ssd目标检测训练自己的数据_【项目实践】从零开始学习SSD目标检测算法训练自己的数据集(附注释项目代码)...
1、SSD的知识思维脑图2、简介2.1、SSD出现的背景针对YOLO V1对于小目标检测的缺陷一个死板的边框定制,导致如果出现过于密集检测物体时,效果就会比较差,而对于多阶段检测的方法,诸如,RCNN,Fast RCNN,Faster RCNN虽然对于小目标有比较好的检测效果,但是由于其自身会产生很多的冗余边界框导致基于分类的检测方法的检测时间比较久,很难满足实时性的要求。SSD是一个端...
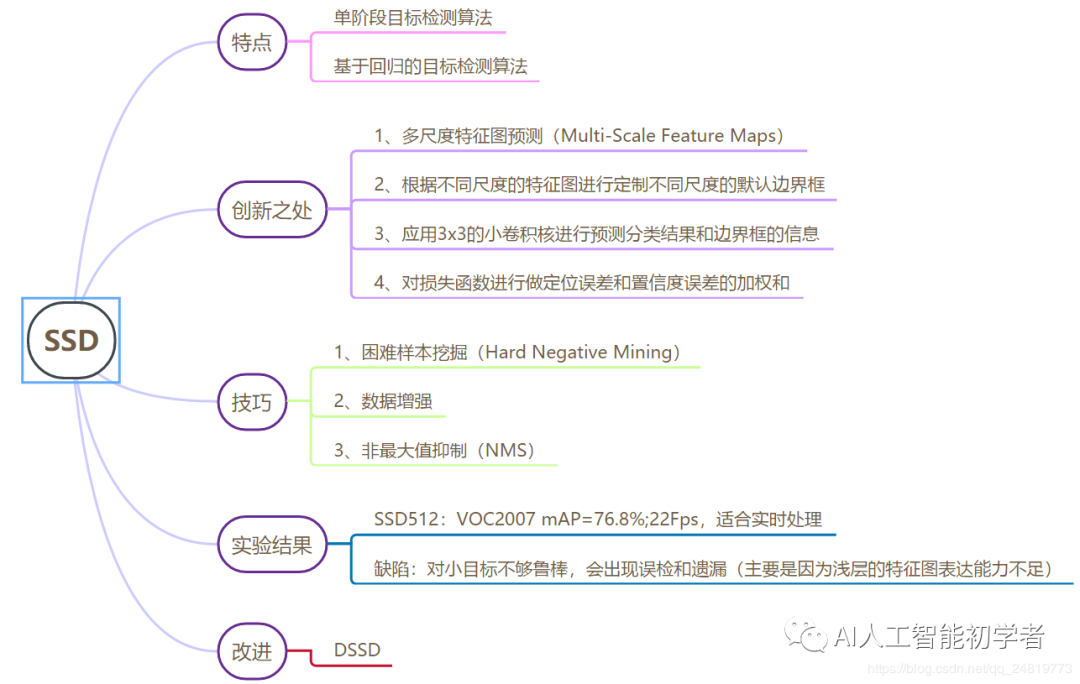
1、SSD的知识思维脑图
2、简介
2.1、SSD出现的背景
针对YOLO V1对于小目标检测的缺陷一个死板的边框定制,导致如果出现过于密集检测物体时,效果就会比较差,而对于多阶段检测的方法,诸如,RCNN,Fast RCNN,Faster RCNN虽然对于小目标有比较好的检测效果,但是由于其自身会产生很多的冗余边界框导致基于分类的检测方法的检测时间比较久,很难满足实时性的要求。
SSD是一个端到端的模型,所有的检测过程和识别过程都是在同一个网络中进行的;同时SSD借鉴了Faster R-CNN的Anchor机制的想法,这样就像相当于在基于回归的的检测过程中结合了区域的思想,可以使得检测效果较定制化边界框的YOLO v1有比较好的提升。
2.2、SSD的模型思想
2.2.1、多尺度特征图预测(Multi-Scale Feature Maps Prediction)
SSD较传统的检测方法使用顶层特征图的方法选择了使用多尺度特征图,因为在比较浅的特征图中可以对于小目标有比较好的表达,随着特征图的深入,网络对于比较大特征也有了比较好表达能力,故SSD选择使用多尺度特征图可以很好的兼顾大目标和小目标。
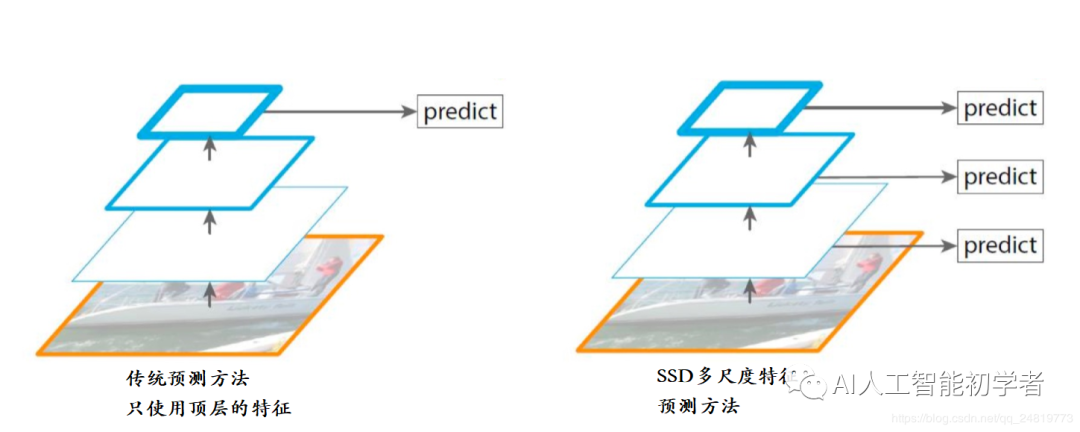
对于对尺度特征图的实验如下,全部使用是可以达到最好的效果:

2.2.2、根据不同尺度的特征图进行定制不同尺度的默认边界框
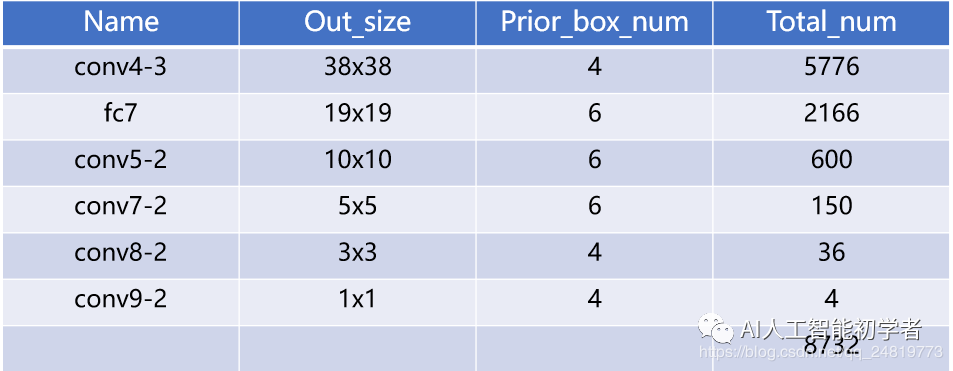
如下图和表所示,针对不同的特征图,SSD定制了不同数量的默认边界框的数量(借鉴了YOLO V1的定制边界框的思想)
但是默认框的数量是动手选择的,SSD为每个特征图定义一个尺度值,从左侧开始,conv4_3的最小尺度值为0.2,然后以0.14的线性增加到最右边的层的0.9(即0.20、0.34、0.48、0.62、0.76、0.90),然后将尺度值(Scale)与目标的宽高比结合,计算默认框的宽度和高度。
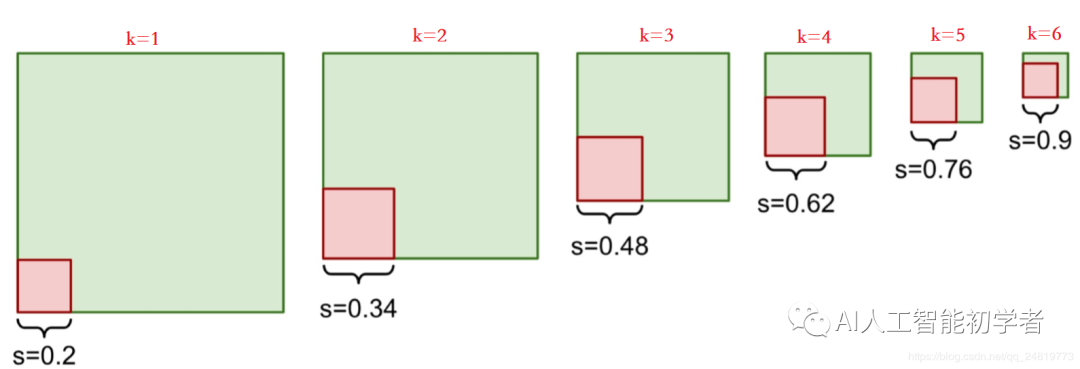
对于进行预测6次的层,SSD以5个目标高宽比开始{1,2,3,1/2,1/3},具体的计算如下:
定义的宽高比为:
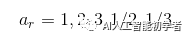
边界框的宽高为: m表示特征图的数量,s_min=0.2,s_max=0.9。
m表示特征图的数量,s_min=0.2,s_max=0.9。
由上面的表和图可以看出,最终总共产生了8732个边界框,最后使用非最大值抑制的方法进行筛选。
2.2.3、使用3x3的小卷积核进行预测分类结果和边界框的信息
SSD不使用特定的区域建议网络。它采用一个非常简单的方法,即使用小卷积滤波器计算位置和类别得分。
在提取特征图之后,SSD对每个单元应用3×3卷积滤波器以进行预测(这些滤波器像常规CNN滤波器一样计算结果)。每个滤波器输出25个通道:21个类别分数+1个边界框的信息。

2.2.4、多任务损失函数
- 匹配策略
SSD预测分为正匹配或负匹配。如果相应的默认边界框(不是预测的边界框)与GT的IoU大于0.5, 则匹配为正。否则,是负的。
SSD仅使用正匹配来计算边界框不匹配的代价。
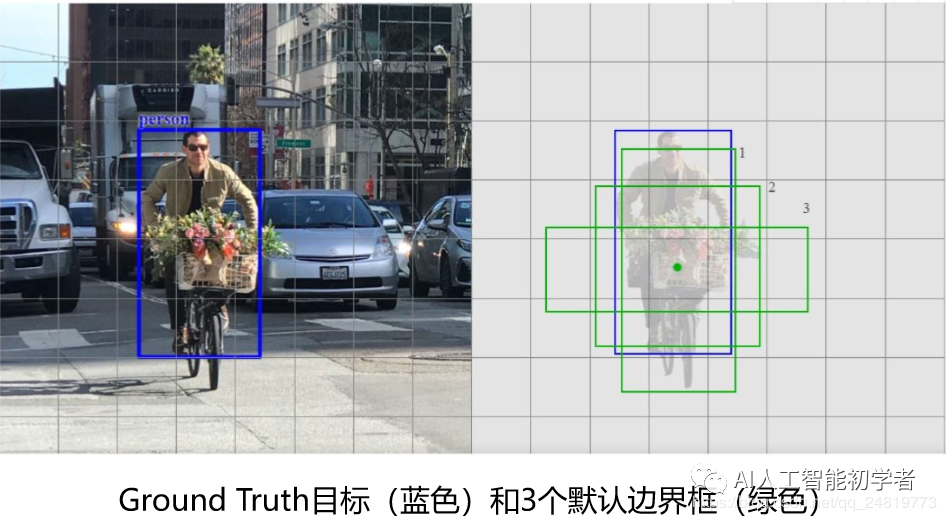
只有默认框1和2(但不是3)的IoU大于0.5。因此, 只有第1和第2个框是正匹配。一旦识别出正匹配,就使用相应的预测边界框来计算代价。这种匹配策略很好地划分了预测所负责的GT框的形状。
该匹配策略鼓励每个预测更接近相应默认框的形状。因此,预测在训练中更加多样化和稳定。
损失函数:
总体目标损失函数是**定位误差(loc)和置信度损失或者叫分类误差(conf)**的加权和:

定位损失:是GT框与预测边界框之间的不匹配。是预测框(?)和GT框(?)参数之间的Smooth L1损失

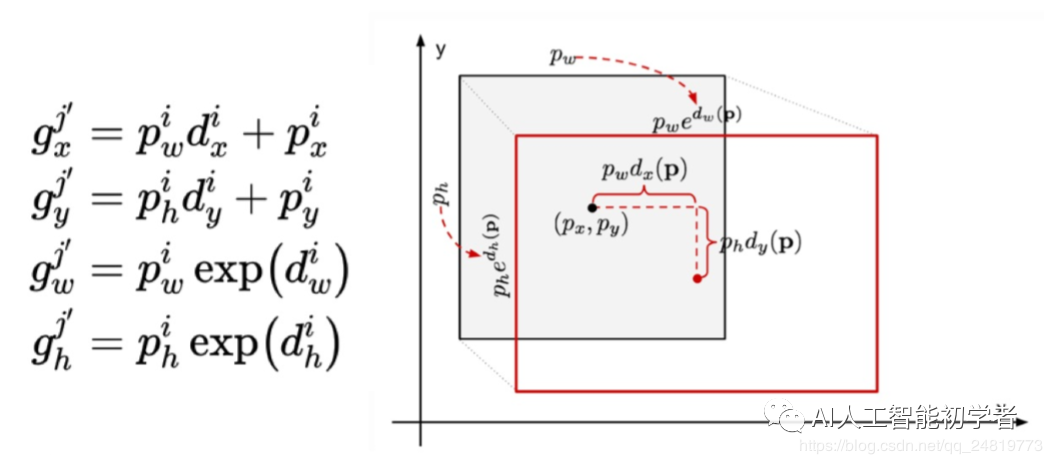
SSD仅对正匹配的预测进行惩罚。希望正匹配的预测能够更接近GT。负匹配可以忽略。
• 置信度损失或者叫分类误差:是多类置信度(c)下的softmax损失。
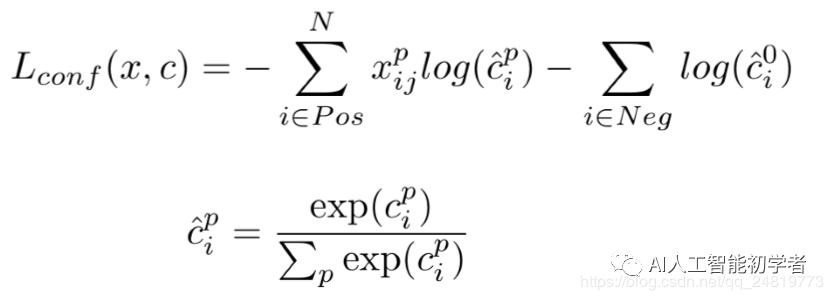
2.2.5、空洞卷积
由于SSD借鉴了DeepLab-LargeFOV,分别将VGG16的全连接层fc6和fc7转换成3×3卷积层Conv6和1×1卷积层Conv7,同时将池化层pool5由原来的2×2−s2变成3×3−s1。为了配合这种变化,采用了一种Atrous Algorithm,其实就是Conv6采用带孔卷积(Atrous/Dilation Convolution),带孔卷积在不增加参数与模型复杂度的条件下指数级扩大卷积的感受野。
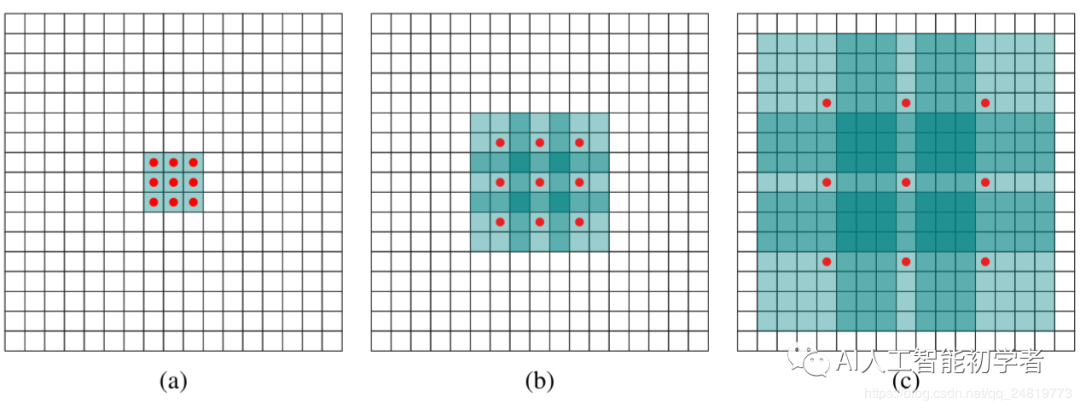
Atrous/Dilation Convolution的思想:紧密相邻的像素几乎相同,全部纳入的话会存在很多的冗余关系,于是选择跳跃H(hole)个像素取一个有效值,这样可以在较少的参数下增大感受野,也节省了内存的使用。
如下图所示,(a)是普通的3×3卷积,其感受野就是3×3,(b)是扩张率为2,此时感受野变成7×7,(c)扩张 率为4时,感受野扩大为15×15,但是感受野的特征更稀疏了。
2.2.6、困难负样本挖掘(Hard negative mining)
由于做出的预测远远超过目标存在的数量,所以负匹配比正匹配要多得多。这造成了一种训 练的类别不平衡:更多地学习背景空间而不是检测目标。
然而,SSD仍然需要负采样,因此它可以了解什么构成不良的预测。因此,我们不是使用所 有的样本,而是通过计算的置信度损失对这些负样本进行排序。SSD选择最高损失的负样本并 确保所选负样本与正样本之间的比率最多为3:1。这导致更快和更稳定的训练。
2.3、SSD的训练过程与细节
2.3.1、框架训练的具体步骤
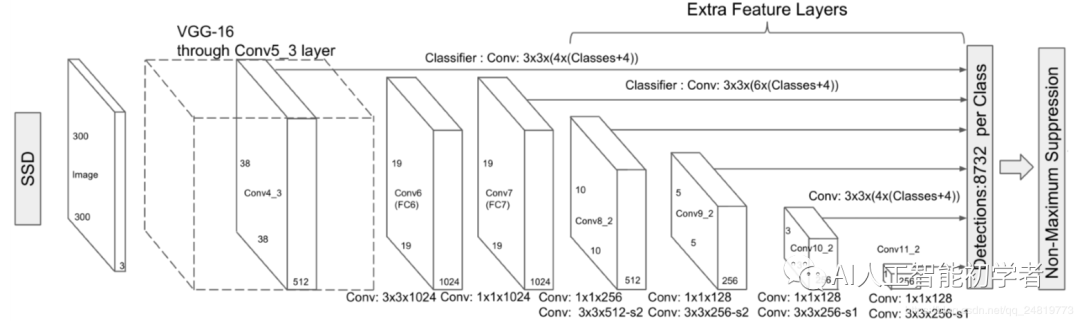
- 首先VGG16在ILSVRC CLS-LOC数据集上进行预训练。
- 然后将VGG16的全连接层fc6和fc7转换成3×3卷积层Conv6(Conv6采用带孔卷积Dilation Convolution,Conv6采用3×3大小,dilation rate=6的膨胀卷积)和1×1卷积层Conv7;
- 然后移除dropout层和fc8层,并新增一系列卷积层,在检测数据集上做fine tuning;
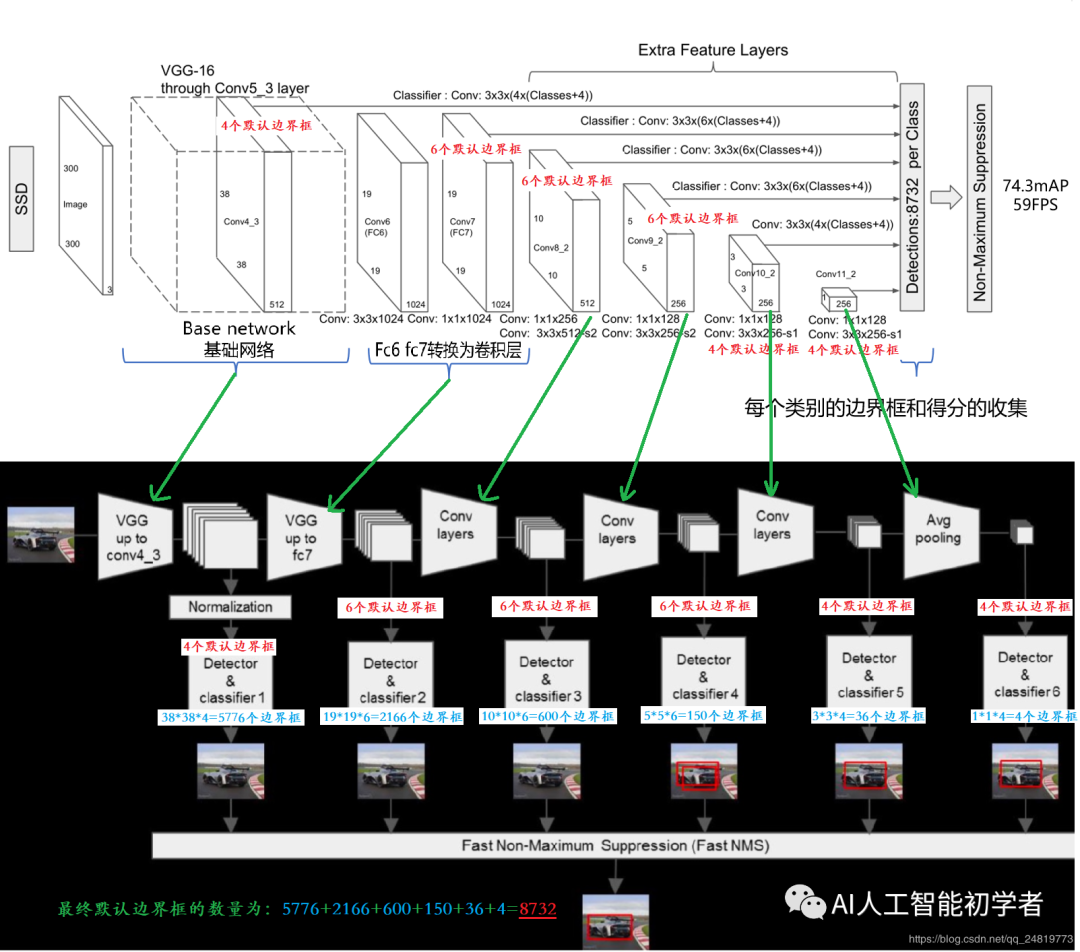
- 从后面新增的卷积层中提取Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2作为检测所用的特征图,加上Conv4_3层,共提取了6个特征图,其大小分别(38,38),(19,19),(10,10),(5,5),(3,3),(1,1),但是不同特征图设置的先验框数目不同(同一个特征图上每个单元设置的先验框是相同的,这里的数目指的是一个单元的先验框数目),由于每个先验框都会预测一个边界框,所以 SSD300一共可以预测38×38×4+19×19×6+10×10×6+5×5×6+3×3×4+1×1×4 = 8732 个边界框,这是一个相当大的数字, 所以说SSD本质上是密集采样;
- 得到了特征图之后,对特征图进行3x3卷积得到检测结果;
- 对于每个预测框,首先根据类别置信度确定其类别(置信度最大者)与置信度值, 并过滤掉属于背景的预测框。
- 然后根据置信度阈值(如0.5)过滤掉阈值较低的预测框。对于留下的预测框进行解码,根据先验框得 到其真实的位置参数(解码后一般还需要做clip,防止预测框位置超出图片)。解码之后,一般需要 根据置信度进行降序排列,然后仅保留top-k(如400)个预测框。
- 使用非最大值抑制NMS进行筛选,过滤掉那些重叠度较大的预测框。最后剩余的预测框就是检测结果。
base = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512]
def vgg(i):
layers = []
in_channels = i
for v in base:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
return layers
def add_extras(i, batch_norm=False):
# Extra layers added to VGG for feature scaling
layers = []
in_channels = i
# Block 6
# 19,19,1024 -> 10,10,512
layers += [nn.Conv2d(in_channels, 256, kernel_size=1, stride=1)]
layers += [nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1)]
# Block 7
# 10,10,512 -> 5,5,256
layers += [nn.Conv2d(512, 128, kernel_size=1, stride=1)]
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1)]
# Block 8
# 5,5,256 -> 3,3,256
layers += [nn.Conv2d(256, 128, kernel_size=1, stride=1)]
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=1)]
# Block 9
# 3,3,256 -> 1,1,256
layers += [nn.Conv2d(256, 128, kernel_size=1, stride=1)]
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=1)]
return layers
2.3.2、特征图的检测过程:
检测值包含两个部分:类别置信度和边界框位置, 各采用一次3×3卷积来进行完成。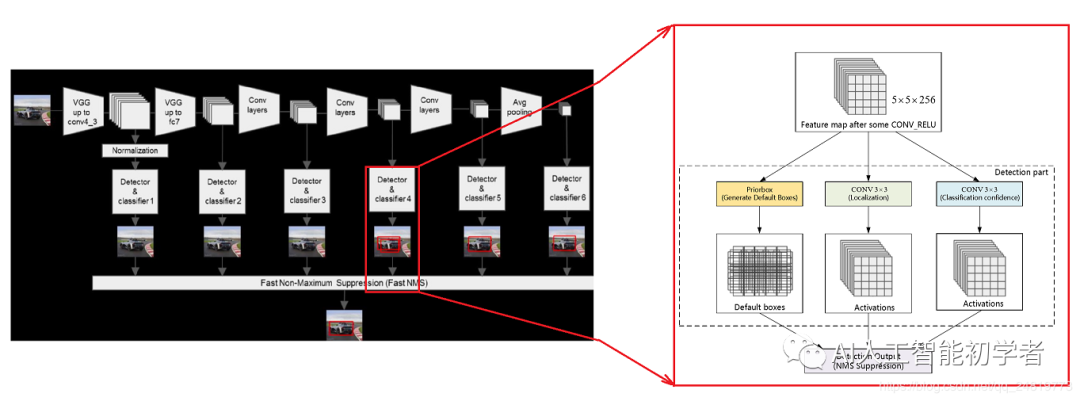 每一个有效特征层对应的先验框对应着该特征层上 每一个网格点上 预先设定好的多个框。所有的特征层对应的预测结果的shape如下:
每一个有效特征层对应的先验框对应着该特征层上 每一个网格点上 预先设定好的多个框。所有的特征层对应的预测结果的shape如下: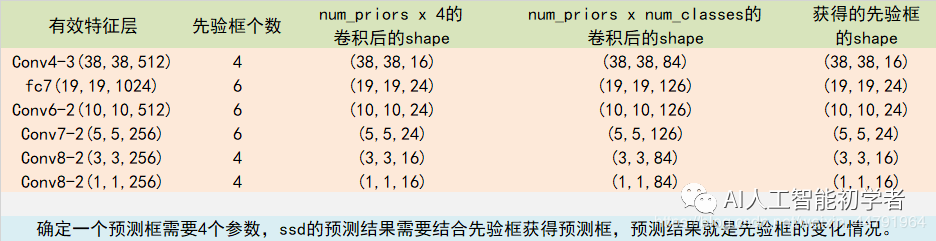
class SSD(nn.Module):
def __init__(self, phase, base, extras, head, num_classes):
super(SSD, self).__init__()
self.phase = phase
self.num_classes = num_classes
self.cfg = Config
self.vgg = nn.ModuleList(base)
self.L2Norm = L2Norm(512, 20)
self.extras = nn.ModuleList(extras)
self.priorbox = PriorBox(self.cfg)
with torch.no_grad():
self.priors = Variable(self.priorbox.forward())
self.loc = nn.ModuleList(head[0])
self.conf = nn.ModuleList(head[1])
if phase == 'test':
self.softmax = nn.Softmax(dim=-1)
self.detect = Detect(num_classes, 0, 200, 0.01, 0.45)
def forward(self, x):
sources = list()
loc = list()
conf = list()
# 获得conv4_3的内容
for k in range(23):
x = self.vgg[k](x)
s = self.L2Norm(x)
sources.append(s)
# 获得fc7的内容
for k in range(23, len(self.vgg)):
x = self.vgg[k](x)
sources.append(x)
# 获得后面的内容
for k, v in enumerate(self.extras):
x = F.relu(v(x), inplace=True)
if k % 2 == 1:
sources.append(x)
# 添加回归层和分类层
for (x, l, c) in zip(sources, self.loc, self.conf):
loc.append(l(x).permute(0, 2, 3, 1).contiguous())
conf.append(c(x).permute(0, 2, 3, 1).contiguous())
# 进行resize
loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1)
conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1)
if self.phase == "test":
# loc会resize到batch_size,num_anchors,4
# conf会resize到batch_size,num_anchors,
output = self.detect(
loc.view(loc.size(0), -1, 4), # loc preds
self.softmax(conf.view(conf.size(0), -1,
self.num_classes)), # conf preds
self.priors
)
else:
output = (
loc.view(loc.size(0), -1, 4),
conf.view(conf.size(0), -1, self.num_classes),
self.priors
)
return output
mbox = [4, 6, 6, 6, 4, 4]
def get_ssd(phase,num_classes):
vgg, extra_layers = add_vgg(3), add_extras(1024)
loc_layers = []
conf_layers = []
vgg_source = [21, -2]
for k, v in enumerate(vgg_source):
loc_layers += [nn.Conv2d(vgg[v].out_channels,
mbox[k] * 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(vgg[v].out_channels,
mbox[k] * num_classes, kernel_size=3, padding=1)]
for k, v in enumerate(extra_layers[1::2], 2):
loc_layers += [nn.Conv2d(v.out_channels, mbox[k]
* 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(v.out_channels, mbox[k]
* num_classes, kernel_size=3, padding=1)]
SSD_MODEL = SSD(phase, vgg, extra_layers, (loc_layers, conf_layers), num_classes)
return SSD_MODEL
2.3.3、Anchor中心的获取
每个默认框的中心位置为:
其中,W、H分别输入图像宽度和高度,i=0,1,...,m-1,j=0,1,...,n-1。
2.3.4、数据增强
为了提高关于目标大小和形状的鲁棒性,SSD采用了数据增强的随机采样策略。
- 使用整幅原始输入图像
- 采样图像块,与目标的最小交并比为0.1、0.3、0.5、0.7、0.9
- 随机采样图像块,每个采样块的大小为原始图像大小的[0.1,1],高宽比为[0.5,2],如果真是边框的中心在采样块内,则保留重叠部分;
- 采样块的增强(亮度变化、大小调整、概率翻转等操作)。



2.4、SSD的优缺点
2.4.1、SSD的优点
- 对于小尺寸目标对象,SSD的性能比Faster R-CNN差。SSD只能在较高分辨率的层(最左边的层)检测小 目标。但是这些层包含低级特征,如边缘或色块,分类的信息量较少。
- 准确率随着默认边界框的数量而增加,但以速度为代价。
- 多尺度特征图改进了不同尺度的目标的检测。
- 设计更好的默认边界框将有助于准确性。
- COCO数据集具有较小的目标。要提高准确性,使用较小的默认框(以较小的尺度0.15开始)。
- 与R-CNN相比,SSD具有较低的定位误差,但处理相似类别的分类错误较多。较高的分类错误可能是因为使 用相同的边界框来进行多个类别预测。
- SSD512 具有比SSD300更高的精度(2.5%),但运行速度为22 FPS而不是59 FPS。
2.4.2、SSD的缺点
- SSD算法对小目标不够鲁棒(会出现误检和漏检);
- 最主要的原因是浅层特征图的表示能力 不够强。
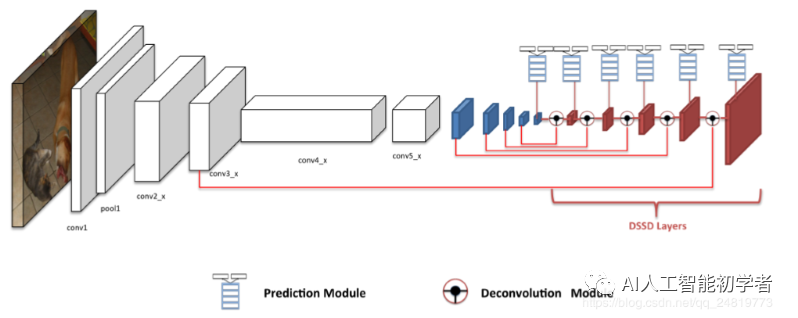
3、SSD的改进——DSSD
3.1、DSSD模型概览
DSSD在原来的SSD模型上主要作了两大改进:
- 替换掉VGG,而改用了Resnet-101作为特征提取网络并在对不同尺度的特征图进行默认框检测时使用了更新的检测单元;
- 在网络的后端使用了多个反卷积层(deconvolution layers)以有效地扩展低维度信息 的上下文信息(contextual information),从而有效地改善了小尺度目标的检测。
3.2、新的预测模块
为每个预测层添加一个残差块,如(c)所示。
还尝试了原始的SSD方法(a)和具有跳跃连接(b)的残差块的版本以及两个连续的残差块(d)。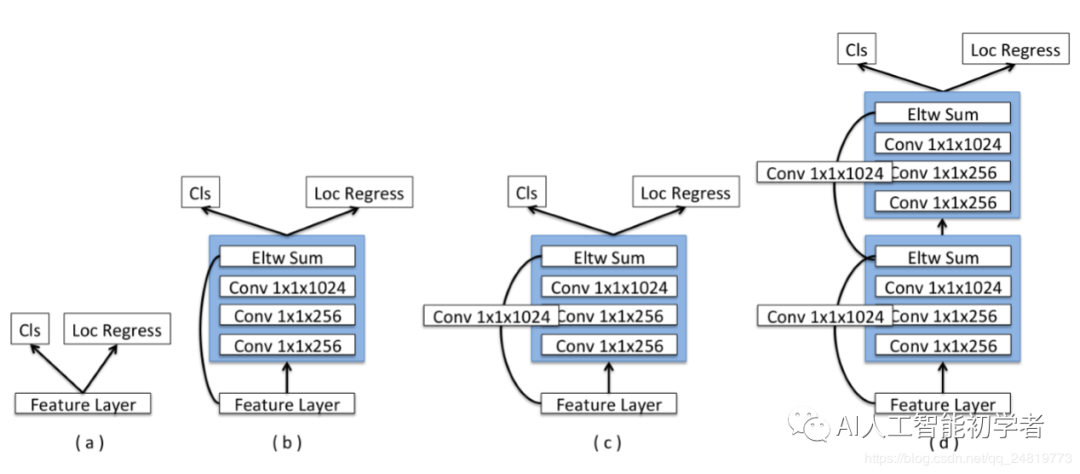
3.3、反卷积模块
DSSD的第二个重大创新来自于在模型后端添加了多个反卷积模块来扩大模型在小尺度上的high level特征信息。而这 种反卷积输出的特征图又会与模型前端卷积层的相同尺度的特征图进行元素级的乘法(element-wise product)来 生成相应尺度的特征图。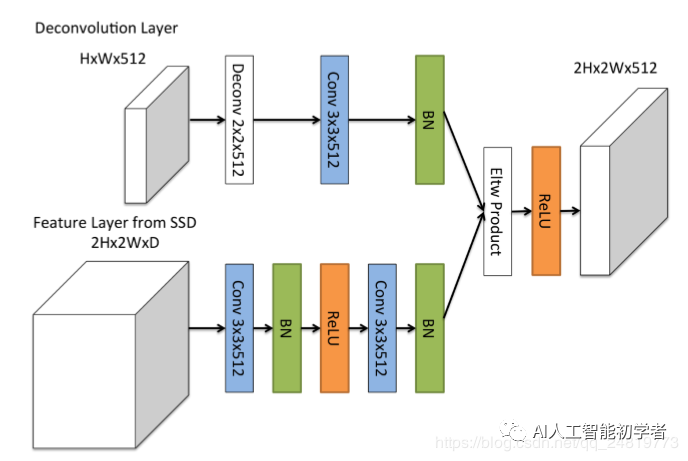
添加额外的反卷积层以连续增加特征图层的分辨率。
为了加强特征,采用了沙漏模型中的“跳跃连接”理念
- 首先,在每个卷积层之后添加BN层。
- 其次,使用学习的反卷积层而不是双线性上采样。
- 最后,测试了不同的 组合方法:逐元素相加和逐元素乘积。
实验结果表明,逐元素乘积提供了最佳的准确性。新的DSSD模型能够胜过以前的SSD框架,特别是在小目标或上下文特定目标上, 同时仍然保持与其他检测器相当的速度。
源码下载训练自己的数据集
扫描下方二维码回复【SSD】即可获取下载链接:

希望您可以关注公众号,也非常期待您的打赏。
声明:转载请说明出处
下方为小生公众号,还望包容接纳和关注,非常期待与您的美好相遇,让我们以梦为马,砥砺前行。

点“在看”给我一朵小黄花


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)