基于卷积神经网络(CNN)的手写数字识别-完整代码
用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。当第二个参数不写入的时候,如果可迭代的元素全部取出来后,会返回Stoplteration的异常;当第二个参数写入的时候,可迭代对象完之后,会一直返回第二个参数写的数值。可以看出Compose里面的参数实际上就是个列表,而这个列表里面的元素就是你想要执行的transform操作。
通过设计一个卷积神经网络模型,实现对MNIST数据集中的手写数字图片进行识别。
#1 导入必要的模块
import numpy as np
import matplotlib.pyplot as plt
import torch
from torchvision import transforms,datasets
from torch.utils.data import DataLoader
import torchvision对数据进行预处理操作,即通过Compose方法把多种预处理操作组合在一起
#2 定义数据预处理操作【通过Compose方法把多种预处理操作组合在一起】
pipline=transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5],[0.5])])torchvision是pytorch的一个图形库,它是服务于PyTorch深度学习框架的,主要用来构建计算机视觉模型。torchvision.transforms主要是用于常见的一些图形变换。其中的torchvision.transforms.Compose()类主要作用是串联多个图片变换的操作。这个类的构造如下:
class torchvision.transforms.Compose(transforms):
# Composes several transforms together.
# Parameters: transforms (list of Transform objects) – list of transforms to compose.
可以看出Compose里面的参数实际上就是个列表,而这个列表里面的元素就是你想要执行的transform操作。
下载MNIST数据集
#3 下载数据集
train_dataset=datasets.MNIST('./data',train=True,transform=pipline,download=True)
test_dataset=datasets.MNIST('./data',train=False,transform=pipline,download=True)分批加载数据集
#分批加载数据集
train_loader=DataLoader(train_dataset,batch_size=16,shuffle=True)
test_loader=DataLoader(test_dataset,batch_size=16,shuffle=False)shuffle=True用于打乱数据集,每次都会以不同的顺序返回。
shuffle的实际效果为,假设有数据a,b,c,d,batch_size=2后打乱,具体是下面的第二种情况:
1.先按顺序取batch,对batch内打乱,即先取a,b,a,b进行打乱;
2.先打乱,再取batch。
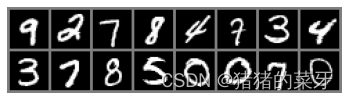
部分数据可视化
第一种数据可视化方法
examples=enumerate(train_loader) #enumerate迭代器
_,(example_data,example_target)=next(examples)
#利用enumerate()中的next()属性取值,用不到索引值,用_接一下值
for i in range(9):
plt.subplot(3,3,i+1)
plt.axis('off')
plt.imshow(torch.squeeze(example_data[i]),cmap='gray')
plt.title(example_target[i].numpy())enumerate()是python中的内置函数之一,属于迭代器函数。用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
例如:
>>> seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]next()函数用于取出可迭代对象的元素,一般与iter()函数联合使用。next函数可以调用生成器的对象以参数形式传入到next(params),返回迭代器到下一个项目。用法:next(iterobject, defalt)
1.iterobject:可迭代的对象
2.default:可选
当第二个参数不写入的时候,如果可迭代的元素全部取出来后,会返回Stoplteration的异常;当第二个参数写入的时候,可迭代对象完之后,会一直返回第二个参数写的数值。

第2种数据可视化方法
def imshow(img):
img=img/2+0.5 #反归一化
np_img=img.numpy()
plt.axis('off')
plt.imshow(np.transpose(np_img,(1,2,0)))
plt.show()
dataiter=iter(train_loader)
images,labels=next(dataiter)
imshow(torchvision.utils.make_grid(images))归一话的时候是先减去平均值0.5 ,然后再除以标准偏差0.5;那么反归一化就是先乘以0.5,再加0.5。
构建网络模型
import torch.nn as nn
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.layer01=nn.Sequential( #模块化
nn.Conv2d(in_channels=1,out_channels=6,kernel_size=(3,3),padding=1), #卷积层
nn.BatchNorm2d(6), #批正则化
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2) #最大池化
) #16*14*14
self.layer02=nn.Sequential(
nn.Conv2d(6,16,3), #32*12*12
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2,2) #32*6*6
)
self.fc=nn.Sequential(
nn.Linear(16*6*6,10),
)
def forward(self,x): #前向传播
x=self.layer01(x)
x=self.layer02(x)
x=x.view(x.size(0),-1) ##四维(b,c,h,w)->二维
x=self.fc(x)
return x实例化操作
net=CNN()
net
for m in net.modules():
if isinstance(m,nn.Conv2d):
nn.init.normal_(m.weight)
nn.init.xavier_normal_(m.weight)
nn.init.constant_(m.bias,0)
elif isinstance(m,nn.Linear):
nn.init.normal_(m.weight)定义损失函数和优化器
loss_fun=nn.CrossEntropyLoss() #交叉熵损失
optimizer=torch.optim.Adam(net.parameters(),lr=0.01) #优化器
tot_loss=0.0
tot_all=0.0
tot_correct=0.0
loss_per_epoch=[]
avg_acc_per_epoch=[]通过上述代码初始化了一个优化器,该优化器使用的是Adam优化算法,optim包里面还包含了其他优化算法。初始化时我们将我们定义的神经网络中的参数传入优化器中,并传入我们定义的学习率。
打印每轮后的损失和时间
import time
start=time.time()
for epoch in range(10):
for iteration,(X_bat,y_bat) in enumerate(train_loader): #枚举器,索引值也可取出
y_pred=net(X_bat) #得到预测标签
loss=loss_fun(y_pred,y_bat) #计算损失
optimizer.zero_grad() #梯度清零
loss.backward() #反向传播
optimizer.step() #梯度更新
#argmax()取最大值对应的索引,利用data属性取出数值,再转化为numpy类型
predict_y = torch.argmax(y_pred, 1).data.numpy()
tot_correct += sum(predict_y == y_bat.data.numpy())
tot_all += len(predict_y)
tot_loss += loss.item() * len(predict_y)
# 打印一轮中的平均精度和损失函数值
avg_acc = tot_correct / tot_all * 100.0
loss_epoch = tot_loss / tot_all
print('[Epoch %d] avg_loss: %.4f, avg_acc: %.4f %%' % \
(epoch+1, loss_epoch , avg_acc))
loss_per_epoch.append(loss_epoch)
avg_acc_per_epoch.append(avg_acc)
tot_loss=0.0
tot_correct=0.0
tot_all=0.0
end=time.time()
print('traning time:',end-start)
损失和训练精度可视化
tot_test=0.0
tot_test_correct=0.0
pred_test_list=[]
true_test_list=[]
for image,target in test_loader:
y_out_test=net(image)
y_pred_test=torch.argmax(y_out_test,1).data.numpy()
tot_test+=len(y_pred_test)
tot_test_correct+=sum(y_pred_test==target.data.numpy())
pred_test_list+=list(y_pred_test)
true_test_list+=list(target.data.numpy())
test_acc=tot_test_correct/tot_test*100.0
print('TestAccuracy:%4f%%'%(test_acc))![]()

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)