-head Attention层了(这里在拼接后还通过一个线性变换来生成最后的输出张量)
class MultiHeadAttention(nn.Module):
def __init__(self, config):
super().__init__()
embed_dim = config.hidden_size
num_heads = config.num_attention_heads
head_dim = embed_dim // num_heads
self.heads = nn.ModuleList(
[AttentionHead(embed_dim, head_dim) for _ in range(num_heads)]
)
self.output_linear = nn.Linear(embed_dim, embed_dim)
def forward(self, query, key, value, query_mask=None, key_mask=None, mask=None):
x = torch.cat([
h(query, key, value, query_mask, key_mask, mask) for h in self.heads
], dim=-1)
return self.output_linear(x)
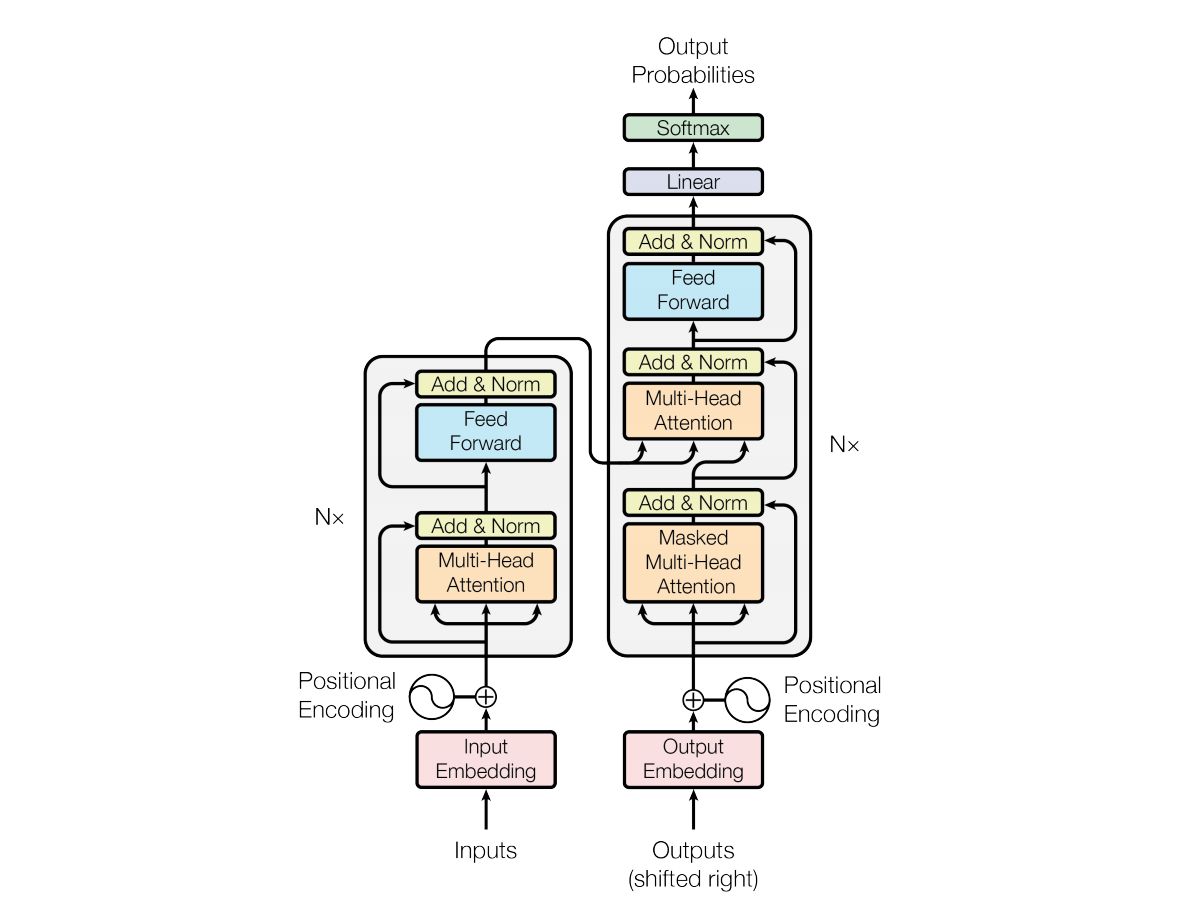
Transformer Feed-Forward Layer前馈层
- transformer模型机构
# Feed-Forward Layer前馈层
class FeedForward(nn.Module):
def __init__(self, config):
super().__init__()
# config.intermediate_size=3072 是词向量大小的4倍
self.linear1 = nn.Linear(config.hidden_size, config.intermediate_size)
self.linear2 = nn.Linear(config.intermediate_size, config.hidden_size)
self.gelu = nn.GELU()
# config.hidden_dropout_prob = 0.1
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, x):
x = self.linear1(x)
x = self.gelu(x)
x = self.linear2(x)
x = self.dropout(x)
return x
Layer Normalization
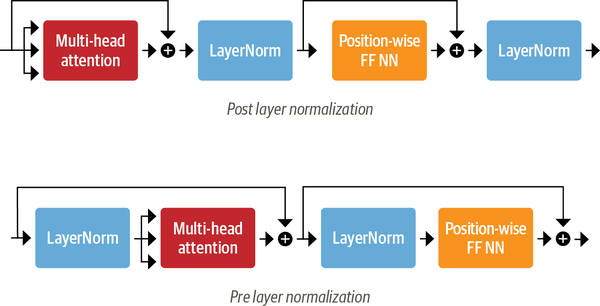
# Layer Normalization 正则化层负责将一批(batch)输入中的每一个都标准化为均值为0且具有单位方差;
# skip Connections 残差连接则是将张量直接传递给模型的下一层而不进行处理
# 采用 Pre layer normalization来构建Transformers Encoder层
class TransformerEncoderLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.layer_norm_1 = nn.LayerNorm(config.hidden_size)
self.layer_norm_2 = nn.LayerNorm(config.hidden_size)
self.attention = MultiHeadAttention(config)
self.feed_forward = FeedForward(config)
def forward(self, x, mask=None):
hidden_state = self.layer_norm_1(x)
x = x + self.attention(hidden_state, hidden_state, hidden_state, mask=mask)
x = x + self.feed_forward(self.layer_norm_2(x))
return x
Position Embeddings
# Positional Embeddings
# 由于注意力机制无法捕获词语之间的位置信息,因此Transformer模型还是用Position Embedings添加了词语的位置信息。
class Embeddings(nn.Module):
def __init__(self, config):
super().__init__()
self.token_embeddings = nn.Embedding(config.vocab_size, config.hidden_size)
# config.max_position_embeddings=512
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
# eps=ε 为了数值稳定而添加到分母的值,默认值1e-5
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=1e-12)
# default 0.5
self.dropout = nn.Dropout()
def forward(self, input_ids):
seq_length = input_ids.size(1)
# 这行代码的结果:tensor([[0, 1, 2, 3, 4]])
position_ids = torch.arange(seq_length, dtype=torch.long).unsqueeze(0)
token_embeddings = self.token_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
embeddings = token_embeddings + position_embeddings
embeddings = self.layer_norm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
# 将所有的层结合起来构建完整的Transformer Encoder
class TransformerEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.embeddings = Embeddings(config)
# config.num_hidden_layers=12
self.layers = nn.ModuleList([
TransformerEncoderLayer(config) for _ in range(config.num_hidden_layers)
])
def forward(self, x, mask=None):
x = self.embeddings(x)
for layer in self.layers:
x = layer(x, mask=mask)
return x
# 进行测试
from transformers import AutoConfig, AutoTokenizer
name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(name)
config = AutoConfig.from_pretrained(name)
text = "I have a dream."
tokens_ids = tokenizer(text, return_tensors="pt", add_special_tokens=False).input_ids
token_emb = torch.nn.Embedding(config.vocab_size, config.hidden_size)
encoder = TransformerEncoder(config)
print(encoder(tokens_ids).size())
运行结果
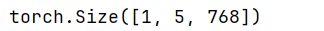
参考

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)