react大数据table_数据分析·数据探查背后的技术分享
背景随着DataWorks数据分析系统被越来越多人所喜爱,弹内外UV越来越高程序猿小哥哥小姐姐们特别开心,于是更加努力,绞尽脑汁地希望自己能更好地服务用户。数据探查就是我们为了帮助用户更好的掌握数据情报,倾情打造,最终呈现的功能之一。详细介绍,可以参看这篇文章介绍:https://zhuanlan.zhihu.com/p/105125065本文重点分享背后用到的部分技术。虚拟滚经测试发现,字段在1
背景
随着DataWorks数据分析系统被越来越多人所喜爱,弹内外UV越来越高
程序猿小哥哥小姐姐们特别开心,于是更加努力,绞尽脑汁地希望自己能更好地服务用户。
数据探查就是我们为了帮助用户更好的掌握数据情报,倾情打造,最终呈现的功能之一。

详细介绍,可以参看这篇文章介绍:https://zhuanlan.zhihu.com/p/105125065
本文重点分享背后用到的部分技术。
虚拟滚
经测试发现,字段在100列以上时,因为整体页面渲染的DOM元素变多,会导致浏览器渲染性能变差。在ODPS表当中,许多客户的字段量达到200列以上,可能出现性能瓶颈,导致用户体验不佳。为了解决此问题,我们引入了虚拟滚动的技术,从而提供更好的用户体验。
原理
虚拟滚动技术是由google所提出的一种懒加载技术,透过控制滚动轴(Scrolling)来有限制地渲染DOM元素。

可参看上图,它的原理是使用了一种moving-window的技巧,此类技巧在讯号处理上被经常使用于过滤杂讯。它的概念是假设使用者的屏幕是一扇窗,因为使用者隔着窗,他所能看到的视线范围是有限的,当使用者透过滚轮上下滑动时,就好比是使用者改变了视角,此时他所能看到的景色也不同。
透过这样的技巧,我们可以按需加载所需要的DOM元素,并移除不在视线范围内的DOM元素,达到有效控制DOM元素数量的目的。
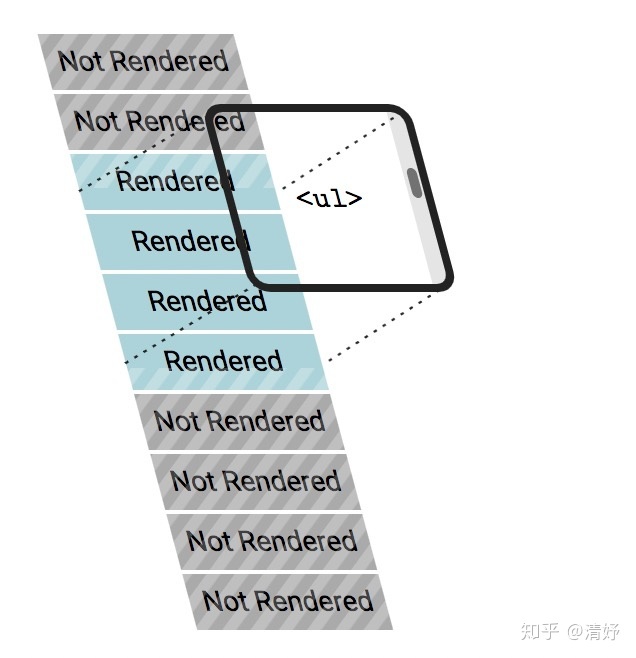
虚拟滚动的重难点在于位置的计算,首先我们必须知道所有的列表个数有多少,以计算滚动条与需要预留的高度;其次,我们需要知道每一个元素(cell)的高度,以计算在window当中可以呈现多少个元素,这个过程中不允许有1px的误差,否则将导致滚动的位置发生错乱。另外,我们还要考虑一些特殊情况,例如
- 当容器装不下内容物时,是否允许撑高宽度;
- 如何有效地渲染window内的元素并尽量避免重复渲染问题;
- 在不同的浏览器,不同的父容器中,怎么确保计算出的结果保持一致;
等,这些问题都解决之后,才能呈现给用户使用。
应用
目前,市面上有2个出色的虚拟滚动库可以供我们使用,一个是react-virtualized,一个是react-window。这两个库都提供了成熟的虚拟滚动组件,包含表格、列表、卡片等等。但react-virtualized在文档精细度、受喜欢程度(18k)以及延伸性(截至目前为止,官网列出的基于react-virtualized开发的三方库有7个)都较佳,因此我们选择它作为实践的工具。
react-virtualized提供了List、Grid、Table等基础组件供使用。因为详情页当中展示的是列表类型的可视化场景,因此我们使用了List组件。此外,为了自适应外部容器的宽高,以达到在不同解析度的屏幕下都能良好的展示,我们使用了AutoSizer组件。AutoSizer组件监听了父容器的宽高变化,并将宽高值更新给List组件进行重新渲染,简单的使用场景如下:
const TableList = ({ data, rowHeight, cells, tableWidth }) => (
<AutoSizer>
{({ width, height }) => (
<List
height={height}
rowCount={data.length}
rowHeight={rowHeight}
rowRenderer={(props: RowRenderProps) => {
return rowRenderer(data, cells, props);
}}
width={tableWidth ? tableWidth : width}
/>
)}
</AutoSizer>
);
当然,为了处理图表显示与每一行不同卡片的展示,我们整体的操作会更复杂一些,这里只对虚拟滚动的原理和应用做简单介绍。
图表智能展示
不同的数据,不同的分析意图,适合的图表都是不一样的。因此在选择要展示的图表类型时,必须有理有据。参照经典的决策树,
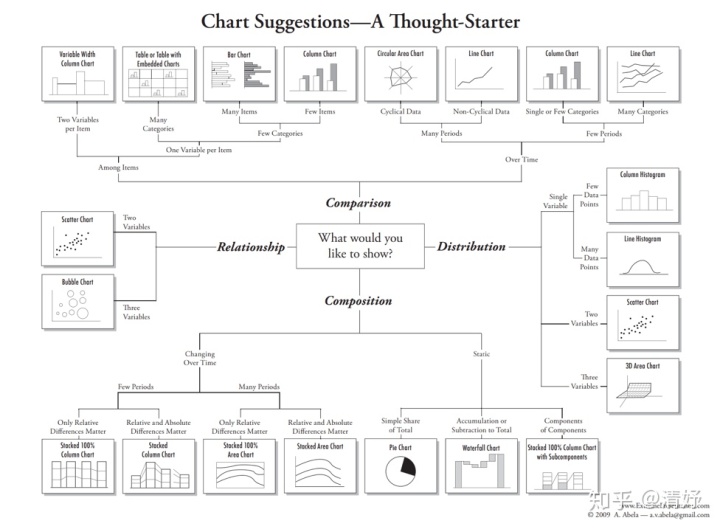
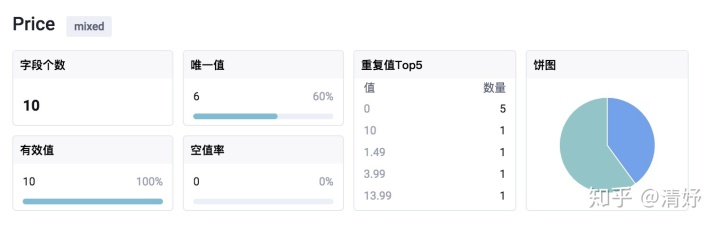
当探查到数据是混合类型时,由于在数据探查领域,用户更想了解的是数据类型的组合情况;因此选择了Composition分支,而我们要分析的数据是static的,且要展示的是整体的份额,因此选择了饼图作为展示方式。
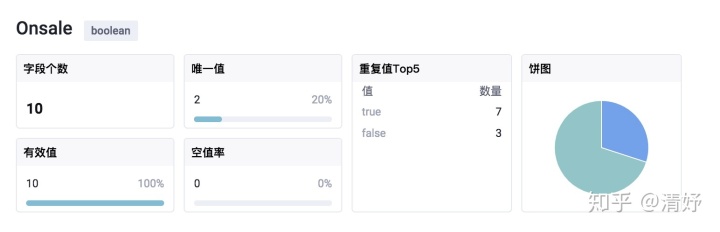
同理,当探查到数据是布尔型时,我们选择以饼图形式为用户展示数据的组合情况。
而当数据是数字型时,用户更想了解的是数据的分布情况;因此选择了决策树的Distribution分支,由于我们的数据是单变量的,装箱后可认为是有限个数据点,因此选择了柱状图。
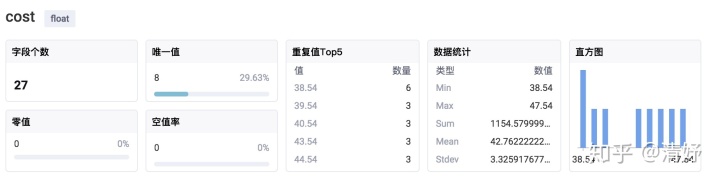
当然,同一列数据变更后,我们也会重新探查,推荐的图表类型也会自动更新。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)