机器学习:使用高斯朴素贝叶斯分类器(GaussianNB)、随机森林分类器(RandomForestClassifier)进行癌细胞分类,预测肿瘤是恶性还是良性
本文旨在根据癌细胞的特征对癌细胞进行分类,并确定它们是“恶性”还是“良性”;通过python编写两种经典的机器学习算法(随机森林分类和朴素贝叶斯分类)来训练细胞的形态特征。根据不同模型对癌症细胞的分类结果,对两个个模型在该数据集中的性能进行评价。

前言
系列专栏:【机器学习:算法项目实战】✨︎
本专栏涉及金融、医疗、电商、图像识别、自然语言处理等多个领域的真实案例,让读者从基础的监督学习(如线性回归、逻辑回归、决策树、随机森林)、无监督学习(聚类算法、降维技术)到进阶的深度学习(神经网络、卷积神经网络CNN、循环神经网络RNN等),都能够全面掌握机器学习领域的核心算法,了解不同行业背景下机器学习的应用。
本文旨在根据癌细胞的特征对癌细胞进行分类,并确定它们是“恶性”还是“良性”;通过python编写两种经典的机器学习算法(随机森林分类和朴素贝叶斯分类)来训练细胞的形态特征。根据不同模型对癌症细胞的分类结果,对两个个模型在该数据集中的性能进行评价。
目录
1. 相关库和数据集
1.1 相关库介绍
GaussianNB是一种朴素贝叶斯分类器,常用于处理分类问题。RandomForestClassifier是一个在scikit-learn库中用于分类问题的强大工具。它是一个集成学习方法,通过集成多个决策树的预测结果来进行最终的分类预测。本文用于根据给定数据集中的属性预测给定患者是患有恶性肿瘤还是良性肿瘤。
Pandas– 该库有助于以 2D 数组格式加载数据框,并具有多种功能,可一次性执行分析任务。Numpy– Numpy 数组速度非常快,可以在很短的时间内执行大型计算。Matplotlib/Seaborn– 此库用于绘制可视化效果。Sklearn– 包含多个库,这些库具有预实现的功能,用于执行从数据预处理到模型开发和评估的任务。
import sklearn
from sklearn.model_selection import train_test_split
# importing the module of the machine learning model
from sklearn.naive_bayes import GaussianNB
# importing the dataset
from sklearn.datasets import load_breast_cancer
1.2 数据集介绍
Scikit-learn 附带了一些小型标准数据集,不需要从任何外部网站下载任何文件。我们将用于机器学习问题的数据集是威斯康星州乳腺癌(诊断)数据集。该数据集包括有关乳腺癌肿瘤的几个数据以及分类标签,即恶性或良性。可以使用以下函数加载它:
load_breast_cancer([return_X_y])
该数据集包含 569 个肿瘤的 569 个实例或数据,包括 30 个属性或特征的数据,如肿瘤的半径、纹理、周长、面积等。我们将使用这些功能来训练我们的模型。
import sklearn
from sklearn.model_selection import train_test_split
# importing the module of the machine learning model
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
# importing the dataset
from sklearn.datasets import load_breast_cancer
# loading the dataset
data = load_breast_cancer()
1.3 组织并检查数据
为了更好地理解数据集包含的内容以及我们如何使用数据来训练我们的模型,让我们首先组织数据,然后使用print函数查看它包含的内容。
# Organize our data
target_names = data['target_names']
targets = data['target']
feature_names = data['feature_names']
features = data['data']
检查数据所包含内容
# looking at the data
print(target_names)
['malignant' 'benign']
因此,我们看到肿瘤的每个数据集都被标记为“恶性”或“良性”。
print(targets)
输出
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 0 0 0 0 0 0 0 0 1 0 1 1 1 1 1 0 0 1 0 0 1 1 1 1 0 1 0 0 1 1 1 1 0 1 0 0
1 0 1 0 0 1 1 1 0 0 1 0 0 0 1 1 1 0 1 1 0 0 1 1 1 0 0 1 1 1 1 0 1 1 0 1 1
1 1 1 1 1 1 0 0 0 1 0 0 1 1 1 0 0 1 0 1 0 0 1 0 0 1 1 0 1 1 0 1 1 1 1 0 1
1 1 1 1 1 1 1 1 0 1 1 1 1 0 0 1 0 1 1 0 0 1 1 0 0 1 1 1 1 0 1 1 0 0 0 1 0
1 0 1 1 1 0 1 1 0 0 1 0 0 0 0 1 0 0 0 1 0 1 0 1 1 0 1 0 0 0 0 1 1 0 0 1 1
1 0 1 1 1 1 1 0 0 1 1 0 1 1 0 0 1 0 1 1 1 1 0 1 1 1 1 1 0 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 0 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1
1 0 1 1 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 1 0 1 1 1 1 0 0 0 1 1
1 1 0 1 0 1 0 1 1 1 0 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 1 1 0 0 1 0 0
0 1 0 0 1 1 1 1 1 0 1 1 1 1 1 0 1 1 1 0 1 1 0 0 1 1 1 1 1 1 0 1 1 1 1 1 1
1 0 1 1 1 1 1 0 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 0 0 1 0 1 1 1 1 1 0 1 1
0 1 0 1 1 0 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 0 1
1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 0 0 1 0 1 0 1 1 1 1 1 0 1 1 0 1 0 1 0 0
1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 0 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 0 0 0 0 0 0 1]
从这里,我们看到每个标签都与 0 和 1 的二进制值相关联,其中 0 代表恶性肿瘤,1 代表良性肿瘤。
print(feature_names)
输出
['mean radius' 'mean texture' 'mean perimeter' 'mean area'
'mean smoothness' 'mean compactness' 'mean concavity'
'mean concave points' 'mean symmetry' 'mean fractal dimension'
'radius error' 'texture error' 'perimeter error' 'area error'
'smoothness error' 'compactness error' 'concavity error'
'concave points error' 'symmetry error' 'fractal dimension error'
'worst radius' 'worst texture' 'worst perimeter' 'worst area'
'worst smoothness' 'worst compactness' 'worst concavity'
'worst concave points' 'worst symmetry' 'worst fractal dimension']
在这里,我们看到了肿瘤的每个数据集所具有的所有 30 个特征或属性。我们将使用这些特征的数值来训练我们的模型,并根据这些特征做出正确的预测,无论肿瘤是恶性的还是良性的。
print(features)
输出
[[1.799e+01 1.038e+01 1.228e+02 ... 2.654e-01 4.601e-01 1.189e-01]
[2.057e+01 1.777e+01 1.329e+02 ... 1.860e-01 2.750e-01 8.902e-02]
[1.969e+01 2.125e+01 1.300e+02 ... 2.430e-01 3.613e-01 8.758e-02]
...
[1.660e+01 2.808e+01 1.083e+02 ... 1.418e-01 2.218e-01 7.820e-02]
[2.060e+01 2.933e+01 1.401e+02 ... 2.650e-01 4.087e-01 1.240e-01]
[7.760e+00 2.454e+01 4.792e+01 ... 0.000e+00 2.871e-01 7.039e-02]]
这是一个庞大的数据集,包含所有 569 个肿瘤数据实例的 30 个属性的数值。
因此,从上述数据中,我们可以得出结论,肿瘤的第一个实例是恶性的,其平均半径值为1.79900000e+01。
2. 构建ML相关模型
2.1 数据分离(训练和测试)
为了测试分类器的准确性,我们必须在看不见的数据上测试模型。因此,在构建模型之前,我们将数据分为两组,即训练集和测试集。我们将使用训练集来训练和评估模型,然后使用训练后的模型对看不见的测试集进行预测。sklearn 模块具有一个名为 train_test_split 的内置函数,该函数会自动将数据划分为这些数据集。我们将使用此函数来拆分数据。
# splitting the data
X_train, X_val,\
Y_train, Y_val = train_test_split(features, targets,
test_size=0.33,
random_state=10)
X_train.shape, X_val.shape
((381, 30), (188, 30))
train_test_split()函数使用参数 test_size 随机拆分数据。我们在这里所做的是,我们将 33% 的原始数据拆分为测试数据(X_val)。其余数据是训练数据。此外,我们为训练变量和测试变量提供了各自的标签,即 Y_train 和 Y_val。
2.2 模型构建(GaussianNB、RandomForestClassifier)
有许多机器学习模型可供选择。它们都有自己的优点和缺点。对于这个模型,我们将使用朴素贝叶斯算法,该算法通常在二元分类任务中表现良好。首先,导入 GaussianNB 模块并使用 GaussianNB() 函数对其进行初始化。然后,使用 fit() 方法将模型拟合到数据集中的数据,从而训练模型。
# initializing the classifier
models = [GaussianNB(), RandomForestClassifier()]
for i in range(len(models)):
models[i].fit(X_train, Y_train)
print(f'{models[i]} : ')
# making the predictions
val_preds = models[i].predict(X_val)
# evaluating the accuracy
print('Validation Accuracy : ', accuracy_score(Y_val, val_preds))
print()
我们可以通过将模型与测试集的实际标签进行比较来评估模型的准确性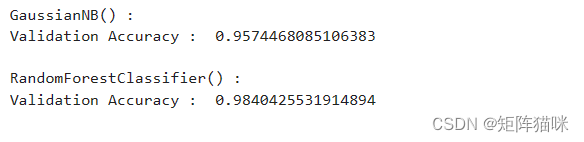
3. 评估ML相关模型
让我们使用GaussianNB、RandomForestClassifier为验证数据绘制混淆矩阵。
models = [GaussianNB(), RandomForestClassifier()]
# 循环遍历每个分类器
for i in range(len(models)):
# 训练分类器
models[i].fit(X_train, Y_train)
# 在验证集上进行预测
val_preds = models[i].predict(X_val)
# 计算混淆矩阵
#cm = confusion_matrix(Y_val, Y_pred)
# 显示混淆矩阵
metrics.ConfusionMatrixDisplay.from_estimator(
models[i], X_val, Y_val, cmap=sns.cubehelix_palette(
dark=.20, light=.95, as_cmap=True))
plt.title(f'Confusion Matrix for {models[i].__class__.__name__}')
plt.show()
print(f'{models[i]} : ')
print('Validation Accuracy : ', accuracy_score(Y_val, val_preds))
print(metrics.classification_report(
Y_val, models[i].predict(X_val)))

4. 总结
因此,我们发现这种基于朴素贝叶斯算法的机器学习分类器在预测肿瘤是恶性还是良性方面的准确率达到 95.74%,而基于随机森林的机器学习分类器在预测肿瘤方面效果更好达到98.40%。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 27
27 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)