李宏毅 机器学习 作业一
资料:助教官方代码 colab地址: https://colab.research.google.com/drive/131sSqmrmWXfjFZ3jWSELl8cm0Ox5ah3C#scrollTo=NzvXP5Jya64较好的作业分享的kaggle位置: https://www.kaggle.com/liyi0123/kernel1381704018这些链接都来自于:助教的PPT中的链接。作
资料:
- 助教官方代码 colab地址: https://colab.research.google.com/drive/131sSqmrmWXfjFZ3jWSELl8cm0Ox5ah3C#scrollTo=NzvXP5Jya64
- 较好的作业分享的kaggle位置: https://www.kaggle.com/liyi0123/kernel1381704018
- 这些链接都来自于:助教的PPT中的链接。
-
作业参考一: https://blog.csdn.net/iteapoy/article/details/105431738
作业参考二: https://mrsuncodes.github.io/2020/03/15/%E6%9D%8E%E5%AE%8F%E6%AF%85%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0-%E7%AC%AC%E4%B8%80%E8%AF%BE%E4%BD%9C%E4%B8%9A/
1. 作业要求

2. 数据说明

3. 步骤



step2: 数据预处理——原始数据为 行:日期,18项;列:24小时各个的数据。转化后:列:18*9小时的数据,行:代表一条数据
处理之后:5652条数据,每条数据的特征维度为162。可以就将原来每个月20天,20*12=240天的数据给扩展成了5652条数据。
step3:Normalize与训练集分类
- 数据特征归一化。去量钢化——去除数据的单位限制,转化为无量纲的纯数值。便于不同单位或量级的指标能够进行比较和加权。经过处理的数据符合标准正态分布,即均值为0,标准差为1
- 将训练数据按8:2拆成训练数据和验证数据。由于数据有顺序的,所以无法随机打乱,只能顺序取。使用验证数据可以简单验证我们模型的好坏
step4: 训练模型
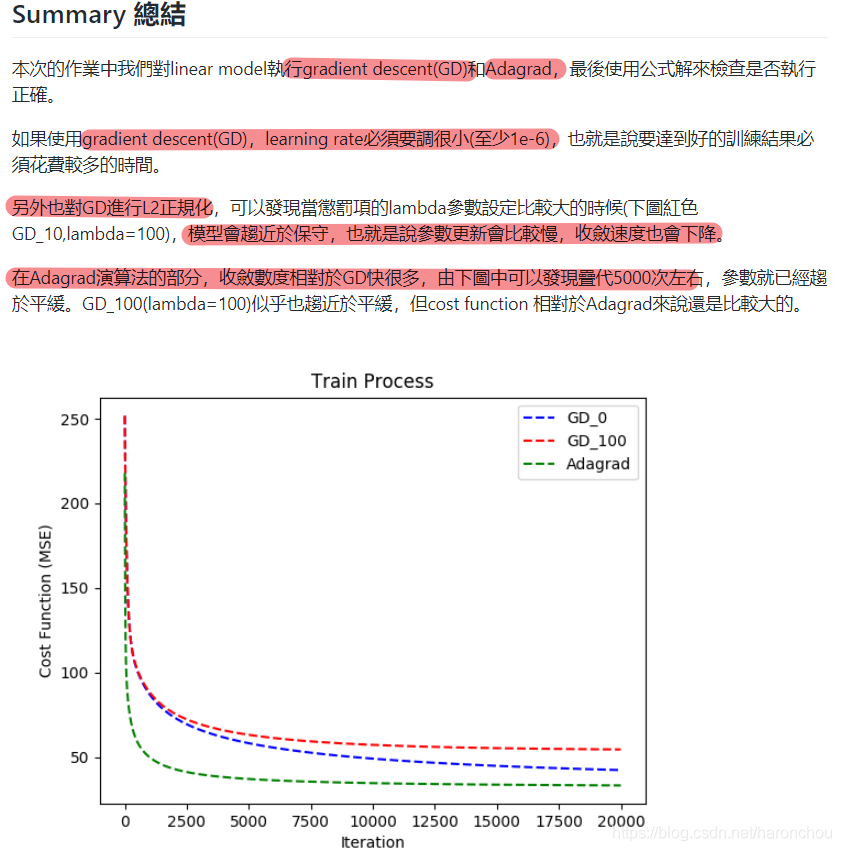
■ 首先明确,我们训练使用的Loss function和梯度下降算法
■ RMS loss是均方误差;梯度计算;
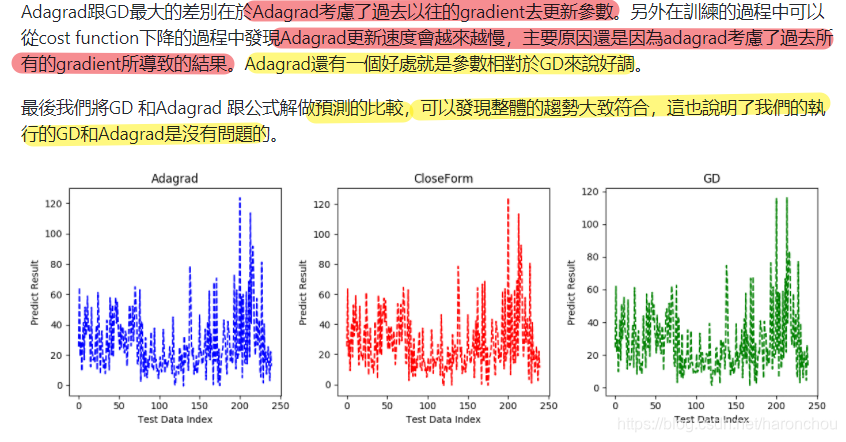
■ 权重更新方式:Adagrad
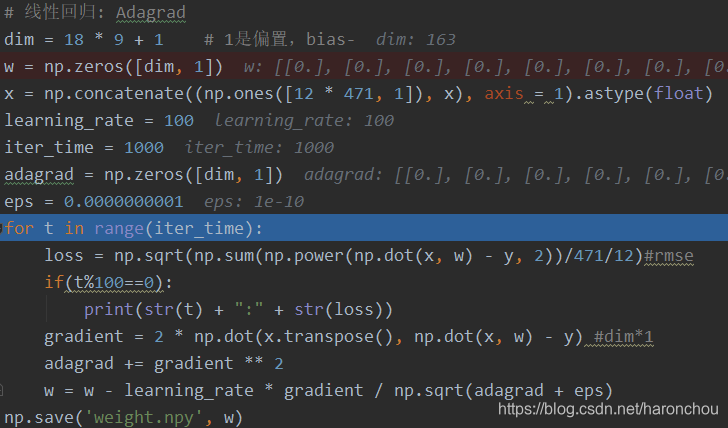


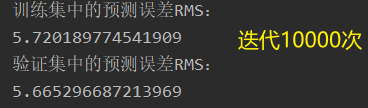
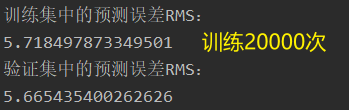
loss 迭代1000次的结果;Adagrad;可以看出从400次之后,就比较慢了。
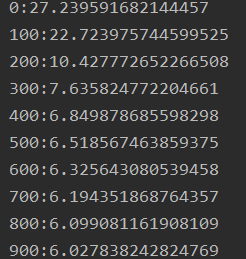
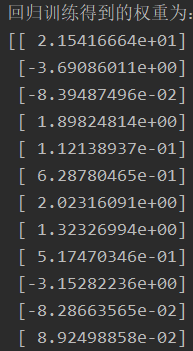
权重:有正有负,竟然有负相关的特征。
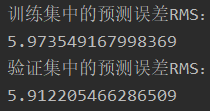
训练集误差 vs 验证集误差:验证集数量较少,导致误差要小些吧。


https://zhuanlan.zhihu.com/p/136329137 作业其他参考
https://github.com/maplezzz/NTU_ML2017_Hung-yi-Lee_HW/tree/master/HW1 的代码如下,写的还可以。
import csv, os
import numpy as np
import matplotlib.pyplot as plt
from numpy.linalg import inv
import random
import math
import sys
def ada(X, Y, w, eta, iteration, lambdaL2):
s_grad = np.zeros(len(X[0]))
list_cost = []
for i in range(iteration):
hypo = np.dot(X,w)
loss = hypo - Y
cost = np.sum(loss**2)/len(X)
list_cost.append(cost)
grad = np.dot(X.T, loss)/len(X) + lambdaL2*w
s_grad += grad**2
ada = np.sqrt(s_grad)
w = w - eta*grad/ada
return w, list_cost
def SGD(X, Y, w, eta, iteration, lambdaL2):
list_cost = []
for i in range(iteration):
hypo = np.dot(X,w)
loss = hypo - Y
cost = np.sum(loss**2)/len(X)
list_cost.append(cost)
rand = np.random.randint(0, len(X))
grad = X[rand]*loss[rand]/len(X) + lambdaL2*w
w = w - eta*grad
return w, list_cost
def GD(X, Y, w, eta, iteration, lambdaL2):
list_cost = []
for i in range(iteration):
hypo = np.dot(X,w)
loss = hypo - Y
cost = np.sum(loss**2)/len(X)
list_cost.append(cost)
grad = np.dot(X.T, loss)/len(X) + lambdaL2 * w
w = w - eta*grad
return w, list_cost
# 每一个维度储存一种污染物的咨询
data = []
for i in range(18):
data.append([])
#read data
n_row = 0
text = open('data/train.csv', 'r', encoding='big5')
row = csv.reader(text, delimiter=',')
for r in row:
if n_row != 0:
for i in range(3,27):
if r[i] != "NR":
data[(n_row-1)%18].append(float(r[i]))
else:
data[(n_row-1)%18].append(float(0))
n_row = n_row + 1
text.close
#parse data to trainX and trainY
x = []
y = []
for i in range(12):
for j in range(471):
x.append([])
for t in range(18):
for s in range(9):
x[471*i + j].append(data[t][480*i+j+s])
y.append(data[9][480*i+j+9])
trainX = np.array(x) #每一行有9*18个数 每9个代表9天的某一种污染物
trainY = np.array(y)
#parse test data
test_x = []
n_row = 0
text = open('data/test.csv' ,"r")
row = csv.reader(text , delimiter= ",")
for r in row:
if n_row %18 == 0:
test_x.append([])
for i in range(2,11):
test_x[n_row//18].append(float(r[i]) )
else :
for i in range(2,11):
if r[i] !="NR":
test_x[n_row//18].append(float(r[i]))
else:
test_x[n_row//18].append(0)
n_row = n_row+1
text.close()
test_x = np.array(test_x)
#parse anser
ans_y = []
n_row = 0
text = open('data/ans.csv', "r")
row = csv.reader(text, delimiter=",")
for r in row:
ans_y.append(r[1])
ans_y = ans_y[1:]
ans_y = np.array(list(map(int, ans_y)))
# add bias
test_x = np.concatenate((np.ones((test_x.shape[0],1)),test_x), axis=1)
trainX = np.concatenate((np.ones((trainX.shape[0],1)), trainX), axis=1)
#train data
w = np.zeros(len(trainX[0]))
w_sgd, cost_list_sgd = SGD(trainX, trainY, w, eta=0.0001, iteration=20000, lambdaL2=0)
# w_sgd50, cost_list_sgd50 = SGD(trainX, trainY, w, eta=0.0001, iteration=20000, lambdaL2=50)
w_ada, cost_list_ada = ada(trainX, trainY, w, eta=1, iteration=20000, lambdaL2=0)
# w_gd, cost_list_gd = SGD(trainX, trainY, w, eta=0.0001, iteration=20000, lambdaL2=0)
#close form
w_cf = inv(trainX.T.dot(trainX)).dot(trainX.T).dot(trainY)
cost_wcf = np.sum((trainX.dot(w_cf)-trainY)**2) / len(trainX)
hori = [cost_wcf for i in range(20000-3)]
#output testdata
y_ada = np.dot(test_x, w_ada)
y_sgd = np.dot(test_x, w_sgd)
y_cf = np.dot(test_x, w_cf)
#csv format
ans = []
for i in range(len(test_x)):
ans.append(["id_"+str(i)])
a = np.dot(w_ada,test_x[i])
ans[i].append(a)
filename = "result/predict.csv"
text = open(filename, "w+")
s = csv.writer(text,delimiter=',',lineterminator='\n')
s.writerow(["id","value"])
for i in range(len(ans)):
s.writerow(ans[i])
text.close()
#plot training data with different gradiant method
plt.plot(np.arange(len(cost_list_ada[3:])), cost_list_ada[3:], 'b', label="ada")
plt.plot(np.arange(len(cost_list_sgd[3:])), cost_list_sgd[3:], 'g', label='sgd')
# plt.plot(np.arange(len(cost_list_sgd50[3:])), cost_list_sgd50[3:], 'c', label='sgd50')
# plt.plot(np.arange(len(cost_list_gd[3:])), cost_list_gd[3:], 'r', label='gd')
plt.plot(np.arange(len(cost_list_ada[3:])), hori, 'y--', label='close-form')
plt.title('Train Process')
plt.xlabel('Iteration')
plt.ylabel('Loss Function(Quadratic)')
plt.legend()
plt.savefig(os.path.join(os.path.dirname(__file__), "figures/TrainProcess"))
plt.show()
#plot fianl answer
plt.figure()
plt.subplot(131)
plt.title('CloseForm')
plt.xlabel('dataset')
plt.ylabel('pm2.5')
plt.plot(np.arange((len(ans_y))), ans_y, 'r,')
plt.plot(np.arange(240), y_cf, 'b')
plt.subplot(132)
plt.title('ada')
plt.xlabel('dataset')
plt.ylabel('pm2.5')
plt.plot(np.arange((len(ans_y))), ans_y, 'r,')
plt.plot(np.arange(240), y_ada, 'g')
plt.subplot(133)
plt.title('sgd')
plt.xlabel('dataset')
plt.ylabel('pm2.5')
plt.plot(np.arange((len(ans_y))), ans_y, 'r,')
plt.plot(np.arange(240), y_sgd, 'b')
plt.tight_layout()
plt.savefig(os.path.join(os.path.dirname(__file__), "figures/Compare"))
plt.show()

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)