机器学习/深度学习/NLP-8-LR、SVM、GBDT、RandomForest、xgboost、boosting
机器学习/深度学习/NLP-3-LR、SVM、GBDT、RandomForest、xgboost、boostingLRSVMGBDTRandomForestxgboostboostingLRSVMGBDTRandomForestxgboostboosting
机器学习/深度学习/NLP-8-LR、SVM、GBDT、RandomForest、xgboost、boosting
(待补充)
LR
首先说一下回归和分类的区别:回归是根据连续变量预测一个定量输出值,分类则是根据离散的变量来预测一个定性输出值。逻辑回归(Logistic Regression)虽然名字叫回归,本质上它却是一种分类方法。
常用sigmoid函数作为假设函数。
SVM
(以下内容主要借鉴参考2,按照自己需要学习的,重新整理了一遍.,理解不算透彻)
支持向量机(support vector machines, SVM)是一种二分类模型,它的工作目标是在特征空间上找到一个使两类数据边际最大的超平面。当然,这要求两类数据点是线性可分的,也就是这两类数据点能够在特征空间中能够被一条直线完全分开。
超平面有无穷个,但几何间隔最大的超平面只有一个: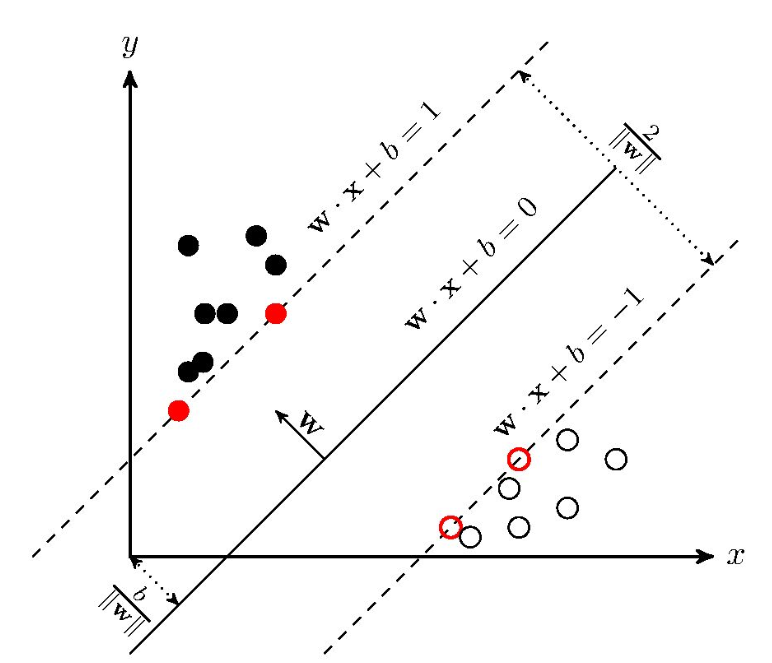
其中,超平面的定义为: w T x + b = 0 w^{T}x+b=0 wTx+b=0 , x x x为训练实例, w w w为权重矩阵, b b b为偏置。
上图中标红的距离超平面最近的点,就叫做支持向量。
优化推导:
从数学的角度可知,二维空间点 ( x , y ) (x,y) (x,y)到直线 A x + b y + C = 0 Ax+by+C=0 Ax+by+C=0 的距离公式为:
∣ A x + B y + C ∣ A 2 + B 2 \frac{\left | Ax+By+C\right |}{\sqrt{A^{2}+B^{2}}} A2+B2∣Ax+By+C∣
扩展到SVM应用的超平面n维空间,点 x = ( x 1 , x 2 ⋯ x n ) x=(x_1,x_2 \cdots x_n) x=(x1,x2⋯xn) 到直线 w T x + b = 0 w^{T}x+b=0 wTx+b=0 的距离为:
∣ w T x + b ∣ ∣ ∣ w ∣ ∣ \frac{\left |w^{T}x+b\right |}{||w||} ∣∣w∣∣∣∣wTx+b∣∣
其中 ∣ ∣ w ∣ ∣ = w 1 2 + w 2 2 + ⋯ + w n 2 {\left ||w\right ||}=\sqrt{w_1^{2}+w_2^{2}+ \cdots +w_n^{2}} ∣∣w∣∣=w12+w22+⋯+wn2 。
假设支持向量到超平面的距离为 d d d ,那么由定义易知其他点到超平面的距离大于 d d d 。
在超平面上,如下公式成立:
{ w T x + b ∥ w ∥ ⩾ d y = 1 w T x + b ∥ w ∥ ≤ − d y = − 1 \left\{\begin{matrix} \frac{ w^{T}x+b}{\left \| w\right \|} \geqslant d & y=1 \\ \frac{ w^{T}x+b}{\left \| w\right \|} \leq -d & y=-1 \end{matrix}\right. {∥w∥wTx+b⩾d∥w∥wTx+b≤−dy=1y=−1
也即:
{ w T x + b ∥ w ∥ d ⩾ 1 y = 1 w T x + b ∥ w ∥ d ≤ − 1 y = − 1 \left\{\begin{matrix} \frac{ w^{T}x+b}{\left \| w\right \|d} \geqslant 1 & y=1 \\ \frac{ w^{T}x+b}{\left \| w\right \|d} \leq -1 & y=-1 \end{matrix}\right. {∥w∥dwTx+b⩾1∥w∥dwTx+b≤−1y=1y=−1
去掉 ∣ ∣ w ∣ ∣ d ||w||d ∣∣w∣∣d 后(因为关注的主要为符号变换,大于0为一类,小于0为另一类, ∣ ∣ w ∣ ∣ d ||w||d ∣∣w∣∣d 是正数项,对目标函数优化没有影响,假设其为1),公式化为:
{ w T x + b ⩾ 1 y = 1 w T x + b ≤ − 1 y = − 1 \left\{\begin{matrix} w^{T}x+b \geqslant 1 & y=1 \\ w^{T}x+b \leq -1 & y=-1 \end{matrix}\right. {wTx+b⩾1wTx+b≤−1y=1y=−1
合并两个方程:
y ( w T x + b ) ⩾ 1 y(w^{T}x+b) \geqslant 1 y(wTx+b)⩾1
因为 ∣ y ∣ = 1 |y|=1 ∣y∣=1 ,所以 y ( w T x + b ) = ∣ w T x + b ∣ y(w^{T}x+b) = |w^{T}x+b| y(wTx+b)=∣wTx+b∣ ,所以点 x = ( x 1 , x 2 ⋯ x n ) x=(x_1,x_2 \cdots x_n) x=(x1,x2⋯xn) 到直线 w T x + b = 0 w^{T}x+b=0 wTx+b=0 的距离为:
d = ∣ w T x + b ∣ ∣ ∣ w ∣ ∣ = y ( w T x + b ) ∣ ∣ w ∣ ∣ d=\frac{\left |w^{T}x+b\right |}{||w ||}=\frac{y(w^{T}x+b) }{||w||} d=∣∣w∣∣∣∣wTx+b∣∣=∣∣w∣∣y(wTx+b)
最大化这个距离(乘以2是为了后面推导,其对目标函数优化没有影响):
m a x 2 ∗ y ( w T x + b ) ∣ ∣ w ∣ ∣ max 2*\frac{y(w^{T}x+b) }{||w||} max2∗∣∣w∣∣y(wTx+b)
因为支持向量满足 y ( w T x + b ) = 1 y(w^{T}x+b)=1 y(wTx+b)=1,所以上述优化可转为:
m a x 2 ∣ ∣ w ∣ ∣ max \frac{2}{||w||} max∣∣w∣∣2
转换一下:
m i n 1 2 ∣ ∣ w ∣ ∣ min \frac{1}{2}{||w||} min21∣∣w∣∣
同样地,为了方便计算,去掉 ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣ 的根号,给它开平方:
m i n 1 2 ∣ ∣ w ∣ ∣ 2 min \frac{1}{2}{||w||^2} min21∣∣w∣∣2
经过上面的这一通操作,最后可以得到SVM目标函数优化问题的通俗公式:
m i n 1 2 ∣ ∣ w ∣ ∣ 2 s . t . y i ( w T x i + b ) ⩾ 1 min \frac{1}{2}{||w||^2} s.t. \qquad y_i(w^{T}x_i+b) \geqslant 1 min21∣∣w∣∣2s.t.yi(wTxi+b)⩾1
GBDT
RandomForest
xgboost
boosting
参考

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)