引导者之歌------------嵌入式软件面试问题集成
文章系统整理了C/C++、Python核心知识点,涵盖数据类型、指针、内存管理、关键字作用、数据结构差异、STM32开发常见问题、操作系统原理及网络协议等内容。重点包括:指针与数组的区别、栈与堆的特性、const/static/extern关键字的应用、FreeRTOS调度机制、进程线程对比、TCP/UDP差异及MQTT协议特点。针对嵌入式开发,详细分析了GPIO模式、中断与DMA机制、I2C/S
目录
顺序结构(数组)和链式结构(链表)有什么不同,应用在哪些场景?
一个开关控制一个LED灯开关,由stm32做主控,按下按键,灯会时亮时不亮,原因由那些?
一、C/C++、Python
sizeof,数据类型地址大小问题
基本变量: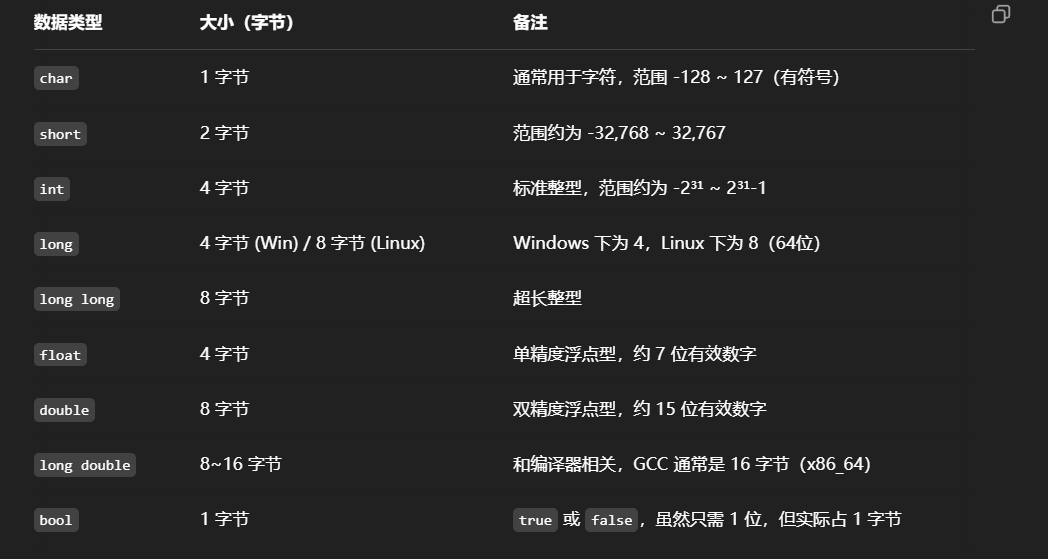
指针:
指针大小在32位操作系统是4字节大小,在 64 位系统中为 8 字节大小。
答案分别是:16、4、4
a是一个数组,所以大小是4*4=16字节
*a是指向数组a的首位,大小是4字节
&a是表示取地址,指针大小是4字节(在32位操作系统中)

运算符优先级

int a = 5;
a += a *= a %= 3;
// a= a%3 a*=a=4 a=a+a=8
cout << "a的结果:" << a << endl; // 8int main(int argc, char const* argv[])
{
int a = 1;
int b = a++ + a++ + ++a;
// 1+2+4=7
printf("%d %d\n", a, b);
// 输出结果:4 7
}sizeof()和strlen()
1.sizeof()是一个运算符;strlen()是一个函数,需要包含头文件。
2.sizeof()计算的是占用内存的大小;strlen()是表示计算字符串的长度。
#include<stdio.h>
#include<string.h>
int main(int argc, char const* argv[])
{
printf("%d %d\n", sizeof("\0"), strlen("\0"));
}这个答案是多少? 应该是 2 ,0
字符串是以 \0 作为结尾,所以strlen不会计算到这个的长度的,答案为0;sizeof计算的是字符串占用内存的大小,其中\0是表示一个字符串,但是C语言字符串最后面会有一个\0作为终止符,所以实际上计算的是\0\0,也就是两个字符的大小,答案是2。
指针常量,常量指针
指针常量如下,这个p是一个常量类型的指针,不能修改这个指针指向的地址,但是这个地址的值是可以修改的。
int * const p;常量指针如下,这个指针指向常量类型的一个指针,也就是说这个地址里面的东西不能改,但 p 本身可以指向别的地址。
const int *p;
int const *p;
很显然,第一个指向的地址里面的值是不能修改的;第二个是表示这个指针指向的地址是不能修改的。

指针函数,函数指针
2.指针函数
int* arry() { int* s = new int[4]; return s; }
1.函数指针
如果在程序中定义了一个函数,那么在编译时系统就会为这个函数代码分配一段存储空间,这段存储空间的首地址称为这个函数的地址。而且函数名表示的就是这个地址。既然是地址我们就可以定义一个指针变量来存放,这个指针变量就叫作函数指针变量,简称函数指针。
int add(int a, int b) { return a + b; } int main(int argc, char const* argv[]) { // 定义函数指针 int (*ptr)(int, int) = &add; return 0; }
指针数组,数组指针
int* p[10]; // 指针数组,里面每一个元素都是指针类型
int(*p)[10]; // 数组指针,本质是一个指针
int main(int argc, char const* argv[])
{
int a[2][3] = { 1,2,3,4,5,6 };
int (*p)[3] = a;
cout << **p << endl;
cout << *p[1] << endl;
cout << (*p)[1] << endl;
cout << (*p + 1)[2] << endl;
cout << (*(p + 1))[0] << endl;
cout << *(*p + 4) << endl;
cout << *((*p + 1) + 0) << endl;
/*
1
4
2
4
4
5
2
*/
}代码问题
这个是不能比较字符串是否相等的,你比如说abc和abcd捏?真正去比较字符串是否相同的可以去使用KMP算法或者BF算法。

程序/进程的内存分为几个段?
- 代码段:用于存储程序的可执行指令,一般是只读,防止被修改
- 数据段(Dat):用于存储已经初始化的全局变量和静态变量
- BSS段:存储没有初始化的全局变量和静态变量
- 堆:用malloc和free去手动分配和释放的
- 栈:用于存储局部变量,栈的内存申请是由操作系统决定的
C语言中内存分配有多少种?
1.栈上分配
2.堆上分配
3.静态存储区分配,比如全局变量、静态变量static
栈和堆有什么区别?
1.栈是由操作系统去自动分配/释放的,堆是由用户去手动分配/释放的。
2.栈的空间分配速度快,堆的分配速度是比较慢的,而且容易出现内存碎片,不好管理。
3.栈空间是有限的还是连续的(数组),堆空间是非常大的而且不是连续的(链表)。
const关键字
- 修饰定义的变量,设置为常量了
- 修饰函数的参数,这个函数体内你不能修改这个参数的值
- 修饰返回值,被修饰的返回值指针,这个指针的执行内容就不能改
extern关键字
【014 关键字】一文彻底搞懂extern用法-CSDN博客
用于声明变量或函数是在其他地方定义的,主要用来解决跨文件访问的问题。
声明可以多次,定义只能一次。
extern C 的作用是什么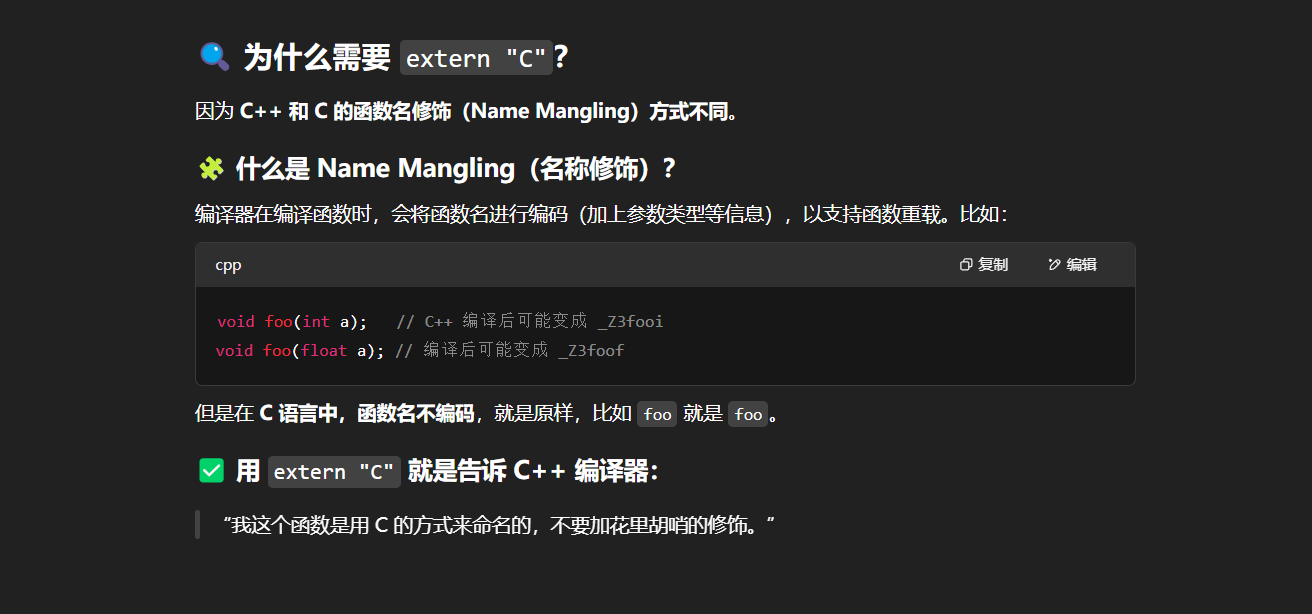
volatile关键字
volatile是 C/C++ 中的一个关键字,意思是:这个变量可能随时发生变化,不要做优化,要每次都从内存中读取它的值。
#include <iostream>
void delay() {
for (int i = 0;i < 99999;i++) {
for (int j = 0;j < 99999;j++) {
}
}
}
int main(int argc, char const* argv[])
{
std::cout << "1111111" << std::endl;
delay();
std::cout << "222222" << std::endl;
return 0;
}
如果使用 g++ main.cc -o main -O3 去进行编译的话,就会对代码进行优化,所以检测到上面这个delay是属于无效的循环的话,编译器会直接忽略掉的。输出结果直接就是111111 222222,中间没有延时。


void delay() {
for (volatile int i = 0;i < 99999;i++) {
for (volatile int j = 0;j < 99999;j++) {
}
}
}但是如果加上volatile去声明变量就不同了,这个加上就是告诉编译器这个变量是不稳定的,每次读取的时候只能从内存上去读取,而不是从寄存器或者缓存区读。
所以这里即使开启了编译等级优化,两个输出之间是有延迟的。
为什么static只需要初始化一次(static关键字)

new/delete、malloc/free 区别

左值和右值区别,应用?
- 左值是指可以出现在等号左边的变量或表达式,它最重要的特点就是可写(可寻址)。也就是说,它的值可以被修改,如果一个变量或表达式的值不能被修改,那么它就不能作为左值。
- 右值是指只可以出现在等号右边的变量或表达式。它最重要的特点是可读。一般的使用场景都是把一个右值赋值给一个左值。
通常,左值可以作为右值,但是右值不一定是左值。左值是可以赋值的,右值是不可以赋值的
结构体内存对齐问题
Linux-----结构体与联合体,大小端模式_联合体大小端-CSDN博客
struct 和 union 区别?
1.结构体占用内存大小是等于所有成员大小之和(遵循结构体成员内存对齐);联合体内存是共享的,由成员中占用内存最大的成员决定的。
理论上联合体占用内存大小是根据成员中占用内存最大的成员决定的, 但是实际上一般输出union 的大小 = 最大成员大小(含对齐)。
大小端存储方式
Linux-----结构体与联合体,大小端模式_联合体大小端-CSDN博客
深拷贝和浅拷贝
浅拷贝
- 是只复制这个指针,多个变量对象使用同一个动态分配的内存
- 适用于简单类型或者是无需独立管理资源的对象
- 可能导致内存泄漏或者是多次释放的问题
深拷贝
- 申请独立的内存空间完全复制前一个对象的全部内容
- 使用与动态分配内存的对象
- 每个对象拥有独立的内存空间副本,不会相互影响
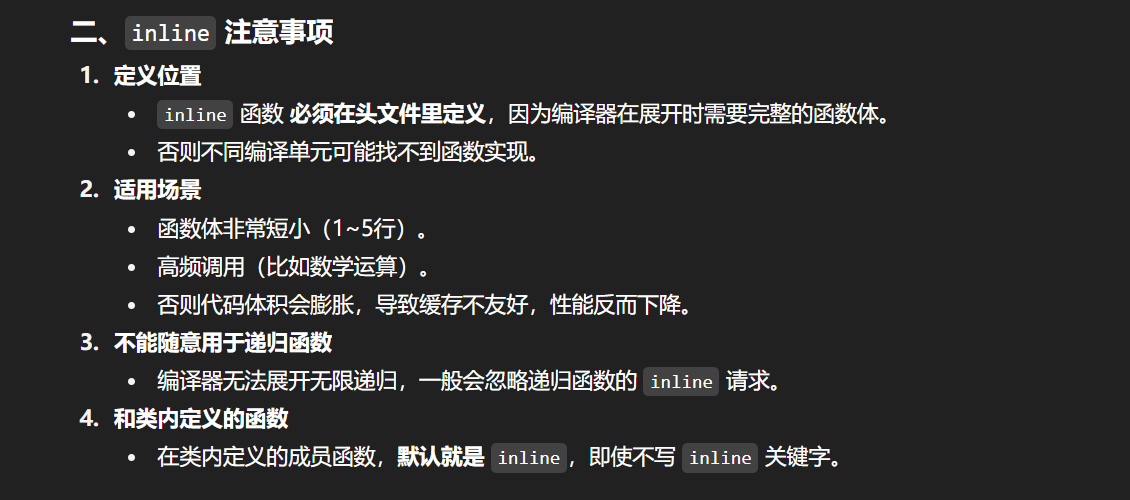
内联函数 inline
内联函数是一种特殊的函数声明方式,在函数的前面加上inline关键字。调用的时候是进行展开,而不是直接去调用。这种适用于体量小、功能简单的函数
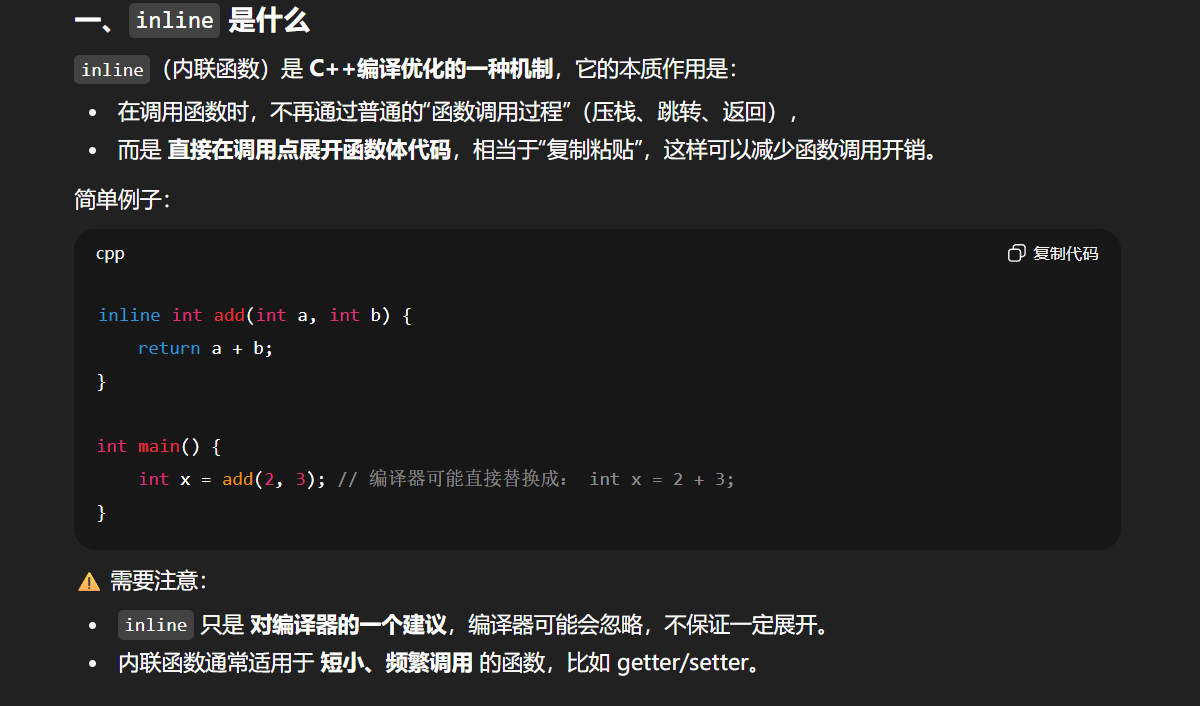
inline int add(int a, int b) {
return a + b;
}
int main(int argc, char const* argv[])
{
int result = add(7, 8);
printf("%d\n", result);
}优点
- 减小函数调用的开销
- 提高执行效率
- 允许编译器进行优化,减少冗余,提高性能
memcpy和strcpy函数
- void* memcpy( void* dest, const void* src, std::size_t count );
- char* strcpy( char* dest, const char* src );
- memcpy是属于内存拷贝,不受数据类型限制按照字节数去拷贝,适用范围更广;strcpy是属于字符串拷贝,仅适用于字符串类型的拷贝。
- memcpy不会检查字符串结束符
\0;而会自动拷贝直到遇到\0,并包括\0本身
memcpy:
char a[] = "ciallo";
char b[] = "0d00";
memcpy(a, b, 4);
printf("%s\n", a);
return 0;
// 输出结果 0d00lo int a[] = { 1,2,3,4 };
int b[] = { 100,200 };
memcpy(a, b, sizeof(int) * 2);
for (int i = 0;i < sizeof(a) / sizeof(a[0]);i++) {
printf("%d ", a[i]);
}
return 0;
// 输出结果 100 200 3 4strcpy:
char a[] = "ciallo";
char b[] = "0d00";
strcpy(a, b);
printf("%s\n", a);
return 0;
// 输出结果 0d00数组越界问题:
char src[] = "HelloWorld"; // 10个字符(含 '\0') char dest[5]; // 空间太小 strcpy(dest, src); // ❌ 越界写入 printf("dest = %s\n", dest); // 有可能崩溃或显示乱码
编译型语言与解释型语言不同

calloc、malloc、realloc函数的区别及用法
calloc、malloc、realloc函数的区别及用法-CSDN博客
类的析构函数可以是虚函数吗
可以的,而且 很多情况下析构函数必须声明为虚函数。
原因是:
-
当一个类作为 基类 使用时,如果它的析构函数不是虚函数,那么通过 基类指针删除派生类对象 时,只会调用基类的析构函数,不会调用派生类的析构函数,这样会造成 资源泄露或未完全释放。
#include <iostream>
using namespace std;
class Base {
public:
Base() { cout << "Base 构造\n"; }
~Base() { cout << "Base 析构\n"; } // 非虚函数
};
class Derived : public Base {
public:
Derived() { cout << "Derived 构造\n"; }
~Derived() { cout << "Derived 析构\n"; }
};
int main() {
Base* p = new Derived();
delete p; // 问题:只调用 Base 的析构函数,Derived 的析构不会被调用
return 0;
}
Base 构造
Derived 构造
Base 析构

C++的构造函数方式有哪些
1️⃣ 默认构造函数(Default Constructor)
没有参数,或所有参数都有默认值。
系统会在对象创建时自动调用。class A { public: A() { // 默认构造函数 cout << "默认构造函数被调用" << endl; } }; A obj; // 自动调用 A()
2️⃣ 有参构造函数(Parameterized Constructor)
构造的时候对类成员变量进行初始化
class A { int x; public: A(int val) { // 有参构造 x = val; cout << "有参构造函数被调用,x=" << x << endl; } }; A a1(10);
3️⃣ 拷贝构造函数(Copy Constructor)
用已有对象初始化新对象。
class A { int x; public: A(int val) : x(val) {} A(const A& other) { // 拷贝构造 x = other.x; cout << "拷贝构造函数被调用" << endl; } }; A a1(10); A a2 = a1; // 调用拷贝构造
4️⃣ 移动构造函数(Move Constructor)
从临时对象中“移动”资源,提高性能(C++11 引入)。
class A { int* data; public: A(int val) { data = new int(val); } // 移动构造 A(A&& other) noexcept { data = other.data; other.data = nullptr; cout << "移动构造函数被调用" << endl; } };
6️⃣ 转换构造函数(Conversion Constructor)
用于从其他类型隐式转换为当前类对象。
class A { int x; public: A(int val) : x(val) {} // int -> A }; A a = 5; // 自动调用 A(int)
C++函数传入指针和引用有什么不同
| 特性 | 指针参数 | 引用参数 |
|---|---|---|
| 语法 | void func(int *p) |
void func(int &r) |
| 调用方式 | 传地址:func(&a) |
直接传变量:func(a) |
是否可为 nullptr |
✅ 可以 | ❌ 不可为空 |
| 是否可重新指向别的对象 | ✅ 可以(p = &b;) |
❌ 不行(引用一旦绑定不能改) |
| 使用时是否需解引用 | ✅ 需要用 *p 访问值 |
❌ 直接用 r 访问值 |
| 是否更安全 | ⚠️ 容易出错(空指针、悬空) | ✅ 更安全(自动引用绑定) |
应用场景:
| 场景 | 推荐方式 | 原因 |
|---|---|---|
普通对象参数(如 int, double) |
引用 | 简洁安全,不需要取地址 |
对象或结构体(如 std::vector) |
const 引用 |
避免拷贝,提高效率 |
| 可为空对象(可选参数) | 指针 | 指针可以为 nullptr,引用不行 |
| 动态内存管理 | 指针 | 需要控制生命周期 |
| 需要修改原对象 | 引用或指针 | 都可以,看可读性要求 |
二、数据结构与算法
顺序结构(数组)和链式结构(链表)有什么不同,应用在哪些场景?


队列和栈有什么不同,应用场景有哪些?


三、stm32
一个开关控制一个LED灯开关,由stm32做主控,按下按键,灯会时亮时不亮,原因由那些?
1️⃣ 按键抖动,按键没弄消抖
2️⃣ 检测方式不对(没有边沿触发)
3️⃣ 中断触发多次(如果你用了 EXTI)
RAM
GPIO工作模式
stm32入门-----GPIO口输出的学习与使用(上)_stm32 ll gpio-CSDN博客
| 模式编号 | 模式名称 | 功能分类 | 输出类型 | 上下拉配置 | 应用场景 |
|---|---|---|---|---|---|
| 1 | 浮空输入 | 输入 | 无 | 无 | 通用输入,外接信号控制电平 |
| 2 | 上拉输入 | 输入 | 无 | 上拉 | 默认高电平的输入,防止悬空 |
| 3 | 下拉输入 | 输入 | 无 | 下拉 | 默认低电平的输入,防止悬空 |
| 4 | 模拟输入(模拟模式) | 模拟 | 无 | 无 | ADC/DAC,降低功耗 |
| 5 | 推挽输出 | 输出 | 推挽 | 可配 | 数字输出,如控制LED |
| 6 | 开漏输出 | 输出 | 开漏 | 外部上拉 | 多主设备通信,如 I2C |
| 7 | 推挽复用输出 | 复用 | 推挽 | 可配 | 外设功能,如 USART、SPI |
| 8 | 开漏复用输出 | 复用 | 开漏 | 外部上拉 | 外设功能,如 I2C、Open-Drain 总线 |
UART和USART区别
| 比较项 | UART(通用异步收发器) | USART(通用同步/异步收发器) |
|---|---|---|
| 全称 | Universal Asynchronous Receiver/Transmitter | Universal Synchronous/Asynchronous Receiver/Transmitter |
| 通信方式 | 仅支持异步通信 | 支持异步和同步通信 |
| 是否需要时钟 | 否 | 同步通信时需要外部或内部时钟 |
| 起始/停止位 | 需要(用于异步同步) | 异步时需要,同步模式下不需要 |
| 通信速度 | 一般较慢(受限于异步机制) | 同步模式下可更快 |
| 应用场景 | 串口调试、GPS模块、蓝牙等常见串口外设 | 除异步串口外,也用于高速同步外设通信 |
| 硬件复杂度 | 简单 | 稍复杂(多了同步部分) |
| 兼容 UART | — | ✅ 是 |
中断和DMA不同
- DMA:是一种无须CPU的参与,就可以让外设与系统内存之间进行双向数据传输的硬件机制,使用DMA可以使系统CPU从实际的I/0数据传输过程中摆脱出来,从而大大提高系统的吞吐率。
- 中断:是指CPU在执行程序的过程中,出现了某些突发事件时,CPU必须暂停执行当前的程序,转去处理突发事件,处理完毕后CPU又返回源程序被中断的位置并继续执行。
总而言之中断和DMA的区别就是:DMA不需CPU参与,而中断是需要CPU参与的。
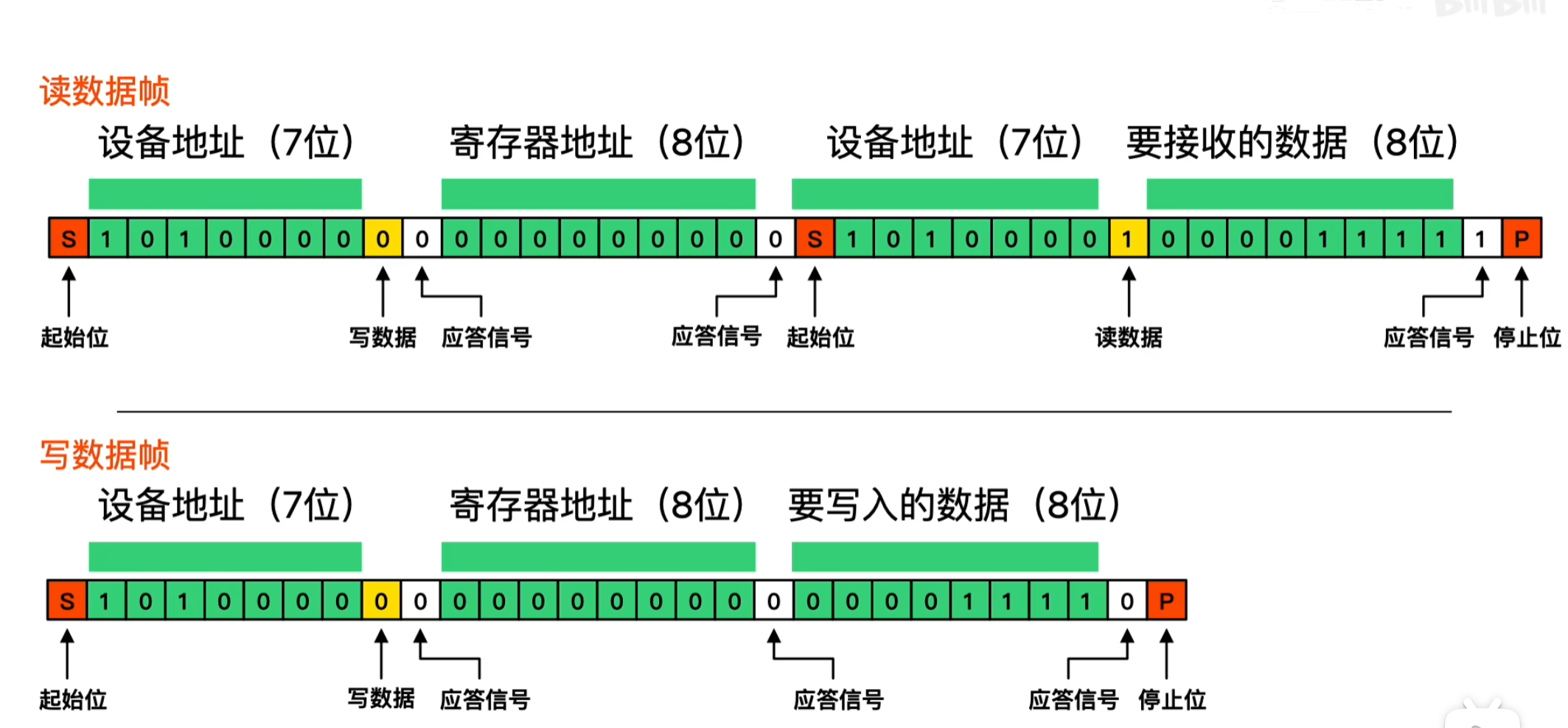
IIC读写时序
stm32入门-----软件I2C通讯_i2c两个相同地址-CSDN博客
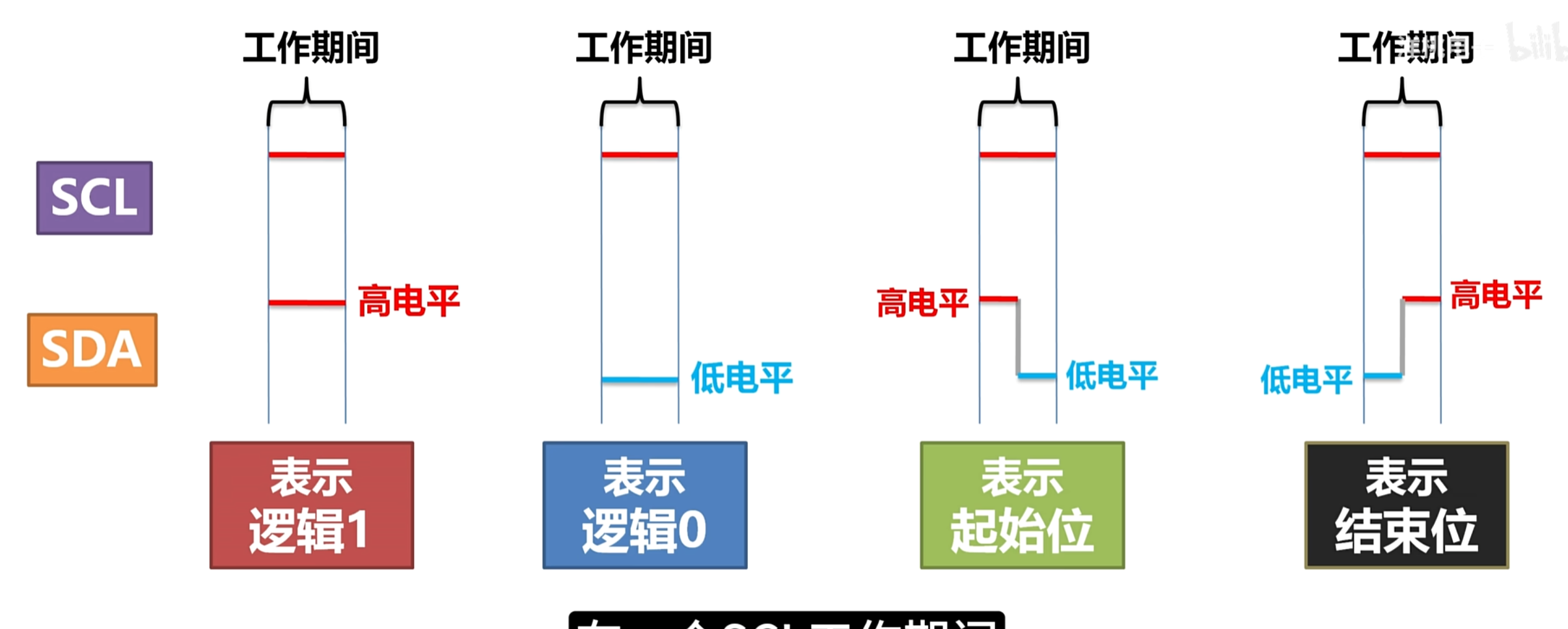
时序
- 规定SCL高电平的时为工作状态,低电平为休息状态。在SCL工作状态时候,保证SDA保持处于高电平(数据1)或低电平(数据0)
- 空闲状态下,SCL和SDA都是高电平状态
- 起始的时候SCL处于高电平,SDA由高电平降低到低电平;结束的时候SCL处于高电平,SDA由低电平会到高电平
- 应答位0表示收到,1表示没收到
- 第一组数据(字节),的前7为表示设备地址,最后一位表示操作位,1是读,0是写
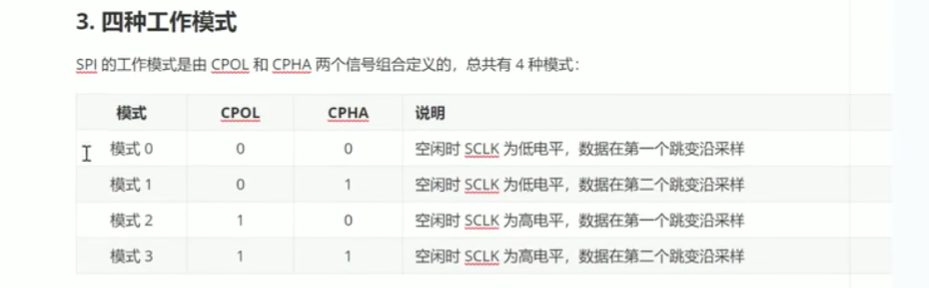
SPI
stm32入门-----SPI通讯协议_stm32spi发送数据-CSDN博客


工作模式
ADC模数转换 (模拟信号到数字信号)

stm32入门-----ADC模数转换器(理论篇——上)-CSDN博客
将 外部的模拟电压信号 转换为 数字信号(数值),供 MCU(如 STM32)进行处理。

1、两个内部信号源:
内部信号源 说明 内部温度传感器(Temperature Sensor) 用于测量芯片内部的温度,可用于过热保护或温补。通常连接到 ADC 的一个专属通道(如 ADC_IN16)。内部参考电压(VREFINT) 内部稳定电压源(3.3V芯片一般为 1.2V 左右),用于对比测量 VDD 的波动(即供电电压监测),通常连接到 ADC_IN17。
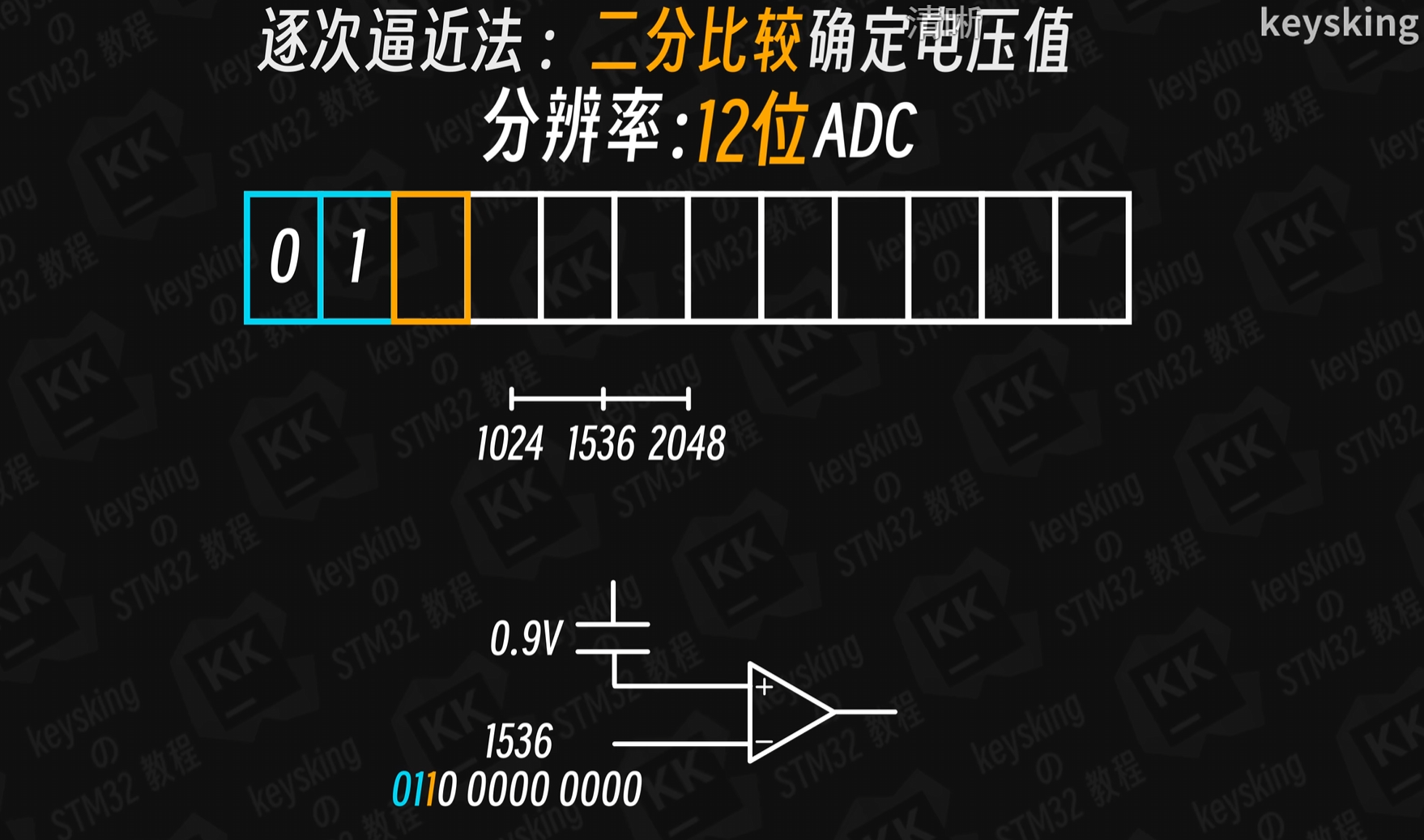
2、逐次逼近型ADC(二分查找)
3、转换模式*4(连续、扫描)
要根据ADC支持的分频情况去分频,比如时钟信号72MHz,ADC最大只能支持14MHz,需要使用6分频。
FreeRtos调度算法
- 抢占式:高优先级任务可以打断低优先级的任务的执行(适应于优先级不同的任务)。
- 时间片轮转:相同优先级的任务以相同的时间片(1ms)去运行,时间片耗尽后就强制退出去执行其他任务。
- 协作式调度:当使用vtaskdelay() 去是否CPU的资源让其他任务来运行,如可用信号量,互斥量实现。(这种方式很少用)
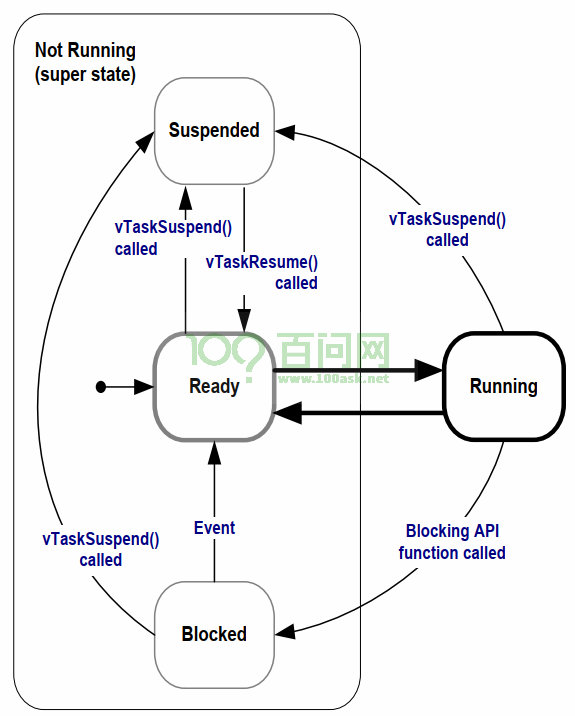
FreeRtos任务的状态
- 就绪态:任务创建的时候就进入到就绪态
- 运行态:任务的代码运行的时候
- 阻塞态:任务在等待信号量、互斥量的时候会进入,同步过程
- 挂起态:使用vTaskSuspend() 函数去进入到挂起,后面可以手动去使vTaskResume()唤醒
FreeRtos任务同步方式
FreeRtos------信号量、互斥量和事件组_信号量重复give-CSDN博客
FreeRtos-----队列_freertos队列发送数据-CSDN博客
- 队列:同步的同时也可以传递数据(天然的生产者消费者模型)
- 信号量:分为二进制信号量(实现共享资源的访问)和计数信号量(实现手动生产者消费者模型)
- 互斥量:实现共享资源的安全访问,又叫做锁
- 事件组:可以实现多个任务的通知,一次性去通知多个任务
- 任务通知:轻量级的任务同步方式,TCB,不需要创建就可以使用,一般用于一对一的通讯(上面的四种都是用于多对多的通讯)

环形缓冲区(KFIFO)
环形缓冲区并不是指真正物理意义上的一个环,只是把一个存储区(比如uint8_t array[1000]),通过程序上的设计实现一个环形的效果,对于这个存储区要实现"先入先出"的特性。这样做的好处就是减少了内存碎片和动态分配内存的系统开销
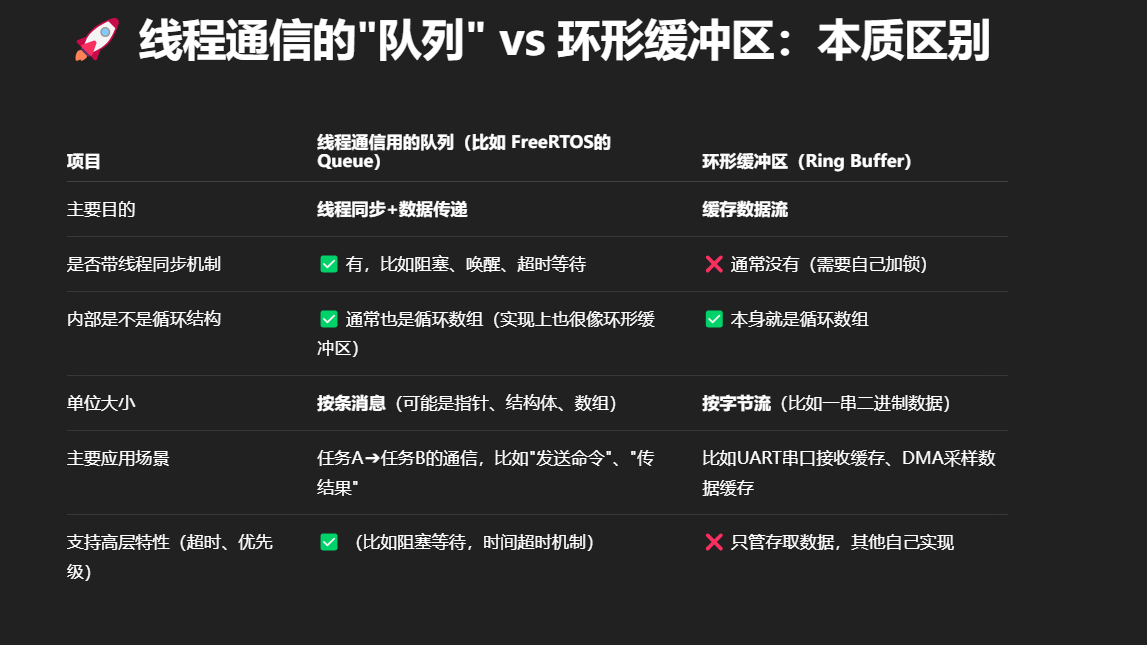
FIFO
四、操作系统Linux
基本指令
FreeRtos和Linux的不同
✅ 1. 实时性
FreeRTOS:实时操作系统,任务调度及时,响应快,适合对时效性要求高的应用。
Linux:默认不是实时系统,响应存在延迟(可打 RT 补丁提升)。
✅ 2. 系统体积
FreeRTOS:非常小,几 KB ~ 几十 KB,就能运行。
Linux:系统庞大,至少几 MB 起步,还需文件系统等。
✅ 3. 资源需求
FreeRTOS:适合资源受限的 MCU,如 STM32。
Linux:需要 MMU、更多 RAM 和存储,如 Cortex-A 芯片。
✅ 4. 编程模型
FreeRTOS:无进程概念,只有任务(线程)。
Linux:支持多进程、多线程,功能更完整。
✅ 5. 设备支持
FreeRTOS:需手动添加驱动,功能有限。
Linux:驱动丰富,支持 USB、文件系统、网络等。
✅ 6. 启动速度
FreeRTOS:极快,几毫秒~几十毫秒。
Linux:慢,通常几秒甚至更久。
✅ 7. 应用场景
FreeRTOS:嵌入式、IoT、工业控制、小型设备。
Linux:智能设备、边缘计算、图像处理、AI。
| 特性 | FreeRTOS | Linux(普通 Linux 内核) |
|---|---|---|
| 调度类型 | 优先级抢占式调度(Preemptive) + 可选时间片轮转 | 完全公平调度 CFS 或实时调度策略(SCHED_FIFO/SCHED_RR) |
| 实时性 | 强实时(RTOS),可保证高优先级任务立即被调度 | 软实时,普通 Linux 调度无法保证严格响应时间 |
| 任务切换开销 | 极小,轻量级 | 相对大(保存/恢复上下文,内核态切换) |
| 调度粒度 | 微秒级,可定制 Tick | 毫秒级(通常 1~10ms tick),依赖系统时钟 |
| 可抢占性 | 高优先级任务可随时抢占低优先级任务 | 默认低优先级任务可能阻塞高优先级任务,除非使用 RT 内核 |
| 任务上下文 | 小,线程/任务结构体控制 | 大,线程 PCB + 内核栈 + 内存页表 |
| 阻塞机制 | 阻塞等待队列(信号量/消息队列) | 阻塞等待内核对象(信号量/文件/IO) |
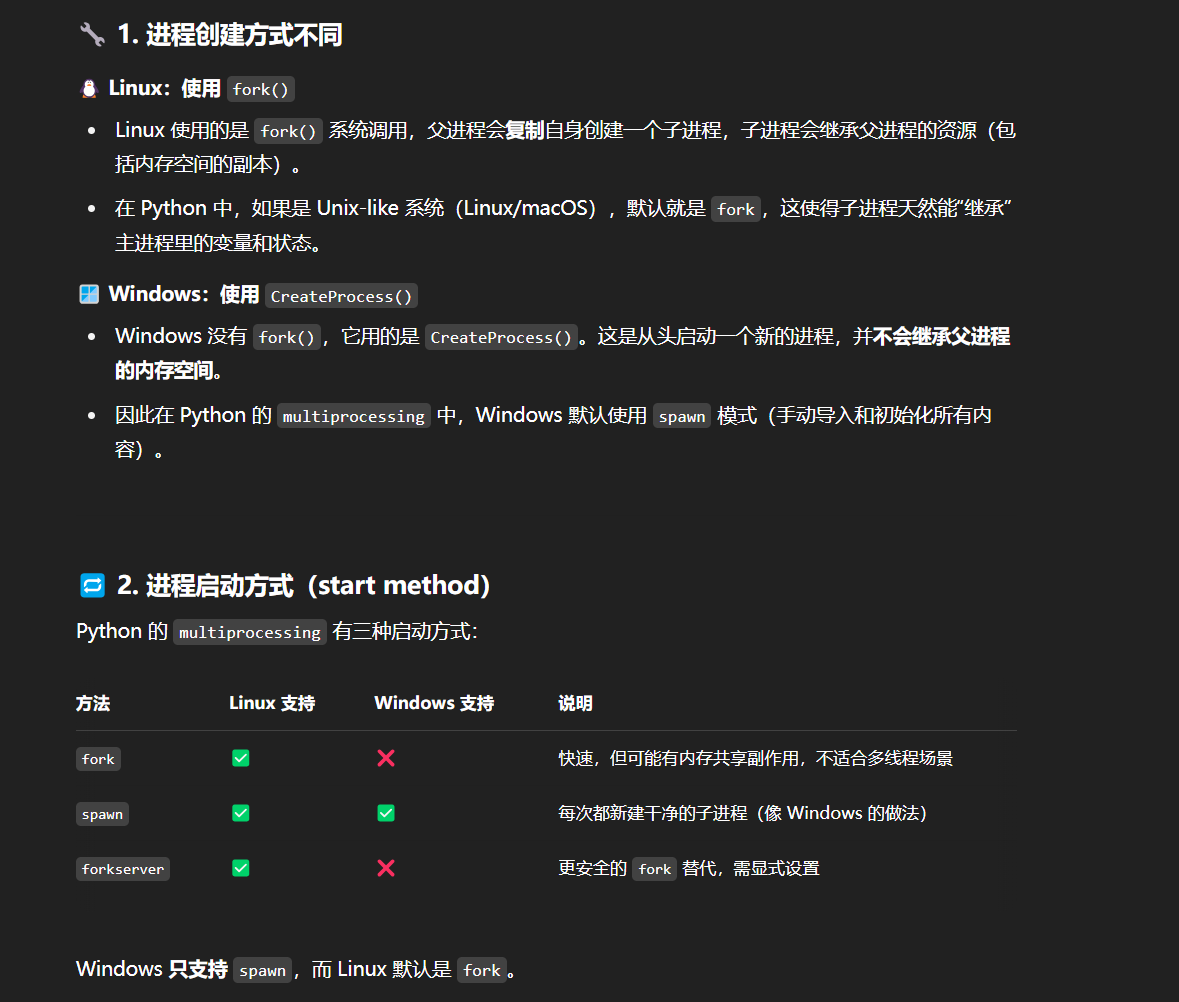
Windows和Linux的多进程有什么不同
怎么去理解FreeRtos的实时性呢,实时体现在哪里?
1. 什么叫“实时”?
实时性 ≠ 快,而是 在规定的时间内一定完成。
举个例子:
非实时系统(比如普通 Linux):外部传感器发来一个信号,系统可能马上响应,也可能因为别的进程占用 CPU 而延迟几十毫秒。
实时系统(FreeRTOS):你能保证“外部中断来了,10 微秒内一定执行某个任务”,即使系统还有其他任务在运行。
2. FreeRTOS 实时性的体现
(1) 任务调度的确定性
FreeRTOS 使用 优先级抢占式调度:
高优先级任务随时可以打断低优先级任务,立即执行。
保证关键任务(比如电机转速控制)不会被次要任务(比如串口日志打印)拖慢。
(2) 中断响应快
FreeRTOS 内核本身很小,ISR(中断服务程序)的延迟非常低。
外设信号到 CPU 执行对应处理之间的时间可控。
(3) 时间片与定时器精度
FreeRTOS 的 tick 中断(通常 1ms 或更小)驱动调度器,可以让任务按精确的周期运行。
例如:设定一个任务每 5ms 必须采样一次传感器,FreeRTOS 能保证它按照 5ms 周期执行,而不会拖到几十毫秒。
(4) 资源访问的有序性
提供信号量、互斥锁、队列等同步机制,避免任务间竞争导致的不可预测延迟。
3. 举个例子 📌
比如一个电机控制系统:
实时需求:电机转速必须每 1ms 采样一次,超过 1ms 延迟会导致控制不稳定甚至烧毁设备。
在 FreeRTOS:
创建一个高优先级任务,每 1ms 采集传感器数据并调整 PWM 占空比。
不管系统还在干什么(比如蓝牙通信、显示屏刷新),这个任务都能按时执行。
在普通 Linux:
可能因为文件系统或网络栈占用 CPU,导致任务被延迟几十毫秒,电机控制就会失效。
✅ 一句话总结:
FreeRTOS 的实时性体现在:它能保证关键任务在规定的时间内被调度和执行,中断响应快、任务切换延迟低,结果是“可预测的时间行为”。
Bootloader的作用有什么
1. Bootloader 是什么?
Bootloader 是设备上电或复位后第一个运行的软件,在操作系统或应用程序启动之前执行。
它相当于系统的“接生员”和“桥梁”,负责把系统从硬件上电状态带到能运行应用的状态。
2. Bootloader 的功能和作用
(1) 硬件初始化
初始化最基本的硬件:时钟、存储器控制器、串口、GPIO、DDR、外设。
让系统进入一个“可运行”的环境。
(2) 加载操作系统或应用
把操作系统内核(Linux kernel、RTOS)或者用户应用程序,从存储器(Flash、eMMC、SD 卡)拷贝到 RAM 里,然后跳转执行。
(3) 提供升级/下载功能
Bootloader 通常带有下载接口(UART、USB、CAN、以太网),可以更新固件。
在嵌入式设备里常用于 OTA(远程升级)。
(4) 安全校验
可以在加载前校验程序完整性(CRC、签名验证),保证固件没有被篡改。
有些系统会支持安全启动(Secure Boot)。
(5) 多启动选择
有的 Bootloader(比如 U-Boot)允许选择启动不同内核、不同分区的系统。
3. 在不同场景下的作用
嵌入式单片机(MCU)
STM32 的 Bootloader 可以让你选择从串口、USB、CAN 下载程序。
用户也可以写自己的 Bootloader,比如支持双分区升级。
Linux/Android 系统
常见的 Bootloader 有 U-Boot。
它先初始化硬件,然后加载 Linux 内核,再传递设备树、内存信息。
PC 里
BIOS/UEFI 就是 Bootloader 的一种,负责加载操作系统(Windows、Linux)。
4. 一句话总结
Bootloader 的作用是:在系统上电后,完成硬件初始化、加载并启动操作系统或应用程序,同时提供升级和安全校验的机制。
Linux启动流程是怎么样的
1. 上电与固件阶段(BIOS/UEFI 或 SoC BootROM)
作用:上电后 CPU 从预设地址取指令,执行固化在芯片内部的启动代码。
主要任务:
完成 硬件自检(内存、CPU、外设)。
根据配置(启动顺序,如 NAND、SD 卡、eMMC、网络等)加载 第一阶段 Bootloader 到内存。
2. Bootloader 阶段(引导程序)
Bootloader 通常分为 两阶段:
第一阶段(Stage1,比如 SPL)
代码很小,放在片上 SRAM。
作用是初始化最基本的硬件(内存、时钟),然后加载更完整的 Bootloader。
第二阶段(Stage2,比如 U-Boot)
提供更丰富的功能(驱动、文件系统)。
常见任务:
初始化内存、串口、网络等。
读取内核镜像(zImage / bzImage / Image.gz)和 设备树(DTB)。
设置启动参数(bootargs)。
最后调用
bootm或bootz跳转到内核入口点。
3. 内核加载与解压阶段
Bootloader 将内核镜像加载到内存后,跳转执行。
内核执行前会:
解压缩(如果是压缩格式)。
初始化页表、内存管理、CPU 核心。
加载设备树(DTB)描述硬件信息。
4. 内核初始化阶段
初始化 驱动、总线、文件系统、网络协议栈 等。
挂载 根文件系统(rootfs)。
找到第一个用户态程序(通常是
/sbin/init或由init=/path指定)。
5. 用户空间启动阶段
init 进程(PID 1)启动。
读取配置文件(如
/etc/inittab、systemd配置)。启动系统服务、登录管理器、网络服务、shell 等。
最终进入用户交互环境(命令行 / 图形界面)。
总结
Linux 启动流程就是:
👉 上电/BIOS → Bootloader → 内核 → init → 用户空间
动态库和静态库区分与应用
定义:
| 项目 | 静态库(Static Library) | 动态库(Dynamic Library) |
|---|---|---|
| 扩展名 | .a(Linux)、.lib(Windows) |
.so(Linux)、.dll(Windows) |
| 链接方式 | 编译时链接 | 运行时链接(程序运行时加载) |
| 是否复制进程序 | ✅ 会复制(编译时嵌入) | ❌ 不复制,程序运行时依赖外部库 |
| 可执行文件大小 | 大(包含库的代码) | 小(仅包含引用信息) |
动态库和静态库的区别:
| 维度 | 静态库 | 动态库 |
|---|---|---|
| 链接时间 | 编译时 | 运行时 |
| 占用空间 | 可执行文件大 | 可执行文件小,库可共享 |
| 更新维护 | 需重新编译整个程序 | 更新库文件即可,无需重新编译 |
| 启动速度 | 快(不依赖外部库) | 稍慢(运行时加载库) |
| 依赖性 | 独立 | 依赖外部库文件 |
| 调试方便性 | 更容易调试 | 动态调试更复杂 |
动态库(Dynamic Library,也叫共享库,如 .so / .dll)虽然带来了模块化、节省内存、便于更新等优点,但它也有一些缺点和使用上的注意点。下面我们来具体看看:


📌 静态库:编译时合并进去,程序独立但体积大
📌 动态库:运行时调用外部库,体积小但需依赖
编译过程(编译原理)
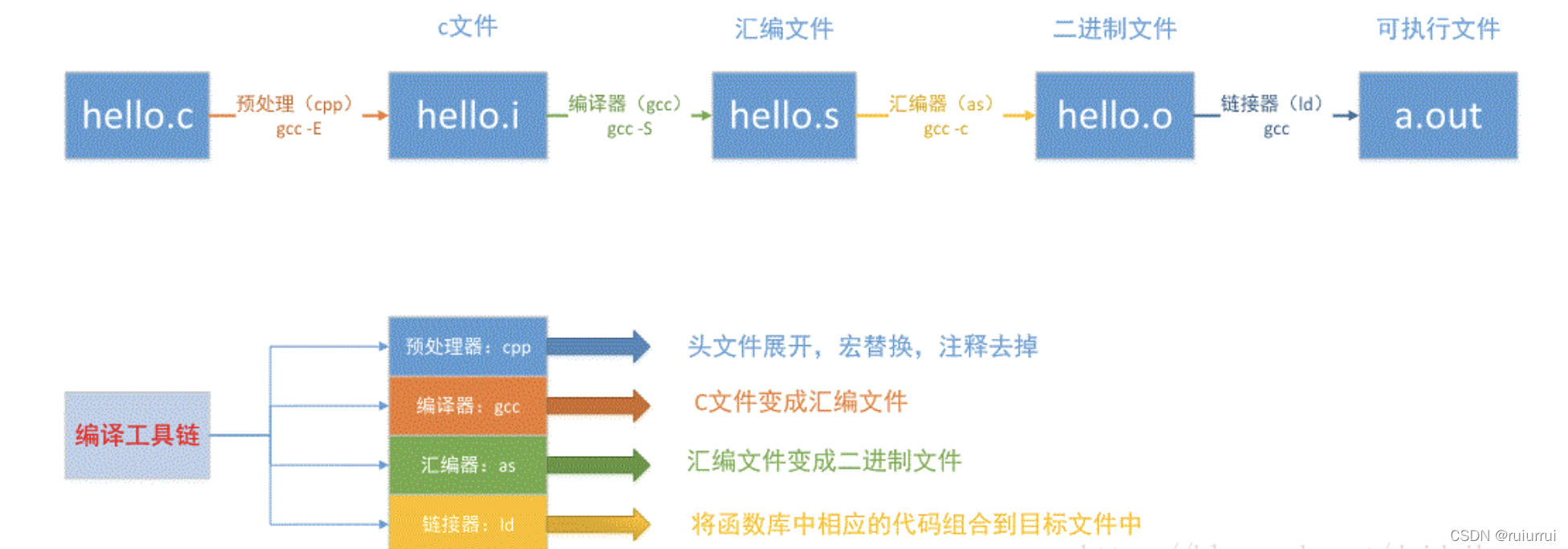
Linux下可执行文件一般是ELF文件,Windows下最常见就是.exe文件。
进程和线程区别(本质区别:是否共享内存)
1.定义:进程是系统资源分配的基本单位;线程是执行最小单元。
2.资源占用:进程都有自己独立的地址空间;在同一个进程中而线程的地址内存是共享的。
3.容错性:进程出问题了不会影响到其他的进程执行;但是线程出问题了整个程序都会出问题。
4.调度:进程是独立的一个单位,在上下文恢复的内容就比较多,消耗的资源也比较多;线程的上下文切换比较快,占用的资源少。
多进程和多线程优缺点、应用场景
线程
优点:
- 轻量级:线程之间上下文切换的开销小,创建和删除也小
- 内存共享:线程之间是可以共享内存的,可以同时访问同一个进程里面的资源
缺点:
- 线程安全:由于数据共享容易导致数据竞争和死锁问题
- 调试问题
适用场景:
- Web服务器、网络服务、用户界面、适用于IO密集型
进程
优点:
- 隔离性:每一个进程有自己独立的空间,不同的进程之间不会影响,安全性稳定性高
- 适合CPU密集型任务:可以利用多核CPU提高程序的并行处理能力
缺点:
- 创建和管理开销大:每一个进程需要独立的空间,创建和删除开销大
- 通讯复杂
- 启动时间比较长
应用场景:
- 适用于CPU密集型任务,需要高度隔离的任务
进程之间通讯有哪些,哪些是需要内核的?
1.管道
2.命名管道
3.共享内存(mmpa)
4.信号量
5.消息队列
6..套接字
7.信号
需要用到内核的如下:
管道,共享内存(在内核空间创建共享内存),信号量,消息队列,套接字。
僵尸进程、孤儿进程、守护进程
Linux-----进程处理(waitpid,进程树,孤儿进程)_linux waitpid-CSDN博客
- 僵尸进程:使用fork创建了子进程,子进程任务退出后,父进程没有去调用wait 或者waitpid函数去结束子进程,子进程的信息还是保留在系统中,并没有结束
- 孤儿进程:因为父进程结束了之后,子进程就会变为孤儿进程,孤儿进程会被init1号线收养
- 守护进程:父进程创建子进程后,后台运行的、长期存在的进程,不直接与用户交互,通常用于执行系统服务、任务调度、监听请求等工作。
线程池
线程池是一种多线程管理模式,主要目的是提高系统的并发性能和资源利用效率。在线程池中,预先创建了一定数量的线程,线程被重复利用来执行任务,从而避免了频繁创建和销毁线程的开销。线程池的核心组件通常包括线程队列、任务队列和线程管理机制。
线程池的工作流程
- 1.初始化线程池:启动应用时,线程池会创建一定数量的线程并使它们处于等待状态
- 2.提交任务:当有任务需要执行时,任务被提交到线程池的任务队列中。
- 3.分配任务:线程池从任务队列中取出任务,并将任务分配给空闲线程执行。
- 4.任务执行:线程从任务队列中取到任务后开始执行,执行完成后线程返回到线程池中继续等待下一个任务。
- 5.重复利用线程:线程池中的线程可以被多个任务重复使用,避免了频繁的创建和销毁操作,降低了系统资源消耗。
线程池的优势
- 减少线程创建和销毁的开销:线程创建和销毁是比较耗时的操作,线程池通过重用线程减少了这种开销。
- 控制并发数:线程池可以通过控制线程的最大数量,防止系统因线程过多而造成资源枯。
- 提高响应速度:当有任务提交时,可以立即使用已有的线程处理任务,无需等待新线程的创建。
应用场景
- 服务器并发处理:如Web服务器、数据库服务器等,需要同时处理大量请求的应用。
- 并行计算任务:如图像处理、数据分析等需要高并发运算的场景。
- 后台任务:如日志记录、异步消息处理等不需要立即返回结果的任务。
线程安全
Linux-----线程同步(资源竞争和同步锁)_linux 同步锁-CSDN博客
Linux-----线程同步(资源竞争和同步锁)_linux 同步锁-CSDN博客
线程安全就是指:在多线程环境下,多个线程同时访问共享资源时,程序的行为是正确的、可预期的,不会因为线程竞争导致错误。
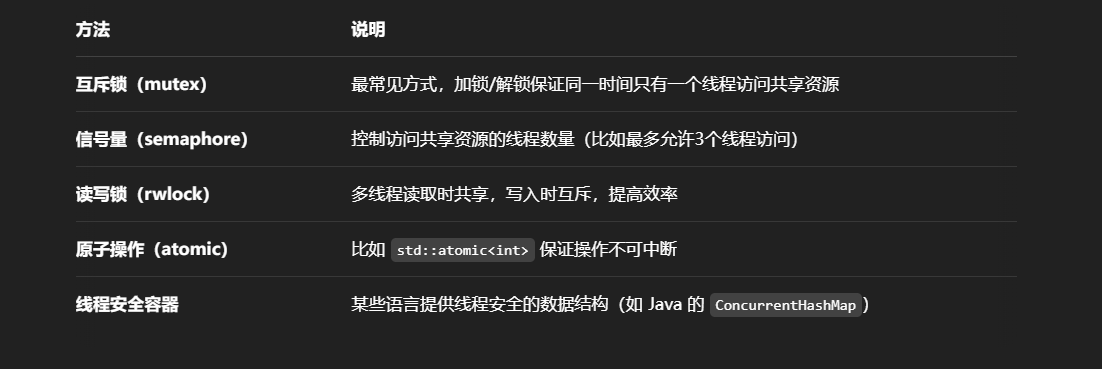
原子操作
原子操作(Atomic Operation)是指一种不可分割的操作,在计算机系统中它要么完全执行成功,要么完全不执行,即使在多线程或多进程环境下也不会被中断或打断。它是实现并发编程中线程安全的重要基础。
读写锁和互斥锁
互斥锁 是一种线程同步机制,线程在获取失败时会阻塞自己,等待调度器唤醒。这是操作系统级别的机制,常用于保证临界区互斥访问。
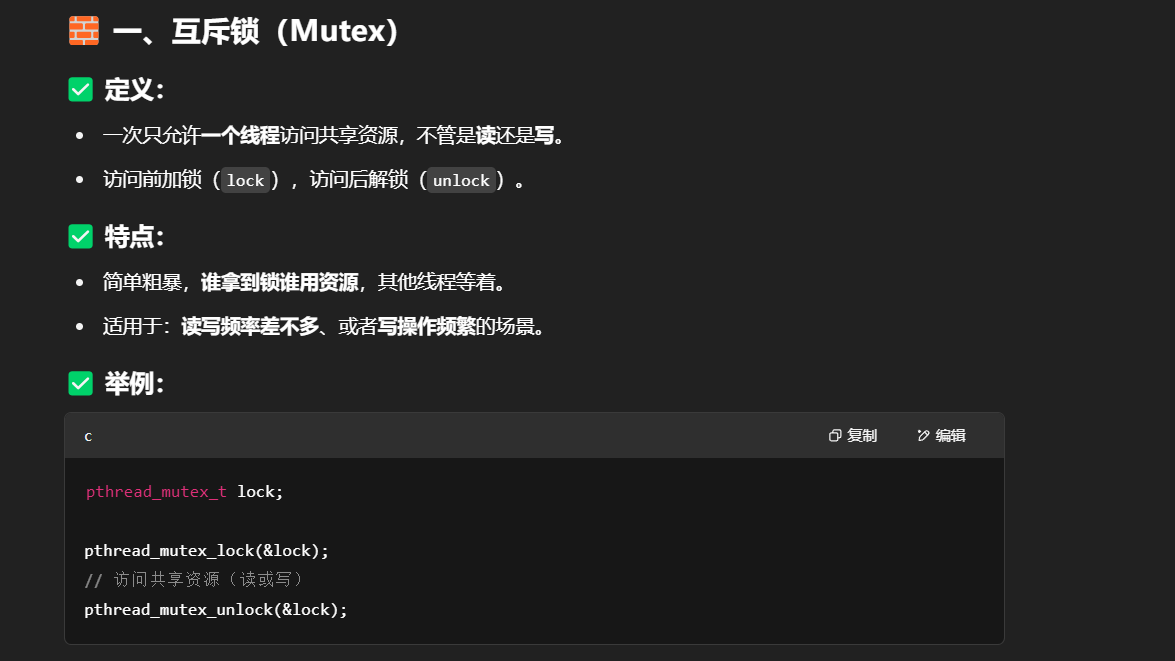
自旋锁
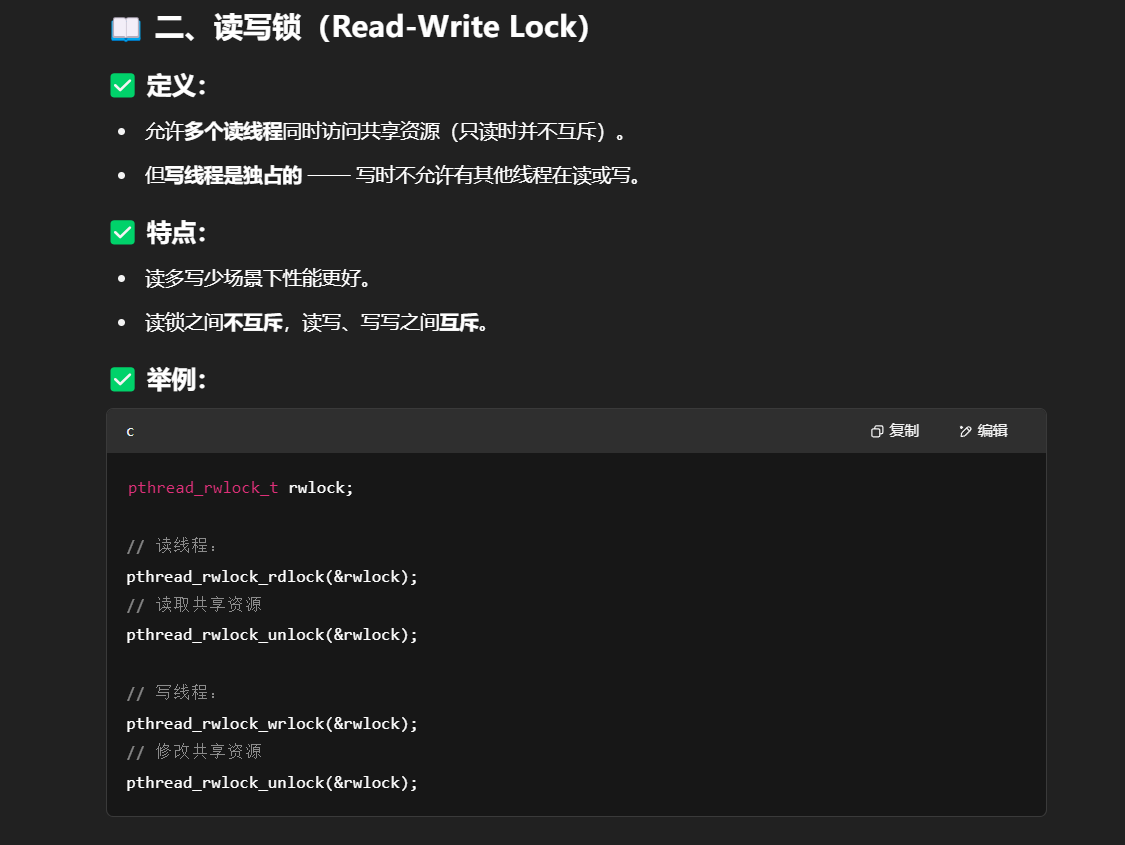
自旋锁 是一种轻量级的锁机制。当线程无法获得锁时,它不会睡眠或让出 CPU,而是一直在循环检查锁是否可用,就像“原地打转”一样。
| 特性 | 自旋锁(Spinlock) | 互斥锁(Mutex) |
|---|---|---|
| 阻塞行为 | ❌ 不阻塞,忙等 | ✅ 阻塞等待,线程可能睡眠 |
| CPU 占用 | 高(空转占 CPU) | 低(挂起线程,等待唤醒) |
| 上锁效率 | ✅ 非常快(无需上下文切换) | ❌ 较慢(涉及线程调度切换) |
| 适合场景 | 🔹 临界区极短、抢锁时间很短 | 🔹 临界区较长,抢锁时间可能较长 |
| 死锁风险 | ⚠️ 有(代码不小心可能一直 spin) | 也有,但更容易管理 |
| 线程上下文切换 | ❌ 无需切换(用户空间处理) | ✅ 需要切换上下文(进入内核) |

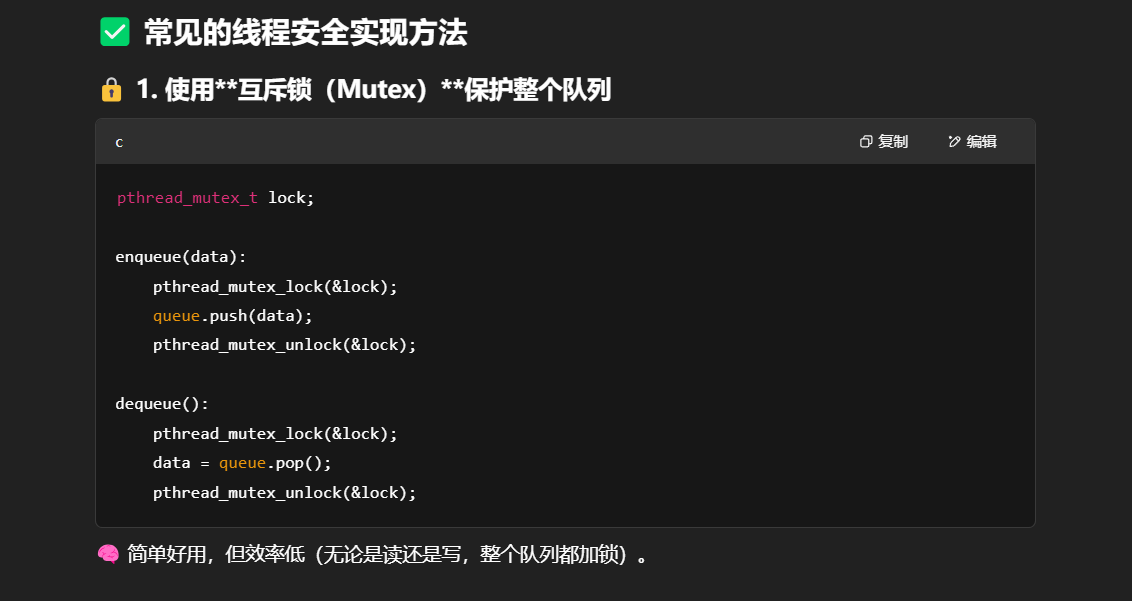
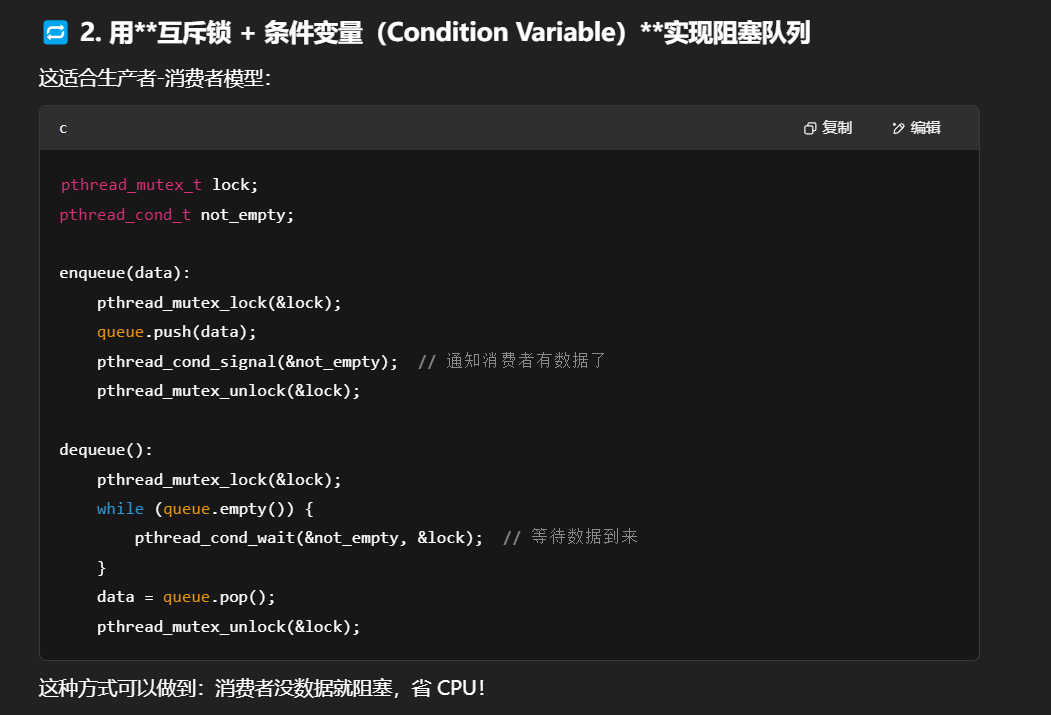
线程通讯队列
OSI七层网络模型
| 层级 | 名称(中文) | 名称(英文) | 功能简述 |
|---|---|---|---|
| 7 | 应用层 | Application Layer | 为用户提供网络服务,如 HTTP、FTP、SMTP 等 |
| 6 | 表示层 | Presentation Layer | 数据的编码、加密、压缩等,确保数据可被正确理解 |
| 5 | 会话层 | Session Layer | 建立、管理、终止会话(Session) |
| 4 | 传输层 | Transport Layer | 端到端通信、可靠性保障,如 TCP、UDP |
| 3 | 网络层 | Network Layer | 寻址与路由选择,如 IP、ICMP |
| 2 | 数据链路层 | Data Link Layer | 数据帧传输、差错检测,如 Ethernet(以太网) |
| 1 | 物理层 | Physical Layer | 比特流传输,如电缆、光纤、网卡等硬件信号传输 |
也可记为:“物数网传会表应”(从下往上)
TCP/IP四层协议
| 层级 | 名称(中文) | 名称(英文) | 主要功能 | 对应 OSI 七层 |
|---|---|---|---|---|
| 4 | 应用层 | Application Layer | 提供应用服务,如 HTTP、FTP、DNS | OSI 第 5~7 层 |
| 3 | 传输层 | Transport Layer | 提供端到端通信,如 TCP、UDP | OSI 第 4 层 |
| 2 | 网络层(互联网层) | Internet Layer | 实现路由和寻址,如 IP、ICMP | OSI 第 3 层 |
| 1 | 网络接口层 | Network Access Layer | 负责物理链路传输,如以太网、Wi-Fi | OSI 第 1~2 层 |
“网传网应”(网络接口层 → 传输层 → 网络层 → 应用层)
TCP和UDP
1.TCP是提供可靠的数据传输方式,通过三次握手四次挥手去连接;UDP是面向无连接的,传输不可靠。
2.UDP传输速度更加快,同时也容易出现丢包现象;而TCP速度慢,对CPU资源占用相对比较大,但不会丢包
3.应用场景:TCP一般应用于邮箱文件的传输;UDP是用于实时视频,直播,游戏的传输。
为什么TCP是三次握手
三次握手如下
tcp要保证双方接收和发送都是正常的。
- 第一次握手客户端发送SYN包后,服务端接收成功,说明客户端发送是正常的(服务端角度)
- 第二次握手服务端回复客户端SYN+ACK包,表示服务端的发送和接收的正常的(客户端角度)
- 第三次握手是客户端再回复一个ACK包给服务端,表示客户端的接收是正常的(服务端角度)
TCP粘包问题和解决
TCP 粘包问题是网络编程中的一个常见现象。它源于 TCP 协议的“流式”特性,即数据是连续不断的字节流,在接收方并不能天然知道每一段数据的边界。
| 原因 | 说明 |
|---|---|
| 1. TCP 是面向字节流的协议 | 没有消息边界,系统按缓存和效率优化发送数据 |
| 2. 发送方发送速度快于接收方读取速度 | 多条消息被合并发送 |
| 3. 网络缓冲机制(Nagle 算法等) | 小数据包被缓冲后合并发送 |
4. recv() 不保证一次收完所有数据 |
可能只读取到部分内容,导致拆包 |
| 方法 | 原理说明 |
|---|---|
| 1. 固定长度消息 | 每个消息长度固定,接收方按固定字节数读取 |
| 2. 特殊分隔符 | 每条消息结尾添加如 \n、` |
| 3. 消息头+消息体 | 先发送消息长度作为头部,接收方先读长度再按长度读数据体(常用) |
| 4. 高级协议封装 | 使用如 Protobuf、HTTP、MQTT 等已处理粘包问题的协议 |
DHCP协议

MQTT协议(物联网)
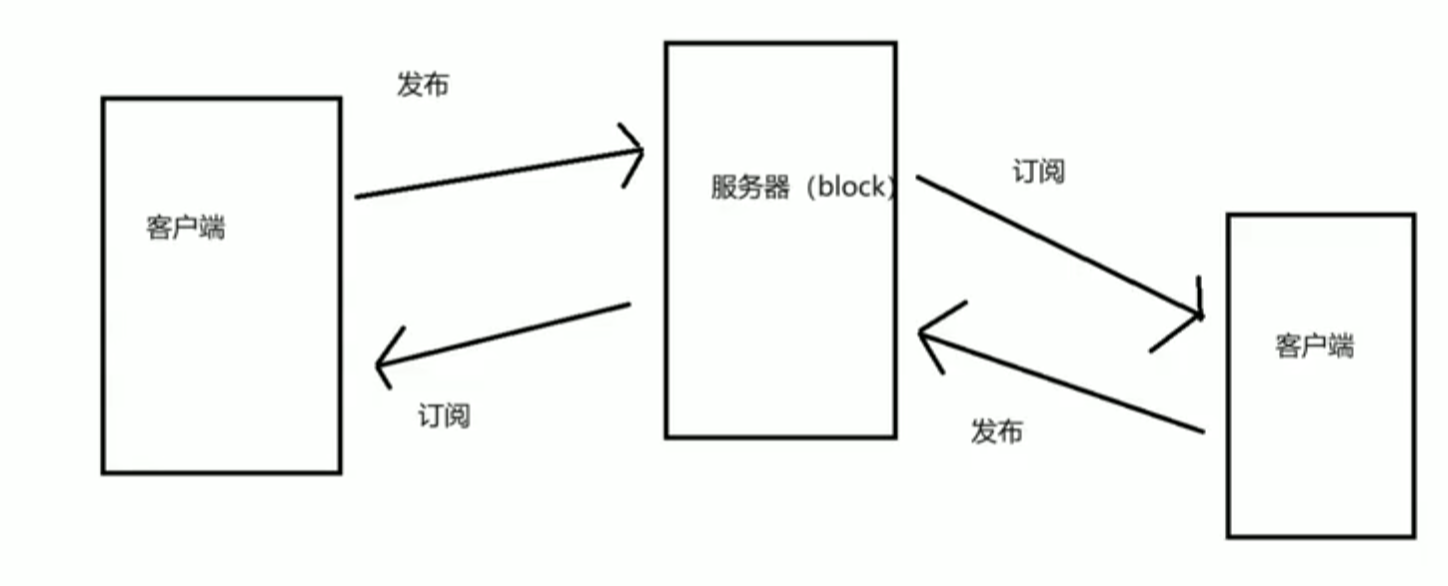
MQTT协议是一种轻量级的消息发表/订阅的协议,适用于低带宽、高延迟和不可靠的设备。其包括如下特点:
- 发布/订阅模型:客户端可以发布消息到特定的主题,也可以订阅主题从而接收到消息,这个服务器就类似于中转站,只要两个客户端是订阅相同的主题的时候就可以互相发送接收消息
- 轻量级:MQTT的开销很小,适合那种资源受限的设备(此协议是基于TCP/IP实现的)
- 服务等级划分:MQTT协议提供三种服务质量等级的划分,分别是QoS0、QoS1、QoS2
- 保持长连接(保活):客户端会定时去向服务端发送一个心跳包以保证连接还存在
| QoS 等级 | 名称(中文) | 名称(英文) | 传输特点 | 是否可能重复接收 | 是否保证不丢消息 | 用途示例 |
|---|---|---|---|---|---|---|
| QoS 0 | 至多一次(最多一次) | At most once | 发送后不确认、不重发 | ✅ 可能丢失 | ❌ 不保证 | 温湿度上传、日志、状态上报等 |
| QoS 1 | 至少一次 | At least once | 收到需 ACK,发送端若未确认会重发 | ❌ 不丢,但 ✅ 可能重复 | ✅ 保证送达 | 报警通知、交易提醒等 |
| QoS 2 | 只有一次(仅一次) | Exactly once | 采用四步握手机制,确保消息 只到达一次 | ❌ 不重复 | ✅ 可靠但代价高 | 金融系统、命令控制等关键场景 |
五、附加



魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)