【图神经网络工具】PyTorch Geometric基础知识(一)
PyTorch Geometric 基础知识
torch_geometric.data 和 torch_geometric.nn 部分。另外,还会介绍怎么设计自己的 Message Passing Layer。
Data 类
torch_geometric.data 包里有一个 Data 类,通过 Data 类可以很方便的创建图结构。
定义一个图结构,需要以下变量:
- 每个节点(node)的 features
- 边的连接关系或者边的 features
以下面的图结构为例,看看怎么用 Data 类创建图结构:
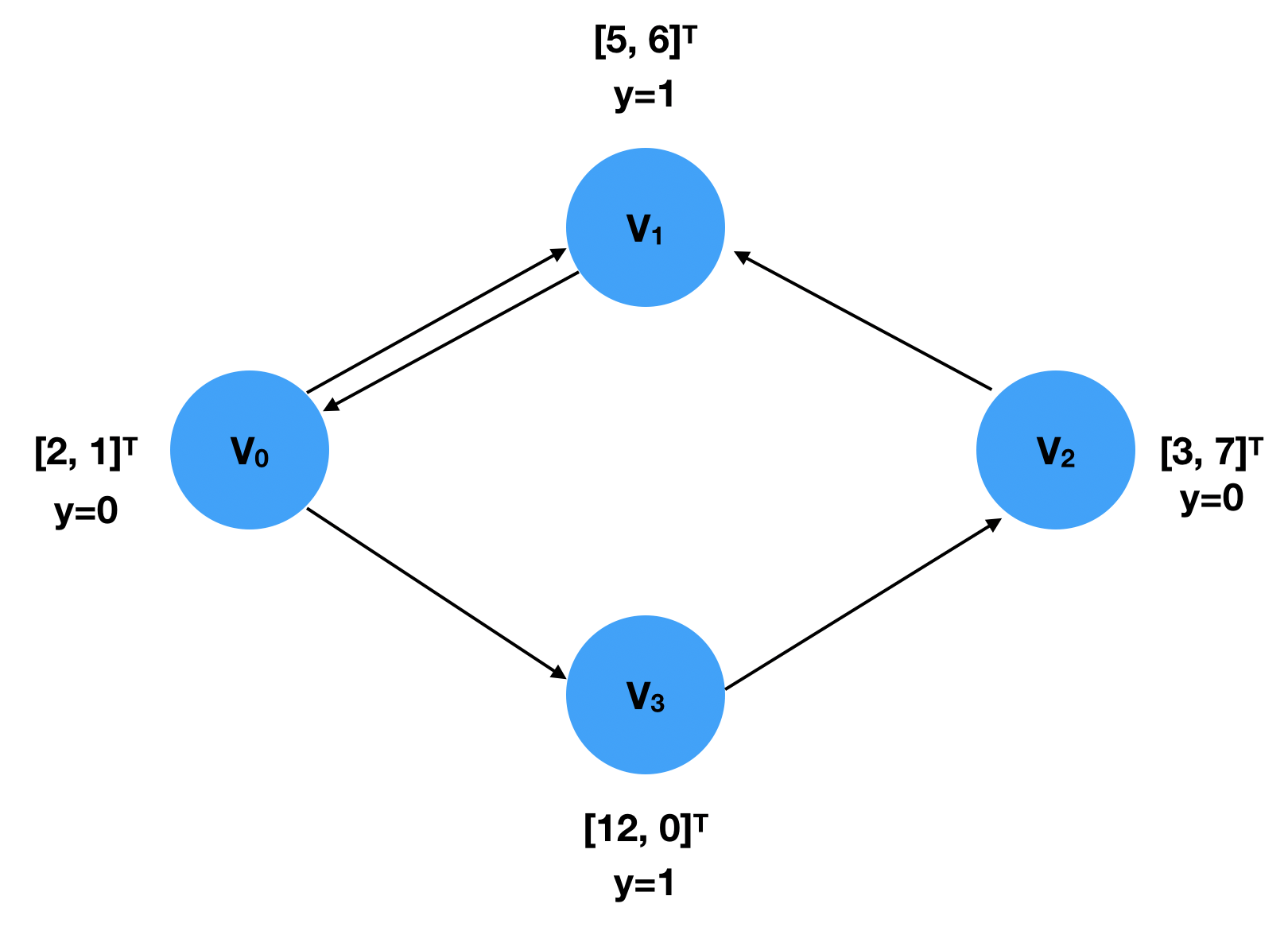
在上图中,一共有四个节点 v 1 , v 2 , v 3 , v 4 v_1,v_2,v_3,v_4 v1,v2,v3,v4,其中每个节点都有一个二维的特征向量和一个标签 y y y。这个特征向量和标签可以用 FloatTensor 来表示:
-
(1)导入了PyTorch和PyTorch Geometric中的
Data类,后者用于表示图数据。 -
(2)创建了节点特征张量
x和标签张量yx是一个 4x2 的张量,表示了4个节点的2维特征。y是一个包含4个元素的标签张量,每个元素对应一个节点的标签。
-
(3)定义了边的索引张量
edge_index:-
edge_index是一个 2x5 的张量,每一列代表一条边,每个边由两个节点的索引表示。例如,第一列
[0, 1]表示一个从节点0到节点1的边。 -
图的连接关系(边)可以用 COO 格式表示。COO 格式的维度是
[2, num_edges],- edge_index中:其中第一个列表是所有边上起始节点的 index,第二个列表是对应边上目标节点的 index
[0,1,2,3,0]:v0,v1,v2v3,v0
[1,0,1,2,3] : v1,v0,v1,v2,v3
-
-
(4)使用创建的节点特征、标签和边的索引来创建一个
Data对象:- 这里将节点特征
x、标签y和边的索引edge_index组合到一个Data对象中。
- 这里将节点特征
"""Data"""
import torch
from torch_geometric.data import Data
x = torch.tensor([[2,1],[5,6],[3,7],[12,0]])
y = torch.tensor([0,1,0,1])
edge_index = torch.tensor([[0,1,2,3,0],
[1,0,1,2,3]],dtype=torch.long)
data = Data(x=x,y = y,edge_index = edge_index)
print(data) # Data(x=[4, 2], edge_index=[2, 5], y=[4])
- 这个输出表示创建的
Data对象包含以下信息:x=[4, 2]:节点特征x是一个4x2的张量,表示4个节点的2维特征。edge_index=[2, 5]:边的索引edge_index是一个2x5的张量,表示图中的5条边。y=[4]:标签y包含4个元素,每个元素对应一个节点的标签。
注意上面的数据里定义边的顺序是无关紧要的,这个数据仅仅用来计算邻接矩阵用的,比如上面的定义和下面的定义是等价的:
edge_index = torch.tensor([[0, 2, 1, 0, 3],
[3, 1, 0, 1, 2]], dtype=torch.long)
Dataset类
PyG 里有两种数据集类型:InMemoryDataset 和 Dataset,
- 第一种适用于可以全部放进内存中的小数据集
- 第二种则适用于不能一次性放进内存中的大数据集。
InMemoryDataset
InMemoryDataset 中有下列四个函数需要我们实现:
- 导入 PyTorch 和 PyTorch Geometric 的相关模块
- 自定义数据集类是继承自 PyTorch Geometric 的
InMemoryDataset类,这是用于处理可以全部加载到内存中的数据集的基类。 __init__函数接受root、transform和pre_transform作为参数,用于初始化数据集对象。在构造函数中,首先调用了基类InMemoryDataset的构造函数,并加载了已处理的数据文件(如果存在),将数据和切片信息存储在self.data和self.slices中。
import torch
from torch_geometric.data import InMemoryDataset
"""创建 MyOwnDataset 类,继承自 InMemoryDataset"""
class MyOwnDataset(InMemoryDataset):
def __init__(self, root, transform=None, pre_transform=None):
super(MyOwnDataset, self).__init__(root, transform, pre_transform)
self.data, self.slices = torch.load(self.processed_paths[0])
raw_file_names()
返回一个包含所有未处理过的数据文件的文件名的列表。
起始也可以返回一个空列表,然后在后面要说的 process() 函数里再定义。
如果数据需要下载,也可以在这个函数中定义下载逻辑。
如果数据文件需要提前下载,可以在这里进行下载,并将文件保存到
self.raw_dir定义的文件夹位置。
@property
def raw_file_names(self):
return ['some_file_1', 'some_file_2', ...]
- 属性返回一个包含原始数据文件名的列表。你需要在这里列出数据集的原始文件名称,这些文件将在
self.raw_dir目录下寻找或下载。
processed_file_names()
返回一个包含所有处理过的数据文件的文件名的列表。
@property
def processed_file_names(self):
return ['data.pt']
download()
如果在数据加载前需要先下载,则在这里定义下载过程,下载到 self.raw_dir 中定义的文件夹位置。
如果不需要下载,返回 pass 即可。
def download(self):
# 下载数据文件到 self.raw_dir 目录
process()
这是最重要的一个函数,需要在这个函数里把数据处理成一个 Data 对象。
- 用于读取原始数据、进行必要的数据处理,然后创建
Data对象并将其保存为已处理的数据文件。 - 在这个函数中,你需要定义如何处理你的数据。
- 通常,你会读取原始数据文件、解析数据、将节点特征、边的连接关系等信息存储在
Data对象中,然后将Data对象保存到已处理的数据文件中。
def process(self):
# 读取数据,进行数据处理,创建 Data 对象并保存
- 在定义完数据集类后,用户可以创建一个数据集对象
dataset = MyOwnDataset(root='path_to_dataset_directory')
import torch
from torch_geometric.data import InMemoryDataset
class MyOwnDataset(InMemoryDataset):
def __init__(self, root, transform=None, pre_transform=None):
super(MyOwnDataset, self).__init__(root, transform, pre_transform)
self.data, self.slices = torch.load(self.processed_paths[0])
@property
def raw_file_names(self):
return ['some_file_1', 'some_file_2', ...]
@property
def processed_file_names(self):
return ['data.pt']
def download(self):
# Download to `self.raw_dir`.
def process(self):
# Read data into huge `Data` list.
data_list = [...]
if self.pre_filter is not None:
data_list [data for data in data_list if self.pre_filter(data)]
if self.pre_transform is not None:
data_list = [self.pre_transform(data) for data in data_list]
data, slices = self.collate(data_list)
torch.save((data, slices), self.processed_paths[0])
DataLoader
将数据按 batch 传给 model,定义的方法如下,需要制定 batch_size 和 dataset:
loader = DataLoader(dataset, batch_size=512, shuffle=True)
- 每个 loader 的循环都返回一个
Batch对象
for batch in loader:
batch
>>> Batch(x=[1024, 21], edge_index=[2, 1568], y=[512], batch=[1024])
Batch相比Data对象多了一个batch参数,告诉我们这个 batch 里都包含哪些 nodes,便于计算
Creating MessagePassing
Message Passing 的公式如下:
x i ( k ) = γ ( k ) ( x i ( k − 1 ) , ⨁ j ∈ N ( i ) ϕ ( k ) ( x i ( k − 1 ) , x j ( k − 1 ) , e j , i ) ) , \mathbf{x}_i^{(k)} = \gamma^{(k)} \left( \mathbf{x}_i^{(k-1)}, \bigoplus_{j \in \mathcal{N}(i)} \, \phi^{(k)}\left(\mathbf{x}_i^{(k-1)}, \mathbf{x}_j^{(k-1)},\mathbf{e}_{j,i}\right) \right), xi(k)=γ(k)
xi(k−1),j∈N(i)⨁ϕ(k)(xi(k−1),xj(k−1),ej,i)
,
- x x x表示节点的embedding
- e e e:表示边的特征
- ⨁ \bigoplus ⨁:表示可微分、排列不变的函数,聚合aggregation函数。eg:sum,mean,max
- ϕ \phi ϕ:表示message函数
- γ \gamma γ:表示update函数
- 上标表示层的index,eg:k=1的时候,x则表示所有输入网络的图结构数据
- γ \gamma γ和 ϕ \phi ϕ:表示可谓分函数,eg:MLPs(多层感知机)
Message基类
- 作用:用于帮助构建消息传递图神经网络(GNN)。这个基类简化了消息传递和节点更新的实现
[MessagePassing]基类,它通过自动处理消息传播来帮助创建此类消息传递图神经网络。
- 只需定义功能 ϕ \phi ϕ,即
message(),和 γ \gamma γ,即update(), - 以及要使用的聚合方案,即
aggr="add",aggr="mean"或aggr="max"。
初始化函数 MessagePassing(aggr=“add”, flow=“source_to_target”, node_dim=-2)
aggr:指定消息如何进行聚合的方案,可以是"add"、“mean"或"max”。"add"表示将所有消息相加,"mean"表示取平均值,"max"表示取最大值。flow:指定消息传递的方向,可以是"source_to_target"或"target_to_source"。"source_to_target"表示消息从源节点传递到目标节点,"target_to_source"则相反。node_dim:指示消息传播沿哪个轴进行的属性。通常,它是负数,例如-2,表示在输入张量的倒数第二个维度上执行消息传播。
propagate(edge_index,size= None,**kwargs)
调用 message 和 update 函数
-
这是开始传播消息的初始调用,需要提供以下参数:
edge_index:表示图中边的索引。size:表示消息传递的图的大小(可选)。这是一个二元组,表示图的节点数量。如果不提供,框架会自动计算。**kwargs:可以包含传递给message()函数的任何其他参数。
此函数用于启动消息传播,并执行一些必要的准备工作,如构建消息和更新节点嵌入所需的所有附加数据。需要注意,
propagate()不仅适用于交换消息的情况,还可以用于交换消息的一般稀疏分配矩阵,例如二分图。如果设置了size,则假设分配矩阵是方阵。这个函数的目的是初始化传播过程。
MessagePassing.propagate(edge_index, size=None, **kwargs):开始传播消息的初始调用。接收边索引以及构建消息和更新节点嵌入所需的所有附加数据。注意,propagate()不限于仅在形状的方邻接矩阵中交换消息,而是还可以通过作为附加参数传递而在形状的一般稀疏分配矩阵(*例如,二分图)中交换消息。*如果设置为,则假定分配矩阵是方阵。对于具有两个独立的节点和索引集且每个集保存其自己的信息的二分图,可以通过将信息作为元组传递来标记此分割,例如。[N, N]``[N, M]``size=(N, M)Nonex=(x_N, x_M)
message(**kwargs)
这个函数定义了对于每个节点对 ( x i , x j ) (x_i,x_j) (xi,xj),怎样生成信息(message)。
MessagePassing.message(...):构造消息到节点 i i i类比于 ϕ \phi ϕ对于每条边 ( j , i ) ∈ ϵ (j,i)\in \epsilon (j,i)∈ϵ如果flow="source_to_target"和 ( j , i ) ∈ ϵ (j,i)\in \epsilon (j,i)∈ϵ如果flow="target_to_source"。可以采用最初传递给 的任何参数propagate()。另外,传递给的张量propagate()可以映射到各自的节点 i i i和 j j j通过将_i或附加_j到变量名称,例如x_i和x_j。注意,我们一般指的是 i i i作为聚合信息的中心节点,参考 j j j作为相邻节点,因为这是最常见的符号。- 该函数用于构造消息,并根据消息传递的方向(“source_to_target” 或 “target_to_source”)为每个边上的目标节点生成消息。
- 此函数用于定义消息的生成过程。它可以接收与
propagate()函数中的任何参数相同的参数。在消息的生成中,通常会将目标节点(target node)作为中心节点(center node),并引用源节点(source node)作为相邻节点(neighbor node)。 - 这是因为这种表示方式在GNN中最为常见。
- 此函数用于定义消息的生成过程。它可以接收与
update(aggr_out, **kwargs)
这个函数利用聚合好的信息(message)更新每个节点的 embedding。
-
MessagePassing.update(aggr_out, ...):更新节点嵌入,类似于 γ \gamma γ对于每个节点 i ∈ V i\in V i∈V。将聚合的输出作为第一个参数以及最初传递给 的任何参数propagate()。 -
该函数用于更新节点的嵌入表示,类似于
message()函数对每个节点的消息。aggr_out参数是在propagate()函数中聚合的输出。这个函数用于更新每个节点的状态或嵌入。同样,它可以接收propagate()函数中的其他参数。
GCN举例
GCN层数学表示
x i ( k ) = ∑ j ∈ N ( i ) ∪ { i } 1 deg ( i ) ⋅ deg ( j ) ⋅ ( W ⊤ ⋅ x j ( k − 1 ) ) + b , \mathbf{x}_i^{(k)} = \sum_{j \in \mathcal{N}(i) \cup \{ i \}} \frac{1}{\sqrt{\deg(i)} \cdot \sqrt{\deg(j)}} \cdot \left( \mathbf{W}^{\top} \cdot \mathbf{x}_j^{(k-1)} \right) + \mathbf{b}, xi(k)=j∈N(i)∪{i}∑deg(i)⋅deg(j)1⋅(W⊤⋅xj(k−1))+b,
- x i ( k ) \mathbf{x}_i^{(k)} xi(k) 表示第 k k k 层中节点 i i i 的特征。
- N ( i ) \mathcal{N}(i) N(i) 表示与节点 i i i 相邻的节点集合。
- deg ( i ) \deg(i) deg(i) 表示节点 i i i 的度数(即与节点 i i i 相连的边的数量)。
- W \mathbf{W} W 表示权重矩阵。
- b \mathbf{b} b 表示偏置向量。
GCN的每一层中,节点的特征 x i ( k ) \mathbf{x}_i^{(k)} xi(k) 通过以下几个步骤来更新
其中相邻节点特征首先通过权重矩阵进行变换 W W W,按其程度归一化,最后总结。最后,我们应用偏置向量 b b b到聚合输出。这个公式可以分为以下几个步骤:
- 将自环添加到邻接矩阵:这意味着每个节点都与自己相邻。
- 通过权重矩阵 W \mathbf{W} W 线性变换节点特征矩阵:将相邻节点的特征与权重矩阵相乘并求和。
- 计算归一化系数:将节点度数的平方根相乘,用于归一化相邻节点的特征。
- 标准化节点特征 ϕ \phi ϕ:将上述步骤得到的值除以归一化系数。
- 总结相邻节点特征("add"聚合):将相邻节点的标准化特征相加,用于更新节点的特征。
- 应用最终偏差向量 b \mathbf{b} b:将偏置向量加到聚合输出中,得到最终的节点特征。
这些步骤描述了GCN层的数学运算过程,每一层都使用相同的权重矩阵 W \mathbf{W} W 和偏置向量 b \mathbf{b} b,但更新后的节点特征 x i ( k ) \mathbf{x}_i^{(k)} xi(k) 不断迭代。
实现步骤:
在代码中,GCN层的实现通常包括以下几个步骤:
- 构建包含自环的邻接矩阵。
- 使用权重矩阵 W \mathbf{W} W 对节点特征进行线性变换。
- 计算并归一化每个节点的度数的平方根,以用于标准化。
- 使用GCN层的聚合函数(通常是"add")来总结相邻节点的特征。
- 应用偏置向量 b \mathbf{b} b。
这些步骤中的前三步通常在消息传递之前进行计算,而后两步则在 MessagePassing 基类中实现。
实现
添加自环、线性变换、归一化、消息传递和偏置。这个层可以用于构建GCN模型,并用于图数据上的节点分类等任务。
- Step 1: 添加自环(Add self-loops)
- 通过
add_self_loops函数向邻接矩阵添加自环,确保每个节点都与自己相邻。这是GCN的一部分,以便每个节点在消息传递时也考虑自身的特征。
- 通过
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))
-
Step 2: 线性变换(Linear Transformation)
x = self.lin(x)接下来,节点特征矩阵
x通过一个线性变换self.lin,其中包含了权重矩阵,将输入特征in_channels映射到输出特征out_channels。 -
Step 3: 计算归一化系数(Compute Normalization)
row, col = edge_index deg = degree(col, x.size(0), dtype=x.dtype) deg_inv_sqrt = deg.pow(-0.5) deg_inv_sqrt[deg_inv_sqrt == float('inf')] = 0 norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]在这一步中,首先计算了每个节点的度数
deg,然后计算了度数的负平方根deg_inv_sqrt,以用于归一化。特别地,将度数为0的节点的负平方根设置为0,以避免除以0的情况。最后,通过row和col数组索引,计算了边的归一化系数norm。 -
Step 4-5: 消息传递(Message Propagation)
out = self.propagate(edge_index, x=x, norm=norm)在这一步中,使用
propagate函数来执行消息传递。propagate函数是MessagePassing基类提供的,它会调用message函数和后续的聚合(在此处是"add"聚合)。 -
Step 6: 最终偏置(Final Bias)
out += self.bias最后,将一个偏置向量
self.bias加到传播后的结果out中。
import torch
from torch.nn import Linear, Parameter
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
class GCNConv(MessagePassing):
# GCNConv类继承自PyTorch Geometric中的MessagePassing类。MessagePassing类是构建图神经网络层的基础类,它处理了消息传递的自动化。
def __init__(self, in_channels, out_channels):
super().__init__(aggr='add') # "Add" aggregation (Step 5). # 调用父类的初始化函数,并指定了消息聚合的方式为"add",表示将消息相加以更新节点的表示(GCN的常见聚合方式)。
self.lin = Linear(in_channels, out_channels, bias=False) # 定义了一个线性变换层(Linear),它用于线性变换节点特征。输入特征的维度为in_channels,输出特征的维度为out_channels,并且设置了bias参数为False,表示不使用偏差项。
self.bias = Parameter(torch.empty(out_channels)) # 定义了一个可学习的偏差向量。
self.reset_parameters() # 调用了reset_parameters方法,用于初始化权重和偏差。
def reset_parameters(self):
"""这个方法用于初始化GCN层的权重和偏差"""
self.lin.reset_parameters() # 初始化线性变换层的权重
self.bias.data.zero_() # 将偏差向量的数据初始化为零
def forward(self, x, edge_index):
"""定义了GCN层的前向传播过程"""
# x has shape [N, in_channels]
# edge_index has shape [2, E]
# Step 1: Add self-loops to the adjacency matrix.
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0)) # 在邻接矩阵中添加自环,以确保每个节点都能考虑到自身的信息。
# Step 2: Linearly transform node feature matrix.
x = self.lin(x) # 将节点特征进行线性变换,即对节点特征矩阵乘以权重矩阵。
# Step 3: Compute normalization.
row, col = edge_index # 从边索引中获取源节点和目标节点的信息
deg = degree(col, x.size(0), dtype=x.dtype) # 计算每个节点的度数(即相邻节点的数量)。
deg_inv_sqrt = deg.pow(-0.5) # 计算度数的负平方根,用于归一化。
deg_inv_sqrt[deg_inv_sqrt == float('inf')] = 0
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col] # 根据度数的负平方根计算归一化系数。
# Step 4-5: Start propagating messages.
out = self.propagate(edge_index, x=x, norm=norm)# 调用propagate方法进行消息传递。这一步是核心的消息传递过程,根据GCN的公式进行节点特征的更新
# Step 6: Apply a final bias vector.
out += self.bias # 将偏差向量加到更新后的节点特征上
return out
def message(self, x_j, norm):
"""这个方法用于定义如何构造消息,即如何计算节点之间传递的信息。"""
# x_j has shape [E, out_channels]
# x_j:表示相邻节点的特征。
# norm:表示归一化系数。这个方法的目的是将相邻节点的特征归一化。
# Step 4: Normalize node features.
return norm.view(-1, 1) * x_j # 表示相邻节点的特征
-
[
GCNConv]继承自[MessagePassing]with"add"传播。 -
该层的所有逻辑都发生在其
forward()方法中。- 首先使用函数将自循环添加到边缘索引[
torch_geometric.utils.add_self_loops()](步骤 1), - 并通过调用实例来线性变换节点特征[
torch.nn.Linear](步骤 2)。
- 首先使用函数将自循环添加到边缘索引[
-
归一化系数由节点度导出 d e g ( i ) deg(i) deg(i)对于每个节点 i i i其转变为 1 / ( deg ( i ) ⋅ deg ( j ) ) 1/(\sqrt{\deg(i)} \cdot \sqrt{\deg(j)}) 1/(deg(i)⋅deg(j))对于每条边 ( j , i ) ∈ E (j,i) \in \mathcal{E} (j,i)∈E。结果保存在
normshape张量中(步骤 3)。[num_edges, ] -
然后调用
propagate(),它在内部调用message(),aggregate()和update()。传递节点嵌入x和归一化系数norm作为消息传播的附加参数。 -
在
message()函数中,需要x_j通过 来规范化相邻节点的特征norm。x_j表示提升张量,其中包含每条边的源节点特征,即每个节点的邻居。- 可以通过将
_i或附加_j到变量名称来自动提升节点特征。 - 事实上,任何张量都可以通过这种方式转换,只要它们包含源或目标节点特征。
conv = GCNConv(16, 32)
x = conv(x, edge_index)
Implementing the Edge Convolution
边缘卷积层处理图或点云,数学上定义为
x i ( k ) = max j ∈ N ( i ) h Θ ( x i ( k − 1 ) , x j ( k − 1 ) − x i ( k − 1 ) ) , \mathbf{x}_i^{(k)} = \max_{j \in \mathcal{N}(i)} h_{\mathbf{\Theta}} \left( \mathbf{x}_i^{(k-1)}, \mathbf{x}_j^{(k-1)} - \mathbf{x}_i^{(k-1)} \right), xi(k)=j∈N(i)maxhΘ(xi(k−1),xj(k−1)−xi(k−1)),
h Θ h_{\mathbf{\Theta}} hΘ表示 MLP。与 GCN 层类似,可以使用MessagePassing类来实现该层,这次使用"max"聚合:
import torch
from torch.nn import Sequential as Seq, Linear, ReLU
from torch_geometric.nn import MessagePassing
class EdgeConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super().__init__(aggr='max') # "Max" aggregation.
self.mlp = Seq(Linear(2 * in_channels, out_channels),
ReLU(),
Linear(out_channels, out_channels))
EdgeConv类继承自MessagePassing,是一个自定义的图卷积层。def __init__(self, in_channels, out_channels)::初始化函数,接受输入特征的维度in_channels和输出特征的维度out_channels作为参数。super().__init__(aggr='max'):调用父类MessagePassing的初始化函数,并指定消息聚合方式为"max",表示使用最大值聚合。self.mlp = Seq(Linear(2 * in_channels, out_channels), ReLU(), Linear(out_channels, out_channels)):定义了一个多层感知器(MLP)模型,包含两个线性层和一个ReLU激活函数。MLP的输入维度是2 * in_channels,输出维度是out_channels。
def forward(self, x, edge_index):
# x has shape [N, in_channels]
# edge_index has shape [2, E]
return self.propagate(edge_index, x=x)
forward方法:定义了层的前向传播过程,接受节点特征张量x和边索引张量edge_index作为输入。return self.propagate(edge_index, x=x):调用propagate方法,进行消息传递,并将结果返回。
def message(self, x_i, x_j):
# x_i has shape [E, in_channels]
# x_j has shape [E, in_channels]
tmp = torch.cat([x_i, x_j - x_i], dim=1) # tmp has shape [E, 2 * in_channels]
return self.mlp(tmp)
message方法:定义了如何构造消息,接受源节点特征张量x_i和目标节点特征张量x_j作为输入。tmp = torch.cat([x_i, x_j - x_i], dim=1):将源节点特征x_i和相对于源节点的目标节点特征x_j - x_i按列(dim=1)拼接在一起,得到临时张量tmp。return self.mlp(tmp):将临时张量tmp传入多层感知器(MLP)中进行处理,并返回处理后的结果,作为构造的消息。
这个EdgeConv层通过在前向传播中调用propagate方法,自动处理了消息传递和消息聚合,可以用于构建图神经网络模型。这种层常用于图分类、节点分类等任务。
在函数内部message(),我们用于转换每条边的self.mlp目标节点特征x_i和相对源节点特征x_j - x_i( ( j , i ) ∈ E (j,i) \in \mathcal{E} (j,i)∈E
Heterogeneous Graph Learning
现实世界中的大量数据集都是以异构图的形式存储的,这促使 PyG 为它们引入了专门的功能。例如,推荐领域的大多数图(如社交图)都是异构图,因为它们存储了不同类型实体及其不同类型关系的信息。将介绍如何将异构图映射到 PyG,以及如何将它们用作图神经网络模型的输入。
异构图(Heterogeneous Graph)是图数据的一种形式,其中节点和边可以具有不同的类型或属性。在异构图中,节点可以表示不同种类的实体,而边表示这些实体之间的关系或交互。异构图广泛用于描述复杂系统中的多模态数据、多关系数据以及具有多种属性的实体之间的关系。
异构图通常包括以下主要元素:
- 节点(Nodes):异构图中的节点代表不同类型或类别的实体。每种类型的节点可以具有不同的属性和特征。例如,在社交网络中,节点可以表示用户、文章、评论等不同类型的实体。
- 边(Edges):边表示不同类型节点之间的关系或连接。异构图中的边可以有不同的类型,不同类型的边可以表示不同的关系。例如,在一个电子商务平台上,边可以表示用户购买商品、用户评论商品等不同类型的关系。
- 节点类型(Node Types):异构图中的节点被分为不同的类型。每个节点类型可以具有特定的属性和特征。节点类型通常用于区分不同种类的实体。
- 边类型(Edge Types):异构图中的边也被分为不同的类型,用于表示不同类型的关系或交互。每种边类型可以具有不同的含义和属性。
- 节点属性(Node Attributes):每个节点可以具有不同的属性,这些属性描述了节点的特征。节点属性通常是关于节点的信息,如用户的年龄、商品的类别等。
- 边属性(Edge Attributes):每种边类型可以具有不同的属性,用于描述不同类型的关系。边属性通常包含了关于边的额外信息,如交互的时间、评论的内容等。
异构图的应用领域非常广泛,包括社交网络分析、推荐系统、知识图谱构建、生物信息学等。在这些领域,异构图能够更准确地捕捉不同类型实体之间的复杂关系,从而提供更有力的分析和预测能力。
Example Graph

给定的异构图有 1,939,743 个节点,分为作者、论文、机构和研究领域四种节点类型。它还具有 21,111,007 条边,这些边也属于以下四种类型之一:
- writes:作者写了一篇特定的论文
- affiliated with:作者附属于特定机构
- cites:一篇论文引用了另一篇论文
- has topic:一篇论文有特定研究领域的主题
该图的任务是根据图中存储的信息推断每篇论文(会议或期刊)的地点。
创建异构图
首先,可以创建一个 类型的数据对象[torch_geometric.data.HeteroData],为每个类型分别定义节点特征张量、边索引张量和边特征张量:
from torch_geometric.data import HeteroData
data = HeteroData()
data['paper'].x = ... # [num_papers, num_features_paper]
data['author'].x = ... # [num_authors, num_features_author]
data['institution'].x = ... # [num_institutions, num_features_institution]
data['field_of_study'].x = ... # [num_field, num_features_field]
data['paper', 'cites', 'paper'].edge_index = ... # [2, num_edges_cites]
data['author', 'writes', 'paper'].edge_index = ... # [2, num_edges_writes]
data['author', 'affiliated_with', 'institution'].edge_index = ... # [2, num_edges_affiliated]
data['paper', 'has_topic', 'field_of_study'].edge_index = ... # [2, num_edges_topic]
data['paper', 'cites', 'paper'].edge_attr = ... # [num_edges_cites, num_features_cites]
data['author', 'writes', 'paper'].edge_attr = ... # [num_edges_writes, num_features_writes]
data['author', 'affiliated_with', 'institution'].edge_attr = ... # [num_edges_affiliated, num_features_affiliated]
data['paper', 'has_topic', 'field_of_study'].edge_attr = ... # [num_edges_topic, num_features_topic]
节点或边张量将在第一次访问时自动创建,并通过字符串键进行索引。节点类型由单个字符串标识,而边类型通过使用三元组字符串来标识:边类型标识符以及边类型可以存在于其间的两个节点类型。因此,数据对象允许每种类型具有不同的特征维度。(source_node_type, edge_type, destination_node_type)
包含按属性名称而不是按节点或边类型分组的异构信息的字典可以直接访问data.{attribute_name}_dict并用作 GNN 模型的输入:
model = HeteroGNN(...)
output = model(data.x_dict, data.edge_index_dict, data.edge_attr_dict)
存在该数据集,则可以直接导入使用。特别是,它将被root自动下载并处理。
from torch_geometric.datasets import OGB_MAG
dataset = OGB_MAG(root='./data', preprocess='metapath2vec')
data = dataset[0]
data可以打印该对象以进行验证
"""
HeteroData(
paper={
x=[736389, 128],
y=[736389],
train_mask=[736389],
val_mask=[736389],
test_mask=[736389]
},
author={ x=[1134649, 128] },
institution={ x=[8740, 128] },
field_of_study={ x=[59965, 128] },
(author, affiliated_with, institution)={ edge_index=[2, 1043998] },
(author, writes, paper)={ edge_index=[2, 7145660] },
(paper, cites, paper)={ edge_index=[2, 5416271] },
(paper, has_topic, field_of_study)={ edge_index=[2, 7505078] }
)
"""
Utility Functions
该类[torch_geometric.data.HeteroData]提供了许多有用的实用函数来修改和分析给定的图形。这些函数可以用于修改和分析给定的异构图数据。这些函数有助于用户更灵活地操作异构图数据
####(1)单独索引节点或边缘数据
可以使用索引操作来访问异构图中的单个节点或边缘数据
paper_node_data = data['paper'] # 获取单个节点类型的数据
cites_edge_data = data['paper', 'cites', 'paper'] # 获取特定边类型的数据
(2)操作边类型的简化
- 如果边类型可以由source_node类型和target_node类型对来唯一标识,那么可以通过以下操作来获取边缘数据
cites_edge_data = data['paper', 'paper'] # 使用节点类型来获取边缘数据
cites_edge_data = data['cites'] # 直接指定边类型来获取边缘数据
(3)添加和删除节点类型或张量
用户可以向数据对象中添加新的节点类型或张量,并在不再需要它们时将其删除
data['paper'].year = ... # 添加一个新的节点属性
del data['field_of_study'] # 删除一个节点类型
del data['has_topic'] # 删除一个边类型
(4)访问元数据
用户可以使用metadata()函数访问数据对象的元数据,其中包含了所有现有节点和边类型的信息
node_types, edge_types = data.metadata()
print(node_types) # 打印所有节点类型
['paper', 'author', 'institution']
print(edge_types) # 打印所有边类型
[('paper', 'cites', 'paper'),
('author', 'writes', 'paper'),
('author', 'affiliated_with', 'institution')]
(5)设备之间传输
数据对象可以像常规PyTorch张量一样在不同的设备之间传输,例如从CPU到GPU或反之。
data = data.to('cuda:0')
data = data.cpu()
(6)检查异构图的性质
用户可以使用以下函数检查异构图的性质:
data.has_isolated_nodes():检查是否有孤立节点。data.has_self_loops():检查是否有自环边。data.is_undirected():检查是否为无向图。
data.has_isolated_nodes()
data.has_self_loops()
data.is_undirected()
(7)转换为同构图
用户可以使用[to_homogeneous()]函数将异构图转换为同构的“类型化”图。这个同构图可以维护特征信息,以确保在不同类型之间的维度匹配。
homogeneous_data = data.to_homogeneous()
print(homogeneous_data)
Data(x=[1879778, 128], edge_index=[2, 13605929], edge_type=[13605929])
这里,homogeneous_data.edge_type表示一个边缘级向量,它将每条边缘的边缘类型保存为整数
Heterogeneous Graph Transformations
在异构图数据对象上进行图变换(transformations)以进行预处理,这些变换类似于用于处理普通图的变换
(1)ToUndirected() 变换
ToUndirected() 变换将一个有向图转换为一个无向图(在PyG表示中),方法是为图中的每条边添加反向边。这意味着未来的消息传递会沿着所有边的两个方向进行。如果有需要,这个函数还可以为异构图添加反向边类型
data = T.ToUndirected()(data)
(2)AddSelfLoops() 变换
AddSelfLoops() 变换用于在特定节点类型的所有节点和形式为 ('node_type', 'edge_type', 'node_type') 的所有现有边缘类型上添加自环边。结果是,在消息传递期间,每个节点可能会从自身接收一条或多条(每种适当的边缘类型一条)消息。
data = T.AddSelfLoops()(data)
(3)NormalizeFeatures() 变换:
NormalizeFeatures() 变换的工作方式类似于同质图的情况,它会将所有指定特征(所有类型的特征)归一化,使它们的总和等于一。这对于确保特征值在不同节点之间具有一致的重要性很有用。
data = T.NormalizeFeatures()(data)
Creating Heterogeneous GNNs
在异构图数据上创建异构图神经网络(Heterogeneous GNNs)。通常的消息传递图神经网络(MP-GNNs)不能直接应用于异构图数据,因为不同类型的节点和边特征无法通过相同的函数处理,由于特征类型的差异。
解决这个问题的一种自然方法是**为每种边类型单独实现消息传递和更新函数**。在运行时,MP-GNN算法需要在消息计算过程中遍历边类型字典,并在节点更新过程中遍历节点类型字典。
为了避免不必要的运行时开销并使创建异构MP-GNN尽可能简单,PyTorch Geometric提供了三种方式供用户在异构图数据上创建模型:
-
自动将同质GNN模型转换为异构GNN模型:可以利用
torch_geometric.nn.to_hetero()或torch_geometric.nn.to_hetero_with_bases()方法,自动将同质图神经网络模型转换为适用于异构图的模型。 -
使用PyG的包装器conv.HeteroConv定义不同类型的函数:可以为不同类型的边和节点特征定义消息传递和更新函数,然后使用PyG的
conv.HeteroConv包装器来构建异构卷积操作。 -
部署现有的(或编写自己的)异构GNN操作:可以利用PyG提供的异构GNN操作或编写自定义操作,以构建适用于异构图数据的模型。
Automatically Converting GNN Models
Pytorch Geometric 允许自动转换任何皮格使用内置函数torch_geometric.nn.to_hetero()或,将 GNN 模型转换为异构输入图的模型torch_geometric.nn.to_hetero_with_bases()。
这个示例使用了Open Graph Benchmark (OGB)的MAG数据集,并构建了一个基于SAGEConv的异构GNN模型
- (1)导入所需的PyTorch Geometric模块和类,
- 包括数据集加载、数据转换、SAGEConv层和to_hetero函数。
import torch_geometric.transforms as T
from torch_geometric.datasets import OGB_MAG
from torch_geometric.nn import SAGEConv, to_hetero
- (2)
dataset变量用于加载OGB_MAG数据集。preprocess='metapath2vec'参数表示在加载数据集时应用了"metapath2vec"的预处理。同时,使用了T.ToUndirected()转换将图转换为无向图。这意味着对于每个有向边,将添加一个反向边,从而将图转化为无向图。- 变量包含了从数据集中提取的第一个数据示例。这个数据示例通常代表了整个数据集中的一个图。
dataset = OGB_MAG(root='./data', preprocess='metapath2vec', transform=T.ToUndirected())
data = dataset[0]
- (3)
class GNN定义了一个简单的异构GNN模型。- 该模型具有两个SAGEConv层,分别用于第一和第二层的消息传递。
- 这两个层的输入特征维度(
in_channels)通过(-1, -1)来指定,这意味着输入特征的维度将根据数据自动确定。 hidden_channels参数指定了第一层的隐藏单元数,out_channels参数指定了输出层的单元数。- 在
forward方法中,模型首先应用第一层SAGEConv,然后应用ReLU激活函数,最后应用第二层SAGEConv。模型的输出是最后一层的节点表示。
class GNN(torch.nn.Module):
def __init__(self, hidden_channels, out_channels):
super().__init__()
self.conv1 = SAGEConv((-1, -1), hidden_channels)
self.conv2 = SAGEConv((-1, -1), out_channels)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index).relu()
x = self.conv2(x, edge_index)
return x
- (4)
model变量实例化了上面定义的GNN模型,同时指定了隐藏单元数和输出单元数。输出单元数等于数据集的类别数量(dataset.num_classes)。
model = GNN(hidden_channels=64, out_channels=dataset.num_classes)
- (5)
to_hetero函数用于将模型转换为适用于异构图的模型。- 它接受三个参数:要转换的模型、数据的元数据信息(通过
data.metadata()获得),以及聚合方法(aggr)。 aggr='sum'表示在消息传递过程中,对所有消息进行求和以更新节点表示。这是异构图中常用的一种聚合方式。
- 它接受三个参数:要转换的模型、数据的元数据信息(通过
model = to_hetero(model, data.metadata(), aggr='sum')
该过程采用现有的 GNN 模型并复制消息函数以单独处理每种边缘类型

因此,该模型现在期望以节点和边类型作为键的字典作为输入参数,而不是同构图中使用的单个张量。请注意,我们传入一个in_channelsto元组[SAGEConv],以便允许在二分图中传递消息。
Lazy Initialization for Heterogeneous GNNs
- 由于不同类型的节点和边缘具有不同数量的输入特征,因此初始化参数在异构GNN中可能会变得复杂。**PyG可以使用"lazy initialization"(延迟初始化)来初始化这些参数,**其中使用
-1作为in_channels参数值。这允许PyG避免计算和跟踪计算图中所有张量的大小。延迟初始化支持所有现有的PyG操作符。
with torch.no_grad(): # Initialize lazy modules.
out = model(data.x_dict, data.edge_index_dict)
- 使用
torch.no_grad()上下文管理器初始化模型的参数。这是通过将数据的特征和边缘信息传递给模型来完成的。通过这种方式,模型的参数被正确初始化。
Flexibility in Model Conversion
-
to_hetero()和to_hetero_with_bases()函数在**将同构模型自动转换为异构模型**方面非常灵活。这意味着您可以根据需要使用各种同构架构,如跳跃连接、知识传递或其他技术。这两个函数支持的操作非常多样化。 -
展示了如何使用
to_hetero()函数创建一个具有可学习跳跃连接的异构图注意力网络。该模型使用GATConv层和线性层进行消息传递,其中输入特征的大小由-1指定。最后,通过aggr='sum'参数定义了消息聚合方式。 -
这个示例是构建异构图神经网络的一个示例,其中包含可学习的跳跃连接。
-
(1)导入了所需的PyTorch Geometric模块。其中,
GATConv用于创建图注意力网络中的层,Linear用于创建线性层,to_hetero用于将同构模型转换为异构模型。-
from torch_geometric.nn import GATConv, Linear, to_hetero
-
-
(2)GAT类定义
-
class GAT(torch.nn.Module): # 这是定义异构图注意力网络的Python类 def __init__(self, hidden_channels, out_channels): super().__init__() self.conv1 = GATConv((-1, -1), hidden_channels, add_self_loops=False) self.lin1 = Linear(-1, hidden_channels) self.conv2 = GATConv((-1, -1), out_channels, add_self_loops=False) self.lin2 = Linear(-1, out_channels) -
hidden_channels:指定隐藏层的输出通道数量。 -
out_channels:指定模型的输出通道数量。 -
self.conv1 = GATConv((-1, -1), hidden_channels, add_self_loops=False):创建第一个图注意力层。这个层的输入特征大小由-1指定,意味着它会根据输入自动确定特征大小。add_self_loops=False表示不添加自环边。 -
self.lin1 = Linear(-1, hidden_channels):创建第一个线性层。同样,输入特征大小由-1指定,它将用于线性变换。 -
self.conv2 = GATConv((-1, -1), out_channels, add_self_loops=False):创建第二个图注意力层。 -
self.lin2 = Linear(-1, out_channels):创建第二个线性层。
-
-
(3)forward方法
-
def forward(self, x, edge_index): # 定义了前向传播过程,其中x是输入特征,edge_index是边的索引。 x = self.conv1(x, edge_index) + self.lin1(x) x = x.relu() x = self.conv2(x, edge_index) + self.lin2(x) return x -
x = self.conv1(x, edge_index) + self.lin1(x):应用第一个图注意力层,然后将结果与第一个线性层的输出相加。 -
x = x.relu():应用ReLU激活函数。 -
x = self.conv2(x, edge_index) + self.lin2(x):应用第二个图注意力层,然后将结果与第二个线性层的输出相加。 -
return x:返回模型的输出。
-
-
(4)模型创建和转换
-
model = GAT(hidden_channels=64, out_channels=dataset.num_classes) model = to_hetero(model, data.metadata(), aggr='sum') -
model = GAT(hidden_channels=64, out_channels=dataset.num_classes):创建一个GAT模型实例,指定了隐藏层大小和输出层大小。这个模型将从数据中学习如何执行异构图注意力传递。 -
model = to_hetero(model, data.metadata(), aggr='sum'):使用to_hetero函数将创建的同构模型转换为异构模型。data.metadata()包含了异构图的元数据,aggr='sum'指定了消息聚合方式。
-
Training Heterogeneous GNNs
-
创建的异构GNN模型可以像常规模型一样进行训练。
def train(): model.train() optimizer.zero_grad() out = model(data.x_dict, data.edge_index_dict) mask = data['paper'].train_mask loss = F.cross_entropy(out['paper'][mask], data['paper'].y[mask]) loss.backward() optimizer.step() return float(loss)model.train()将模型设置为训练模式。optimizer.zero_grad()清零梯度。out = model(data.x_dict, data.edge_index_dict)用数据的特征和边缘信息进行前向传播。mask = data['paper'].train_mask获取用于训练的掩码。F.cross_entropy(out['paper'][mask], data['paper'].y[mask])计算损失。loss.backward()计算梯度。optimizer.step()执行优化步骤。- 返回损失值作为训练过程的结果。
Using the Heterogeneous Convolution Wrapper
使用异构卷积包装器torch_geometric.nn.conv.HeteroConv来创建自定义异构消息和更新函数,以从头开始构建用于异构图的任意消息传递图神经网络(MP-GNN)。与自动转换to_hetero()在所有边类型上使用相同的运算符不同,包装器允许为不同的边类型定义不同的运算符。
导入模块和数据加载:
- 导入了所需的PyTorch Geometric模块和对数据的预处理。
- 创建了OGB_MAG数据集的实例,并加载了预处理后的数据。
import torch_geometric.transforms as T
from torch_geometric.datasets import OGB_MAG
from torch_geometric.nn import HeteroConv, GCNConv, SAGEConv, GATConv, Linear
HeteroGNN类定义
class HeteroGNN(torch.nn.Module):
def __init__(self, hidden_channels, out_channels, num_layers):
super().__init__()
self.convs = torch.nn.ModuleList()
for _ in range(num_layers):
conv = HeteroConv({
('paper', 'cites', 'paper'): GCNConv(-1, hidden_channels),
('author', 'writes', 'paper'): SAGEConv((-1, -1), hidden_channels),
('paper', 'rev_writes', 'author'): GATConv((-1, -1), hidden_channels),
}, aggr='sum')
self.convs.append(conv)
self.lin = Linear(hidden_channels, out_channels)
class HeteroGNN(torch.nn.Module)::这是异构图神经网络的定义。def __init__(self, hidden_channels, out_channels, num_layers):构造函数初始化模型的各个部分。hidden_channels:指定隐藏层的输出通道数量。out_channels:指定模型的输出通道数量。num_layers:指定要堆叠的异构卷积层数。
self.convs = torch.nn.ModuleList():创建一个模块列表,用于存储异构卷积层。for _ in range(num_layers):根据指定的卷积层数进行循环。- 在循环中,为每个卷积层创建一个
HeteroConv实例。这里,HeteroConv接受一个包含不同边类型的子模块的字典。 - 对于每种边类型,使用不同的卷积层,例如
GCNConv、SAGEConv和GATConv。 aggr='sum'指定了消息聚合方式。
- 在循环中,为每个卷积层创建一个
self.lin = Linear(hidden_channels, out_channels):创建一个线性层,用于最终输出。
forward方法:
def forward(self, x_dict, edge_index_dict):
for conv in self.convs:
x_dict = conv(x_dict, edge_index_dict)
x_dict = {key: x.relu() for key, x in x_dict.items()}
return self.lin(x_dict['author'])
def forward(self, x_dict, edge_index_dict)::定义了前向传播过程,其中x_dict包含了不同节点类型的特征数据,edge_index_dict包含了不同边类型的边缘索引。- 对于每个卷积层,将数据字典
x_dict和边索引字典edge_index_dict传递给卷积层,然后应用ReLU激活函数。 - 最终,返回模型对"author"节点类型的输出。
模型创建和初始化
model = HeteroGNN(hidden_channels=64, out_channels=dataset.num_classes,
num_layers=2)
model = HeteroGNN(hidden_channels=64, out_channels=dataset.num_classes, num_layers=2):创建一个异构GNN模型实例,指定了隐藏层大小、输出层大小和卷积层数。- 通过在
torch.no_grad()块中调用模型一次,可以懒惰地初始化模型参数。这是因为异构图中的不同节点类型和边类型可能具有不同的特征大小,因此在模型初始化时,参数尺寸会根据数据动态调整。
模型训练:
with torch.no_grad(): # Initialize lazy modules.
out = model(data.x_dict, data.edge_index_dict)
- 可以按照标准的PyTorch训练流程对模型进行训练

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)